1Economic and Technical College, Anhui Agricultural University, Hefei 231200, China 2School of Management, Hefei University of Technology, Hefei 230009, China 3Key Laboratory of Process Optimization & Intelligent Decision-Making, Ministry of Education, Hefei University of Technology, Hefei 230009, China
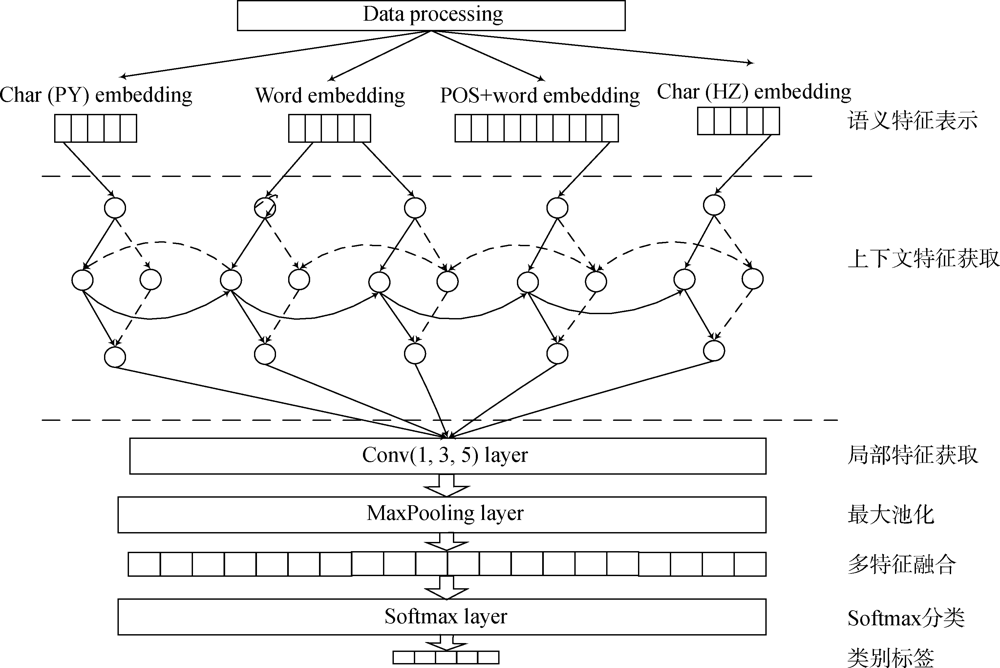
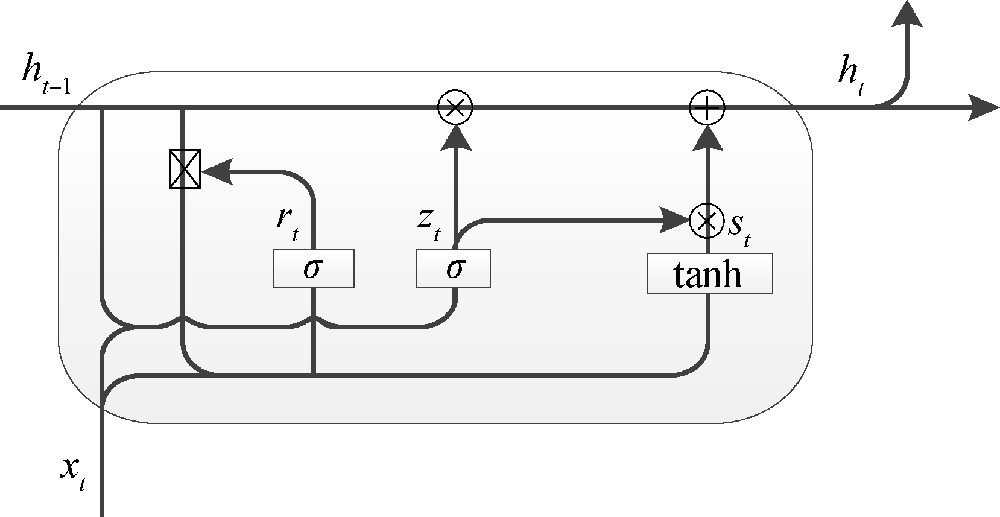
[Objective] This paper proposes a new classification model for Chinese texts, aiming to address the issues of weak structure, spelling errors or homonyms in the texts. [Methods] We constructed a multi-feature fusion method based on the traditional fusion features model for text classification. Then, we combined word level features, part of speech feature extension, the Chinese character features and the Pinyin letters to create multi-feature semantic representation. Third, we introduced the new multi-semantic characteristics into the BiGRU to obtain the context semantics, which were processed with the multi-channel CNN to generate the main features. Finally, we merged these features for the softmax layer to finish the classification tasks, and predicted the required category labels. [Results] The accuracy of our multi-feature fusion model reached 83.3% and 91.1% with two datasets, which was 7% higher than the existing model. [Limitations] More research is needed to examine the model with larger datasets. [Conclusions] The proposed model could effectively finish the Chinese text classification tasks.
王艳, 王胡燕, 余本功. 基于多特征融合的中文文本分类研究*[J]. 数据分析与知识发现, 2021, 5(10): 1-14.
Wang Yan, Wang Huyan, Yu Bengong. Chinese Text Classification with Feature Fusion. Data Analysis and Knowledge Discovery, 2021, 5(10): 1-14.
(Wu Jiao, Hong Caifeng, Gu Yongchun, et al. Class-wise Nearest Neighbor Dictionary based Linear Regression Model for Text Classification[J/OL]. Computer Engineering. [2021-06-18]. https://doi.org/10.19678/j.issn.1000-3428.0058692.)
(Fang Qiulian, Wang Peijin, Sui Yang, et al. Parameter Optimization of Text Feature Vector of Naïve Bayesian Classifier[J]. Journal of Jilin University (Science Edition), 2019, 57(6): 1479-1484.)
[3]
Kim Y. Convolutional Neural Networks for Sentence Classification [C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. 2014: 1746-1751.
[4]
Kalchbrenner N, Grefenstette E, Blunsom P. A Convolutional Neural Network for Modelling Sentences [C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. 2014: 655-665.
[5]
Johnson R, Zhang T. Deep Pyramid Convolutional Neural Networks for Text Categorization [C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. 2017: 562-570.
(Wang Haitao, Song Wen, Wang Hui. Text Classification Method Based on Hybrid Model of LSTM and CNN[J]. Journal of Chinese Computer Systems, 2020, 41(6): 1163-1168.)
(Yu Bengong, Zhang Peixing. WPOS-GRU Patent Classification Method Based on Two-channel Feature Fusion[J]. Application Research of Computers, 2020, 37(3): 655-658.)
(He Bo, Ma Jing, Li Chi. Research on Commodity Text Classification Based on Fusion Features[J]. Information Studies: Theory & Application, 2020, 43(11): 162-168.)
(Hu Jiming, Zheng Xiang, Cheng Qikai, et al. Public Opinion Extraction and Focus Presentation in Government Microblog Based on BiLSTM-CRF[J]. Information Studies: Theory & Application, 2021, 44(1): 174-179.)
(Zhao Yuxiao, Hua Bolin. Research on Topic Modeling of China’s Provincial Scientific and Technology Management Department Based on Official Website Text Data[J]. Information Studies: Theory & Application, 2020, 43(11): 116-121, 168.)
(Chen Zhao, Xu Ruifeng, Gui Lin, et al. Combining Convolutional Neural Networks and Word Sentiment Sequence Features for Chinese Text Sentiment Analysis[J]. Journal of Chinese Information Processing, 2015, 29(6): 172-178.)
(Liu Jingxue, Meng Fanrong, Zhou Yong, et al. Character-Level Convolutional Neural Networks for Short Text Classification[J]. Computer Engineering and Applications, 2019, 55(5): 135-142.)
(Yang Luhui, Liu Guangjie, Zhai Jiangtao, et al. Improved Algorithm for Detection of the Malicious Domain Name Based on the Convolutional Neural Network[J]. Journal of Xidian University, 2020, 47(1): 37-43.)
(Nie Weimin, Chen Yongzhou, Ma Jing. A Text Vector Representation Model Merging Multi-Granularity Information[J]. Data Analysis and Knowledge Discovery, 2019, 3(9): 45-52.)
(Liu Longfei, Yang Liang, Zhang Shaowu, et al. Convolutional Neural Networks for Chinese Micro-blog Sentiment Analysis[J]. Journal of Chinese Information Processing, 2015, 29(6): 159-165.)
(Yu Bengong, Zhang Lianbin. Chinese Short Text Classification Based on CP-CNN[J]. Application Research of Computers, 2018, 35(4): 1001-1004.)
[19]
Tian J, Zhu D J, Long H. Chinese Short Text Multi-Classification Based on Word and Part-of-Speech Tagging Embedding [C]//Proceedings of the 2018 International Conference on Algorithms, Computing and Artificial Intelligence. 2018: 62.
[20]
Kalarani P, Selva Brunda S. Sentiment Analysis by POS and Joint Sentiment Topic Features Using SVM and ANN[J]. Soft Computing, 2019, 23(16): 7067-7079.
doi: 10.1007/s00500-018-3349-9
(He Hongye, Zheng Jin, Zhang Zuping. Text Sentiment Analysis Combined with Part of Speech Features and Convolutional Neural Network[J]. Computer Engineering, 2018, 44(11): 209-214, 221.)
[22]
Harikrishna D M, Rao K S. Classification of Children Stories in Hindi Using Keywords and POS Density[C]// Proceedings of 2015 International Conference on Computer, Communication and Control (IC4). 2015. DOI: 10.1109/IC4.2015.7375666.
doi: 10.1109/IC4.2015.7375666
(Lu Yonghe, Wang Hongbin. Feature Weighting Method Affected by Part of Speech in Text Classification[J]. New Technology of Library and Information Service, 2015(4): 18-25.)
[24]
Jiang T, Yu H Z, Zhang B. Tibetan Text Classification Using Distributed Representations of Words [C]//Proceedings of International Conference on Asian Language Processing. 2015: 123-126.
[25]
Rohit, Singh A K. Accuracy Enhancement of Collaborative Filtering Recommender System for Blogs Using Latent Semantic Indexing[C]// Proceedings of 2017 Conference Information and Communication Technology. DOI: 10.1109/INFOCOMTECH.2017.8340646.
doi: 10.1109/INFOCOMTECH.2017.8340646
[26]
Dalaorao G A, Sison A M, Medina R P. Integrating Collocation as TF-IDF Enhancement to Improve Classification Accuracy [C]//Proceedings of the 13th IEEE International Conference on Telecommunication Systems Services and Applications. 2019: 282-285.
[27]
Saikia L P, Singh S. Feature Extraction and Performance Measure of Requirement Engineering (RE) Document Using Text Classification Technique [C]//Proceedings of the 4th International Conference on Recent Advances in Information Technology. 2018: 1-6.
[28]
Cheng K F, Yue Y N, Song Z W, et al. Sentiment Classification Based on Part-of-Speech and Self-Attention Mechanism[J]. IEEE Access, 2020, 8: 16387-16396.
doi: 10.1109/Access.6287639
[29]
Bektaş Y, Özel S A. The Effect of POS Tag Information on Sentence Boundary Detection in Turkish Texts [C]//Proceedings of 2018 Innovations in Intelligent Systems and Applications Conference (ASYU). IEEE, 2018: 1-5.
[30]
Hoesen D, Purwarianti A. Investigating Bi-LSTM and CRF with POS Tag Embedding for Indonesian Named Entity Tagger [C]//Proceedings of 2018 International Conference on Asian Language Processing. 2018: 35-38.
[31]
Yuwana R S, Suryawati E, Pardede H F. On Empirical Evaluation of Deep Architectures for Indonesian POS Tagging Problem [C]//Proceedings of 2018 International Conference on Computer Control Informatics and Its Applications. 2018: 204-208.
(Cheng Bin, Shi Shuicai, Du Yuncheng, et al. Keyword Extraction for Journals Based on Part-of-Speech and BiLSTM-CRF Combined Model[J]. Data Analysis and Knowledge Discovery, 2021, 5(3): 101-108.)
[33]
Huang M L, Qian Q, Zhu X Y, et al. Encoding Syntactic Knowledge in Neural Networks for Sentiment Classification[J]. ACM Transactions on Information Systems, 2017(3): No.26.
[34]
Shiguihara-Juárez P, Murrugarra-Llerena N, Andrade Lopes A D. POS-Tags Features for Protein-Protein Interaction Extraction from Biomedical Articles[C]// Proceedings of 2018 IEEE 25th International Conference on Electronics, Electrical Engineering and Computing (INTERCON). DOI: 10.1109/INTERCON.2018.8526370.
doi: 10.1109/INTERCON.2018.8526370
(Wang Yi, Shen Yang, Dai Yueming. Sentiment Analysis of Texts Based on Fine-Grained Multi-Channel Convolutional Neural Network[J]. Computer Engineering, 2020, 46(5): 102-108.)
[36]
Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and Their Compositionality [C]// Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2. 2013: 3111-3119.