
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于语义相似度和多属性决策方法的商品信息智能检索模型
[曾子明 , 张李义]
, 张李义]
, 张李义]
|
|


提出一种结合语义检索和多属性决策方法的商品信息检索模型。通过构建语义向量空间进行语义相似度计算,以实现检索结果与顾客查询关键词的语义匹配;同时该模型也采用TOPSIS多属性决策方法对检索到的商品进行效用值计算,从而建立商品内容的比较机制。最后,从准确率、顾客接受度等指标通过实验证实该模型的有效性,能够提高商品信息检索的精准度。
In this paper,a commodity information retrieval model is presented, which integrates semantic retrieval and multi-attribute decision method. Firstly, semantic similarity is computed by constructing semantic vector-space in order to realize the semantic consistency between retrieved result and customer’s query. Besides, TOPSIS method is also utilized to construct the comparison mechanism of commodity by calculating the utility value of each retrieved commodity. Finally, the experiment is conducted in terms of accuracy and customer acceptance rate, and the results verify the effectiveness of the model,which can improve the precision of the commodity information retrieval.
近年来,Internet和Web信息技术的发展促进了电子商务的发展。通过Internet网络,在线购物已逐步走近人们的日常生活中,在电子商务网站上进行购买、销售和执行电子交易的人数正在显著增长。但是,随着电子商务规模的进一步扩大,顾客面对网上海量的商品信息进行择优购买,并不是一件轻松的事情。目前,顾客获取商品信息的主要方式基本上通过公共搜索引擎(如Google、百度等)或在不同的电子商务网站上采用基于关键词等方式进行查找,不仅效率低下,而且有时获取的网页文档内容与所需商品毫不相关。产生该问题的主要原因有以下几种:
(1)传统的信息检索技术不能正确表达语义信息,信息检索以关键词匹配为基础,检索结果经常出现语义偏差现象;
(2)电子商务平台的多样性,相关领域信息的描述没有统一标准,导致信息组织异构特性明显;
(3)没有建立有效的商品评价和比较机制,使得检索结果出现信息过载现象。
为了解决传统信息检索存在的问题,国内外学者提出了基于本体和语义网的Web信息检索方法。文献[1]提出一种基于本体的文档信息检索模型,利用本体方法对文档进行语义自动标记和索引,并开发了文档信息抽取和全文检索的平台。文献[2]则在经典向量空间检索模型的基础上,利用本体和自动标记技术提出一种新颖的语义检索模型。文献[3]中TAP系统采用半自动化技术从自由文本和半结构化数据中抽取知识,在对文档进行语义分析之后,采用自动或人工方式将其转化为语义网文档格式,从而使用结构化知识以提高信息的查准率。文献[4]提出一种基于语义相似度的信息检索算法,利用本体来描述和刻画用户查询及文档等的语义,通过计算概念及属性组成的语义向量来实现语义信息检索。文献[5]提出基于本体的语义标记方法,以本体的知识组织体系为基础,抽取文档的语义向量,为语义检索的智能推理提供基础。
这些方法均能在一定程度上解决信息的语义偏差,实现用户查询与文档信息的语义匹配。但是,商品信息检索在实现一般信息语义检索的基础上,还要求建立有效的商品评价和比较机制,以解决商品信息过载问题,为顾客网上购物提供精准的信息检索和导购服务[ 6]。针对该问题,本文提出一种结合语义检索和多属性决策方法的集成信息检索模型,一方面基于领域本体,通过分别构建查询语义向量和文档语义向量,进行语义相似度计算来实现检索结果与顾客查询的语义匹配;另一方面,检索模型也考虑商品的多属性特征,对检索到的商品从不同方面(例如与商品内容相关的不同性能特征)进行评价和比较,从中筛选出符合顾客购物偏好的商品。因此,该集成模型既考虑语义检索问题,也采取了商品选择与比较机制,从而试图提高商务信息检索的精准度,为顾客购物提供智能化的信息检索服务。
商品信息检索模型的主要任务有以下两方面。
(1)实现商品检索信息与顾客查询的语义匹配,使得检索结果符合顾客的语义需求;
(2)提供检索结果的比较和评价机制,提高检索结果的精准度。
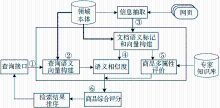
其系统模型结构如图1所示:
 | 图1 智能检索系统结构 |
整个检索过程为:
(1)查询接口的主要任务是实现顾客和检索系统之间的双向通信。一方面,顾客通过查询接口输入查询条件,包括查询的相关概念、概念属性及其取值;另一方面,系统便于收集和分析顾客的当前个人需求,例如查询接口向顾客咨询关于笔记本商品性能的定性需求,要求顾客表达对于多媒体性能、图像显示性能、网络通信性能、接口支持性能等特征的定性需求,并给出需求偏好的权重值。
(2)系统基于领域本体对查询关键词进行分析和语义扩展,并构建查询语义向量。
(3)系统对检索的网页信息进行信息抽取,通过领域本体进行文档语义标记和特征词索引权重计算,构建文档语义向量。
(4)计算查询语义向量和文档语义向量之间的语义相似度,实现文档与查询关键词的语义匹配。
(5)从标记的商品文档中抽取商品相关特征信息,利用系统嵌入的专家知识对商品各个定性性能特征进行评价,并基于多属性决策方法计算商品的效用值。
(6)综合语义相似度和商品效用值计算商品综合评分,最后对检索到的商品进行排序。
本体是一个可共享概念化的显式的规范说明[ 7]。领域本体则是用于描述指定领域知识的一种专门本体,它的提出是获取相关领域的知识,并提供对该领域知识的共同理解,确定该领域内共同认可的概念,并从不同层次的形式化模式上给出这些概念和概念间关系的精确描述[ 8]。在商品信息检索领域中,这样的结构建立了很好的层次知识。为了便于顾客在不同电子商务网站中进行商品检索和比较,首要任务是建立特定领域的本体,以实现商品分类和商品信息模型的构建。对于简单的商务网站,领域本体可以手工建立或从网站内容半自动化获取。然而,对于大型的商务网站,本体的手工构建比较繁琐,一般可以对现有本体进行重用,并在此基础上进行增加或修改,以适应具体应用领域。建立领域本体后,可以基于领域本体从电子商务网站中抽取商品的语义信息。这里,以笔记本电脑为例,利用本体编辑器Protégé设计了相应的领域本体,以作为智能检索系统的基础。其简化的部分领域本体结构如图2所示:
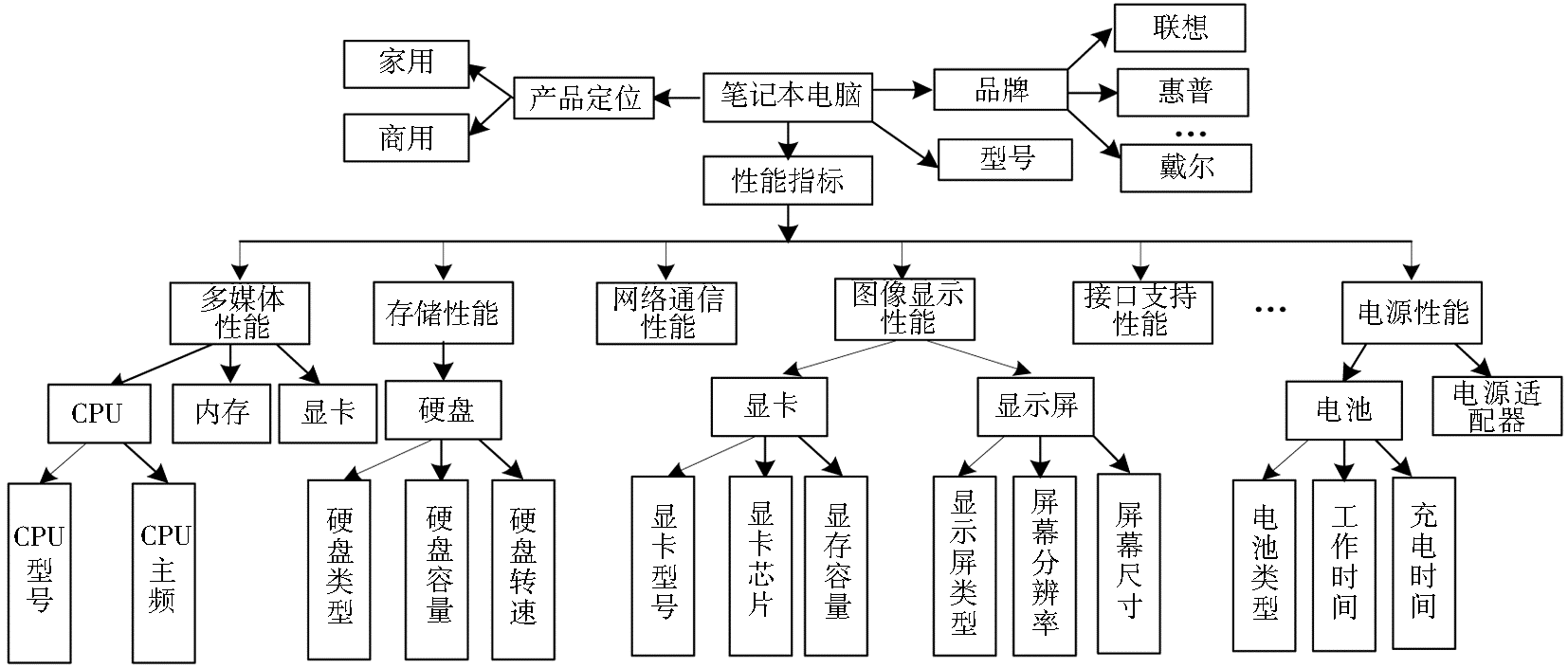 | 图2 笔记本电脑的部分领域本体 |
(1)确定商品本体的领域和范围;
(2)领域概念体系的构建,包括定义领域本体中的类及类的分层体系、定义类的属性及创建实例取值;
(3)本体概念的规范化处理;
(4)应用Protégé编辑器对商品本体进行构建,并转换为OWL本体语言表示的文件格式存储;
(5)商品本体评价和维护。
该过程的技术思路为:在笔记本电脑商品等特定领域的信息检索中,利用领域本体在知识描述上的优势,对顾客查询的关键词进行语义分析和扩展[ 10],其目的是帮助检索系统准确定位顾客的查询意图。在此基础上,形成扩展后的顾客查询条件,并生成对应的顾客查询语义向量。
在本文中,语义扩展实现方法以初始查询关键词为中心,基于领域本体对初始查询关键词分别进行同义词扩展、上位扩展和下位扩展。其中,同义词扩展是通过领域本体求出与初始关键词对应的所有同义词,并作为扩展后的新关键词;上位扩展则是通过领域本体求出与初始关键词对应的上位邻接词作为扩展后的新关键词;而下位扩展则通过领域本体求出与初始关键词对应的下位邻接词(包括概念属性或实例取值)作为扩展后的新关键词。因此,在处理顾客查询时,通过领域本体能对初始关键词进行语义描述和扩展,从而准确捕获顾客的查询意图,并从查询中提取特定概念属性及取值。例如,顾客购买笔记本电脑,在查找相应商品的信息时输入“惠普 商用 显示屏 17 英寸 IEEE802.11”,在抽取查询关键词时,结合领域本体可以判断顾客的查询意图是检索本体概念“笔记本电脑”的相关信息,通过分别对关键词“惠普”和“商用”进行语义上位扩展,系统可知顾客要求的电脑品牌是“惠普”,并且产品定位是“商用”;通过对关键词“显示屏”和“17英寸”分别进行下位扩展和上位扩展,可知顾客要求显示屏的尺寸是“17英寸”;通过对关键词“IEEE802.11”进行上位扩展,可知顾客要求无线网卡标准为“IEEE802.11”,并且性能特征应支持“无线上网”通信功能。
查询关键词语义扩展过程完成后,可以将获得扩展后的顾客查询条件表示为向量Q={C1,C2,…,Ci,…,Ct} (Ci表示第i个查询属性),其对应的权值Wi(1≤i≤t)即构成查询语义向量,可表示为WQ={W1,W2,…,Wi,…,Wt},向量的各个权值就是对应的关键词表达查询的语义重要程度。在查询语义向量生成过程中,系统可提供友好的人机交互方式进一步协助顾客确定其明确的查询语义,以对查询语义向量进行实时更新。
系统选取一些经典的B2C电子商务网站(例如当当网、亚马逊等),使用包装器(Wrapper)从检索到的HTML页面中抽取商品属性等相关信息,并转换成XML格式的文档;然后基于领域本体从XML文档中抽取能够代表文档的概念,以语义查询词为文档的特征项,将文档转化成基于OWL本体语言的格式,从而实现对Web页面的文档语义标记。
在对文档进行语义标记的过程中,系统可将顾客查询词作为文档的特征项,根据其在文档中出现的位置和频率确定该概念的权值,并构建文档语义向量[ 11]。向量构建过程为:对于从相关网站中返回的检索结果文档集D(设文档数量为),以语义扩展后的顾客查询条件Q={C1,C2,…,Ci,…,Ct}作为文档集D中的每一篇文档Dk(1≤k≤m)的特征项,即Dk={C1,C2,…,Ci,…,Ct},Ci(1≤i≤t)为文档Dk的特征项。在文档向量空间模型中,特征项常常被赋予一个对应的权值Wik,该值可利用TF×IDF公式[ 12]进行求解:
Wik=tfik×idfi= 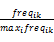

其中,freqik为特征项Ci在文档Dk中出现的频率次数;maxi freqik是文档Dk中出现频率最高的特征项的频率;m表示文档集合中的文档个数,ni为文档集D中出现特征项Ci的文档数。按照公式(1),可计算出文档集D中每个文档的权值。因此,在文档向量空间中,文档Dk的语义向量可进一步表示为Dk={W1k,W2k,…,Wik,…,Wtk}。
(1)语义相似度计算
当查询语义向量和文档语义向量产生后,利用余弦向量度量法[ 2, 13]可计算顾客查询与商品文档信息之间的语义相似度,以评价检索结果与顾客需求的语义匹配度,其计算公式为:
Sim(Dk,WQ)=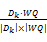
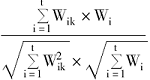
其中,Dk为文档语义向量,WQ为关键词语义扩展后的查询语义向量,显然相似度值在[0,1]之间,其值越大,则搜索到的商品信息和顾客查询从语义上越匹配。
(2)商品效用值计算
在语义检索的基础上,为了对检索到的商品信息进行有目的的筛选,需要建立有效的比较和评价机制,系统采用多属性决策方法TOPSIS (Technique for Order Preference by Similarity to Ideal Solution)[ 14, 15]来计算每个商品报价的效用值。TOPSIS法的基本思想是借助于多属性决策问题的“理想解”和“负理想解”来排序,以确定各方案的优劣。如果其中有一个解最靠近理想解,同时又最远离负理想解,则该解即为m个方案中的最优解。系统预先可将专家知识嵌入到系统中,对不同品牌和型号的笔记本电脑从各个性能特征(如多媒体性能、图像显示性能等)方面给出客观的评分。在信息检索过程中,基于TOPSIS法的商品比较和评价步骤为:
①将商品性能特征作为商品评价及顾客定性需求的指标,建立初始决策矩阵F。具体过程可描述为:设P={p1,p2,…,pm}为检索到的商品信息集;Y={y1,y2,…,yn}为顾客定性需求指标。则初始矩阵可表示为F=(fij)m×n,其中fij为第i个商品关于第j个指标的评分值。
②将决策矩阵进行规范化,得到规范化后的决策矩阵F'=(f'ij)m×n,其中:
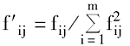
③将顾客当前定性需求向量W=<ω1,ω2,…,ωn>进行规范化,得到规范化后的需求向量W'=<ω'1,ω'2,…,ω'n>,其中ω'j表示规范化后的需求指标j的权重,则:
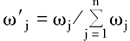
④分别计算每个候选商品Pi(1≤i≤m)到理想解和负理想解的距离:
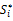
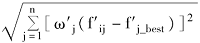
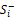
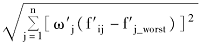
其中,n表示商品定性特征的数量,f'ij是对fij进行规范化后的评分值,ω'j是对定性需求ωj进行规范化的需求权重,f'j_best是规范化后的理想解的第j个分量,f'j_worst是规范化后的负理想解的第j个分量。
⑤计算所有候选商品Pi(1≤i≤m)的效用值Ui:
Ui=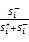
(3)集成的商品信息检索算法
综合语义相似度和商品效用值计算商品Pi(1≤i≤m)综合评分ProRanki,其值为:
ProRanki=λSim(Di,WQ)+(1-λ)Ui (0≤λ≤1)(8)
由公式(8)可知,当λ=1时,系统仅提供基于语义的信息检索,并不能对检索到的商品信息提供比较机制;λ=0时,系统则仅提供商品信息的比较,而没有考虑检索的商品信息与顾客查询的语义匹配。集成的智能信息检索主要算法如下:
算法:Product_Rank ()
输入:顾客查询关键词、商品特征定性需求及权重
输出: 排名Top-K的商品对应网站的URL
Init(Q); Load(Q); // 进行查询关键词的语义扩展,初始化并加载顾客查询语义向量
Begin
for each Di do
if log(Di) = 0 then // 该商品Pi对应的文档向量Di未被处理过
{
Load(Di); // 对文档Di进行语义处理,并加载文档语义向量
GetSimarity(Q,D0);//计算商品Pi对应文档Di与查询关键词间的语义相似度
GetProduct_Utility(Pi); //基于TOPSIS法计算商品Pi的效用值
GetProduct_Rank(Pi); //基于公式(8)计算商品Pi的综合评分
InsertTo(Result); //按降序排入检索结果集合Result中
}
Output(Result, Top-K);
// 输出Result中排名前Top-K的商品URL作为检索结果,并提交给顾客查看
End
系统从预定义的B2C电子商务网站(例如当当网、亚马逊等)中搜索相关的笔记本电脑商品信息,并将搜索到的商品信息下载到本地数据库中。系统平时从相关网站中下载3 000个商品HTML网页作为实验数据集,并使用包装器从检索到的HTML页面中抽取商品属性等相关信息,基于领域本体实现对Web页面的文档语义标记。
评价检索系统的一个主要指标是商品查询的准确率。商品信息的准确率与一般信息查准率计算方法相似,计算公式如下:
准确率=
其中, 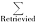
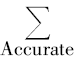
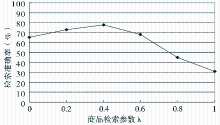
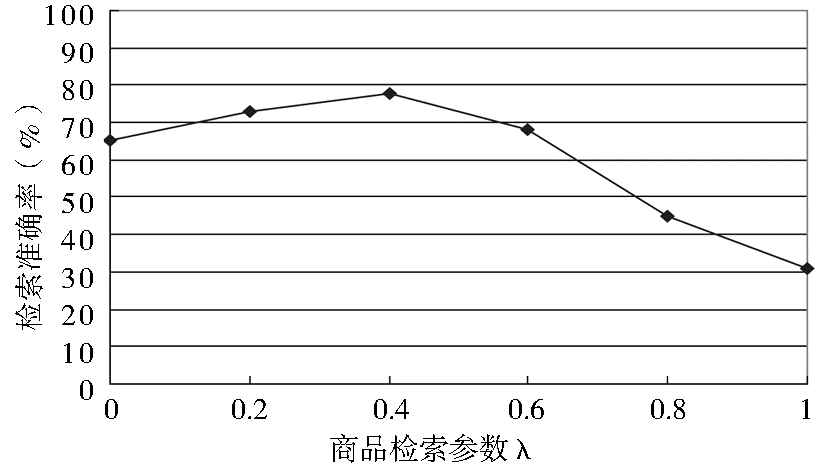 | 图3 参数λ与系统检索准确率的关系 |
另外,商品信息检索与一般信息检索不同,综合语义相似计算和商品效用值计算后,将排名前Top-K的K个商品提交给顾客查看,然后顾客从中选中若干个商品,将其添加到购物车中作进一步购买。为了验证本文提出的检索算法在检索结果排序策略上的有效性,本文定义了一个新的商品信息检索指标:顾客接受度(Customer Acceptance Ratio,CAR),计算公式如下:
顾客接受度=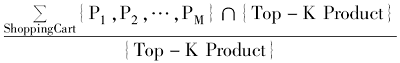
其中,{Top-K Product}表示根据本文检索算法输出排名前的商品集合, 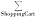
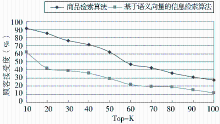
在实验过程中,将本算法(参数值设置为0.4)与传统仅基于语义向量模型的信息检索算法(即λ=1)根据顾客接受度指标进行对比,Top-K中的K分别设置为10-100等不同值,随意抽样10次顾客查询并取平均值,所得的平均顾客接受度如图4所示:
 | 图4 两种算法下的顾客接受度之比较 |
从图4可以看出,在不同的K值下,商品检索算法的顾客接受度均高于传统基于语义向量的信息检索算法,尤其当值较小(K≤50时),两者的差异更加明显。这是因为商品信息检索不同于一般的信息检索,除了要求检索结果在语义上应和查询关键词相匹配外,还要考虑对商品内容和质量的比较与评价,使检索结果更符合顾客的实际购买需求。同时应注意,随着K值的增加,两者的顾客接受度都不断下降。这是由于实际在线购物过程中,顾客仅关注排序最靠前的商品信息(例如K≤10)。因此,本文的商品信息检索算法是有效的,而传统的信息检索算法较难满足顾客的实际购物需求。
本文深入分析了电子商务环境下商品信息检索与一般信息检索的异同,提出了一种智能商品信息检索模型。在该模型中,系统综合基于向量空间的语义相似度计算和TOPSIS商品效用值计算,既实现了商品信息的语义检索,也提供了商品选择与比较机制,为顾客购物提供智能化的信息检索服务。此外,通过商品信息的准确率、顾客接受度等指标验证了检索算法的有效性和实用性。实验结果表明,本算法优于传统的语义信息检索算法,更符合顾客的实际购物需求。目前,以笔记本电脑商品为例,对原型系统做了一些开发工作,结果表明系统具有一定的电子商务应用潜力。基于目前的研究工作,笔者将继续完善检索模型,使其能为网上顾客提供更精准的商品信息检索服务。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|