Detecting Topics of Group Chats with Multiple Strategies
Wu Xu1,2,3(),Chen Chunxu1,2
1Key Laboratory of Trustworthy Distributed Computing and Service (BUPT), Ministry of Education, Beijing 100876, China 2School of Cyberspace Security, Beijing University of Posts and Telecommunications, Beijing 100876, China 3Beijing University of Posts and Telecommunications Library, Beijing 100876, China
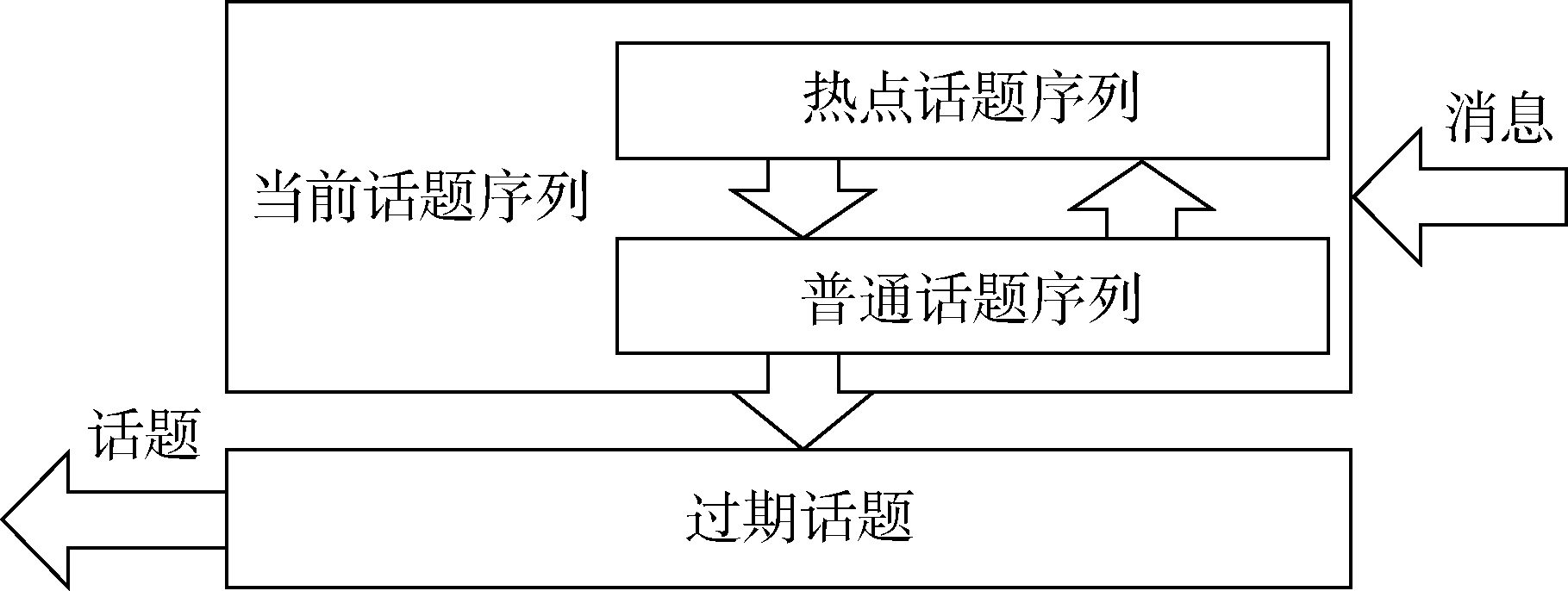
[Objective] This paper tries to detect topics of continuous group chats with variou types of message, aiming to address the topic entanglement issue of group chats, and reduce the influence of sparse text features on clustering. [Methods] We proposed a detection model for group chat topics based on multi-strategies. This model solves topic crossover issue with topic sequences, and improves clustering results with data on users, time, and types of messages. [Results] We examined our model with plain texts of three group chats. The new method’s F value was 2.9%, 6.1% and 3.0% higher than those of the existing algorithms. The speed of our model is about 27.6%, 32.1% and 47.1% faster. This method also processed mixed types of data that cannot be handled by traditional algorithms, and the speed was improved by about 29.4%, 27.1%, and 22.5% respectively. [Limitations] We do not fully utilize the text features of group chat message and set too many thresholds for the algorithm. [Conclusions] The proposed method could identify group chat topics, and improve the efficiency of public opinion analysis.
吴旭,陈春旭. 基于多策略的群聊话题检测技术*[J]. 数据分析与知识发现, 2021, 5(5): 1-9.
Wu Xu,Chen Chunxu. Detecting Topics of Group Chats with Multiple Strategies. Data Analysis and Knowledge Discovery, 2021, 5(5): 1-9.
(China Internet Network Information Center. The 44th China Statistical Report on Internet Development[R/OL].(2019-08-30).[2020-04-10]. https://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201908/t20190830_70800.htm.)
[2]
Uthus D C, Aha D W. Multiparticipant Chat Analysis: A Survey[J]. Artificial Intelligence, 2013, 199-200:106-121.
[3]
Onan A, Koruko$\check{a}$lu S, Bulut H. Ensemble of Keyword Extraction Methods and Classifiers in Text Classification[J]. Expert Systems with Applications: An International Journal, 2016,57(C):232-247.
doi: 10.1016/j.eswa.2016.03.045
[4]
Xie F, Wu X D, Zhu X Q . Efficient Sequential Pattern Mining with Wildcards for Keyphrase Extraction[J]. Knowledge Based Systems, 2017,115:27-39.
doi: 10.1016/j.knosys.2016.10.011
[5]
Kang Y B, Haghigh P D, Burstein F . TaxoFinder: A Graph-based Approach for Taxonomy Learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2016,28(2):524-536.
doi: 10.1109/TKDE.2015.2475759
[6]
Sanchez-Pi N, Martí L, Garcia A C B. Improving Ontology-based Text Classification: An Occupational Health and Security Application[J]. Journal of Applied Logic, 2016,17(C):48-58.
doi: 10.1016/j.jal.2015.09.008
[7]
Saleh A I, Al Rahmawy M F, Abulwafa A E. A Semantic Based Web Page Classification Strategy Using Multi-layered Domain Ontology[J]. World Wide Web, 2017,20(5):939-993.
doi: 10.1007/s11280-016-0415-z
[8]
Wu D Z, Zhu H, Li G L , et al. An Efficient Wikipedia Semantic Matching Approach to Text Document Classification[J]. Information Sciences: An International Journal, 2017,393(C):15-28.
doi: 10.1016/j.ins.2017.02.009
[9]
Agathangelou P, Katakis I, Koutoulakis I , et al. Learning Patterns for Discovering Domain-oriented Opinion Words[J]. Knowledge and Information Systems, 2018,55(1):45-77.
doi: 10.1007/s10115-017-1072-y
[10]
Bandhakavi A, Wiratunga N, Padmanabhan D , et al. Lexicon Based Feature Extraction for Emotion Text Classification[J]. Pattern Recognition Letters, 2017,93:133-142.
doi: 10.1016/j.patrec.2016.12.009
[11]
Manek A S, Shenoy P D, Mohan M C , et al. Aspect Term Extraction for Sentiment Analysis in Large Movie Reviews Using Gini Index Feature Selection Method and SVM Classifier[J]. World Wide Web, 2017,20(2):135-154.
doi: 10.1007/s11280-015-0381-x
[12]
Chaturvedi I, Ong Y S, Tsang I W , et al. Learning Word Dependencies in Text by Means of a Deep Recurrent Belief Network[J]. Knowledge-Based Systems, 2016,108(C):144-154.
doi: 10.1016/j.knosys.2016.07.019
[13]
Tommasel A, Godoy D . Short-text Feature Construction and Selection in Social Media Data: A Survey[J]. Artificial Intelligence Review, 2018,49(3):301-338.
doi: 10.1007/s10462-016-9528-0
[14]
Pavlinek M, Podgorelec V . Text Classification Method Based on Self-training and LDA Topic Models[J]. Expert Systems with Applications: An International Journal, 2017,80(C):83-93.
doi: 10.1016/j.eswa.2017.03.020
[15]
Qin Z C, Cong Y H, Wan T . Topic Modeling of Chinese Language Beyond a Bag-of-words[J]. Computer Speech and Language, 2016,40(C):60-78.
doi: 10.1016/j.csl.2016.03.004
[16]
Zhang H, Zhong G Q . Improving Short Text Classification by Learning Vector Representations of Both Words and Hidden Topics[J]. Knowledge-Based Systems, 2016,102(C):76-86.
doi: 10.1016/j.knosys.2016.03.027
[17]
Zuo Y, Zhao J C, Xu K . Word Network Topic Model: A Simple but General Solution for Short and Imbalanced Texts[J]. Knowledge and Information Systems, 2016,48(2):379-398.
doi: 10.1007/s10115-015-0882-z
[18]
Pinheiro R H W, Cavalcanti G D C, Tsang I R. Combining Dissimilarity Spaces for Text Categorization[J]. Information Sciences: An International Journal, 2017, 406-407:87-101.
[19]
Elnahrawy E. Log-based Chat Room Monitoring Using Text Categorization: A Comparative Study[C]// Proceedings of the 2002 International Conference on Information and Knowledge Sharing. 2002.
[20]
Özyurt Ö, Köse C . Chat Mining: Automatically Determination of Chat Conversations’ Topic in Turkish Text Based Chat Mediums[J]. Expert Systems with Applications, 2010,37(12):8705-8710.
doi: 10.1016/j.eswa.2010.06.053
[21]
Adams P H, Martell C H. Topic Detection and Extraction in Chat[C]// Proceedings of the 6th International Conference on Semantic Computing, 2008: 581-588.
[22]
Wang L D, Oard D W. Context-based Message Expansion for Disentanglement of Interleaved Text Conversations[C]// Proceedings of the 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics. 2009: 200-208.
( Li Tiancai, Wang Bo, Xi Yaoyi. Conversation Extraction in Short Text Message Streams Based on Multiple Strategies[J]. Application Research of Computers, 2016,33(4):997-1002.)
( Huang Jiuming, Wu Quanyuan, Liu Chunyang, et al. Unsupervised Conversation Extraction in Short Text Message Streams[J]. Journal of Software, 2012,23(4):735-747.)
[25]
Ding Y X, Meng X J, Chai G R, et al. User Identification for Instant Messages[C]// Proceedings of the 18th International Conference on Neural Information Processing. 2011: 11-13.
[26]
Köse C, Özyurt Ö, İkibaş C. A Comparison of Textual Data Mining Methods for Sex Identification in Chat Conversations[C]// Proceedings of the 4th Asia Conference on Information Retrieval Technology. 2008: 638-643.
[27]
Shen D, Yang Q, Sun J T, et al. Thread Detection in Dynamic Text Message Streams[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2006: 35-42.