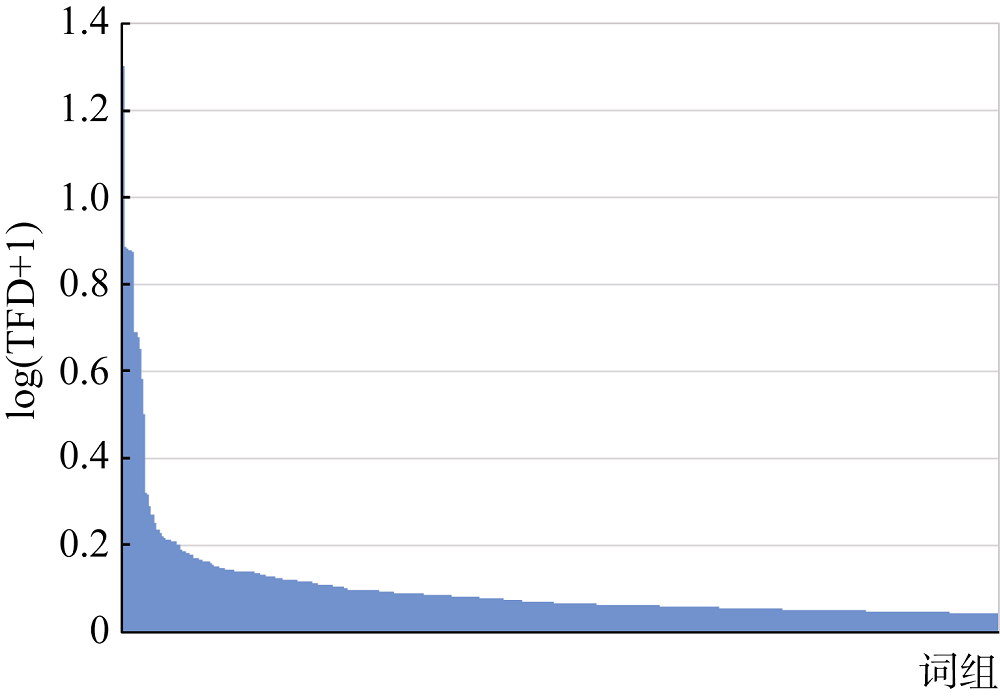
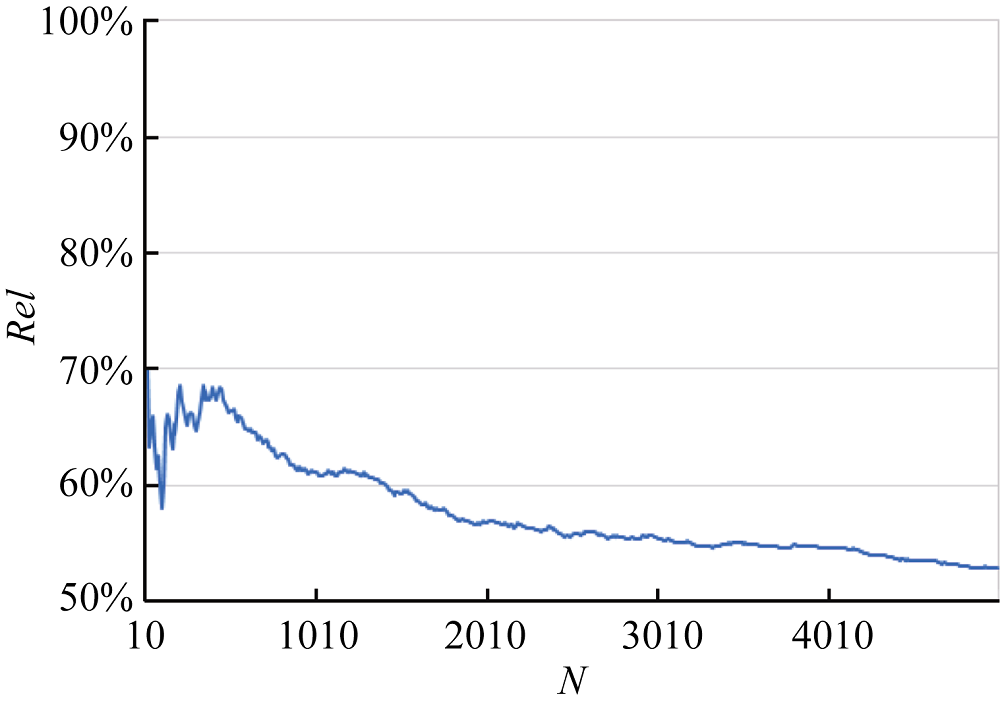
[Objective] This paper aims to improve the performance of Chinese word segmentation techniques on domain literature by optimizing results of existing approaches. [Methods] First, we proposed a new criteria of Term Frequency Deviation (TFD) to capture word formation characteristics of domain literature based on the analysis of segmentation errors. Then, we developed an unsupervised segmentation refining approach with the help of TFD. [Results] We examined the proposed approach with agriculture documents. It improved the segmentation results of three popular Chinese word segmentation approaches (i.e., ICTCLAS, THULAC and LTP) by 2%~3% in F1 measure. The proposed approach was easy to use and robustness to parameters. [Limitations] The recall of the proposed approach needs to be improved. [Conclusions] The new Chinese word segmentation approach, which imrpoves the performance of traditional methods on domain literature, could be applied to other fields due to its independence of domain-specific vocabulary and annotated corpus.
倪维健, 孙浩浩, 刘彤, 曾庆田. 面向领域文献的无监督中文分词自动优化方法*[J]. 数据分析与知识发现, 2018, 2(2): 96-104.
Ni Weijian,Sun Haohao,Liu Tong,Zeng Qingtian. An Unsupervised Approach to Optimize Chinese Word Segmentation on Domain Literature. Data Analysis and Knowledge Discovery, 2018, 2(2): 96-104.
(Huang Changning, Zhao Hai.Chinese Word Segmentation: A Decade Review[J]. Journal of Chinese Information Processing, 2007, 21(3): 8-19.)
doi: 10.3969/j.issn.1003-0077.2007.03.002
(Zhang Guiping, Liu Dongsheng, Yin Baosheng, et al.Research on Chinese Word Segmentation for Patent Documents[J]. Journal of Chinese Information Processing, 2010, 24(3): 112-117.)
doi: 10.3969/j.issn.1003-0077.2010.03.017
(Yue Jinyuan, Xu Jin’an, Zhang Yujie.Chinese Word Segmentation for Patent Documents[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2013, 49(1): 159-164.)
(Zhang Jie, Zhang Haichao, Zhai Dongsheng.Research of the Word Segmentation for Chinese Patent Claims[J]. New Technology of Library and Information Service, 2014(9): 91-98.)
[8]
Li S, Xue N.Effective Document-Level Features for Chinese Patent Word Segmentation[C]//Proceedings of the 52nd Annual Meeting of the ACL. 2014:199-205.
(Wang Junhui, Hu Tiejun, Li Danya, et al.Research on Method for Chinese Word Segmentation Without Thesaurus in Chinese Biomedical Text[J]. Journal of the China Society for Scientific and Technical Information, 2011, 30(2): 197-203.)
doi: 10.3772/j.issn.1000-0135.2011.02.012
(Li Guolei, Chen Xianlai, Xia Dong, et al.Research on Segmentation of Chinese Text in Medical Record[J]. Chinese Journal of Biomedical Engineering, 2016, 35(4): 477-481.)
(Huang Shuiqing, Wang Dongbo, He Lin.Exploring of Word Segmentation for For-Qin Literature Based on the Domain Glossary of Sinological Index Series[J]. Library and Information Service, 2015, 59(11): 127-133.)
doi: 10.13266/j.issn.0252-3116.2015.11.018
(Zhang Yue, Wang Dongbo, Zhu Danhao.Segmenting Chinese Words from Food Safety Emergencies[J]. Data Analysis and Knowledge Discovery, 2017, 1(2): 64-72.)
(Zhang Lin, Qin Ce, Ye Wenhao.Automatic Recognition of Legal Language Entities Based on Conditional Random Fields[J]. Data Analysis and Knowledge Discovery, 2017, 1(11): 46-52.)
(Shi Chongde, Wang Huilin.Research on Chinese Word Segmentation Optimization in Statistical Machine Translation[J]. New Technology of Library and Information Service, 2012(4): 29-34.)
(Han Dongxu, Chang Baobao.Approches to Domain Adaptive Chinese Segmetation Model[J]. Chinese Journal of Computers, 2015, 38(2): 272-281.)
doi: 10.3724/SP.J.1016.2015.00272
[17]
Zeng D, Wei D, Chau M, et al.Domain-specific Chinese Word Segmentation Using Suffix Tree and Mutual Information[J]. Information Systems Frontiers, 2011, 13(1): 115-125.
doi: 10.1007/s10796-010-9278-5
[18]
Song Y, Xia F.Using a Goodness Measurement for Domain Adaptation: A Case Study on Chinese Word Segmentation[C]//Proceedings of the 6th Language Resources and Evaluation Conference. 2012: 3853-3860.
(Gu Jun, Wang Hao.Study on Term Extraction on the Basis of Chinese Domain Texts[J]. New Technology of Library and Information Service, 2011(4): 29-34.)
(Xu Huating, Zhang yujie, Yang Xiaohui, et al. Active Learning Based Domain Adaptation for Chinese Word Segmentation[J]. Journal of Chinese Information Processing, 2015, 29(5): 55-63.)
[21]
Liu Y, Zhang Y, Che W, et al.Domain Adaptation for CRF-based Chinese Word Segmentation Using Free Annotations[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. 2014: 864-874.
(Zhang Meishan, Deng Zhilong, Che Wanxiang, et al.Combing Statistical Model and Dictionary for Domain Adaption of Chinese Word Segmentation[J]. Journal of Chinese Information Processing, 2012, 26(2): 8-13.)
doi: 10.3969/j.issn.1003-0077.2012.02.002
[23]
Beeferman D, Berger A, Lafferty J.Statistical Models for Text Segmentation[J]. Machine Learning, 1999, 34(1-3): 177-210.
doi: 10.1023/A:1007506220214
(Yu Shiwen, Duan Huiming, Zhu Xuefeng, et al.The Basic Processing of Contemporary Chinese Corpus at Peking University Specification[J]. Journal of Chinese Information Processing, 2002, 16(6): 58-65.)