{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于通用搜索引擎的深层网络表面化方法研究
[郭少友 ]
]
]
|
|


On the basis of related works, this paper analyzes the basic principle of deep Web surfacing based on common search engines. Several key issues related to the deep Web surfacing are discussed, which include determination of value ranges of form fields, query processing, and hyperlink setting in result pages.
深层网络是指Web中难以直接被传统的搜索引擎索引到的那部分内容[ 1, 2],包括通过填写并提交查询表单才能访问的在线数据库(以下称为深层网络数据库)、由于缺乏被指向的超链接而不能被搜索引擎索引到的页面、访问受限的网站等类型。其中深层网络数据库的数量庞大、数据结构化程度高,是主要的深层网络信息资源。用户可以通过以下两种方式来访问深层网络数据库:通过某种途径(如CompletePlanet)获取数据库的网址,直接通过其查询接口来访问;通过垂直搜索引擎来访问。
前者需要用户花费时间和精力来发现数据库,而且可能需要在不同数据库的查询接口之间切换;后者对用户的查询请求有一定的限制,当用户想获取多个主题领域的信息时,需要访问多个垂直搜索引擎。如果能由通用搜索引擎来爬行、索引深层网络数据库,将会为用户带来极大的方便。深层网络表面化是指通用搜索引擎用适当的查询词自动填写查询表单,提取深层网络数据库的Web服务器动态生成的页面,并像处理静态网页那样来保存、索引这些页面。当搜索引擎的查询结果中包含了深层网络数据库的内容时,用户既可通过网页快照来查看缓存在搜索引擎页面数据库中的深层网络数据库内容,也可点击查询结果标题下的超链接来直接查看位于深层网络数据库中的原始数据。目前Google、百度等已经开始这方面的尝试,用户通过它们可以检索到一些深层网络数据库的内容。本文将在现有相关研究的基础上,对基于通用搜索引擎的深层网络表面化方法的基本原理和若干关键问题进行探讨。
查询表单的自动识别是深层网络表面化的首要工作。深层网络数据库一般都在其网站上提供一个查询接口,该接口以HTML表单的形式存在,定义在标签Form中。Doan等[ 3]分析了表单的自动识别、表单的输入项以及每个输入项对应的输入值等问题。Raghavan等[ 4]设计的HiWE系统借助于爬行器下载网页,并利用表单分析器识别表单接口。BrightPlanet公司[ 5]的深层网络资源查询管理器DQM实现了表单接口的自动化处理。
能表达数据库主题的关键词的自动提取是深层网络表面化的另一项重要工作。从深层网络数据库中提取能够表达数据库主题的关键词,一般需要对数据库进行抽样。Callan等[ 6]提出了一种选择关键词的算法,用一些初始关键词进行检索,根据检索结果对初始关键词进行优化,不断地重复上述优化过程直到得到满意的结果为止。Ipeirotis等[ 7]描述了从文本数据库中检索文档并在此基础上生成数据库的关键词摘要的算法。
查询条件的自动构建是深层网络表面化的核心步骤。查询条件的优劣直接影响搜索引擎从深层网络数据库中提取的数据量,从而影响搜索引擎对数据库的覆盖率。搜索引擎应能针对任一深层网络数据库自动生成一组优质的查询条件。Ntoulas等[ 8]讨论了用迭代法生成查询条件的方法。Wu等[ 9]讨论了每次只用一个输入框来生成查询条件的情况。Byers等[ 10]讨论了可以输入邮政编码等特殊类型信息的表单域的处理方法。
搜索引擎爬行器对深层网络数据库的爬行是深层网络表面化的关键步骤。Google公司的Madhavan等[ 11]提出了一个深层网络表面化方法,该方法针对每个GET型表单生成有意义的表单提交(Form Submissions),将每个表单提交看做一个独立的URL,并将其放入URL列表中供爬行器爬行。Madhavan等人的方法不处理提交方式为POST型的深层网络数据库,也不考虑查询表单中所包含的脚本。百度公司于2008年启动了阿拉丁计划,其重要目标之一是挖掘深层网络中的有用信息[ 12],但未透漏技术细节。
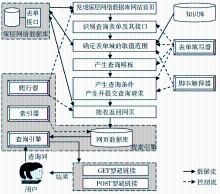
基于通用搜索引擎的深层网络表面化方法的目标是用户在通用搜索引擎中能查询到尽可能多的深层网络信息,其基本原理如图1所示:
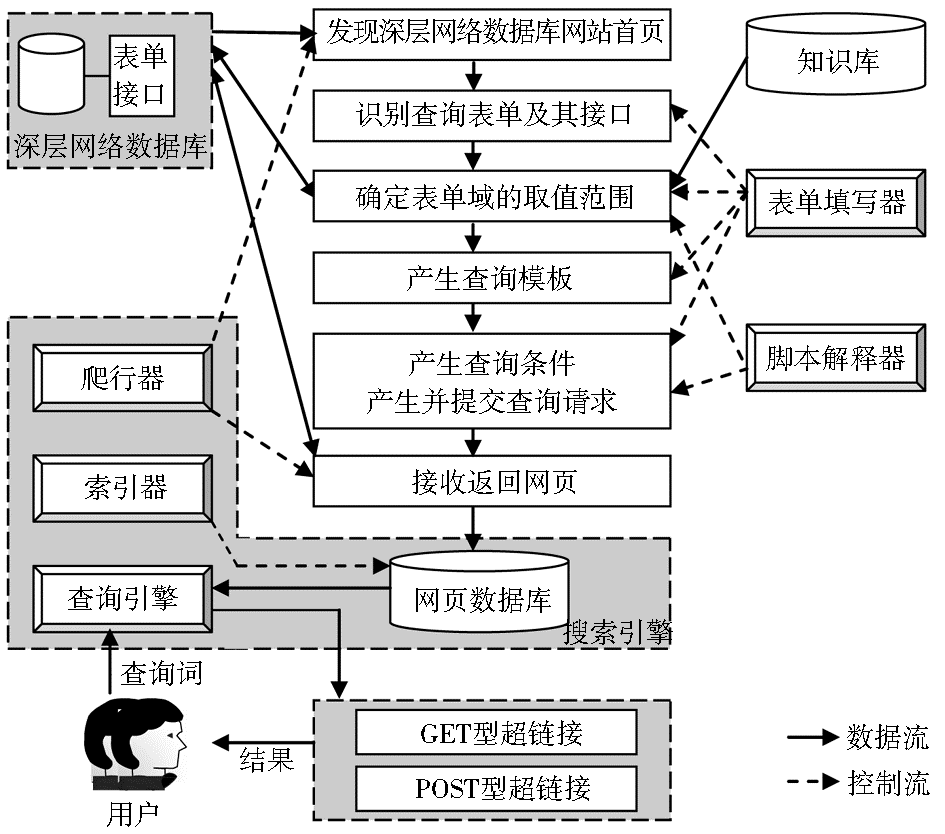 | 图1 基于通用搜索引擎的深层网络表面化方法逻辑结构 |
(1)通过搜索引擎的爬行器发现深层网络数据库网站首页。
(2)由表单填写器识别网页中的表单,提取表单所包含的标签、表单域和表单按钮,判断表单的类型。如果表单含有与个人信息无关的文本框或其他可用来选值的表单域,则该表单很可能对应于一个可供查询的数据库,可将其看做信息查询表单。基于通用搜索引擎的深层网络表面化只处理信息查询表单,而忽略其他类型的表单。
(3)确定表单域的取值范围。针对不同类型的表单域,表单填写器需要分别采用相应的方法确定其取值范围。如果某个表单域或表单按钮包含事件脚本,则需要调用脚本解释器来执行相应的脚本,因为有些表单域可能需要通过执行事件脚本来确定其取值范围。
(4)产生查询模板。表单填写器根据表单域的特点,从一个信息查询表单的所有非隐藏表单域中选择若干个域组成一至多个查询模板。
(5)产生查询条件、产生并提交查询请求。表单填写器为查询模板中的表单域分配具体的取值,通过计算模板中表单域之间的笛卡尔积来产生一组查询条件。在此基础上,根据信息查询表单的提交方式对查询条件进行处理,将其转换为GET型或POST型的HTTP请求后提交给深层网络数据库的查询接口程序。
(6)利用通用搜索引擎现有的技术方法来接收、存储、索引返回网页。
(7)在用户检索阶段,如果某条结果记录来自深层网络数据库,则查询引擎根据其提交方式来确定到该数据库的链接形式。如果提交方式为GET,则结果记录中标题下的超链接采用GET型超链接;如果提交方式为POST,则采用POST型超链接(具体方法见本文4.3节)。
基于通用搜索引擎的深层网络表面化涉及一系列的问题,以下仅对表单域取值范围的确定、查询处理、查询结果的超链接设置等关键问题进行讨论。
(1)表单域类型分析
根据表单域的特点及赋值要求的不同,可将信息查询表单中的表单域分为文本框型表单域、非文本框型表单域两种类型,每种类型又分别分为两种子类型,如表1所示:
| 表1 表单域的类型 |
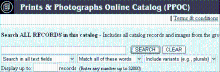
SC1型表单域可以输入任意关键词,而SC2型表单域要求输入特定类型的数据,如邮政编码、日期、价格或记录数等,而且这些数据有一定的取值范围。例如在图2中,表单按钮SEARCH左面的文本框属于SC1型表单域,可以输入任意关键词,而底部的文本框则属于SC2型表单域,要求输入1-32 000之间的整数。
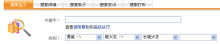
SC3型表单域的取值范围是固定的。在含有SC4型表单域的表单中,当一个表单域的取值发生变化时,另一个表单域的取值范围会随之发生变化,原因在于两个表单域彼此有关联关系,前一个表单域的事件脚本控制着后一个表单域的取值范围。例如在图3中,底部从左至右有c1、c2、c3、c4四个下拉列表框,关联关系为c1→c2→c3→c4,其中c1属于SC3型表单域,c2、c3、c4属于SC4型表单域。当从c1的值列表中选择某个值如“男装”时,c1的Onchange事件发生并自动为c2生成值列表(值列表中的关键词都与“男装”有关),此时c1的Onchange事件脚本控制着c2的取值范围。SC4型表单域具体可以是受事件脚本控制的下拉列表框、复选框、单选按钮组或隐藏域。
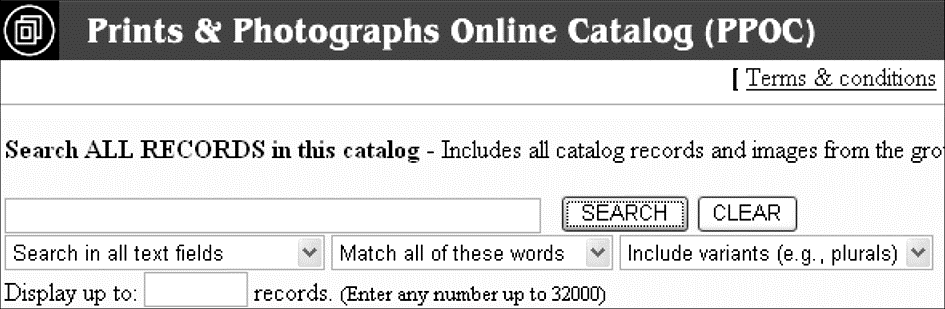 | 图2 两种类型的文本框型表单域示例① |
 | 图3 两种类型的非文本框型表单域示例② |
(2)确定表单域取值范围的方法
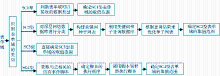
表单域的类型不同,其取值范围的确定方法也不同。SC3型表单域的取值范围较易确定,可根据表单域的标签名和Name属性值,通过解析HTML文档直接得到所有可能的取值,从而得到其取值范围。另外三种表单域取值范围的确定方法稍微复杂一些,基本步骤如图4所示。
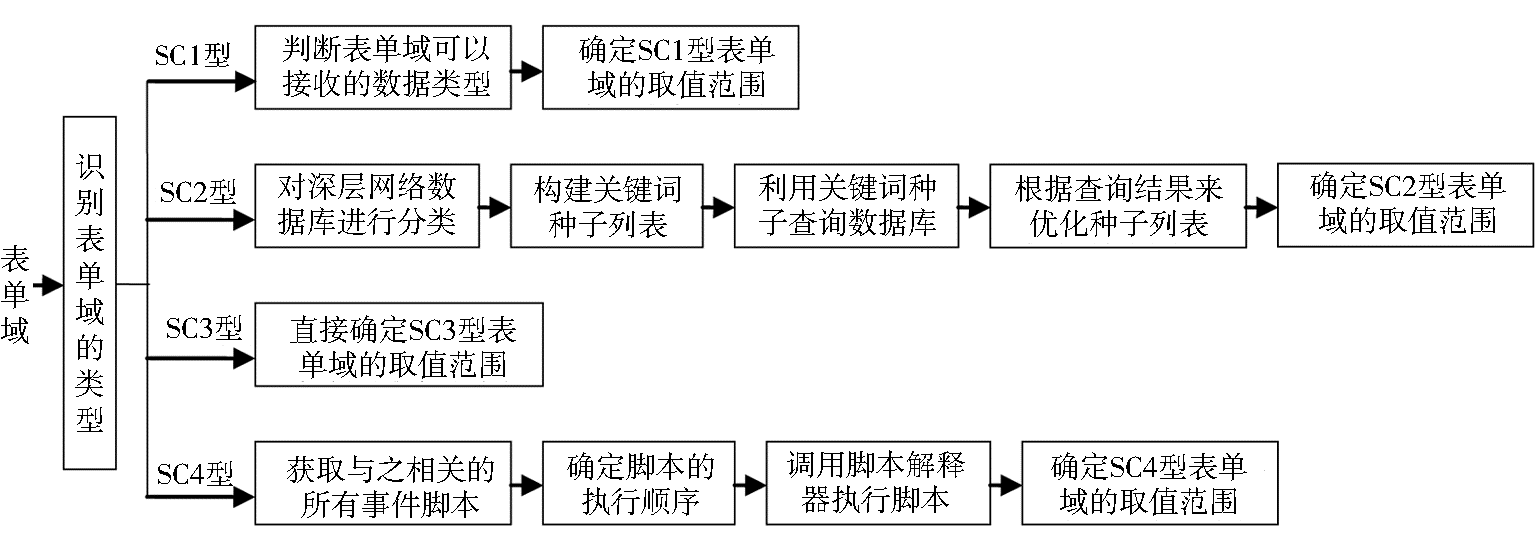 | 图4 表单域取值范围的确定方法 |
在图4中,如果表单域是SC1型表单域,在判断表单域可以接收的数据类型时,可以用多组不同类型的数据进行填充,每组都包含若干个类型相同且具有代表性的数据。进行多次尝试查询之后,表单填写器根据返回结果基本可以判断表单域所要求的数据类型,如邮政编码、日期、价格或记录数等。在此基础上,表单填写器根据已确定的数据类型的特点,借助于事先建立的相关知识库,选择一组数量更大的数据并轮流填充到表单域中,根据返回结果数的多少大致可以确定表单域的取值范围。
① http://lcweb2.loc.gov/pp/pphome.html
② http://search1.taobao.com/browse/ad_search.htm
如果表单域是SC2型表单域,可以采用现有的方法对深层网络数据库进行分类,然后根据数据库所属的类别从网络分类目录体系中提取适量的关键词作为种子。为了提高关键词种子的质量,根据数据库所属的某个类别所提取的关键词数目应与该类别和数据库之间的相关度有关,相关度越高,则提取的关键词越多,反之,则越少。在优化种子列表时,可从返回结果中抽取TF×IDF值最高的部分关键字加入到种子列表中,重复该过程,直到种子列表不再发生变化为止。最后可从种子列表中提取TF×IDF值最高的若干个关键词作为SC2型表单域的取值范围。
如果表单域是SC4型表单域,在确定其取值范围时,需要考虑Onclick、Onfocus、Onchange、Onblur、Onsubmit、Onreset等可能对表单域有影响的HTML事件,提取与这些事件相关联的脚本,识别各个脚本的类型及存在方式,并调用相应的脚本解释器来执行。根据HTML的规定,同一表单域的多个事件的发生顺序为:Onclick→Onfocus→Onchange→Onblur→Onsubmit→Onreset,表单填写器在调用脚本解释器执行脚本时,也要遵循这一顺序。
信息查询表单一般包含多个表单域,可将对查询结果有较大影响的部分表单域提取出来,形成查询模板,并根据查询模板中各个表单域的取值范围来形成一系列的查询条件。在查询条件的基础上生成查询请求并提交后,需要对返回结果进行特殊的处理。查询处理流程如图5所示。
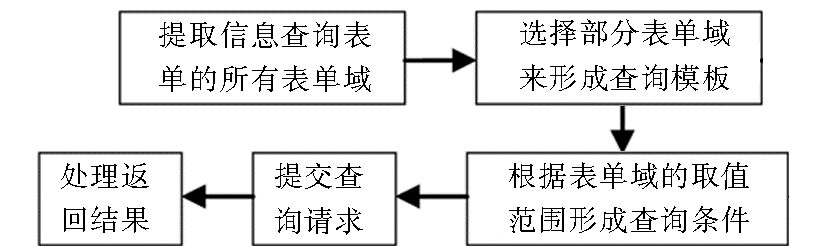 | 图5 查询处理流程 |
在形成查询模板时,如果表单中存在SC1型表单域,表单填写器可忽略其他类型的表单域,将该表单域作为查询模板的唯一元素;如果不存在SC1型表单域,则将所有的非隐藏表单域作为查询模板的元素。在形成查询条件时,将查询模板之外所有表单域的取值设为默认值,然后计算查询模板中各个表单域的笛卡尔积,最后依次从笛卡尔积中提取元素,与上述默认值一起形成一系列的查询条件。
在查询条件的基础上生成查询请求时,需要获取深层网络数据库的查询接口地址及表单提交方式。前者可根据数据库网站的URL和表单的ACTION属性值来决定,后者则由表单的METHOD属性值决定。根据提交方式的不同,表单填写器可为每个查询条件分别形成相应的HTTP请求并提交给深层网络数据库。
搜索引擎在处理深层网络数据库返回的结果网页时,需要做以下工作:对结果网页进行分析,如果返回的记录数少于规定的阈值,则认为其信息量不足,可忽略对该网页的保存和索引;如果返回的记录数大于等于规定的阈值,则根据信息查询表单的提交方式为该网页分配一个URL。当提交方式为GET时,可根据深层网络数据库的接口要求,将各种参数名及其值添加在数据库查询接口程序的后面,用“?”隔开,形成一个包含查询条件的URL。当提交方式为POST时,也仿照GET方式,形成一个包含查询条件的特殊形式的URL。搜索引擎的索引器将上述URL视为结果网页的来源地址,对网页进行索引。
需要说明的是,向深层网络数据库每提交一次查询请求,都可能返回很多条数据库记录,且往往是分页显示。在对返回结果进行处理时,有两种不同的方法:只保存、索引首页;除首页外,对后续网页也进行保存、索引。
第一种方式较为简便,但降低了用户直接在搜索引擎中检索到后续网页中的数据的概率。第二种方式提高了搜索引擎对数据库记录的覆盖率,但可能出现提交一次查询请求就能得到成百上千个网页的情况,从而引起网页数据库和索引库的急剧膨胀。本文的实验采用第一种方法。
按通用搜索引擎(如百度、Google)的现有做法,每条查询结果一般都至少包含两部分内容:网页标题和网页摘要,其中标题部分大都包含了一个超链接,指明了该查询结果的来源地址。从深层网络数据库中爬取回来的数据以网页的形式保存在网页数据库中,用户通过搜索引擎的查询引擎(也称检索引擎)可以检索到这些网页。为了让用户在检索到这些网页之后能进一步到相应的深层网络数据库中查看原始数据,查询引擎在显示查询结果时,需要根据现有的做法,在相应查询结果的标题下添加一个超链接,其值即为4.2节所讨论的来源地址。
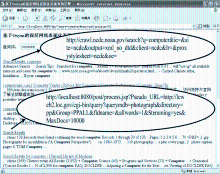
如果某条查询结果来自GET型深层网络数据库,查询引擎在显示结果记录时,可直接在其标题下添加一条其URL形如“http://crawl.ncdc.noaa.gov/search?q= computer&ie=&site=ncdc&output=xml_no_dtd&client=ncdc&lr=&proxystylesheet=ncdc&oe=”的超链接。上例中的URL是表单填写器在GET型深层网络数据库National Climatic Data Center (NOAA)的文本框中填入“computer”后生成的,爬行器可以利用该URL从该数据库中爬行数据;用户在查询引擎中检索到该数据并点击上例中的超链接后,可以通过该URL查看位于该数据库中的原始数据。
如果某条查询结果来自POST型深层网络数据库,查询引擎在显示结果记录时,无法在标题下添加能直接查看深层网络数据库中相应的原始数据的超链接,这是由POST型表单提交方式的特点决定的。可采用如下方法来解决这一问题:在标题下添加一条其URL为“http://localhost:8080/post/process.jsp?Pseudo_URL= http://lcweb2.loc.gov/cgi-bin/query?querymdb=photograph&directory=pp&Group=PPALL&fldname=&allwords=1&Stemming=yes&MaxDocs=10000”的超链接,用户点击该超链接后,由搜索引擎的专用程序process.jsp代替用户来提取原始数据。上例中的URL是表单填写器在POST型深层网络数据库Prints & Photographs Online Catalog的文本框中填入“photograph”后生成的,其作用不是供用户直接到该数据库中查看原始数据,而是当用户在查询引擎的结果页面中点击上述超链接时,由process.jsp从该URL中提取相关参数,按HTTP协议的要求形成带实体部分的HTTP请求,代替用户向该数据库提出查询请求,以便查看相应的原始数据。
process.jsp可代替用户向指定的POST型深层网络数据库提交查询请求,其工作过程大致如下:
(1)接收参数Pseudo_URL。
(2)从Pseudo_URL中进一步析取数据库的查询接口地址(如上例中的http: //lcweb2.loc.gov/cgi-bin/query)和需要提交的参数值对。
(3)根据查询接口地址建立到数据库的连接。
(4)按HTTP协议的要求发送请求消息,其中参数值对安排在请求消息的实体部分。
(5)接收数据库返回的响应消息,将检索到的原始数据呈现给用户。
(1)数据准备
为了降低实验的复杂度,笔者通过手工方式选取了9个可公开访问的深层网络数据库进行处理,其中表单提交方式为GET型的数据库有7个,为POST型的有2个,如表2所示。
从数据库内容上看,既有主题较为单一的数据库如NIH PubMed、National Climatic Data Center(NOAA)等,也有综合性的数据库如LC Online Catalog、eBay.com等。另外,Commerceinc.com和Digital Library Program的查询表单均包含JavaScript脚本,但脚本的存在方式不同:前者所包含的脚本与事件连在一起,后者所包含的脚本以JS文件的形式存在。
| 表2 实验所用的深层网络数据库 |
本实验用到的资源主要有:Java开源搜索引擎Oxyus-0.2.3,Java开源脚本解释器Rhino1.7以及雅虎英文目录Yahoo! Directory。
(2)实验结果
在Oxyus的基础上建立的深层网络表面化原型系统查询结果界面如图6所示:
 | 图6 基于Oxyus的深层网络表面化原型系统查询结果界面及两种类型的超链接示例 |
图6中的所有记录均是在输入查询词“computer”之后,原型系统从其网页数据库中检索得到的,这些记录所对应的网页则是原型系统事先从各个深层网络数据库中爬行得到的,例如,第一条记录所对应的网页是从数据库National Climatic Data Center (NOAA)中用关键词“computer”爬行得到的,用户点击标题下的超链接即可通过“http://crawl.ncdc.noaa.gov/search?q=computer&ie=&site= ncdc&output=xml_no_dtd&client=ncdc&lr=&proxystylesheet=ncdc&oe=”重新查询数据库并得到原始数据;第4条记录所对应的网页是从数据库Prints & Photographs Online Catalog中用关键词“photograph”爬行得到的,用户点击标题下的超链接,则由原型系统的process.jsp代替用户向该数据库提交POST型的查询请求,并得到原始数据。
通过实验发现,原型系统对表2中非隐藏表单域个数为1的5个数据库的爬行效果较好,分别都得到了500个结果网页;对非隐藏表单域个数为2的3个数据库的爬行效果也较好,所得到的结果网页数均在495个以上;而对数据库Prints & Photographs Online Catalog的爬行效果相对要差一些,只得到483个结果网页。导致上述情况发生的原因可能在于部分非隐藏表单域的默认值与SC1型表单域的某些取值组合成查询条件时,从数据库中检索得到的结果记录数为0,而原型系统不保存和索引结果记录数为0的返回网页。
由于笔者并不能确切地获悉表2中9个数据库的实际规模,因此无法估算原型系统的表面化结果对各个数据库的覆盖率大小。
深层网络表面化涉及信息查询表单的识别、表达数据库主题的关键词的自动提取、查询模板和查询条件的自动构建、查询请求的自动提交、查询结果的超链接设置等问题。本文在现有研究的基础上做了以下工作:
(1)对基于通用搜索引擎的深层网络表面化方法的基本原理进行了较为系统、完整的描述;
(2)讨论了不同类型表单域取值范围的确定方法;
(3)讨论了POST型深层网络数据库的表面化方法,包括与之相关的查询处理、查询结果的超链接设置等问题。
下一步的工作是对基于Oxyus的深层网络表面化原型系统进行完善,包括以下几个方面:
(1)逐步完善知识库,使原型系统能更准确地确定SC2型表单域的取值范围;
(2)对查询模板的产生过程进行优化,以便一个信息查询表单可以产生一至多个查询模板,并且将与数据库内容相关的表单域和与结果排列方式相关的表单域(如控制每页显示记录数的表单域)分别加以考虑;
(3)完善信息查询表单识别功能,使之能自动处理更多的深层网络数据库。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|