|
|
|
| Optimizing LDA Model with Various Topic Numbers: Case Study of Scientific Literature |
Wang Tingting1,2( ), Han Man1,2, Wang Yu1 ), Han Man1,2, Wang Yu1 |
1(School of Statistics, Huaqiao University, Xiamen 361021, China)
2(Center for Modern Applied Statistics and Large Data Research, Huaqiao University, Xiamen 361021,China) |
|
|
|
|
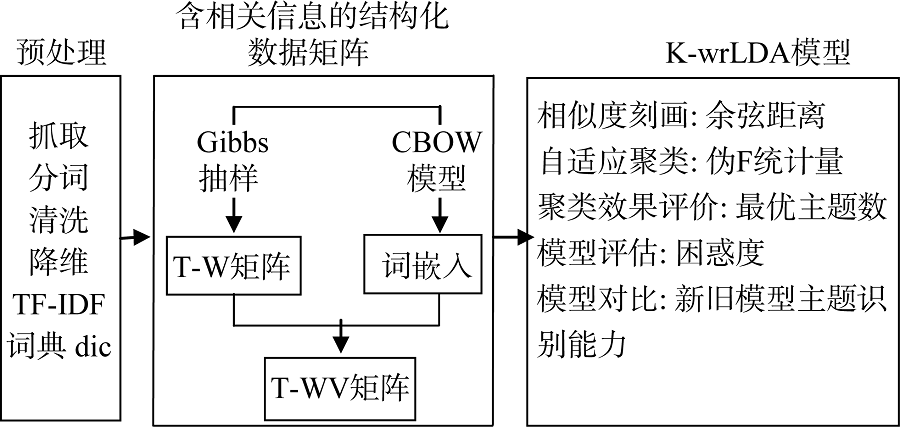
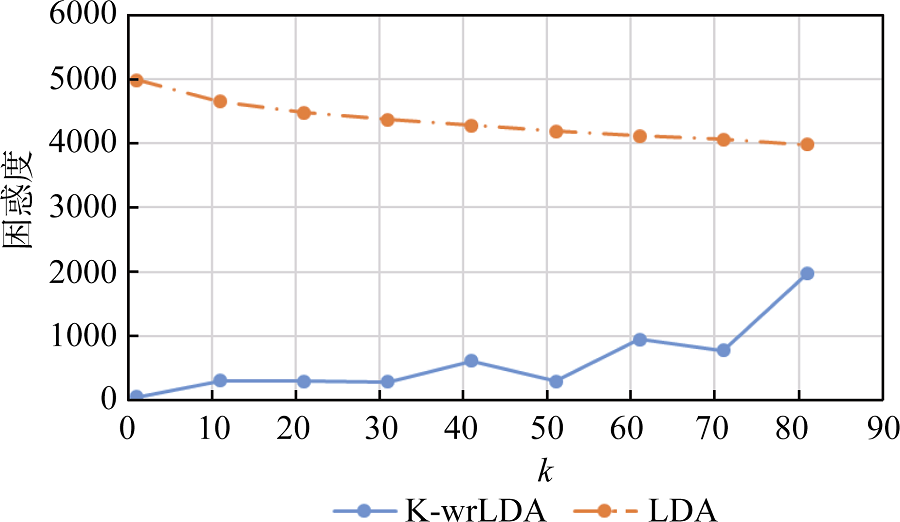
Abstract [Objective] This paper proposes a K-wrLDA model based on adaptive clustering, aiming to improve the subject recognition ability of traditional LDA model, and identify the optimal number of selected topics. [Methods] First, we used the LDA and word2vec models to construct the T-WV matrix containing the probability information and the semantic relevance of the subject words. Then, we selected the number of topics based on the evaluation of clustering effects and the pseudo-F statistic. Finally, we compared the topic identification results of the proposed model with the old ones. [Results] The optimal number of topics was 33 for the proposed model, which also has lower level of perplexity than the traditional ones. [Limitations] The sample size needs to be expanded. [Conclusions] The proposed model, which has better recognition rate than the traditional LDA model, could also calculate the optimal number of topics. The new model may be applied to process large corpus in various fields.
|
|
Received: 20 July 2017
Published: 05 February 2018
|
|
|
| [1] |
Blei D M, Ng A Y, Jordan M I.Latent Dirichlet Allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
|
| [2] |
Blei D M, Lafferty J D.Correlated Topic Models[J]. Advances in Neural Information Processing Systems, 2005, 18: 113-120.
|
| [3] |
关鹏, 王曰芬, 傅柱.不同语料下基于 LDA 主题模型的科学文献主题抽取效果分析[J]. 图书情报工作, 2016, 60(2): 112-121.
|
| [3] |
(Guan Peng, Wang Yuefen, Fu Zhu.Effect Analysis of Scientific Literature Topic Extraction Based on LDA Topic Model with Different Corpus[J].Library and Information Service, 2016, 60(2): 112-121.)
|
| [4] |
Griffiths T L, Steyvers M.Finding Scientific Topics[J]. Proceedings of the National Academy of Sciences of the United States of America, 2004, 101(S1): 5228-5235.
doi: 10.1073/pnas.0307752101
|
| [5] |
石晶, 胡明, 石鑫, 等. 基于LDA模型的文本分割[J]. 计算机学报, 2008, 31(10): 1865-1873.
doi: 10.3321/j.issn:0254-4164.2008.10.022
|
| [5] |
(Shi Jing, Hu Ming, Shi Xin, et al.Text Segmentation Based on LDA Model[J]. Chinese Journal of Computers, 2008, 31(10): 1865-1873.)
doi: 10.3321/j.issn:0254-4164.2008.10.022
|
| [6] |
Hajjem M, Latiri C.Combining IR and LDA Topic Modeling for Filtering Microblogs[J]. Procedia Computer Science, 2017, 112: 761-770.
doi: 10.1016/j.procs.2017.08.166
|
| [7] |
廖列法, 勒孚刚, 朱亚兰. LDA模型在专利文本分类中的应用[J]. 现代情报, 2017, 37(3): 35-39.
doi: 10.3969/j.issn.1008-0821.2017.03.007
|
| [7] |
(Liao Liefa, Le Fugang, Zhu Yalan.The Application of LDA Model in Patent Text Classification[J]. Journal of Modern Information, 2017, 37(3): 35-39.)
doi: 10.3969/j.issn.1008-0821.2017.03.007
|
| [8] |
刘江华. 一种基于kmeans聚类算法和LDA主题模型的文本检索方法及有效性验证[J]. 情报科学, 2017, 35(2): 16-21.
|
| [8] |
(Liu Jianghua.A Text Retrieval Method Based on Kmeans Clustering Algorithm and LDA Topic Model and Its Effectiveness[J]. Information Science, 2017, 35(2): 16-21.)
|
| [9] |
Teh Y, Jordan M, Beal M, et al.Hierarchical Dirichlet Processes[J]. Journal of the American Statistical Association, 2007, 101(476): 1566-1581.
|
| [10] |
颜端武, 陶志恒, 李兰彬. 一种基于HDP模型的主题文献自动推荐方法及应用研究[J]. 情报理论与实践, 2016, 39(1): 128-132.
doi: 10.16353/j.cnki.1000-7490.2016.01.023
|
| [10] |
(Yan Duanwu, Tao Zhiheng, Li Lanbin.A Method of Automatic Recommendation of Subject Documents Based on HDP Model and Its Application[J]. Information Studies: Theory & Application, 2016, 39(1): 128-132.)
doi: 10.16353/j.cnki.1000-7490.2016.01.023
|
| [11] |
唐浩浩, 王波, 席耀一, 等. 基于HDP的无监督微博情感倾向性分析[J]. 信息工程大学学报, 2015, 16(4): 463-469.
doi: 10.3969/j.issn.1671-0673.2015.04.014
|
| [11] |
(Tang Haohao, Wang Bo, Xi Yaoyi, et al.Unsupervised Sentiment Orientation Analysis on Micro-Blogs Based on Hierarchical Dirichlet Processes[J]. Journal of Information Engineering University, 2015, 16(4): 463-469.)
doi: 10.3969/j.issn.1671-0673.2015.04.014
|
| [12] |
曹娟, 张勇东, 李锦涛, 等. 一种基于密度的自适应最优LDA模型选择方法[J]. 计算机学报, 2008, 31(10): 1780-1787.
|
| [12] |
(Cao Juan, Zhang Yongdong, Li Jintao, et al.A Method of Adaptively Selecting Best LDA Model Based on Density[J]. Chinese Journal of Computers, 2008, 31(10): 1780-1787.)
|
| [13] |
关鹏, 王曰芬. 科技情报分析中LDA主题模型最优主题数确定方法研究[J]. 现代图书情报技术, 2016(9): 42-49.
|
| [13] |
(Guan Peng, Wang Yuefen.Research on the Method of Determining the Optimum Topic Number of LDA Topic Model in Scientific and Technical Information Analysis[J]. New Technology of Library and Information Service, 2016(9): 42-49.)
|
| [14] |
茆诗松, 王静龙, 濮晓龙. 高等数理统计[M]. 北京: 高等教育出版社, 2006: 446-449.
|
| [14] |
(Mao Shisong, Wang Jinglong, Pu Xiaolong.Advanced Mathematical Statistics [M]. Beijing: Higher Education Press, 2006: 446-449.)
|
| [15] |
Hinton G E.Learning Distributed Representations of Concepts[C]//Proceedings of the 8th Annual Conference of the Cognitive Science Society.1986.
|
| [16] |
Mikolov T, Sutskever I, Chen K, et al.Distributed Representations of Words and Phrases and Their Compositionality[C]//Proceedings of the Neural Information Processing Systems Conference. 2013.
|
| [17] |
MacQueen J. Some Methods for Classification and Analysis of Multivariate Observations[C]//Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, 1967.
|
| [18] |
Wei X, Croft W B.LDA-based Document Models for Ad-Hoc Retrieval[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM, 2006: 178-185.
|
| [19] |
王学民. 应用多元分析[M]. 上海: 上海财经大学出版社, 2003: 217-218.
|
| [19] |
(Wang Xuemin.Applied Multivariate Analysis [M]. Shanghai: Shanghai University of Finance and Economics Press, 2003: 217-218.)
|
| [20] |
Heinrich G.Parameter Estimation for Text Analysis[R]. vsonix GmbH + University of Leipzig, 2008: 29-30.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|