Recognizing Semantics of Continuous Strings in Chinese Patent Documents
Wang Xueying, Wang Hao(), Zhang Zixuan
School of Information Management, Nanjing University, Nanjing 210023, China Jiangsu Key Laboratory of Data Engineering and Knowledge Service (Nanjing University), Nanjing 210023, China
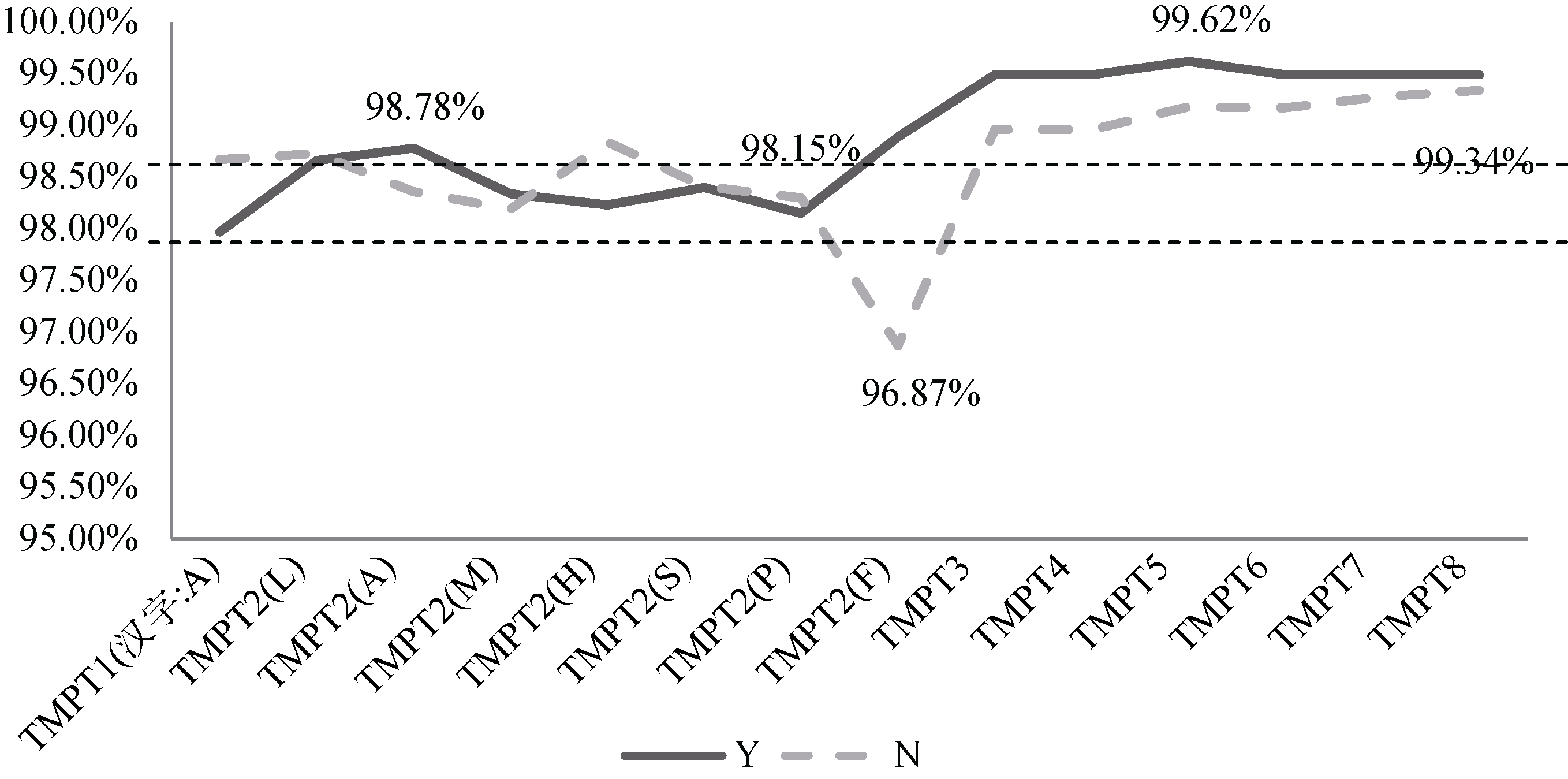
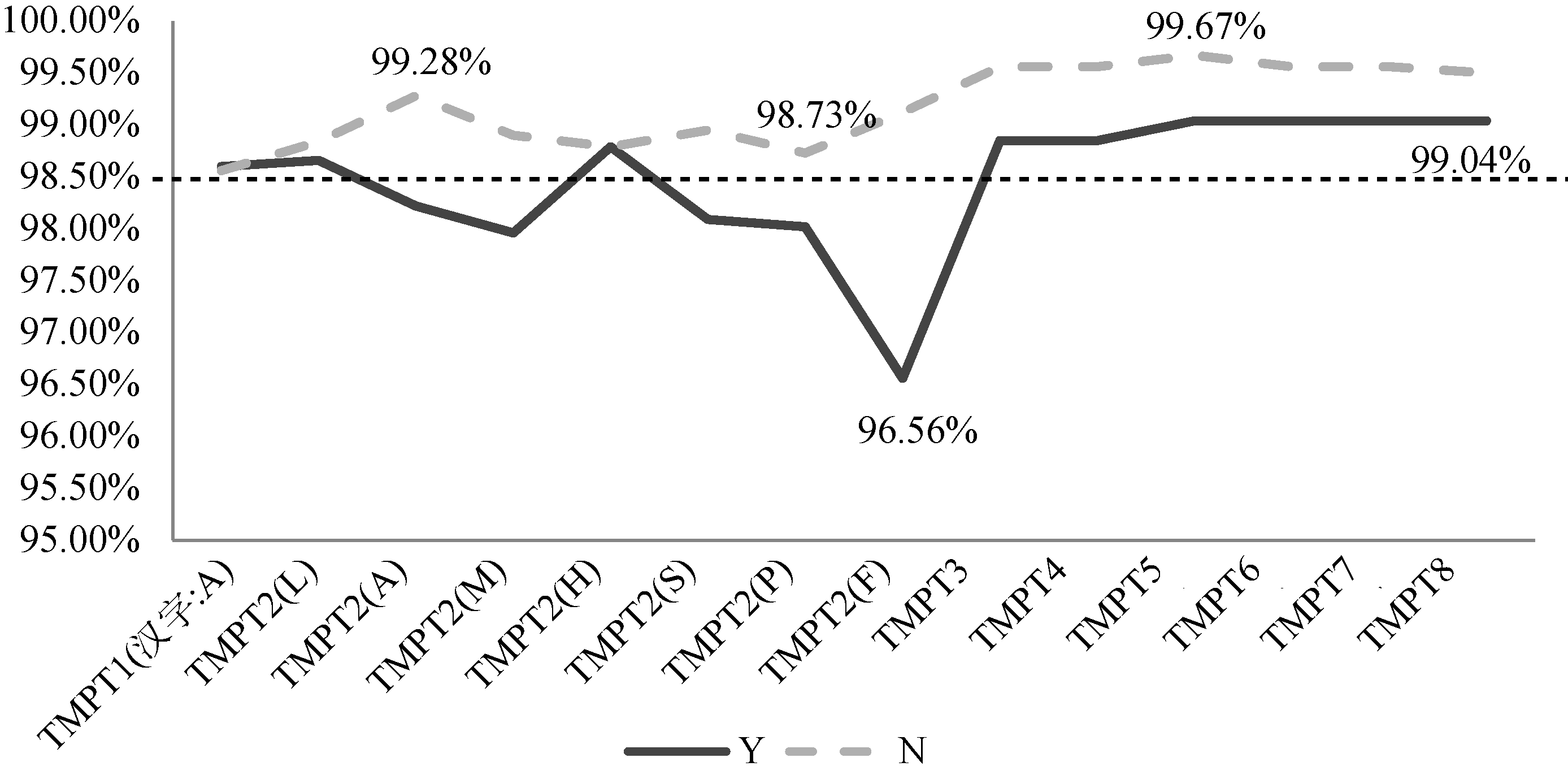
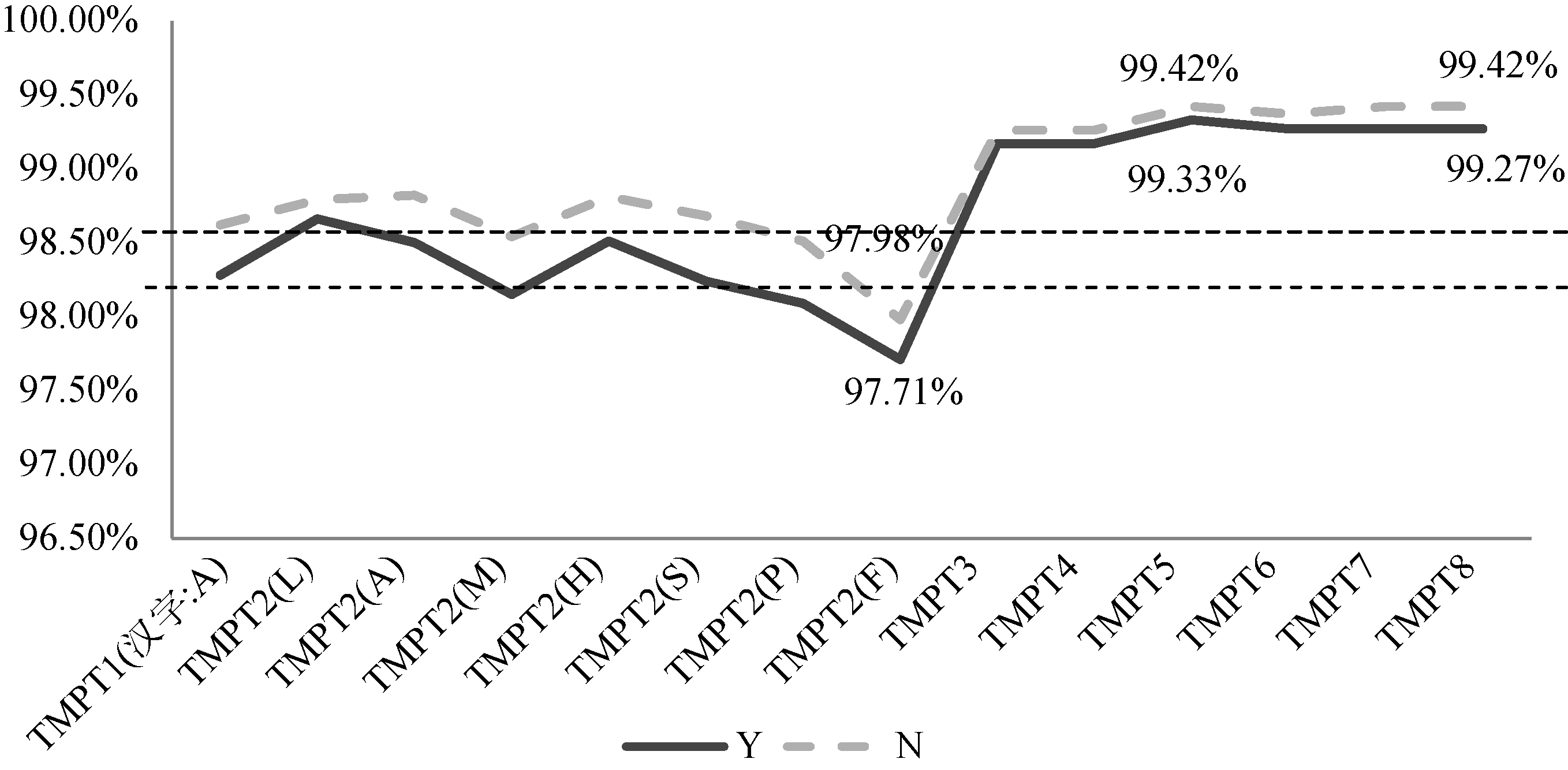
[Objective] This paper aims to extract the semantic information from continuous strings in Chinese patent documents in the field of iron and steel metallurgy. [Methods] First, we collected strings with identified the semantics as the learning corpus. Then, we examined the basic features, as well as characteristics of Chinese characters and strings with the corpus to establish the best model. Finally, we used this model to recognize the semantics of other strings. [Results] The proposed model could effectively extract semantics of the continuous strings. [Limitations] We did not include the identified characters to the training corpus. [Conclusions] The new model could identify the semantics of continuous strings in Chinese patent documents, which could be used to study the continuous strings in English literature.
王雪颖, 王昊, 张紫玄. 中文专利文献中连续符号串的语义识别*[J]. 数据分析与知识发现, 2018, 2(5): 11-22.
Wang Xueying,Wang Hao,Zhang Zixuan. Recognizing Semantics of Continuous Strings in Chinese Patent Documents. Data Analysis and Knowledge Discovery, 2018, 2(5): 11-22.
Trappey C V, Wu H Y, Taghaboni-Dutta F, et al.Using Patent Data for Technology Forecasting: China RFID Patent Analysis[J]. Advanced Engineering Informatics, 2011, 25(1): 53-64.
doi: 10.1016/j.aei.2010.05.007
[2]
王密平. 汉语专利术语抽取及应用研究——以钢铁冶金领域为例[D]. 南京: 南京大学, 2017.
[2]
(Wang Miping.A Study on Chinese Terms Extraction and Their Application: The Case of Iron and Steel Metallurgy[D]. Nanjing: Nanjing University, 2017.)
(Wang Miping, Wang Hao, Deng Sanhong, et al.A Study on Chinese Terms Extraction and Their Application: The Case of Iron and Steel Metallurgy[J]. New Technology of Library and Information Service, 2016(6): 28-36.)
[6]
韩杰冰. 基于字角色标注的中文专利术语识别研究[D]. 南京: 南京大学, 2015.
[6]
(Han Jiebing.The Research on Chinese Term Recognition of Patents Based on Word-Role Tagging[D]. Nanjing: Nanjing University, 2015.)
(Jiang Wu.Application of Pattern Recognition Techniques in Plant Numerical Taxonomy and Chlorophyll Content of Genus Camellia[D]. Jinhua: Zhejiang Normal University, 2013.)
(Luo Jun, Wang Qingli, Zhang Hua, et al.Phenetic Classification for Photosynthetic Characters of Different Sugarcane Varieties[J]. Chinese Journal of Applied and Environmental Biology, 2007, 13(4): 461-465.)
doi: 10.3321/j.issn:1006-687x.2007.04.004
(Liu Xiaoyun, Chen Wenxin.16S rDNA PCR-RFLP Analysis and Numerical Taxonomy for Rhizobia Isolated from Trifolium, Crotalaria and Mimosa[J]. Journal of China Agricultural University, 2003, 8(3): 1-6.)
doi: 10.3321/j.issn:1007-4333.2003.03.001
(Luo Lipu, Guo Xianguo.Classification of a Medically Important Group of Gamasid Mites by Numerical Taxonomy in Yunnan, China[J]. Journal of Tropical Medicine, 2007, 50(1): 172-177. )
doi: 10.3321/j.issn:0454-6296.2007.02.011
(Chen Xiaoqin, Chen Qiang, Zhang Shirong, et al.Taxonomy and BOX-PCR Analysis of Free-Living Dizotrophs Isolated from Soils in Liusha River Valley[J]. Journal of Agro-Environment Science, 2006, 25(S): 528-532.)
[14]
孙家梅. 白蛉的数值分类和基于DNA条形码的分子系统学研究[D]. 广州: 暨南大学, 2010.
[14]
(Sun Jiamei.The Numerical Taxonomy and Molecular Systematic Using Phlebotomus DNA Barcode of Phlebotomine Sandflies[D]. Guangzhou: Jinan University, 2010.)
[15]
么枕生. 用于数值分类的聚类分析[J]. 海洋湖沼通报, 1994(2): 1-12.
[15]
(Yao Zhensheng.Cluster Analysis Used in Numerical Classification[J]. Transactions of Oceanology and Limnology, 1994(2): 1-12.)
(Zhao Xinxin.Research on Character Coding Based Text Stenographer and Its Attack Methods[D]. Hefei: University of Science and Technology of China, 2009.)
(Jin Hua, Zhu Yatao, Jin Zhiqiang.Research on Detection Method of English Italic Characters in Agriculture Acquisition[J]. Journal of Agricultural University of Hebei, 2015, 38(6): 124-128.)
doi: 10.13320/j.cnki.jauh.2015.0148
(Tang Qing, Lv Xueqiang, Li Zhuo, et al.Research on Domain Ontology Term Extraction[J]. New Technology of Library and Information Service, 2014(1): 43-50.)
(Qu Peng, Wang Huilin.Patent Term Extraction for Information Analysis[J]. Library and Information Service, 2013, 57(1): 130-135.)
doi: 10.7536/j.jssn.0252-3116.2013.01.023
(Hu Apei, Zhang Jing, Liu Junli.Chinese Term Extraction Based on Improved C-value Method[J]. New Technology of Library and Information Service, 2013(2): 24-29.)
(Hou Ting, Lv Xueqiang, Li Zhuo.Hierarchical Filtering Method for Patent Term Extraction[J]. New Technology of Library and Information Service, 2015(1): 24-30.)
(He Yuanbiao, Le Xiaoqiu, Zhang Fan.Research on Keyphrase Extraction from Scholarly Article Outline[J]. New Technology of Library and Information Service, 2014(3): 73-79.)
(Du Liping, Li Xiaoge, Zhou Yuanzhe, et al.Application of Mutual Information Improvement Method in Term Extraction[J]. Computer Applications, 2015, 35(4): 996-1000, 1005.)
doi: 10.11772/j.issn.1001-9081.2015.04.0996
(Gu Jun, Wang Hao.Study on Term Extraction on the Basis of Chinese Domain Texts[J]. New Technology of Library and Information Service, 2011(4): 29-34.)
(Zeng Wen, Xu Shuo, Zhang Yunliang, et al.The Research and Analysis on Automatic Extraction of Science and Technology Literature Terms[J]. New Technology of Library and Information Service, 2014(1): 51-55.)
(Tang Tao, Zhou Qiaoli, Zhang Guiping.Term Extraction Based on the Combination of Statistics and Rules[J]. Journal of Shenyang University of Aeronautics and Astronautics, 2011, 28(5): 71-74.)
(Chen Feng, Zhai Yujia, Wang Fang.Automatic Theory Recognition in Academic Journals Based on CRF[J]. Library and Information Service, 2016, 60(2): 122-128.)
doi: 10.13266/j.issn.0252-3116.2016.02.019
(Wang Rongyang, Ju Jiupeng, Li Shoushan, et al.Feature Engineering for CRFs Based Opinion Target Extraction[J]. Journal of Chinese Information Processing, 2012, 26(2): 56-61.)
(Hou Libin, Li Peifeng, Zhu Qiaoming.Study of Event Recognition Based on CRFs and Cross-event[J]. Computer Engineering, 2012, 38(24): 191-195.)
doi: 10.3969/j.issn.1000-3428.2012.24.045
(Luo Yanyan, Huang Degen.Chinese Word Segmentation Based on the Marginal Probabilities Generated by CRFs[J]. Journal of Chinese Information Processing, 2009, 23(5): 3-8.)
[38]
CRF++[EB/OL]. [2017-11-16]. .
[39]
周志华, 王珏. 机器学习及其应用[M]. 北京: 清华大学出版社, 2009.
[39]
(Zhou Zhihua, Wang Jue.Machine Learning and Its Application [M]. Beijing: Tsinghua University Press, 2009.)