{kind=link}
{kind=link}
{kind=link}
基于粒度的本体模块描述方法
[郭文丽1  , 张晓林
, 张晓林2 ]
, 张晓林|
|


针对用户来自不同角度及不同层次的本体需求,提出建立基于粒度的本体模块描述方法,以便帮助用户从现有的大型本体中抽取出所需模块。将粒度计算方法与分面分类理论结合起来,定义并论证本体的粒度属性,并在此基础上给出本体粒度划分的相关定义与语义解释。
To satisfy the various Ontology demands from different perspectives and hierarchies, this paper proposes a new description of Ontology modules based on granularity theory, by which the users can easily extract the modules from existing large Ontologies. Through combining granular computing and faceted classification, this paper defines the granular properties of the Ontology and gives the definition of Ontology granular partitioning as well as its semantic explanation.
随着本体研究的不断深入,目前已构造出了不同类型且规模各异的多种本体。如何从现有本体中选取用户需要的内容并加以复用,是当前本体应用领域的重要研究课题。
值得注意的是,本体内容的巨量化与本体描述语言的专业化给本体的复用带来了诸多现实的障碍。现有的本体大多采用专门的本体描述语言(如OWL、RDF),且容量巨大、内容庞杂。以UMLS (United Medical Language System)为例,它集成了来自60多个生物医学词汇体系的大约90万个概念所对应的200多万个名称和1 200多万个关系[ 1]。对于这种大型本体,用户往往只需要其中很小的一部分内容,但由于本体描述语言的专业性,普通用户很难用准确的本体描述语言来刻画他们的需求、达到从巨型本体中抽取所需内容的目的。
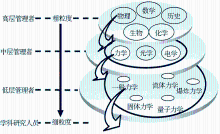
事实上,对于具有不同身份、背景及承担不同任务的用户而言,他们所需要的知识内容是不同的。如图1所示,高层科研管理人员需要了解的是粗粒度的学科概念以及这些概念之间的关系,中层管理人员则只关注某一学科中较细粒度的概念及其关系,而低层管理者或科研人员则需要某一学科内特定研究方向的更细粒度的本体内容。这样的知识需求具有多粒度特征,现有的本体描述语言中没有与之对应的描述机制。
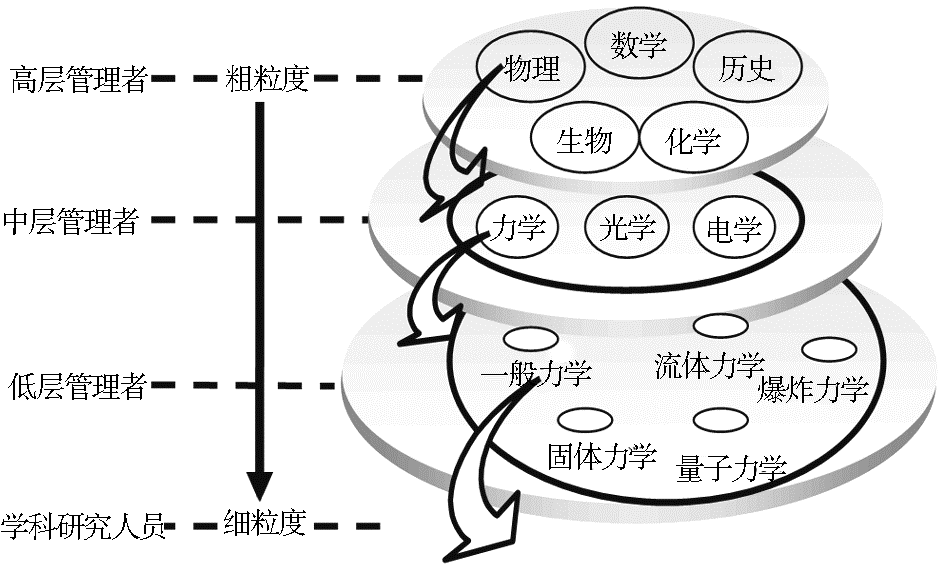 | 图1 不同用户对本体模块的不同角度、不同层次的需求示例 |
鉴于以上情况,本文提出了一种基于粒度的本体模块描述机制。该模块描述机制既便于用户描述本体模块需求,又便于从现有的本体模型中提取模块信息。
近年来,本体模块化研究作为本体复用研究方向的一个重要分支,在本体模块化的概念、形式化描述、设计模式与选取方法等方面取得了一定的研究成果。
本体模块的描述方法是在本体模块化方向研究最多的问题之一,目前主要的本体模块描述方法包括基于描述逻辑的描述方法和基于图形结构的描述方法。
(1)基于描述逻辑的本体模块描述方法以描述逻辑作为理论基础,对现有的本体描述语言OWL做相应的语法或语义上的改进以便用于表示本体模块,或者依据本体模块的形式化描述方法构建新的专门用于描述本体模块的语言。目前本体模块的形式化描述研究主要集中在对描述逻辑语言的扩展方面,包括分布式描述逻辑(Distributed Description Logic,DDL)[ 2]、ε-连接(ε-Connection)[ 3, 4]和基于包的描述逻辑(Package-based Description Logic,P-DL)[ 5, 6]。其中DDL与ε-Connection之间具有一定的互补性。DDL解决了分布式本体之间概念的映射问题,而ε-Connection则侧重于通过角色映射来实现外部本体中概念的复用。P-DL虽然刚刚提出,但其通过将本体分包来达到概念直接复用的思想受到了业界的关注。总的来说,本体模块的形式化描述逻辑目前还集中在理论研究方面,在语法与语义方面存在的一些问题还有待进一步探讨[ 7]。
(2)基于图形结构的本体模块描述方法利用本体三元组的特性把本体转换为图形结构的表示形式,然后通过限定本体模块的大小以及计算图形节点之间相关度的方式来确定本体模块。用RDF描述的本体可以方便地转换为图形结构的形式。但对于OWL格式的本体,由于其采用框架系统作为抽象语法,不同于RDF的三元式模型,OWL所能表达的某些内容无法直接描述为三元式。例如,OWL中的约束(Restriction)类就无法用一个三元式表示,需要引入若干内部标识符才能形成一组三元式。因此,用OWL表示的本体在转换为图形结构时,往往会有一定程度的语义损失。如何在图形转换时把本体中蕴涵的丰富的语义信息传递到有限的图形元素中,是这种本体模块描述方法所面临的一个难题。
本文将粒度计算的理论与方法引入本体模块化研究领域,提出了一种基于粒度的本体模块描述方法,以解决本体模块边界区分困难的问题。粒度计算是信息处理的一种新的概念与计算范式,是对于利用粒度(群、类、簇)概念来解决问题的理论、方法以及技术的通称[ 8]。粒度计算的基本思想实质上是用简单易求的、低成本的、足够满意的近似解来替代精确解。基于粒度的本体模块描述方法通过对OWL本体中的基本元素附加粒度描述信息来达到描述本体模块的目的,可以有效地复用现有的丰富的OWL本体资源。
本体作为一种表达、共享与重用知识的方法[ 9],是由类、实例、关系等基本元素构成的。在本体知识管理中,如果以本体实例、关系这些本体基本元素作为知识单元,显得粒度太细,会产生语义缺失等问题;如果以本体库或者本体文档作为知识单元,又显得粒度太粗, 缺乏知识揭示、演化、管理与利用的灵活性[ 10]。显然,在这些知识单元中不存在显式的粒度描述方法。但通过分析本体结构的特点,可以从中析取出有助于确定本体粒度的一些信息,进而形成基于粒度的本体模块描述方法。
在粒度计算理论中,粒度是指对信息颗粒大小的衡量,可以看作是对问题从不同层次所进行的抽象与凝练。体现粒度的一个重要方面是事物之间的序关系(Order Relation)。在不同的情境中,序关系可以有不同的定义与解释,例如,可以是集合之间的包含关系[ 11],也可以是地理位置的层次关系[ 12],还可以是任务与子任务之间的关系[ 13]等。这种序关系往往具有传递性,也可以具有自反性,但不能具有对称性。考虑到序关系在体现粒度方面的重要性,不妨假设在本体中也存在这样的关系,并依据这种关系定义本体的粒度属性。
定义1:本体的粒度属性
给定本体中的一个对象属性域U,如果在U上的属性集之间存在序关系,即具有传递性但不具有对称性的关系,则这种属性称为本体的粒度属性。
粒度属性可以是本体中显式存在的属性知识,也可以是隐含的、抽象的属性。
在本体结构中存在着层次性与分面性,二者都是本体的粒度属性。
本体的核心元素是概念以及概念之间的语义关系。概念之间的语义关系可分为层次语义关系与非层次语义关系。最常见的层次语义关系有上下位关系(Hyponymy Relation)与部分/整体关系(Meronymic Relation)。本体中存在的上下位关系与部分/整体关系使得本体结构具有层次性。上下位关系与部分/整体关系都具有传递性而不具有对称性[ 14],符合粒度计算理论中关于序关系的要求,因此它们可看作本体域中的一种序关系。
具体而言,本体结构中的层次性主要体现在以下三个方面:本体的类结构与实例结构之间的层次性、本体的类结构内部的层次性以及本体的实例结构内部的层次性。
OWL本体从整体结构上可分为类结构和实例结构两个部分。实例结构是类结构的具体实现,可看作类结构的下层内容。
以本体Wine.owl[ 15] 为例, “WineBody”、“Winery”、“VintageYear”、“Region”等类概念词组成了类结构,而每个类又由若干个不同的实例组成。例如,类“WineBody” (酒体,指酒中所含固形物浓度)由“Full”、“Medium”、“Light”这三个具体的酒体实例组成。再如,类“Region”由“USRegion”、“AustralianRegion”、“FrenchRegion”等具体的地区实例组成。显而易见,类结构与实例结构之间存在着层次上的隶属关系,每个实例都可在类结构层面上找到其对应的类,因而整个实例结构可以看作是类结构的下层结构。
在本体类结构内部,类与类之间通过关系词联系起来。OWL规范中定义的主要类间关系词包括“subClassOf”(子类)、“equivalentClass”(等价类)、“intersectionOf”(交运算)、“unionOf”(并运算)、“complementOf”(补运算)、“disjointWith”(不相交类)等,其中“subClassOf”是具有传递性的类间关系描述词,类与类之间通过此关系形成层次结构。
在本体实例结构内部,实例与实例之间的关系主要通过对象属性来描述,例如在本体Wine.owl中,对象属性“locatedIn”是传递属性,其对象域为“owl#Thing”,范围是“#Region”。利用对象属性可以描述实例之间的关系,如下面的OWL语句描述了类“Region”的实例“CaliforniaRegion”位于“USRegion”,而其另一实例“NapaRegion”又位于“CaliforniaRegion”,由于“locatedIn”是传递属性,因此可以推出“NapaRegion”位于“USRegion”,也就是说“NapaRegion”、“CaliforniaRegion”、“USRegion”等实例通过传递属性“locatedIn”形成了一个层次结构。
本体实例结构内部的层次性由实例与实例之间的传递性关系决定,这种传递性关系也是本体域中的序关系。
通过以上分析可知,本体结构中的层次性符合本体粒度属性的定义,是本体的一种粒度属性。
需要强调的是,本体中的层次关系是本体的一种粒度属性,但对本体进行粒度分析的目的是要借助于本体粒度来解决本体模块化的问题,而仅仅通过本体中的层次关系还不能完整地表达本体模块的自含性,尤其是模块和那些与之没有层次关系的模块之间的复杂关系。为此,本文引入分面分类方法来梳理这些复杂的语义关系。
本体是用于描述或表达某一领域知识的一组概念或术语,可用于组织知识库较高层次的抽象概念,也可以用来描述特定领域的知识[ 16],呈现出多侧面、多维度的特点,例如:很多本体中都包含了时间、空间、物质等方面的内容;另一方面,对于本体用户而言,他们关心的往往是某一主题在一定范围、一定层次内的概念及关系,而分面分类理论是用于划分主题的一种重要理论,因此,借助于分面理论也易于描述用户对本体模块的需求。
分面分类法本是为方便标引文献而提出的一种分类方法。由于其类目体系自由、灵活,且适合于计算机处理[ 17],因此在搜索系统[ 18]与网络信息组织[ 19]中也得到了成功的应用。这里引入本体分面的概念,目的在于利用分面分类理论来揭示本体的粒度特征。
Harter把分面定义为一组概念,这些概念对于一个给定的信息搜索需求而言,搜索者认为它们是等价的,也就是说它们是同义的[ 20]。
依据这种观点,本文给出如下的“本体分面”定义。
定义2:本体分面
本体分面是一组概念,这些概念对于一个给定的本体需求而言,本体用户认为它们是等价的,也就是说它们是同义的。
本文把本体的概念词、关系词等基本构成元素通称为“本体词项”。对本体进行分面划分主要就是要对各种“本体词项”分别进行分面划分。
例如,本体Wine.owl中的部分类概念词及对应的实例概念词如表1所示:
| 表1 本体Wine.owl中的部分“类概念词”及对应的“实例概念词” |
如何对这些概念词进行分面划分呢?按照定义2,一个本体分面是一组概念词,这些概念词从某种需求意义上而言是等价的。
印度著名的学者阮冈纳赞(Ranganathan)提出了一种通用的分面分类方法——冒号分类法[ 21],这种方法提出从以下5个分面对主题进行分类:
(1) 本性(Personality):最基本的分面,本质属性。
(2) 物质(Matter):物质、材料等。
(3) 能量(Energy):各种活动、影响、状态及问题。
(4) 空间(Space):空间、位置等。
(5) 时间(Time):与时间有关的内容。
这种分面的思想与方法对于表1中所列出的 “类概念词”及 “实例概念词”也是适用的。例如,类概念词“WineBody”及其实例概念词可划分到“Personality”及 “Matter”分面中,类概念词“Winery”及其实例概念词可划分到“Personality”及 “Energy”分面中,类概念词“VintageYear”及其实例概念词可划分到“Time”分面中,类概念词“Region”及其实例概念词可划分到“Space”分面中。
分析本体Wine.owl中的另一个重要组成部分“关系词”的分面性。本体Wine.owl中的“关系词”如表2所示。这些词显然也可按冒号分类法进行分面划分。例如,关系词“adjacentRegion”和“locatedIn”可划分到“Space”分面中,而关系词“hasVintageYear”可以划分到“Time”分面中。
| 表2 本体Wine.owl中的“关系词” |
利用分面分类法对OWL本体中的“类概念词”、“实例概念词”、“关系词”等各种词项进行划分,可将这些词项切分为不同分面上的词项集合。
需要说明的是,冒号分类法是对本体词项进行分面分类的一种方法,但并不是唯一的方法。针对不同本体的具体内容,可选择不同的分面方法。
分面集之间存在序关系,例如:
{Space}⊂{Space, Time}⊂{Space, Time, Matter}
在必要的情况下,还可将各个分面进一步区分为若干个子分面、子分面又可区分为子子分面,而这样的分面结构显然也满足序关系的条件,是本体域中的序关系。本体的分面性也是本体的一种粒度属性。
综上所述,本体结构中存在的层次性与分面性都是本体的粒度属性。
在上节中,论述了本体结构中存在的层次性与分面性是体现本体粒度特征的重要属性。利用这两种粒度属性,可对本体进行模块划分,即基于粒度进行本体模块划分。因此,在“本体的粒度属性”这一概念的基础上,本文给出如下 “基于粒度的本体模块”定义。
定义3:基于粒度的本体模块
本体模块可定义为一个三元组(T,F,L)。其中:
T(Terms)是一个由本体词项(即本体基本元素,包括类、实例、关系词等)构成的集合;
F(Facets)是由若干分面词构成的集合,用于表征本体模块所具有的分面特征;
L(Level)表示本体分面所具有的层次,可从1层开始,逐层递增,1层表示最粗粒度,层次值越大,粒度越细;也可采用与之相对应的权值范围来描述。
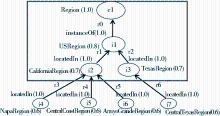
图2所示是本体Wine.owl中的一个片段,对应了分面“Space”上的一部分本体内容,每个词项后面的数值是该词项在分面“Space”上的层次表示值。为了更精确地描述这种层次关系,这里没有直接用从1开始的层次值,而是使用了范围在 [0,1] 之间的层次权值。权值越大,所表示的粒度越粗。当权值为1时,表示该词项就是该分面词或其同义词,所表示的粒度最粗。
 | 图2 基于粒度的本体模块表示方法示例 |
在图2中,方框内的部分是分面为“Space”、层次的权值范围为 [0.7,1.0]的本体模块,其中包括了节点“c1”、“i1”、“i2”、“i3”和边“r0”、“r1”、“r2”。这些词项对应于分面“Space”的层次权值都在[0.7,1.0]范围内,而且边“r0”、“r1”、“r2”对应的节点也都在这个权值范围内。
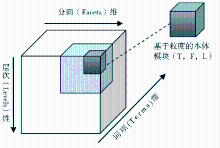
基于粒度的本体模块被定义为一个三元组(T,F,L),其中T为本体词项、F为分面集、L为层次值。这样一个本体模块所具有的语义可用图3来表示:
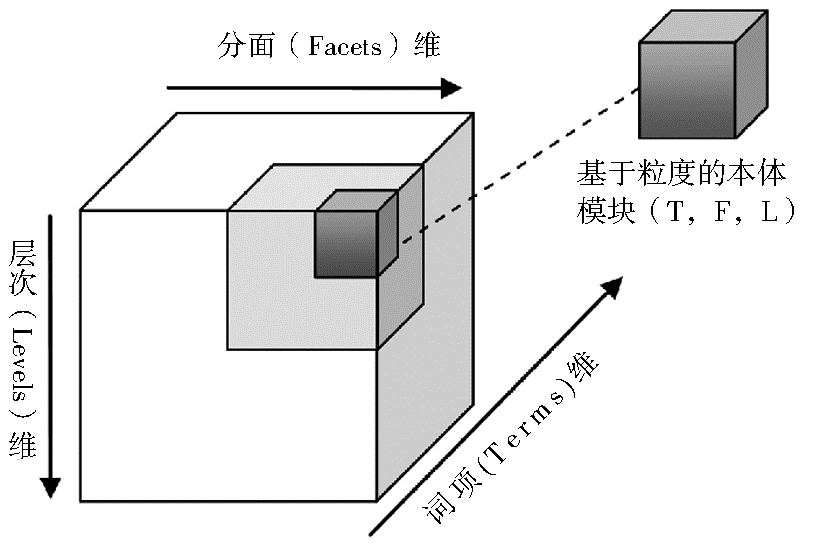 | 图3 基于粒度的本体模块划分 |
在图3中,本体模块被抽象表示为一个由本体词项(Terms)维度、分面(Facets)维度和层次(Levels)维度所构成的三维空间。本体词项是本体中原有的构成成分,由类概念词、实例概念词、关系词集、概念断言、实例断言等构成。分面和层次则是依据本体中概念词、关系词等语义信息而抽象出的表征本体粒度特征的信息。在这样一个三维本体中,本体模块被解释为具有相同的分面信息与层次信息的概念以及概念之间的关系。分面、层次取值的变化使得对应本体粒度的内容动态可调。也就是说,符合上述定义的本体模块的粒度是由其分面、层次的取值来决定的。
本体模块的表示方法是在本体模块化方向研究最多的问题之一,是实现本体模块化的核心与基础。
本文针对用户对本体需求的模糊性与本体描述的专业化、本体内容的巨量化之间存在的矛盾,提出把粒度计算方法与分面分类理论结合起来,形成基于粒度的本体模块描述方法,帮助用户把模糊的本体模块需求较为清晰地表达出来。下一步将在这种本体模块描述方式的基础上,建立一种基于粒度的本体模块抽取方法,以提高本体模块抽取的准确性和精确度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|