A Multiple Pattern Matching Algorithm for Specifications of Incremental Metadata for Sci-Tech Literature
Dong Mei1,2,Chang Zhijun1,2,Zhang Runjie3()
1National Science Library, Chinese Academy of Sciences, Beijing 100190, China 2Department of Library, Information and Archives Management, School of Economics and Management, University of Chinese Academy of Sciences, Beijing 100190, China 3Electronics and Computer Science, University of Southampton, Southampton SO17 1BJ, UK
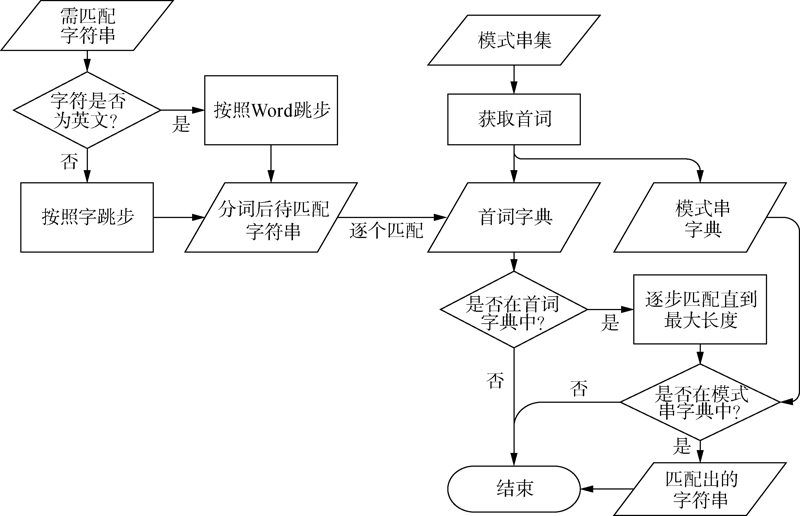
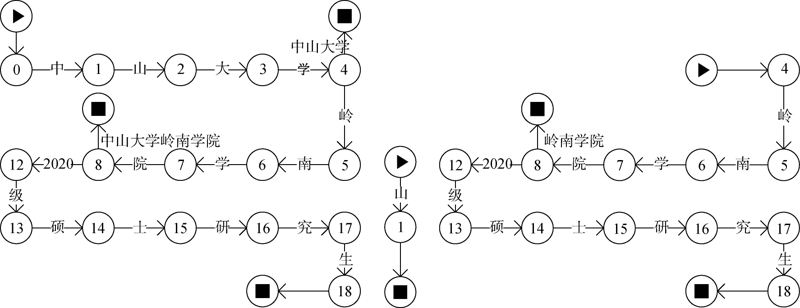
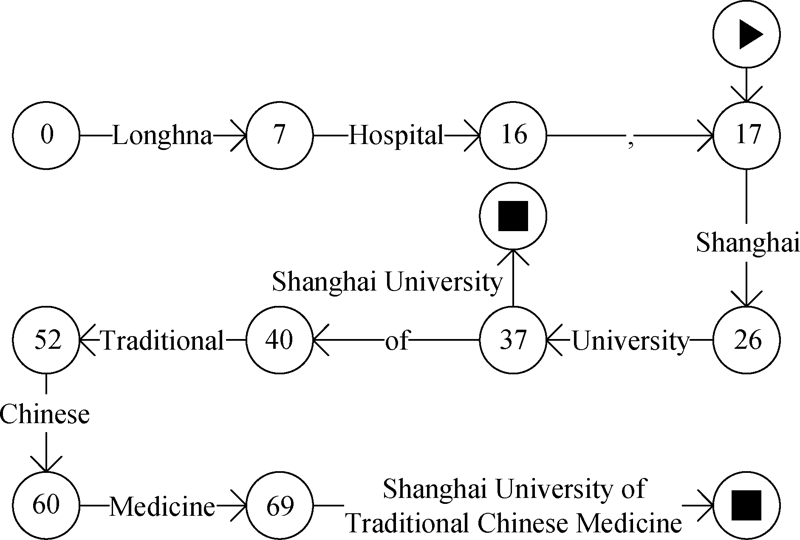
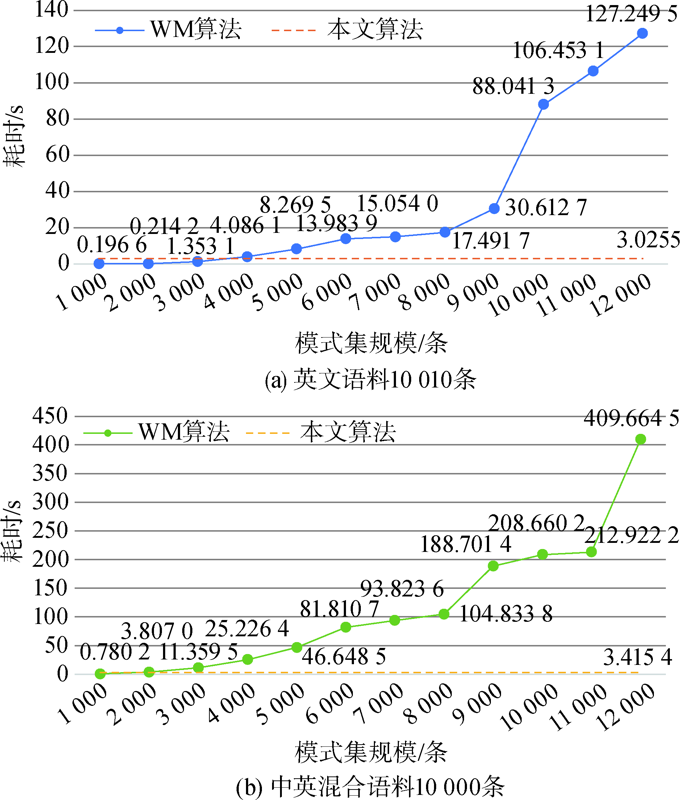
[Objective] This paper designs a multiple pattern matching algorithm to standardize the institutional information of sci-tech literature metadata. [Methods] First, we used the Hash function to locate the pattern strings and reduced the system memory usage. Then, we extracted the first words of the pattern strings, which were combined with word skipping matching. The new algorithm reduced the number of matches and increased the jump range, which improved the efficiency of multiple pattern matching. [Results] We examined our model with the CSCD’s institutional library as the pattern string set. Compared with the Aho-Corasick (AC) algorithm, our method quickly constructed the dictionary corresponding to the pattern string sets. When the data volume reached about 10 000, our model spent less time on the same tasks. For the English corpus, there was a 9.39% improvement in time performance. Compared with the Wu-Manber (WM) algorithm, our method was not restricted by the shortest pattern strings. [Limitations] The algorithm or data needs to be adjusted for different pattern strings and text strings. This algorithm and the extended headless mode are not suitable for small pattern string sets with large string sets. [Conclusions] The algorithm can be applied to Chinese, English, and Chinese-English mixed texts. The time performance of our algorithm is superior to the AC and WM algorithms in processing large pattern string set (106) and small string set (about 10,000).
(Qi Hui, Cao Min, Yuan Shizhong. Testing for Contrasting Performance of Pattern Matching Algorithms and Its Application[J]. Henan Science, 2009,27(7):835-838.)
[6]
Knuth D E, Morris J H, Pratt V R. Fast Pattern Matching in Strings[J]. Siam Journal on Computing, 1977,6(2):323-350.
doi: 10.1137/0206024
(Cao Chenghong, Lei Yingke. Survey of Bit-stream Oriented Link-layer Unknown Frame Analysis Techniques[J]. Journal of Chinese Computer Systems, 2018,39(2):297-303.)
(Liu Bangguo, Chen Qingchun, Lei Xianfu. Efficient Multi-pattern Matching Algorithm for PDF Content Search[J]. Application Research of Computers, 2020,37(6):1755-1759.)
(Zhao Guofeng, Ye Fei, Yao Yongan, et al. Design and Implementation of A Multi-pattern String Matching Algorithm in Cloud Center Network Intrusion Detection System[J]. Netinfo Security, 2018(1):52-57.)
[13]
Baeza-Yates R A, Gonnet G H. A New Approach to Text Searching[J]. ACM SIGIR Forum, 1989,23(SI):168-175.
doi: 10.1145/75335.75352
[14]
朱俊. 多模式匹配算法研究[D]. 合肥:合肥工业大学, 2010.
[14]
(Zhu Jun. Multiple Patterns Match Algorithm Research[D]. Hefei : Hefei University of Technology, 2010.)
(Wang Peifeng, Li Li. Research on Multi-Pattern Matching Algorithms Based on Aho-Corasick Algorithm[J]. Application Research of Computers, 2011,28(4):1251-1253, 1259.)
[17]
Nieminen J, Kilpelinen P. Efficient Implementation of Aho-Corasick Pattern Matching Automata Using Unicode[J]. Software: Practice and Experience, 2010,37(6):669-690.
doi: 10.1002/(ISSN)1097-024X
(Li Zhidong, Yang Wu, Zhang Rubo, et al. Multi-pattern Matching Algorithm Based on Heterogeneous Implicit Storage[J]. Journal on Communications, 2009,30(3):119-124.)
[19]
胡丽娟. 大规模多模式匹配算法的研究[D]. 西安:西安电子科技大学, 2017.
[19]
(Hu Lijuan. Research on Large-Scale Multi-pattern Matching Algorithms[D]. Xi’an: Xidian University, 2017.)
(Chen Yongjie, Wushour Silamu, Yu Qing. An Improved Multi-pattern Matching Algorithm Based on Aho-Corasick Algorithm[J]. Modern Electronics Technique, 2019,42(4):89-93.)
(Cao Weizheng, Ge Mengmeng. Multi-pattern Matching Algorithm Research and Optimization[J]. Intelligent Computer and Applications, 2018,8(2):129-133.)
[22]
潘华伟. 网络防护墙中多模式匹配算法的研究[D]. 武汉:湖北工业大学, 2017.
[22]
(Pan Huawei. The Research of Multi-pattern, Matching Algorithm in Network Firewall[D]. Wuhan: Hubei University of Technology, 2017.)
[23]
Fredriksson K, Grabowski S. Average-Optimal String Matching[J]. Journal of Discrete Algorithms, 2009,7(4):579-594.
doi: 10.1016/j.jda.2008.09.001
[24]
Coit C J, Staniford S, Mcalerney J. Towards Faster String Matching for Intrusion Detection or Exceeding the Speed of Snort[M]. Piscataway, NJ: IEEE Press, 2001.
(Dong Zhixin, Fang Binxing. Optimization Research of Multi Pattern Matching Algorithm Based on AC_QS[J]. Intelligent Computer and Applications, 2017,7(5):100-103.)
(Xia Nian, Song Tian. Short-rule-efficient Rapid Multi-pattern Matching Algorithm[J]. Computer Engineering and Applications, 2017,53(7):1-8.)
[29]
Zhang W. An Improved Wu-Manber Multiple Patterns Matching Algorithm[C]// Proceedings of the 2016 IEEE International Conference on Electronic Information and Communication Technology. Piscataway, NJ: IEEE Press, 2016: 286-289.
[30]
Saikrishna V, Rasool A, Khare N. Spam Filtering Through Multiple Pattern Bit Parallel String Matching Combining Shift AND & OR[J]. International Journal of Computer Applications, 2013,61(5):40-45.
(Meng Xudong, Xu Qiangkai. Implementation of FPGA Applied to Web Server Matching Algorithm[J]. Computer Technology and Development, 2016,26(12):142-147,152.)
[32]
戴正华. 面向体系结构的串匹配算法优化研究[D]. 北京:中国科学院计算技术研究所, 2006.
[32]
(Dai Zhenghua. Optimization of String Matching Algorithm Based on Computer Architecture[D]. Beijing: Institute of Computing Technology of Chinese Academy of Sciences, 2006.)
(Chen Rui, Gu Naijie, Ye Hong. A Single Mode Bit-Parallel String Matching Algorithm Based on HXDSP[J]. Computer Applications and Software, 2020,37(7):246-252.)
[34]
Lubanovic B. Python语言及其应用[M]. 丁嘉瑞, 梁杰, 禹常隆译. 北京: 人民邮电出版社, 2016.
[34]
(Lubanovic B. Introducing Python[M]. Translated by Ding Jiarui, Liang Jie, Yu Changlong. Beijing: Posts & Telecom Press, 2016.)
[35]
Matthes E. Python编程:从入门到实践[M]. 袁国忠译. 北京: 人民邮电出版社, 2016.
[35]
(Matthes E. Python Crash Course:A Hands-On, Project-Based Introducation to Programming[M]. Translated by Yuan Guozhong. Beijing: Posts & Telecom Press, 2016.)
(Chinese Science Citation Database Group. Selection and Evaluation of Source Journals of Chinese Science Citation Database[J]. Chinese Journal of Scientific and Technical Periodicals, 1997,8(4):17-21.)