


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于本体的军备情报抽取系统的设计与实现
[高文利 ]
]
]
|
|


基于本体的军备情报抽取系统主要由两部分构成:知识库和处理程序。该系统基于文本分类技术实现武器类别判定,基于命名实体识别技术实现武器对象判定。依据句法语义约束所形成的信息抽取规则,实现军备情报抽取,并依据本体在一定程度上实现语义层面上的信息整合。
The system of arms information extraction based on Ontology consists of two parts: knowledge base and processing subsystem. It realizes the arms category determination based on text categorization, and the arms object determination based on named entity recognition. According to information extraction rules based on syntax and semantic constraint,it implements the information integration based on the Ontology in semantic level to some extent.
公开情报研究正日益受到各国的普遍重视,而随着互联网的迅猛发展,互联网已经成为公开情报研究的最大来源之一。我国国防建设也急需能在海量信息中自动搜集、提取、整合各种情报的信息处理工具。而实现这一工具的最关键的核心技术是信息抽取。
信息抽取(Information Extraction)系统的主要功能是从文本中抽取出特定的信息。从20世纪80年代末开始,由于Tipster文本项目、消息理解会议(MUC)、自动内容抽取会议(ACE)、多语言实体任务会议(MET) 等因素的推动,信息抽取研究蓬勃开展起来[ 1, 2]。中文信息抽取方面的主要研究工作集中在对中文命名实体的识别方面,但也有不少学者正积极探索设计实现完整的中文信息抽取系统。
文献[3]基于各种短语识别,开发了一个面向网络的事件关键信息抽取系统。文献[4]利用HowNet和语义约束,实现了关于特定事件的角色抽取。文献[5]以同一突发事件的多个新闻报道为处理对象,进行了突发事件的信息抽取研究,主要探索了无指导的模式获取方法。文献[6]利用最长公共子串,通过聚类的方法,对关于农作物的品种描述模式获取进行了研究。另外,文献[7]对人民日报中的会议消息进行了抽取研究。
上述研究极大地推进了信息抽取领域的研究,但仍然留下了大量的研究课题,如信息抽取实践中抓取到的文本类型往往是未知的,因而文本分类技术必须集成到信息抽取系统中;信息抽取的实质是基于本体的知识工程,
信息抽取就是某一领域知识框架的若干“槽”的填充过程,本体构建技术也必须集成到信息抽取系统中;另外,网页中充满了大量冗余甚至矛盾的信息,如何把新抽取到的信息整合到目标库也是值得探索的问题。
为了进一步探索实现完整的中文信息抽取系统所需要的关键性技术,本文设计实现了一个基于本体的军备情报抽取系统。
基于本体的军备情报抽取、整合系统结构如图1所示:
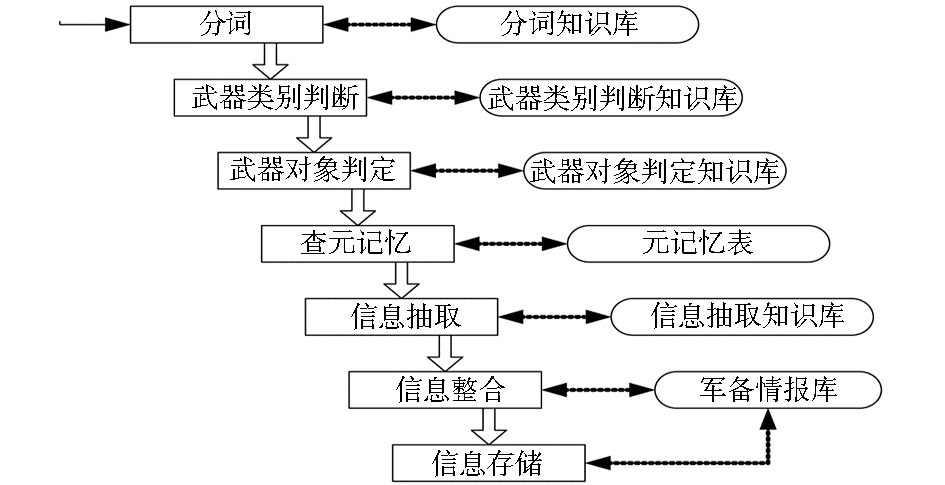 | 图1 军备情报抽取、整合系统结构图 |
从图1可知,系统主要由两部分构成:知识库和处理程序。本系统的知识库包括分词知识库、武器类别判断知识库、武器对象判定知识库、信息抽取知识库,这些知识库是系统进行各项处理的基础。除分词知识库外,本系统其余的知识库全部人工构建。处理程序完成系统的各项功能,由依次相连的7个模块组成:
(1)分词:将文本切分成词,以便于进一步处理。
(2)武器类别判断:判别文本讨论的武器类别。不同类别武器的信息抽取模式是不同的,必须先判断该文本讨论的武器类别,才便于调用相应的信息抽取模式。本文将文本分为航母、潜艇、坦克、战斗机、直升机、未知6类。
(3)武器对象判定:获取文本讨论的主要武器对象。不仅要知道文本讨论的武器类别,还必须弄清文本讨论的具体武器对象,这样才能将该武器对象的所有信息整合起来,保存在情报库中,以便于情报查询。
(4)查元记忆:判断该武器对象是否已在军备情报库中。不存在,则新建该武器对象的情报表;如果存在,则调出该武器对象的情报表,准备进行信息整合。
(5)信息抽取:根据武器类别从信息抽取知识库中调用相应的信息抽取规则,逐句进行句法语义模式匹配,从匹配的句子中抽取相应的信息。
(6)信息整合:将同一对象的新旧信息整合成一个有机整体。从情报库中调出该对象的情报表,与工作表中刚抽取的信息按照属性逐一进行整合。
(7)信息存储:将整合后的相关情报信息保存至军备情报库。
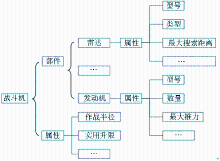
本体是领域知识的逻辑抽象而构筑起来的体现概念及关系的概念模型。构建本体的目的是为了知识的表示、共享和重用。而事物的静态知识可以看成关系、部件、属性这三者的集合。关系集合中的每种关系可以看成“事物-关系-相关方”三元组;部件集合中的每个部件又可以看成关系、部件、属性这三者的集合;属性集合中每个属性可以看成“属性域-属性值”对。具体事物的知识框架实际上就是上述抽象框架的具体运用,如本系统在抽取、整合战斗机信息的知识框架如图2所示:
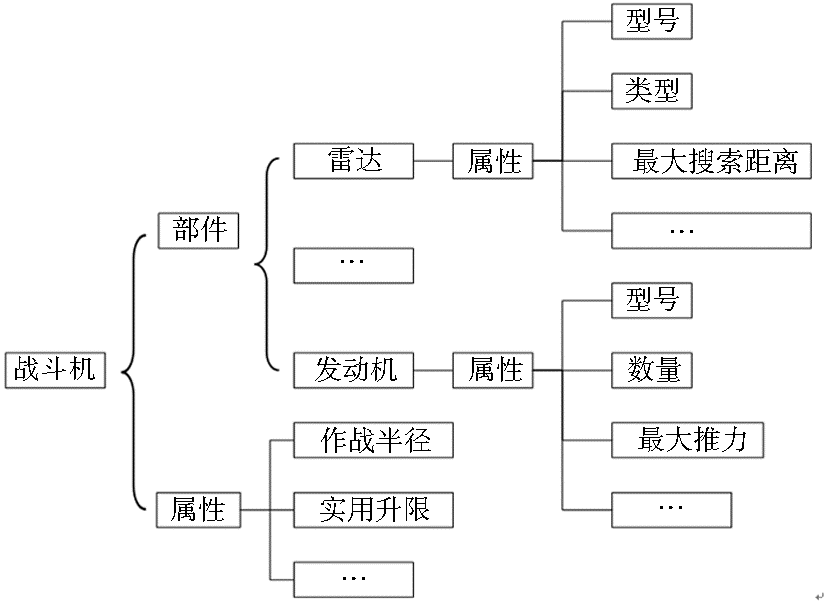 | 图2 战斗机知识框架简图 |
笔者用W3C推荐的Web本体标准语言OWL构建了军备情报这一领域知识的本体。根据该本体构建了信息抽取模板,然后依据模板中需要填充的槽来构建信息抽取知识库。
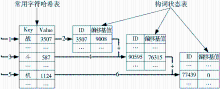
本系统采用笔者开发的“基于三数组Trie索引树词典查询机制的分词系统”来分词。该分词算法采用基于三数组Trie索引树的词典查询机制进行查询,其实质也是最大匹配法。三数组Trie索引树的词典由常用字符哈希表、构词状态表两部分组成。
具体分词算法为:每次读入一个字符,与前面的待处理字符构成当前待处理字符串,查询构词状态表,判断该当前待处理字符串具体属于哪一种情况,然后做出相应的处理(详见文献[8])。
查询过程相当于从一个状态到另一个状态。查询时,先从常用字符哈希表中获取该字符对应的地址,以此地址从构词状态表中取值进行判断,依据其性质进行状态转移,直到确定一个词。通过偏移基值、词典入口指针、上一状态的值来控制状态转移。如查询“战斗机”步骤如下:
(1)读入“战”,查常用字符哈希表得“战”地址为3507,以3507为地址查构词状态表可知“战”为情况,可以读入下一字符。
(2)查得“斗”的地址为587,加上上一状态“战”的偏移基值90008,得90595,以90595为地址查得“战斗”为情况,可以读入下一字符。
(3)查得“机”的地址为1124,加上上一状态“战斗”的偏移基值76315,得77439,以77439为地址查得“战斗机”为情况,为终词状态,必须将其切出。
至此已完成分词查询。整个查询过程如图3所示:
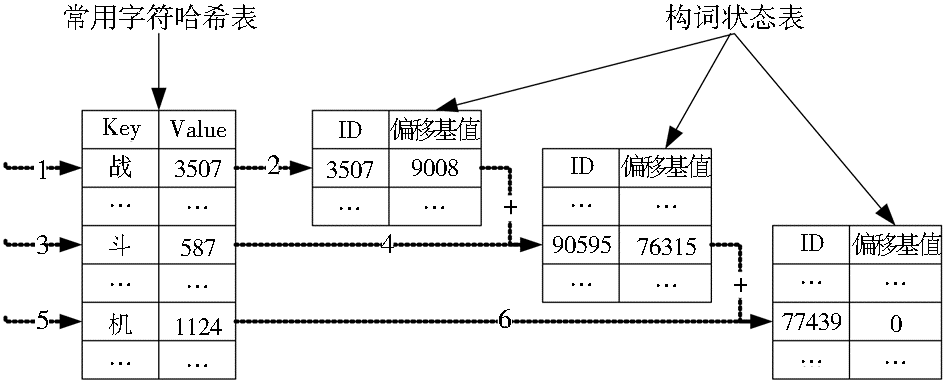 | 图3 基于三数组Trie索引树的词典查询机制 |
由于该分词系统采用了由短词及长词的确定性工作方式,避免了整词二分查询机制中不必要的多次试探性查询,效率较高。
本系统运用文本分类技术来实现武器类别判断。武器类别判断子系统采用向量空间模型表示文本,通过改进后的互信息计算公式进行特征筛选,筛选出区分性高的前3 000个特征,实现了高效的特征降维,然后使用K-近邻算法对文本进行分类,具体算法如下:
(1)进行文本预处理,得到训练样本集中的每篇文档表示向量;
(2)计算待分类文本与训练样本中每篇文本向量之间的相似度,并对相似度进行排序,取前K个最相似的文档。相似度计算使用夹角余弦公式:
Sim(Dj,Dk)=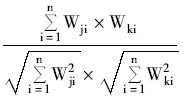
其中,Wji、Wki分别表示文本Dj和Dk第i个特征项的权值,1≤i≤N。
(3) 计算这K篇文档中所属于的类型的权重,权重最大的类别即为待分类文本的类型。权重计算公式如下:
SimScore(x,Cj)= 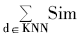
其中,SimScore(x,di) 为待分类文本向量x与训练文档之间的相似度;y(di,Cj) 为类别属性函数,当di属于类Ci,那么函数值为1,否则为0。
只有实现了武器对象判定,才能将信息整合到保存这一武器情报的军备情报库中。该子系统通过命名实体识别技术识别文档中出现的武器对象,采用规则和统计相结合的方法,模拟人们日常阅读中的智力活动,判定文档讨论的最主要武器对象,具体算法如下:
(1)获取文本结构。把文档切分成标题和若干个自然段。
(2)取标题,进行标题分析。从内存中调用标题分析知识库,判定能否从该文章的标题中直接抽取到本文的对象。如果能,则直接返回该对象;否则,进入下一步。
(3)取介引句,进行介引句分析。从内存中调用介引句分析知识库,判定能否从该文章的介引句中直接抽取到本文的对象。如果能,则直接返回该对象;否则,进入下一步。
(4)统计判定,获取权值最大的讨论对象。识别文中各处出现的武器对象,根据其文中出现的不同位置赋予不同的权值,然后统计各武器对象在文中的总权值,权值最大的武器对象就是文章的讨论对象。
在实际开发中该子系统对多武器对象文章的处理能力尚未实现,目前该系统尚不具备对多讨论对象的文章进行对象判定的能力。
基于本体的军备情报抽取、整合系统采用基于关键词驱动的信息抽取子系统进行信息抽取,主要由句子过滤、句法语义分析、信息提取等几个关键性环节组成。该信息抽取子系统在本质上是基于规则的,并且是基于产生式规则:条件→操作,即如果句法语义模式匹配成功,则从句中抽取相应的信息。具体算法如下:
(1)遍历句子列表,依次读取一个句子,并对句子进行过滤:只有该句子有关键词,才能进入步骤(2)进行处理。
(2)将有关键词的句子分解为分句,一一对各分句进行过滤:只有该分句有关键词,才能进入步骤(3)进行处理。
(3)运用关键词作为触发器,从信息抽取知识库中调用与关键词相对应的信息抽取规则,对有关键词的分句进入步骤(4)进行相应处理。
(4)将信息抽取规则分解为“测试规则”和“提取规则”两部分,并运用“测试规则”对句子进行测试,看该句的句模是否与规则相匹配。相匹配者,才能进入步骤(5)进行信息抽取。
(5)运用“提取规则”从句中相应的位置上抽取相应的信息,并贴上语义标签。
①将“提取规则”分解为“属性名提取规则” 和“属性值提取规则”。
②分析“属性名提取规则”,提取相应的信息给NameOfProperty。
③分析“属性值提取规则”,提取相应的信息并贴上相应的语义标签,赋值给ValueOfProperty。
(6)将抽取到的信息登记到数据黑板的工作表中,以便于进行下一步的信息整合:在工作表中添加新行:“属性名”栏中填入NameOfProperty的值,“属性值”栏中填入ValueOfProperty的值。
为了确保信息抽取子系统具有较好的可移植性,笔者设计了一种信息抽取规则描述语言(Information Extraction Rule Description Language,IERDL)[ 9]来描述武器每个属性的抽取规则。每抽取到一个新的武器对象,就将其添加到元记忆表,为以后的信息整合做好准备。
基于本体的军备情报抽取、整合系统以武器对象为中心组织信息,即有关该武器对象的一切信息都保存在以该对象名称为表名的武器情报表中。由于每个对象只有唯一的信息记录表,信息整合在技术上就表现为将“工作表”中新抽取的信息整合到军备情报库中“武器情报表”的过程。由于事先完成了本体的构建,同一对象的知识框架是固定的、统一的,此时信息整合就演变成对同一武器对象的各属性值进行整合的过程。
本信息整合系统保留抽取到的各武器的各属性的所有值,通过可信度为标准来筛选信息。某武器某一属性的任一值的可信度为该值在该属性的所有值中的出现频率。这样,在信息检索时就取可信度最大的值作为该属性的属性值。
综合集成上述的各项技术,用VB.NET为开发语言,以Access关系数据库为后台数据库,采用ADO.NET技术与数据库交互,开发出了一个基于本体的军备情报抽取、整合系统。实验平台如下,操作系统:Windows XP;CPU:赛扬3处理器1.20 GHz;内存:256MB。
在实验中,使用了5个武器类别,分别为航母、潜艇、坦克、战斗机、直升机。笔者随机从因特网下载了讨论这5个武器类别的228篇文章作为测试语料,对上述算法进行测试,实验结果令人满意,平均分类精度达97.96%。
笔者随机从中国军网、中华网军事、新浪军事等网站下载了有关战斗机的165篇文章,对武器对象判定算法进行测试,结果有141篇成功地抽取到了该文章的讨论对象,精确率为85.5%。未能成功抽取的文章,主要是由于表述不规范,如有的文章全篇用“.”来代替句号,致使程序无法将其切分成句,自然也就无法抽取到正确的讨论对象;又如有的文章出现一次“F-18”后,其他地方就全变成了“F一18”,程序把后者作为文章的讨论对象。
目前,该系统的知识库还只完成了一个武器类别——“战斗机”部分的建设,但整个系统已通过了测试。本文用讨论战斗机的文档对系统进行了测试,实际运行情况如下:
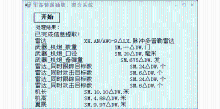
(1)图4是系统正在对一篇讨论“F-14”战斗机的文档进行处理时的情况。
 | 图4 军备情报抽取、整合系统正在处理时的情况 |
(2)图5是系统刚刚完成对一篇讨论“F-14”战斗机的文档进行信息抽取时的情况。这时还没有进行信息整合,就连自身的重复项都未进行任何处理。
 | 图5 军备情报抽取、整合系统的信息抽取示例 |
(3)图6是系统对两篇讨论“F-16”文档进行信息整合后的结果。可知,系统已成功地将新抽取到的信息整合到“F16”战斗机的信息表中,并且新的情报来源全文也被保存在信息表中,为将来的情报查询做好了准备。
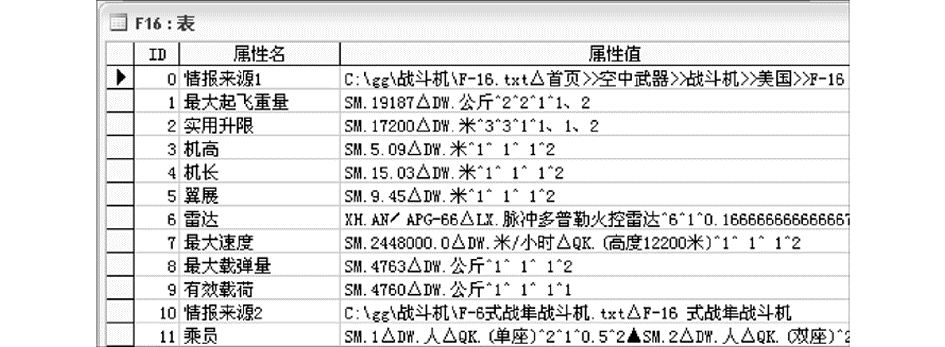 | 图6 军备情报抽取、整合系统完成信息整合后的信息表 |
为了有效地利用Web上的信息资源,人们从各个方向开展研究,并提出了一些方法,信息抽取就是其中一种。由于本体模型是一个对有共识的、己经概念化的事物的规范的、明确的定义,有利于知识在不同的系统之间实现基于语义的共享,因而基于本体模型指导的信息抽取整合是真正实现Web信息共享的出路之一。本系统虽在一定程度实现了语义层面上的信息整合,但各处理环节还需要进一步完善。另外,本系统尚有网页搜索、文档清洗两个处理环节没有实现,还不能直接自动地从网络上获取相关网页、截取相关文档、抽取相关信息并进行整合,这也是今后进一步努力的方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|