|
|
|
| Structural Recognition of Abstracts of Academic Text Enhanced by Domain Bilingual Data |
Liu Jiangfeng1,Feng Yutong1,Liu Liu1,Shen Si2,Wang Dongbo1( ) ) |
1College of Information Management, Nanjing Agricultural University, Nanjing 210095, China
2School of Economics & Management, Nanjing University of Science and Technology, Nanjing 210094, China |
|
|
|
|
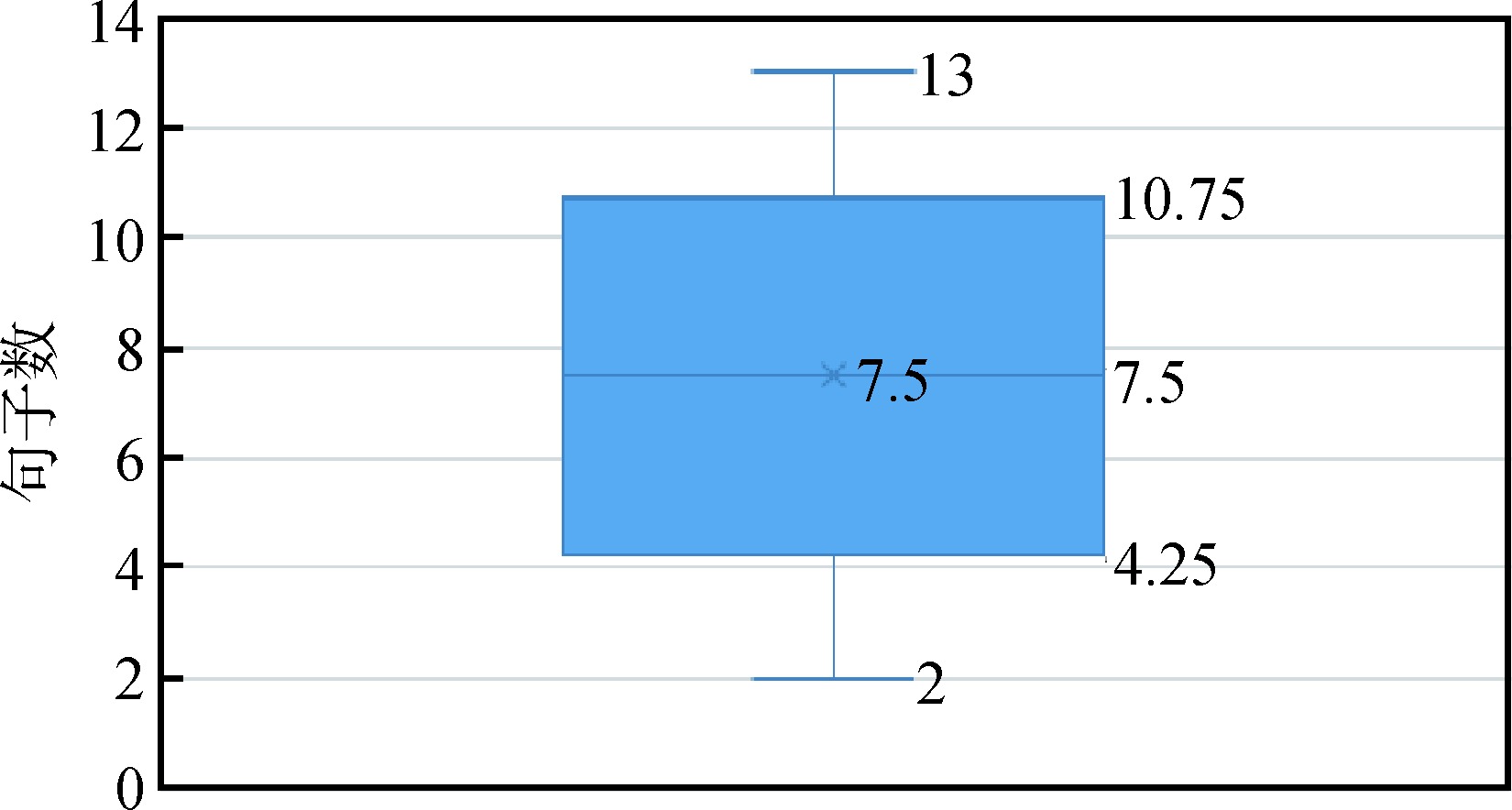
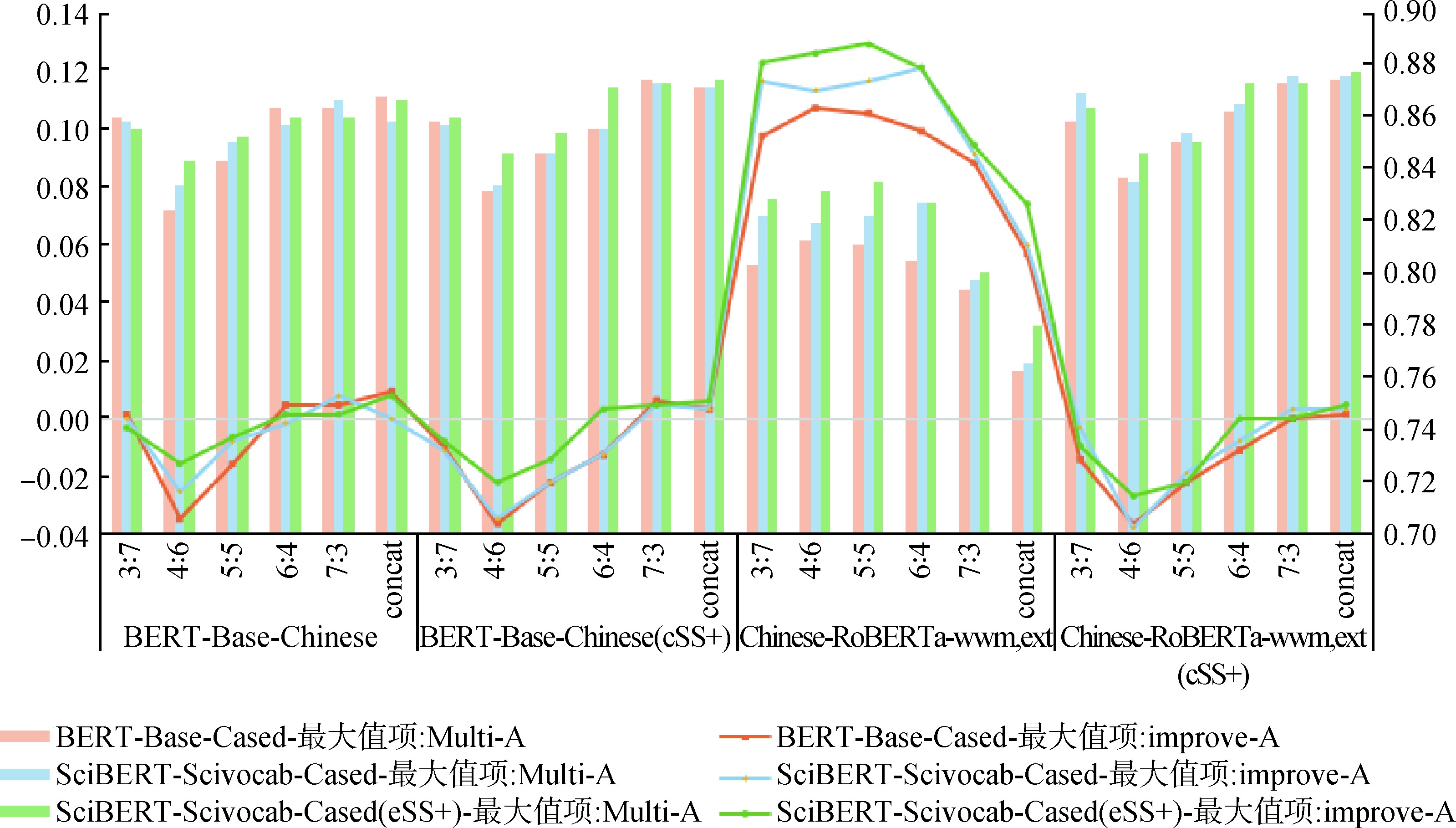
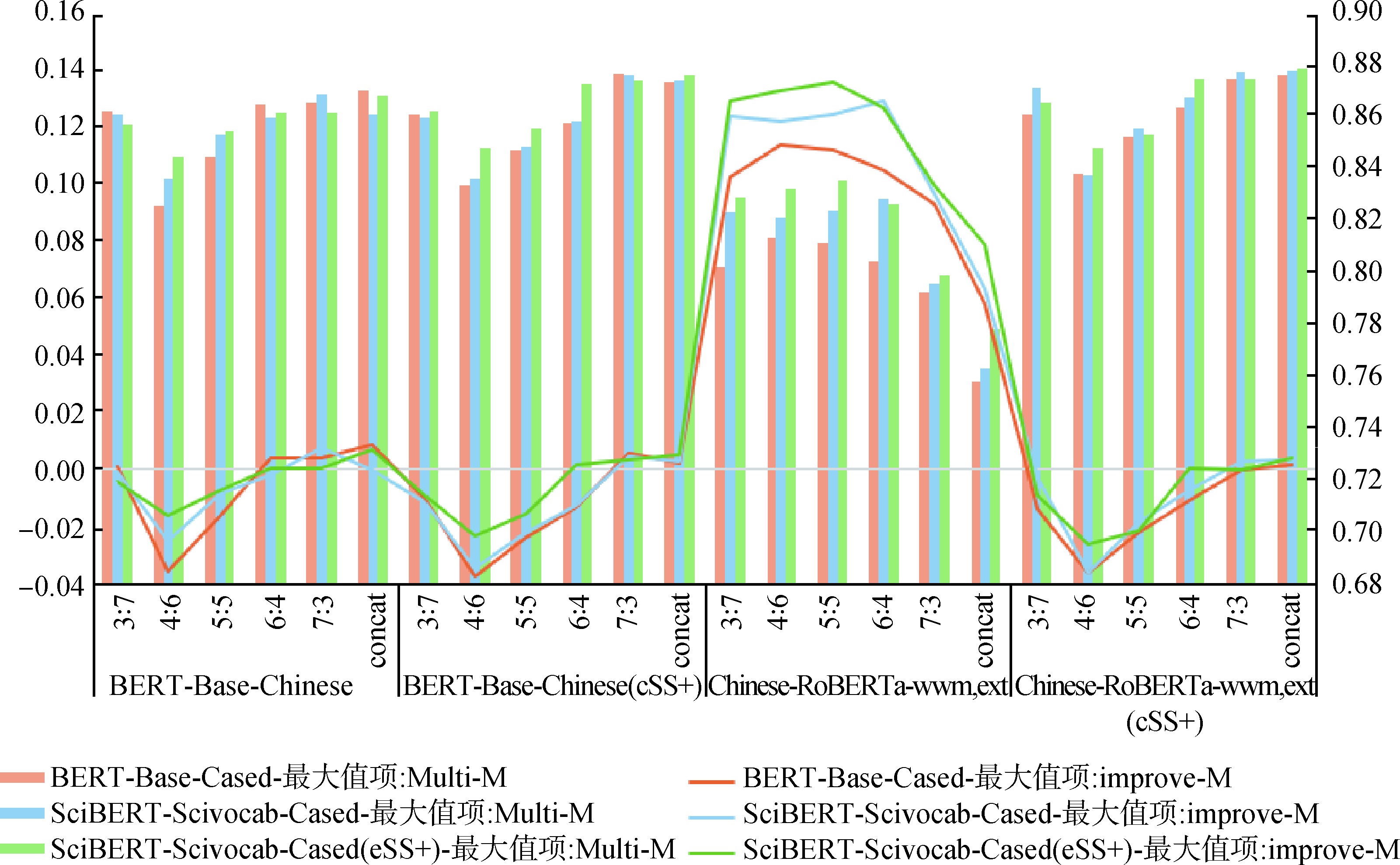
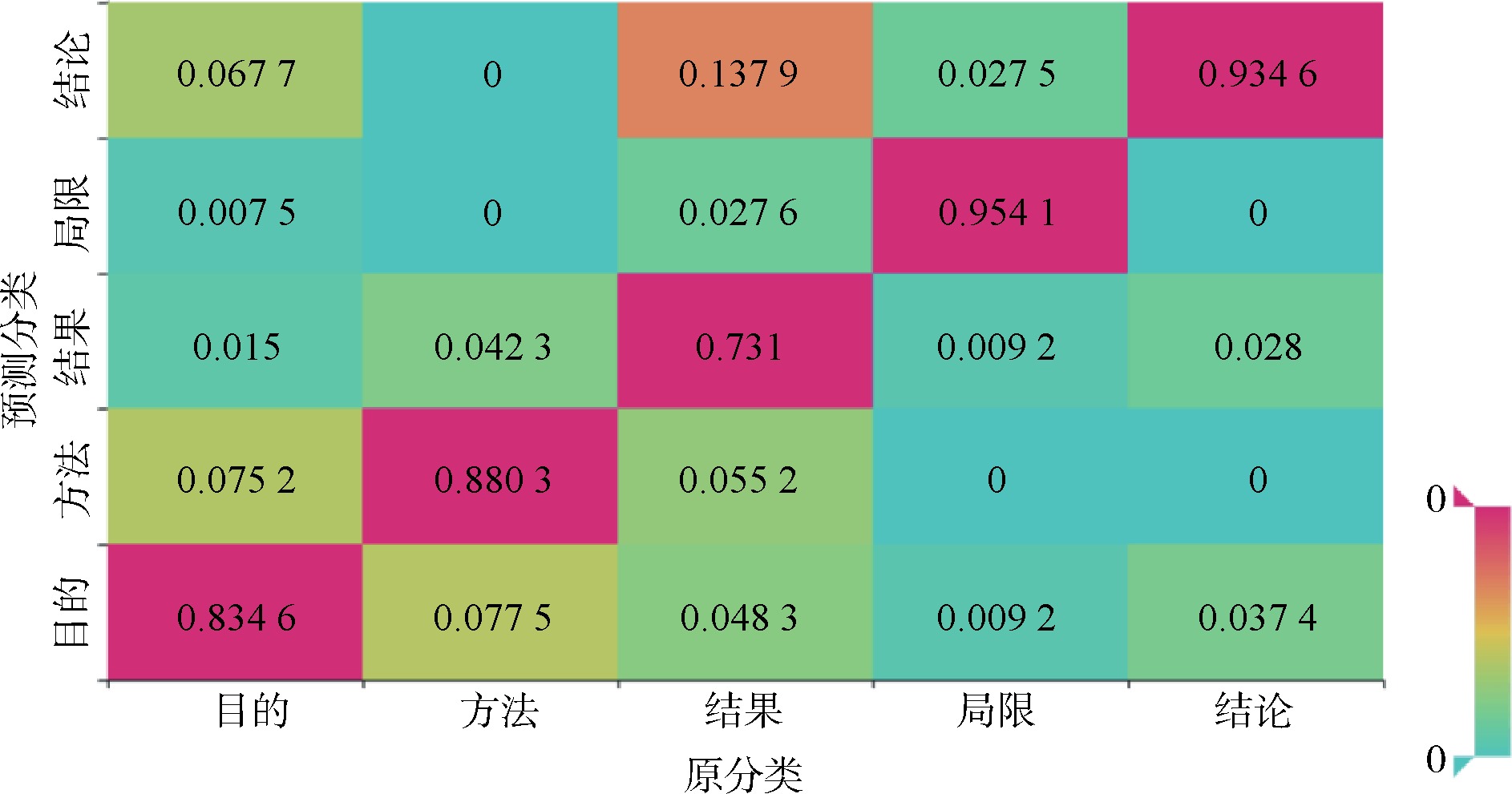
Abstract [Objective] This paper aims to grasp the core content of social science academic literature accurately and improve the structure recognition effect of literature abstracts. [Methods] An experiment was conducted on the bilingual abstract data of several core periodicals in the field of library and information science by using pre-training language model, and an enhanced learning method was proposed by using domain data in the stages of pre-training, fine-tuning and model's output layer. [Results] Enhancement pre-training, fine-tuning, and fusion of bilingual sentence classification probability could improve the F1 values of abstract structure recognition by 1 to 2, 1, and 0.5 to 1 percentage point on single journal data, respectively. [Limitations] Due to limited computing resources, the field bilingual text continued pre-training and performance test were not conducted on the cross-language pre-training model. [Conclusions] This research makes full use of bilingual resources in academic literature and effectively improves the recognition effect of abstract structure, which is of certain significance to quickly understand the content of literature and promote scientific communication.
|
|
Received: 12 May 2022
Published: 08 October 2023
|
|
|
| Fund:National Natural Science Foundation of China(71974094) |
|
Corresponding Authors:
Wang Dongbo,ORCID: 0000-0002-9894-9550,E-mail: db.wang@njau.edu.cn。
|
| [1] |
张智雄, 刘欢, 丁良萍, 等. 不同深度学习模型的科技论文摘要语步识别效果对比研究[J]. 数据分析与知识发现, 2019, 3(12): 1-9.
|
| [1] |
(Zhang Zhixiong, Liu Huan, Ding Liangping, et al. Identifying Moves of Research Abstracts with Deep Learning Methods[J]. Data Analysis and Knowledge Discovery, 2019, 3(12): 1-9.)
|
| [2] |
Swales J M. Research Genres: Explorations and Applications[M]. Cambridge, UK: Cambridge University Press, 2004.
|
| [3] |
Beltagy I, Lo K, Cohan A. SciBERT: A Pretrained Language Model for Scientific Text[OL]. arXiv Preprint, arXiv: 1903.10676.
|
| [4] |
Lee J, Yoon W, Kim S, et al. BioBERT: A Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining[J]. Bioinformatics, 2020, 36(4): 1234-1240.
doi: 10.1093/bioinformatics/btz682
pmid: 31501885
|
| [5] |
田亮, 李博闻, 章成志. 基于学术论文全文的跨语言研究方法自动分类研究[J]. 图书馆建设, 2022(1): 75-86.
|
| [5] |
(Tian Liang, Li Bowen, Zhang Chengzhi. Classification of Cross-Lingual Research Methods Based on Full-Text Content of Academic Articles[J]. Library Development, 2022(1): 75-86.)
|
| [6] |
张乐, 卫乃兴. 学术论文中篇章性句干的型式和功能研究[J]. 解放军外国语学院学报, 2013, 36(2): 8-15.
|
| [6] |
(Zhang Le, Wei Naixing. Patterns and Functions of Textual Sentence Stems in Research Articles[J]. Journal of PLA University of Foreign Languages, 2013, 36(2): 8-15.)
|
| [7] |
王立非, 刘霞. 英语学术论文摘要语步结构自动识别模型的构建[J]. 外语电化教学, 2017(2): 45-50.
|
| [7] |
(Wang Lifei, Liu Xia. Constructing a Model for the Automatic Identification of Move Structure in English Research Article Abstracts[J]. Technology Enhanced Foreign Language Education, 2017(2): 45-50.)
|
| [8] |
丁良萍, 张智雄, 刘欢. 影响支持向量机模型语步自动识别效果的因素研究[J]. 数据分析与知识发现, 2019, 3(11): 16-23.
|
| [8] |
(Ding Liangping, Zhang Zhixiong, Liu Huan. Factors Affecting Rhetorical Move Recognition with SVM Model[J]. Data Analysis and Knowledge Discovery, 2019, 3(11): 16-23.)
|
| [9] |
赵丹宁, 牟冬梅, 白森. 基于深度学习的科技文献摘要结构要素自动抽取方法研究[J]. 数据分析与知识发现, 2021, 5(7): 70-80.
|
| [9] |
(Zhao Danning, Mu Dongmei, Bai Sen. Automatically Extracting Structural Elements of Sci-Tech Literature Abstracts Based on Deep Learning[J]. Data Analysis and Knowledge Discovery, 2021, 5(7): 70-80.)
|
| [10] |
王末, 崔运鹏, 陈丽, 等. 基于深度学习的学术论文语步结构分类方法研究[J]. 数据分析与知识发现, 2020, 4(6): 60-68.
|
| [10] |
(Wang Mo, Cui Yunpeng, Chen Li, et al. A Deep Learning-Based Method of Argumentative Zoning for Research Articles[J]. Data Analysis and Knowledge Discovery, 2020, 4(6): 60-68.)
|
| [11] |
郭航程, 何彦青, 兰天, 等. 基于Paragraph-BERT-CRF的科技论文摘要语步功能信息识别方法研究[J]. 数据分析与知识发现, 2022, 6(2/3): 298-307.
|
| [11] |
(Guo Hangcheng, He Yanqing, Lan Tian, et al. Identifying Moves from Scientific Abstracts Based on Paragraph-BERT-CRF[J]. Data Analysis and Knowledge Discovery, 2022, 6(2/3): 298-307.)
|
| [12] |
赵旸, 张智雄, 刘欢, 等. 基金项目摘要的语步识别系统设计与实现[J]. 情报理论与实践, 2022, 45(8): 162-168.
|
| [12] |
(Zhao Yang, Zhang Zhixiong, Liu Huan, et al. Design and Implementation of the Move Recognition System for Fund Project Abstract[J]. Information Studies: Theory & Application, 2022, 45(8): 162-168.)
|
| [13] |
宋若璇, 钱力, 杜宇. 基于科技论文中未来工作句集的学术创新构想话题自动生成方法研究[J]. 数据分析与知识发现, 2021, 5(5): 10-20.
|
| [13] |
(Song Ruoxuan, Qian Li, Du Yu. Identifying Academic Creative Concept Topics Based on Future Work of Scientific Papers[J]. Data Analysis and Knowledge Discovery, 2021, 5(5): 10-20.)
|
| [14] |
罗卓然, 蔡乐, 钱佳佳, 等. 学术论文创新贡献句识别研究[J]. 图书情报工作, 2021, 65(12): 93-100.
doi: 10.13266/j.issn.0252-3116.2021.12.009
|
| [14] |
(Luo Zhuoran, Cai Le, Qian Jiajia, et al. Research on the Recognition of Innovative Contribution Sentences of Academic Papers[J]. Library and Information Service, 2021, 65(12): 93-100.)
doi: 10.13266/j.issn.0252-3116.2021.12.009
|
| [15] |
Lo K, Wang L L, Neumann M, et al. S2ORC: The Semantic Scholar Open Research Corpus[OL]. arXiv Preprint, arXiv: 1911.02782.
|
| [16] |
Devlin J, Chang M W, Lee K, et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding[OL]. arXiv Preprint, arXiv: 1810.04805.
|
| [17] |
Liu Y H, Ott M, Goyal N, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach[OL]. arXiv Preprint, arXiv: 1907.11692.
|
| [18] |
Cui Y M, Che W X, Liu T, et al. Pre-Training with Whole Word Masking for Chinese BERT[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3504-3514.
doi: 10.1109/TASLP.2021.3124365
|
| [19] |
Conneau A, Khandelwal K, Goyal N, et al. Unsupervised Cross-Lingual Representation Learning at Scale[OL]. arXiv Preprint, arXiv: 1911.02116.
|
| [20] |
Chi Z W, Dong L, Zheng B, et al. Improving Pretrained Cross-Lingual Language Models via Self-Labeled Word Alignment[OL]. arXiv Preprint, arXiv: 2106.06381.
|
| [21] |
Bird S, Klein E, Loper E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit[M]. O’Reilly Media, Inc., 2009.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|