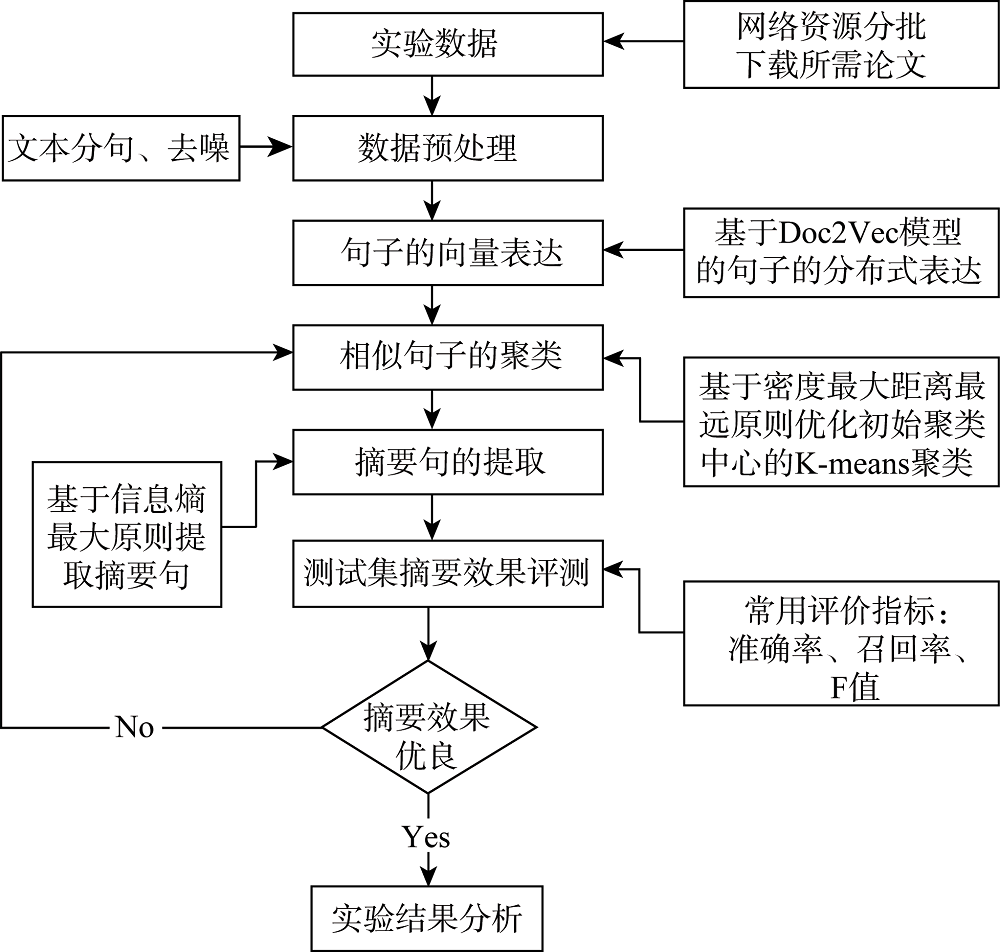
[Objective] This paper aims to improve the performance of automatic abstracting with the help of “Doc2vec” model and improved K-means clustering algorithm. [Methods] First, we introduced the Doc2Vec model, which could examine the document contextual information, to extract the semantics, grammar and word sequences of Chinese document sentences. Then, we transformed these sentences to vectors of fixed dimensions. Third, we identified clustering centers for the improved K-means algorithm, and then processed the sentence vectors. Finally, the sentences with larger information entropy in one cluster, as well as higher similarity with other sentences in the cluster, were extracted. [Results] Compared with the PLSA method, the precision, recall, and F value of the proposed model increased by 9.57%, 7.62% and 10.30% respectively. [Limitations] We could not use the sentences extracted from the documents to generate high quality abstracts. [Conclusions] The proposed method could improve the performance of automatic abstracting of Chinese documents.
(Cheng Yuan, Wushouer Silamu, Maimaitiyiming Hasimua.Automation Text Summarization Based on Comprehensive Characteristics of Sentence[J]. Computer Science, 2015, 42(4): 226-229.)
(Liu Xinghan, Huo Hua.Automatic Summarization for Text Based on Mutual Information[J]. Journal of Hefei University of Technology: Natural Science, 2014, 37(10): 1198-1203.)
(Gao Yongbing, Wang Yu, Ma Zhanfei.Research on Automatic Summarization of Personal Events Based on CR-PageRank Algorithm[J]. Computer Engineering, 2016, 42(11): 64-69.)
doi: 10.3969/j.issn.1000-3428.2016.11.011
(Mi Wenli, Sun Yuexin.Microblog Hot Topics Discovery Method Based on Probabilistic Topic Model[J]. Computer Systems & Applications, 2014, 23(8): 163-167.
(Zhang Qun, Wang Hongjun, Wang Lunwen.Classifying Short Texts with Word Embedding and LDA Model[J]. New Technology of Library and Information Service, 2016(12): 27-35.)
(Lin Jianghao, Zhou Yongmei, Yang Aimin, et al.Analysis on Topic Evolution of News Comments by Combining Word Vector and Clustering Algorithm[J]. Computer Engineering and Science, 2016, 38(11): 2368-2374.)
doi: 10.3969/j.issn.1007-130X.2016.11.032
[11]
Dai X, Bikdash M, Meyer B.From Social Media to Public Health Surveillance: Word Embedding Based Clustering Method for Twitter Classification[C]// Proceedings of SoutheastCon. IEEE, 2017.
(Yang Yuting, Wang Mingyang, Tian Xianyun, et al.Sina Microblog Sentiment Classification Based on Distributed Representation of Documents[J]. Journal of Intelligence, 2016, 35(2): 151-156.)
doi: 10.3969/j.issn.1002-1965.2016.02.027
(Huang Ren, Zhang Wei.Study on Sentiment Analyzing of Internet Commodities Review Based on Word2Vec[J]. Computer Science, 2016, 43(S1): 387-389.)
[14]
Cholakov K, Kordoni V.Using Word Embeddings for Improving Statistical Machine Translation of Phrasal Verbs[C]// Proceedings of the Workshop on Multiword Expressions. 2016: 56-60.
[15]
Wei H, Zhang H, Gao G.Representing Word Image Using Visual Word Embeddings and RNN for Keyword Spotting on Historical Document Images[C]// Proceedings of IEEE International Conference on Multimedia and Expo. IEEE Computer Society, 2017: 1368-1373.
(Yu Jie.Microblog New Word Recognition Combining Skip-Gram Model and Word Vector Projection[J]. Computer Systems & Applications, 2016, 25(7): 130-136.)
doi: 10.15888/j.cnki.csa.005236
[17]
Rui W, Liu J, Jia Y.Unsupervised Feature Selection for Text Classification via Word Embedding[C]// Proceedings of IEEE International Conference on Big Data Analysis. IEEE, 2016: 1-5.
(Zhai Donghai, Yu Jiang, Gao Fei, et al.K-means Text Clustering Algorithm Based on Initial Cluster Centers Selection According to Maximum Distance[J]. Application Research of Computers, 2014, 31(3): 713-715.)
doi: 10.3969/j.issn.1001-3695.2014.03.017
(Zhang Yinming, Huang Tinglei, Lin Ke, et al.An Improved K-means Algorithm for Text Clustering[J]. Journal of Guilin University of Electronic Technology, 2016, 36(4): 311-314.)
doi: 10.3969/j.issn.1673-808X.2016.04.011