Recognizing and Analyzing Cited Spans in Literature
Xu Jian1(), Li Gang1, Mao Jin1, Ye Guanghui2
1Center for Studies of Information Resources, Wuhan University, Wuhan 430072, China 2School of Information Management, Central China Normal University, Wuhan 430079, China
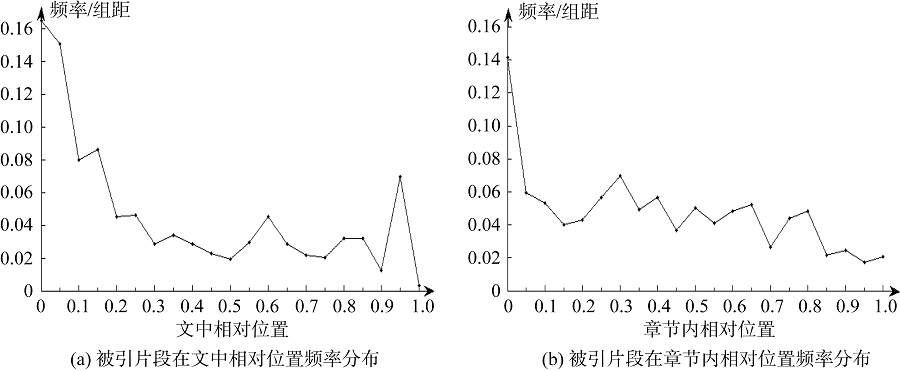
[Objective] This paper analyzes features of the cited document spans, and compares the effectiveness of several recognization techniques. [Methods] Firstly, we analyzed the annotated data of cited spans from CL-SciSumm 2016 for their length and position features as well as correlations with citation contexts. Then, we compared the effectiveness of bag-of-words, topic model, semantic dictionary (WordNet) methods by their performance of recognizing cited spans. [Results] We found that 96% of the annotated cited spans were less than three sentences, and most of the cited spans occurred in the front part of the whole paper or each chapter. The average TextRank weight of these cited spans was significantly higher than that of the regular spans. The length of these cited spans was correlated to the length of their corresponding sections, however, there was no obvious ties with the position features. The method based on bag-of-words was the most effective one, followed by the methods based on semantic similarity and topic model. [Limitations] Our discussion on the conception and characteristics of the cited spans are in theory. All data analysis was done with the annotation dataset of CL-SciSumm 2016. [Conclusions] The choice of words in scientific literature is very formal and rigorous, which makes the lexical features play an important role in recognizing the cited spans.
Jaidka K, Chandrasekaren M K, Elizalde B F, et al.The Computational Linguistics Summarization Pilot Task[C]// Proceedings of Text Analysis Conference. 2014.
[2]
Jaidka K, Chandrasekaren M K, Rustagi S, et al.Overview of the CL-SciSumm 2016 Shared Task[C]// Proceedings of the 2016 Joint Workshop on Bibliometric-enhanced Information Retrieval and NLP for Digital Libraries. 2016.
[3]
Le M H, Ho T B, Nakamori Y.Detecting Emerging Trends from Scientific Corpora[J]. International Journal of Knowledge and Systems Sciences, 2005, 2(2): 53-59.
(Zhu Qingsong, Leng Fuhai.Topic Identification of Highly Cited Papers Based on Citation Context Analysis[J]. Journal of Library Science in China, 2014, 40(1): 39-49.)
doi: 10.3969/j.issn.1001-8867.2014.01.004
[5]
Bradshaw S G.Reference Directed Indexing: Indexing Scientific Literature in the Context of Its Use[D]. Evanston, IL, USA: Northwestern University, 2002.
[6]
Aljaber B, Stokes N, Bailey J, et al.Document Clustering of Scientific Texts Using Citation Contexts[J]. Information Retrieval, 2010, 13(2): 101-131.
doi: 10.1007/s10791-009-9108-x
[7]
Aljaber B, Matinez D, Stokes N, et al.Improving MeSH Classification of Biomedical Articles Using Citation Contexts[J]. Journal of Biomedical Informatics, 2011, 44: 881-896.
doi: 10.1016/j.jbi.2011.05.007
pmid: 21683802
[8]
Nanba H, Okumura M.Towards Multi-paper Summarization Using Reference Information[C]// Proceedings of the 16th International Joint Conference on Artificial Intelligence. 1999.
[9]
Qazvinian V, Radev D R.Scientific Paper Summarization Using Citation Summary Networks[C]// Proceedings of the 22nd International Conference on Computational Linguistics, Manchester, UK. Stroudsburg, PA, USA: Association for Computational Linguistics, 2008: 689-696.
[10]
Qazvinian V, Radev D R, Ozgur A.Citation Summarization Through Keyphrase Extraction[C]// Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China. 2010.
(Lu Wei, Meng Rui, Liu Xingbang.A Deep Scientific Literature Mining-Oriented Framework for Citation Content Annotation[J]. Journal of Library Science in China, 2014, 40(6): 93-104.)
doi: 10.13530/j.cnki.jlis.140029
[12]
孙枫军. 引文上下文中的概念抽取[D]. 北京:中国科学技术信息研究所, 2012.
[12]
(Sun Fengjun.Concept Extraction in Citation Context[D]. Beijing: Institute of Scientific and Technical Information of China, 2012.)
[13]
Mei Q, Zhai C X.Generating Impact-Based Summaries for Scientific Literature[C]// Proceedings of the 46th Meeting of the Association for Computational Linguistics: Human Language Technologies. 2008:816-824.
[14]
Mollá D, Jones C, Sarkers A.Impact of Citing Papers for Summarisation of Clinical Documents[C]//Proceedings of Australasian Language Technology Association Workshop. 2014.
[15]
Cohan A, Soldaini L, Mengle S S R, et al. Towards Citation-based Summarization of Biomedical Literature[C]// Proceedings of the Text Analysis Conference. 2014.
[16]
Nomoto T.NEAL: A Neurally Enhanced Approach to Linking Citation and Reference[C]// Proceedings of the 2016 Joint Workshop on Bibliometric-enhanced Information Retrieval and NLP for Digital Libraries. 2016.
[17]
Klampfl S, Rexha A, Kern R.Identifying Referenced Text in Scientific Publications by Summarisation and Classification Techniques[C]// Proceedings of the 2016 Joint Workshop on Bibliometric-enhanced Information Retrieval and NLP for Digital Libraries. 2016.
[18]
Moraes L, Baki S, Verma R, et al.University of Houston at CL-SciSumm 2016: SVMs with Tree Kernels and Sentence Similarity[C]// Proceedings of the 2016 Joint Workshop on Bibliometric-enhanced Information Retrieval and NLP for Digital Libraries. 2016.
[19]
Saggion H, AbuRa’ed A, Ronzano F. Trainable Citation- enhanced Summarization of Scientific Articles[C] // Proceedings of the 2016 Joint Workshop on Bibliometric- enhanced Information Retrieval and NLP for Digital Libraries. 2016.
[20]
Cao Z, Li W, Wu D.PolyU at CL-SciSumm 2016[C]// Proceedings of the 2016 Joint Workshop on Bibliometric- enhanced Information Retrieval and NLP for Digital Libraries. 2016.
[21]
Lu K, Mao J, Li G, et al.Recognizing Reference Spans and Classifying Their Discourse Facets[C]// Proceedings of the 2016 Joint Workshop on Bibliometric-enhanced Information Retrieval and NLP for Digital Libraries. 2016.
[22]
Aggarwal P, Sharma R.Lexical and Syntactic Cues to Identify Reference Scope of Citance[C]// Proceedings of the 2016 Joint Workshop on Bibliometric-enhanced Information Retrieval and NLP for Digital Libraries. 2016.
[23]
Mihalcea R, Tarau P. TextRank: Bringing Order into Texts [J/OL]. UNT Scholarly Works, 2004. .
[24]
Blei D, Carin L, Dunson D.Probabilistic Topic Models[J]. IEEE Signal Processing Magazine, 2010, 27(6): 55-65.
doi: 10.1109/MSP.2009.934715
[25]
Miller G A.WordNet: A Lexical Database for English[J]. Communications of the ACM, 1995, 38(11): 39-41.
[26]
Lin C Y.ROUGE: A Package for Automatic Evaluation of Summaries[C]// Proceedings of Post-Conference Workshop of ACL on Text Summarization Branches Out. 2004.