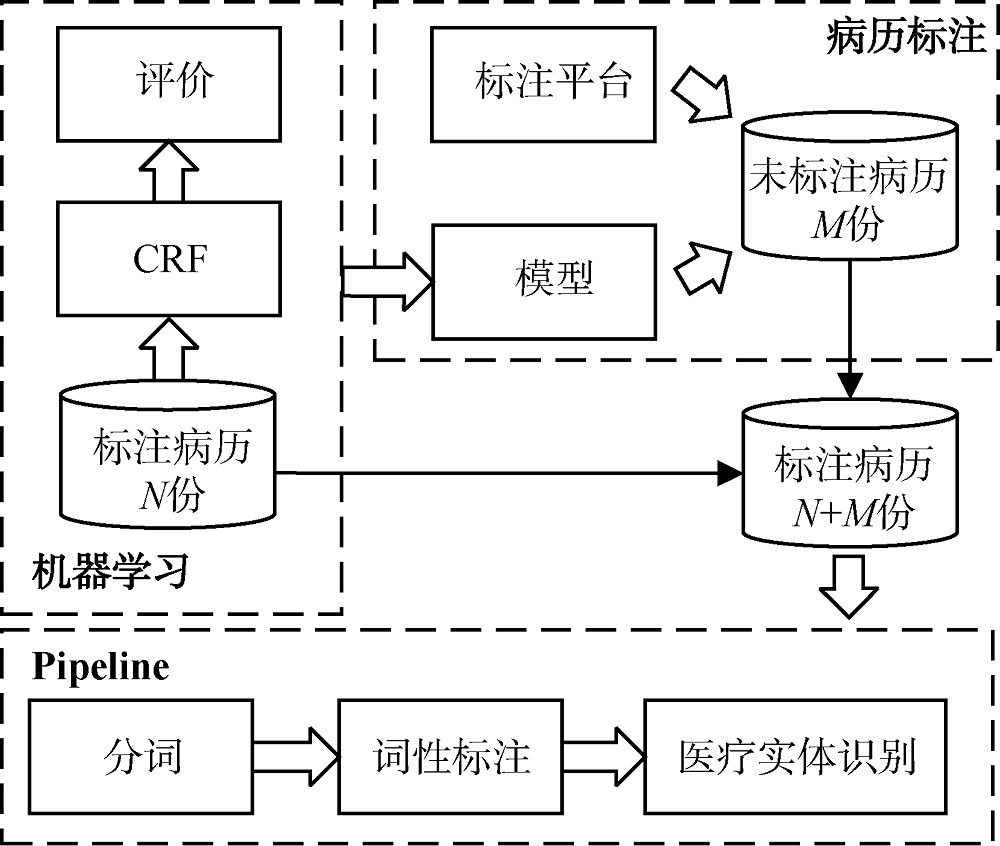
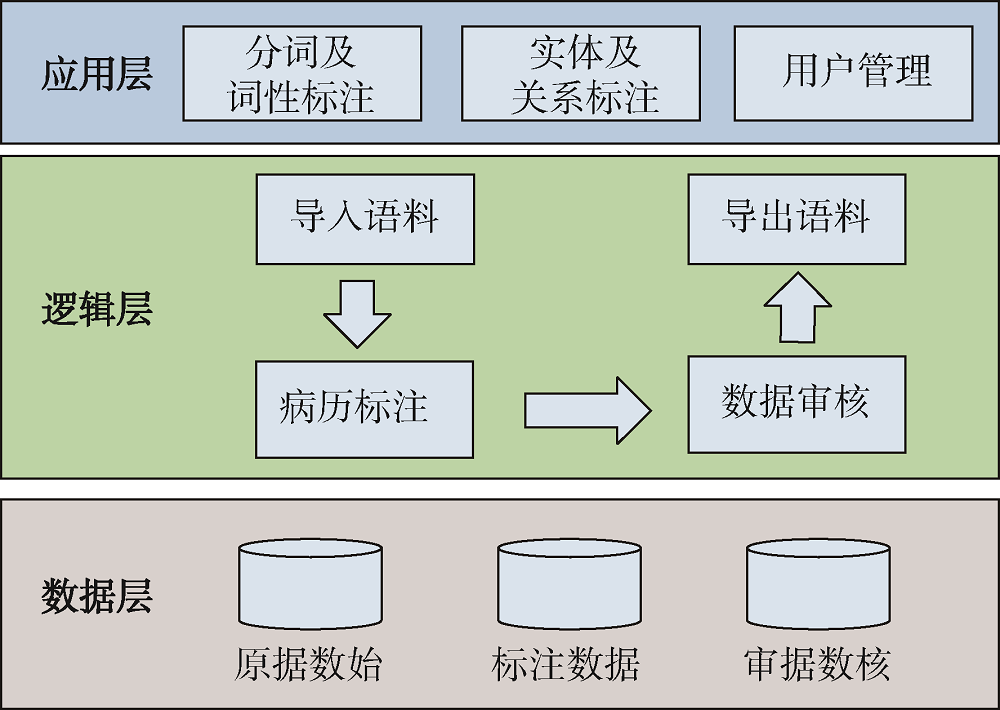
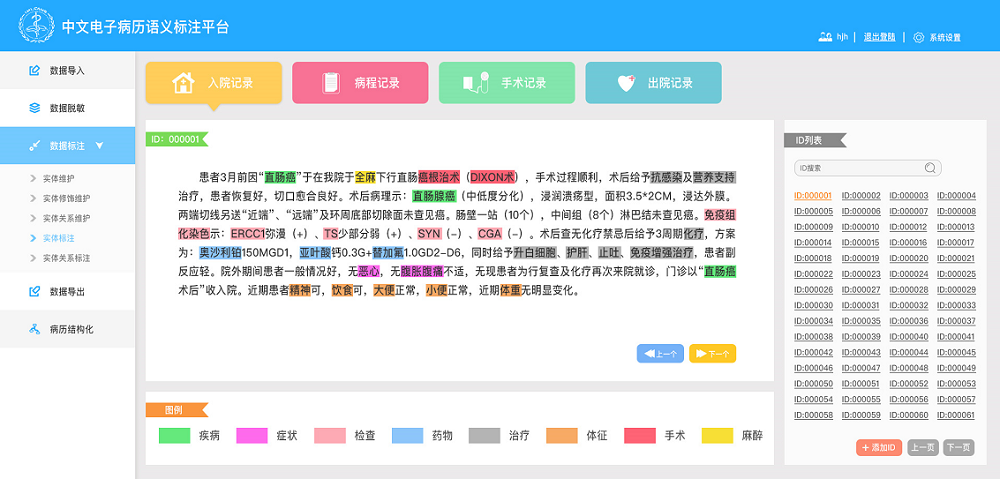
[Objective] This paper studies the annotation method for Chinese electronic medical records, aiming to improve the processing of massive clinical texts and clinical knowledge discovery. [Methods] First, we proposed annotation method for Chinese e-medical records, and constructed a visual interactive platform. Then, based on the word and phrase features of these records, we identified the medical name entities with natural language processing and machine learning approaches. [Results] A total of 700 annotated records were obtained, and the overall F value of the Pipeline-based annotation method reached 0.8772, which was 32.9% higher than those based on the original medical records. [Limitations] Since the electronic medical record contains sensitive privacy information, this study was conducted with open dataset, and the corpus size was limited. [Conclusions] The Chinese electronic medical record annotation method and platform constructed in this study could effectively process clinical texts, and the association of medical knowledge.
Yetisgen M, Vanderwende L. Automatic Identification of Substance Abuse from Social History in Clinical Text [C]// Proceedings of the 16th Conference on Artificial Intelligence in Medicine. 2017: 171-181.
[2]
Brisimi T S, Xu T, Wang T , et al. Predicting Chronic Disease Hospitalizations from Electronic Health Records: An Interpretable Classification Approach[J]. Proceedings of the IEEE, 2018,106(4):690-707.
[3]
Karakurt G, Patel V, Whiting K , et al. Mining Electronic Health Records Data: Domestic Violence and Adverse Health Effects[J]. Journal of Family Violence, 2017,32(1):79-87.
[4]
Caillet C, Sichanh C, Assemat G , et al. Role of Medicines of Unknown Identity in Adverse Drug Reaction-Related Hospitalizations in Developing Countries: Evidence from a Cross-Sectional Study in a Teaching Hospital in the Lao People’s Democratic Republic[J]. Drug Safety, 2017,40(9):809-821.
[5]
Skeppstedt M, Kvist M, Nilsson G H , et al. Automatic Recognition of Disorders, Findings, Pharmaceuticals and Body Structures from Clinical Text: An Annotation and Machine Learning Study[J]. Journal of Biomedical Informatics, 2014,49:148-158.
[6]
Bates D W, Saria S, Ohno-Machado L , et al. Big Data in Health Care: Using Analytics to Identify and Manage High-Risk and High-Cost Patients[J]. Health Affairs, 2014,33(7):1123-1131.
[7]
Zhou X, Peng Y, Liu B . Text Mining for Traditional Chinese Medical Knowledge Discovery: A Survey[J]. Journal of Biomedical Informatics, 2010,43(4):650-660.
[8]
Leaman R, Khare R, Lu Z . Challenges in Clinical Natural Language Processing for Automated Disorder Normalization[J]. Journal of Biomedical Informatics, 2015,57:28-37.
( Yang Jinfeng, Yu Qiubin, Guan Yi , et al. An Overview of Research on Electronic Medical Record Oriented Named Entity Recognition and Entity Relation Extraction[J]. Acta Automatica Sinica, 2014,40(8):1537-1562.)
doi: 10.3724/SP.J.1004.2014.01537
( Xia Lixin, Chen Chen, Wang Zhongyi . Research on Knowledge Discovery Framework of Internet Resource Based on Multi-Dimensional Aggregation[J]. Information Science, 2016,34(5):3-8.)
( Wang Ying, Wu Zhenxin, Xie Jing . Review on Semantic Retrieval System for Scientific Literature[J]. New Technology of Library and Information Service, 2015(5):1-7.)
( Yang Rui, Tang Yijie, Liu Yi , et al. Research on the Application of Semantic Open Interface Under Knowledge Service Environment[J]. Library and Information Service, 2014,58(4):99-104.)
[13]
Reinsel D, Gantz J, Rydning J . Data Age 2025: The Evolution of Data to Life-Critical Don’t Focus on Big Data; Focus on Data That’s Big[R]. IDC White Paper, 2017.
Mack R, Mukherjea S, Soffer A , et al. Text Analytics for Life Science Using the Unstructured Information Management Architecture[J]. IBM Systems Journal, 2004,43(3):490-515.
[19]
Savova G K, Masanz J J, Ogren P V , et al. Mayo Clinical Text Analysis and Knowledge Extraction System (cTAKES): Architecture, Component Evaluation and Applications[J]. Journal of the American Medical Informatics Association, 2010,17(5):507-513.
[20]
Savova G K, Tseytlin E, Finan S , et al. DeepPhe: A Natural Language Processing System for Extracting Cancer Phenotypes from Clinical Records[J]. Cancer Research, 2017,77(21):e115-e118.
[21]
Penn Treebank. Alphabetical List of Part-of-Speech Tags Used in the Penn Treebank Project[EB/OL]. [ 2018- 06- 19]. .
[22]
Tsuruoka Y. GENIA Tagger[EB/OL]. [ 2018- 06- 19]. .
[23]
Bodenreider O . The Unified Medical Language System (UMLS): Integrating Biomedical Terminology[J]. Nucleic Acids Research, 2004,32(S1):267-270.
[24]
Gonzalezhernandez G, Sarker A , O’Connor K, et al. Capturing the Patient’s Perspective: A Review of Advances in Natural Language Processing of Health-Related Text[J]. Yearbook of Medical Informatics, 2017,26(1):214-227.
[25]
Uzuner Ö, South B R, Shen S , et al. 2010 i2b2/VA Challenge on Concepts, Assertions, and Relations in Clinical Text[J]. Journal of the American Medical Informatics Association, 2011,18(5):552-556.
( Yang Jinfeng, Guan Yi, He Bin , et al. Corpus Construction for Named Entities and Entity Relations on Chinese Electronic Medical Records[J]. Journal of Software, 2016,27(11):2725-2746.)
[27]
He B, Dong B, Guan Y , et al. Building a Comprehensive Syntactic and Semantic Corpus of Chinese Clinical Texts[J]. Journal of Biomedical Informatics, 2017,69:203-217.
( Qu Chunyan, Guan Yi, Yang Jinfeng , et al. The Construction of Annotated Corpora of Named Entities for Chinese Electronic Medical Records[J]. Chinese High Technology Letters, 2015,25(2):143-150.)
[29]
Rama T, Brekke P, Nytrø Ø, et al. Iterative Development of Family History Annotation Guidelines Using a Synthetic Corpus of Clinical Text [C]// Proceedings of the 9th International Workshop on Health Text Mining and Information Analysis. 2018: 111-121.
[30]
Knowledge Graph and Semantic Computing. Language, Knowledge, and Intelligence [C]//Proceedings of the 2nd China Conference on Knowledge Graph and Semantic Computing. Springer, 2018.
[31]
CIPS. CCKS 2018: China Conference on Knowledge Graph and Semantic Computing[EB/OL]. [ 2018- 12- 20]. .
[32]
CIPS. CHIP 2018: The 4th China Conference on Health Information Processing[EB/OL]. [ 2018- 12- 20]. .
[33]
Lafferty J, McCallum A, Pereira F C N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data [C]// Proceedings of the 18th International Conference on Machine Learning. 2001: 282-289.
[34]
Pustejovsky J, Stubbs A . Natural Language Annotation for Machine Learning: A Guide to Corpus-Building for Applications[M]. O’Reilly Media, 2012.
[35]
Trivedi G, Pham P, Chapman W W , et al. NLPReViz: An Interactive Tool for Natural Language Processing on Clinical Text[J]. Journal of the American Medical Informatics Association, 2017,25(1):81-87.
[36]
Shellum J L, Freimuth R R, Peters S G , et al. Knowledge as a Service at the Point of Care[J]. AMIA Annual Symposium Proceedings, 2016: 1139-1148.