

{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种新的跨语言商品信息检索方法在图书搜索中的应用
[张李义 , 张震云]
, 张震云]
, 张震云]
|
|


分析跨语言信息检索的基本模式和翻译消歧关键技术,采用基于词语对共现率和词语间距加权计算的方法,对查询式翻译进行消歧优化,在此基础上构建跨语言商品信息检索系统并应用于图书商品搜索,实验结果证明翻译质量和检索效果得到提高。
This paper analyzes the basic model of Cross-Language Information Retrieval(CLIR) and the techniques of translation disambiguation. Then it optimizes translation disambiguation based on co-occurrences between pairs of terms and computing weights of terms,and constructs a CLIR system for book searching. The experiments show that the translation quality and the retrieval effectiveness are improved.
随着经济全球化的不断发展,电子商务全球化的趋势愈发强烈。一方面,Internet 上的商品信息日益丰富,在不同国家和地区分散分布且相对孤立,无法形成一个整体价值链;另一方面,用户对商品信息检索的语言功能需求不断提高,他们常常希望利用本国语言直接检索出更多更精确的其他语言表达的信息。电子商务系统必须提供多种语言的检索机制来引导客户查询可能超过其本身语言能力的商品信息。跨语言信息检索(Cross-Language Information Retrieval, CLIR) 是信息检索的一个重要分支,指用户使用某种语言表示的查询式,从另一种或多种语言表示的信息资源中检索出所需信息的方法或技术。跨语言商品信息检索逐渐成为电子商务活动中人们获取商品、服务和信息的基本手段,具有很大的市场和应用价值,得到了国内外学术界和企业的广泛关注。
近年来,国内在线图书B2C 市场发展迅速,并引领了网络购物市场的繁荣。同时,随着读者对外文书籍需求度的提高,用户对于图书信息的跨语言搜索需求不断扩张。在传统搜索引擎中,用户需要不断切换输入法来完成多种语言图书信息的搜索,有时候用户并不能确定如何用他们不熟悉的语言来确切表示搜索目标,搜索结果的覆盖度和精确度往往达不到预期。因此,在图书搜索领域,能克服语言障碍,充分理解并处理用户查询的跨语言图书商品信息检索十分必要。
跨语言信息检索的研究最早可以追溯到20 世纪60 年代末,由康奈尔大学的Salton[ 1] 首次提出。随着网络技术的迅速繁荣,跨语言信息检索技术受到越来越多的重视,研究重点主要集中在语言资源、翻译歧义性消解、交互式界面等方面。近年来,国内外学者做了大量CLIR 研究工作,发表了许多相关论文并召开一些关于跨语言信息检索技术的会议,反映了当今CLIR 的研究热点和趋势,如文本检索会议(TREC)[ 2]、跨语言评价论坛(CLEF)[ 3]、日本国家科学信息系统中心信息检索系统测试集会议(NTCIR)[ 4] 和美国计算机协会信息检索特殊兴趣小组会议(ACM SIGIR)[ 5]。
实现CLIR 的基本模式包括文档翻译(Document Translation)、查询式翻译(Query Translation)、中间语种转换(Interlingual Representation)、非翻译(No Translation)、同源匹配(Cognate Matching)。查询式翻译是目前绝大多数CLIR 系统所采用的翻译模式[ 6]。由于查询式一般比较简短,语种转化的工作易于实现,而且能够在传统单语环境检索系统的基础上构建跨语言检索机制。但是查询式缺乏足够的上下文语境信息,增加了翻译的难度。非翻译模式并不对源语种和目标语种进行翻译,包括潜在语义索引[ 7]和向量空间模型[ 8]。
现阶段跨语言信息检索主要解决源语种和目标语种之间的翻译转换问题,研究的热点和难点集中表现为翻译歧义性消解。一个词汇可能有多重意义,系统在翻译时面临对众多翻译项进行选择的问题。目前,在针对CLIR 翻译消歧技术的研究中,有以下几种关键技术:
(1)查询扩展(Query Expansion)。查询扩展技术的思想是对用户提交的查询式进行语义扩展,利用词的同义、近义、上下位等关系确定词义,以缩小翻译项的语义范围,帮助系统排除干扰项的影响。查询扩展可以在翻译前、翻译后或翻译前后同时进行[ 9]。
(2)基于语料库(Corpus-based)。语料库是指由大量经过整理的文本形成的具有既定格式与标记的文本集。在CLIR 应用中,语料库的组织形式主要是用两种或多种语言来描述同一信息或同一主题的信息。利用不同语种在同一信息上的对应关系,实现对翻译项的筛选,或者根据对应语料库中源语词和翻译项出现的频率来确定最佳翻译结果[ 10]。
(3)词性标记(Part-of-speech Tags)。词性标记技术的基本思想是只选择那些与源语种查询式词汇有相同词性标记的翻译项。Davis[ 11]等人在解决英语和西班牙语之间的CLIR 翻译消歧时采用了这种技术,只有在英西词典中的西班牙语与作为查询式的英语有相同的词性标注时,该翻译才会被采纳。这种方法要求进行词性标记的软件同时适用于源语种和目标语种。
(4)结构化查询(Structured Query)。结构化查询将查询式的众多翻译项看成一个同义词集合,从这个角度引入传统的布尔逻辑。Hull 认为,布尔运算采取了一种自然方式将众多翻译项进行等值连接,而不会过分增加基本概念的权重。基于一个纳入了布尔运算符的查询式排列文档,Hull 等人还提出了概率检索模型[ 12]。
(5)基于共现率(Co-occurrence Based)。共现率技术的核心思想是查询式的正确翻译组合共同出现在文档中的概率要大于不正确的翻译组合[ 13]。例如,在一个英文查询式中同时包含“Mercury”和“Planet”这两个单词,虽然“Mercury”有多个翻译项,但在这里由于和“Planet” 共同出现,因此被翻译成“水星”的概率最大。
(6)检索反馈(Retrieval Feedback)。在CLIR 中,第一次检索得到的结果往往并不理想,需要采取相应的方法获取反馈信息,对查询式和翻译结果进行改进,反馈信息可以成为提高系统检索性能的依据[ 14]。
对于CLIR 系统,一个最直接的选择就是利用现有的机器翻译系统对查询式进行翻译,将问题简化为单语检索。然而,机器翻译对源语的语法结构要求较高,而事实上用户输入的查询式往往并不是一个完整的句子,有时甚至只是几个关键词的随意组合。此外,基于机器翻译的CLIR 只能给出唯一的“最佳”翻译结果,而这个“最佳”翻译结果只是根据系统预先定义的算法得出的,这对用户而言并不友好,用户只能被动接受由系统的内建机制制定的翻译标准,而失去了根据实际需要进行选择的权利。双语词典被广泛应用于CLIR 实验,然而以往的研究工作表明,在英汉跨语言信息检索系统中,基于简单词典查询法的翻译策略的检索效果仅仅为单语检索的60%[ 15],主要原因包括:
(1)词典的覆盖度不够;
(2)词典可以列出每个源语词的众多翻译项,但是却无法提供选择最合适翻译项的方法或每个翻译项被选择的概率信息。
本文尝试基于一种新的翻译消歧优化方法来构建跨语言图书商品信息检索系统。系统采用目前应用最为广泛的查询式翻译实现语言转换,将查询式语种转化为目标语种,然后在目标语言环境下进行检索。系统对用户输入并无语法结构上的要求,而且考虑到最终检索结果的有效性,提供用户对翻译结果的选择和反馈机制。系统采用机器可读词典和词语对共现率统计相结合的方法对查询式翻译进行消歧优化,根据充分考虑词语间联系的概率最大化算法来实现CLIR。
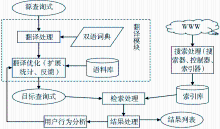
本文提出的以Web 商品信息资源为检索目标的CLIR 系统模型框架是在信息检索基本模型的基础上加以扩展,加入了查询式的人工或自动翻译机制,主要分为翻译处理模块、搜索处理模块、结果处理模块三个部分,体系结构如图1 所示:
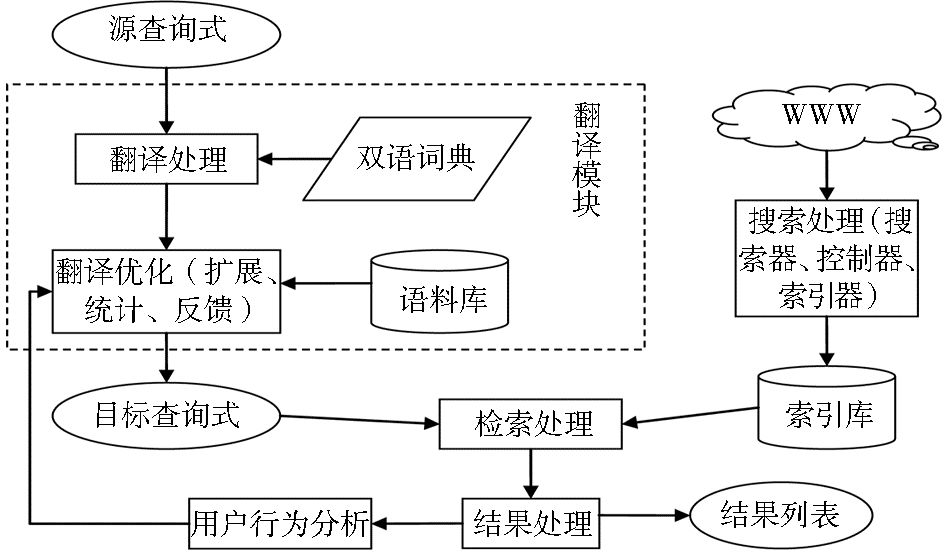 | 图1 CLIR 系统体系结构 |
由于用户提交的查询式形式简洁且无语法约束,因此翻译处理模块无需过多考虑语法因素,而专注于解决语言的一词多义和近义词处理等问题。系统的交互性能也是非常重要的,尤其是在跨语言环境下,某些时候系统无法通过简单的翻译理解查询式所表达的用户意图。在用户提交查询式之后,系统利用查询扩展等技术提供一个翻译列表,包括系统无法自动过滤的所有可能的翻译形式供用户选择,或在此基础上让用户自行优化翻译结果。在这种用户辅助查询的方式下,系统可以更加直观地理解用户需求以提高查准率。搜索处理模块基于开放源代码的Lucene 来构建一个图书信息搜索引擎,本文对此并不进行详细介绍,而将研究重点放在降低翻译歧义性的翻译优化过程上。
在图书信息搜索中,用户提交的查询式大多是书名或者反映图书内容的关键词组合,在翻译时对语法识别的要求并不高,且副词、介词、连词、助词、叹词和拟声词等虚词不易产生歧义。因此,无论用户提交的查询式是单词、短语或短句,在本文中被统一当做词组来处理,即由词语组成的线性序列,而这里将词语作为翻译系统处理的最小单元。
词语的一词多义问题是翻译系统遇到的最大障碍,克服语意模糊性的最好方法就是利用上下文语境[ 16]。除非用户亲自对输入进行解释,否则系统只能根据上下文来选择最有可能符合用户意图的翻译,而查询式中每个词语的上下文就是其他词语。假设源语种查询式Q是由一系列词语组成的线性序列,Q=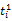
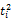
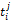
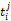
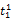
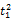
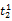
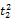
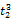
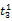
一个简单的方法是统计每一种翻译组合在语料库中的共现情况,得分最高的组合作为最佳翻译。但是,语料库通常非常庞大,统计每一种组合的共现次数需要消耗大量时间。在词语数量较多时,有可能面临数据稀疏的情况,即使语料库十分庞大,也无法获得足够数量的共现次数。另外,并没有对词语间关联度进行区分。因此,本文考虑翻译项的词语对在单语语料库中的共现率(Pairs of Terms Co-occurrences, PTC)。用骰子系数(Dice Coefficient)[ 17]来表示词语对之间的共现关系, 计算公式如下[ 18]:
DC(t,t')=
其中,freq(t)表示词语t出现的次数,freq(t,t')表示词语t和t'同时出现的次数,DC(t,t')的取值在0到1的范围内变化。词语对的共现率越高,产生歧义的可能性就越小,其作为最佳翻译项的可能性就越大。
(1)n阶无向完全图
本文利用图的概念来表示查询式各词语翻译项之间的联系。如图2 所示,用节点来表示各个翻译项,用一条边连接两个节点来表示翻译项词语对,两个节点之间的边则表示这个词语对的共现关系,需要注意的是同一个词语的各个翻译项作为一组节点,同一组节点之间并无连接[ 18]。不同组节点两两之间存在一条边,形成多个n阶无向完全图,这样,每个n阶无向完全图表示一个翻译组合(n表示源语种查询式中词语的个数,这里n=3),比如< 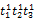
 | 图2 词语对的共现 |
在这里,为图中的每一条边赋予一个系数来计算两个翻译项的共现率,可以直接用骰子系数的计算公式来表示共现率:
Co(ei,j)=
其中,Co(ei,j)表示ei,j的系数,ei,j为连接i,j这两个节点的边。在一个n阶无向完全图中,把每一条边的系数相加即得到这个n阶无向完全图的系数:
Co(graph)=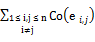
其中,ei,j表示连接源语种查询式中第i个和第j个词语的翻译项的边。边的系数反映了词语对之间的关联度,进而一个n阶无向完全图中所有边的系数之和从某种程度上可以反映这个n阶无向完全图中所有节点所表示的一组翻译项的关联度。笔者认为,系数最大的n阶无向完全图表示的翻译组合产生歧义的可能最小,优于其他翻译组合。
(2)距离因子
假设 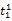
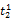
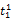
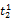
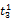
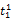
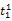
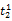
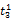
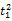
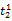
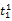

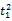
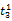
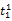

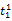
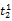
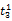
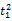
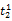
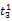
在短语或句子中,相比于相距较远的两个词语,相邻两个词语间的联系往往更加紧密。最佳翻译项的共现率不能仅仅依靠其中每个词语对的共现率简单相加来获得。因此,本文将每对词语的权重进行区分,引入距离因子d,距离远的词语对权重低,反之,距离近的词语对权重高,公式(3)可修正为:
Co(graph)= 
将根据公式计算出来的所有n阶无向完全图的系数进行比较,得出最佳翻译组合:
BestTrans=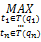
(3)翻译组合可选范围
虽然公式(5)通过更精确的加权计算得到了所有翻译项组合中相对最可靠的翻译,将源语种查询式转化为目标语种查询式,然而翻译的歧义性并没有完全消除,仍然可能出现几个n阶无向完全图的系数相近的情况。这时候仅仅依靠比较系数的大小来进行取舍显然没有足够的说服力,容易产生词义上的偏差。因此,在得到最可靠翻译组合的同时,系统可以列出其他可能的组合供用户选择,借助用户参与以帮助提高翻译的准确性。在本文方法中,规定一个阈值来限定选择范围。利用公式(6)得到符合要求的最终翻译列表:
TransList(Q)={probtrans|probtrans∈Trans(Q)
and Co(graph)probtrans≥(1-p)·Co(graph)max}(6)
其中,阈值p取值为0.2,Co(graph)max表示所有n阶无向完全图的最大系数,Trans(Q)表示所有可能的翻译项组合的集合,probtrans表示可供用户选择的翻译项组合。
为了检测上述方法的有效性,本文构建了一个基于词语对共现率的跨语言图书商品搜索引擎进行实验验证。与此同时,采用简单词典查询法(Simple Dictionary Based)、机器翻译法(Machine Translation) 以及单语检索(Mono- IR) 进行对照,比较实验结果。为了更好地进行验证,系统仅在翻译处理模块分别采用上述几种不同方法,而在搜索处理、索引和检索机制等系统的其他部分保持一致。
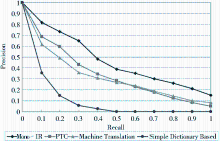
实验中,中文语料库来源于从当当网、卓越亚马逊、新华书店三家图书销售网站采集的共62 419 篇文档。笔者针对图书领域设计了7 组查询主题,考虑到实际应用中用户并不一定查找书名,而可能需要输入较长的查询语句与图书摘要或简介进行内容匹配,因此,分别人工构造了50 条英文长查询式和短查询式作为源语种查询式。采用平均查准率(Mean Average Precision, MAP) 作为评价指标。有关4组实验结果的查全率/查准率曲线如图3、图4 所示:
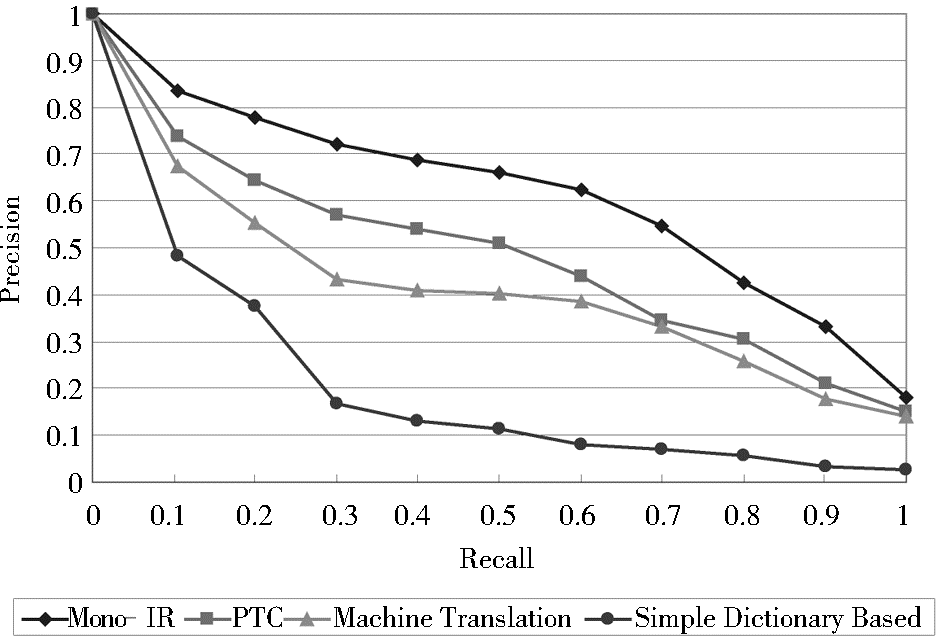 | 图3 短查询式的查全率/查准率曲线图 |
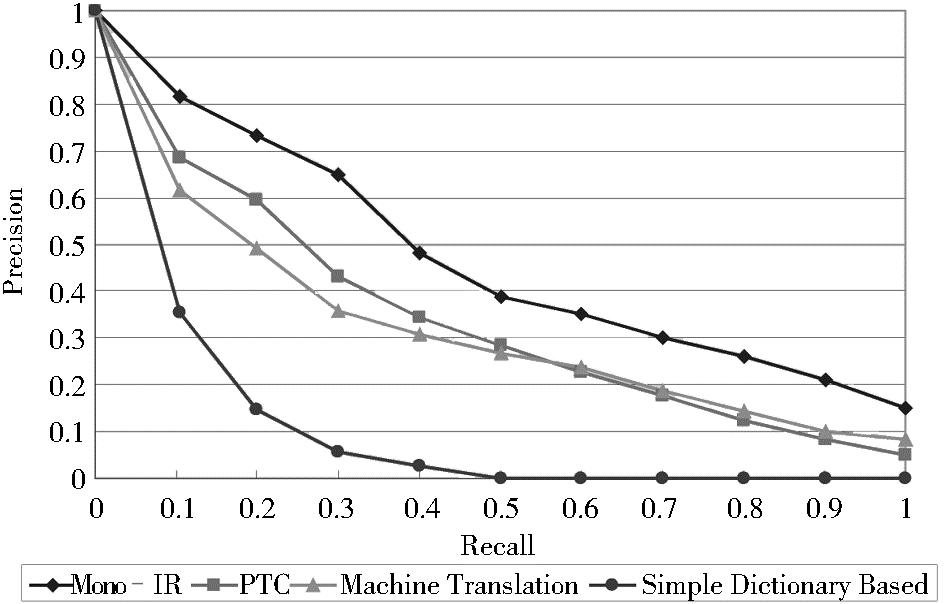 | 图4 长查询式的查全率/查准率曲线图 |
从实验结果来看,本文方法在查全率和查准率方面的表现优于简单词典查询法和机器翻译法,且短查询式MAP值已经达到单语检索的77.03%,如表1所示。通过分析,笔者认为这个差距主要归因于所采用的中文语料库覆盖范围不够,某些主题中的查询式词语没有正确的翻译或未翻译。此外,在长查询式实验组中,当查全率较高时,查准率的表现尚不及机器翻译,主要是由于本文方法并未着重语法分析,在检索过程中检出了大量非相关文档而产生的影响。
| 表1 短查询式平均查准率的比较 |
本文介绍了一种新的跨语言商品信息检索方法,对传统的基于词典查询或机器翻译的查询式翻译模式进行了翻译消歧优化,用到的翻译资源包括英汉双语机器可读词典和英汉单语语料库。在理论研究的基础上展开图书商品搜索领域的实验研究,结果表明,语法要求不高的CLIR 应用中,经过改进的方法在翻译消歧方面起到了良好的作用,在一定程度上提高了CLIR 系统的查全率和查准率。然而,CLIR 仍然存在众多问题尚未得到妥善解决,比如,某些特定领域的语料库的采集和组织十分困难;翻译效率问题;用户交互反馈方面,如何有效利用用户行为日志对翻译策略进行改进;在查询式翻译中,能利用的上下文信息非常有限,如何将语义分析加入CLIR,利用领域本体等工具从语义层面上改善翻译结果,这是CLIR 研究的一个重要方向[ 19]。本文的方法仅仅只在理想条件下对查询式翻译的质量进行优化,在今后的研究工作中,需要结合上述问题,进行扩展和完善。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|