
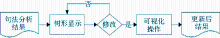

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
中英文句法分析系统及验证平台的设计与实现
[祝清松 , 王惠临]
, 王惠临]
, 王惠临]
|
|


针对改善句法分析整体性能的需求,从可视化编辑学习的规则和词典、树形显示和操作句法分析结果两方面入手,提出并构建一个中英文句法分析系统及验证平台。对平台的设计思想、具体实现和关键技术进行详细的介绍,指出存在的问题和改善的方法。
For the need of improving the overall performance of syntactic analysis, the paper puts forward and builds a syntactic analysis system and verification platform for Chinese and English in the two views of visually editing rules and dictionaries learned from training file as well as displaying and operating results of the syntactic analysis by tree. It also introduces the design ideas, key technologies and concrete implementation in details, and points out the existing problems as well as the improvement measures.
句法分析是自然语言处理研究的关键性问题之一,其主要任务是自动识别句子的句法结构,即句子包含的句法单位以及这些句法单位相互之间的关系。句法分析的结果直接决定着以统计机器翻译、信息抽取、信息检索和自动文摘等为代表的自然语言处理应用系统的最终性能[ 1];句法分析是语义、语用等自然语言处理深层研究的基础[ 2],因此,句法分析技术的研究具有重要的理论意义和应用价值。句法分析研究己经获得长足的进展,然而,在通往实际应用的路上仍然存在很多困难,尤其是中文方面,句法分析的准确率并不高,尚未达到实用化的阶段,句法分析研究任重而道远[ 1]。
国内外对句法分析的研究主要分为基于规则的方法和基于统计的方法。纯粹基于规则的句法分析有歧义问题、鲁棒性问题和规则冲突问题等[ 3],无法解决处理大规模真实文本时自然语言的高度复杂性和歧义性[ 1]。而基于统计的方法以大规模语料库为基础,通过训练学习获取模型,具有明显的客观性和优越性,目前国内外研究都是以基于统计的方法为主。
传统的句法分析技术开发包括人工构建规则和词典、实现执行算法;统计的句法分析技术开发包括准备训练数据、实现学习算法和执行算法,学习算法通过对训练语料的学习来获得句法模式,相当于传统开发方法中的规则和词典。为提高统计句法分析的性能,国内外学者大多都是从计算机科学的角度出发,通过改变机器学习策略、句法分析算法等来改善句法分析的精度[ 4]。
本文以统计的句法分析技术为依托,在机器学习策略和句法分析算法不变的情况下,从计算语言学的角度入手,试图通过可视化编辑训练学习的规则和词典以及通过操作树形来改变句法分析结果,将传统和统计的句法分析技术开发方法进行有机结合,达到验证句法分析结果和提升句法分析整体性能的目标。
(1)可视化编辑句法模式文件
句法分析模型的训练包括两个步骤:通过训练语料的学习获取包含规则和词典等的句法模式文件;根据句法模式文件编译出用于句法分析应用的句法模型。平台要实现对句法模式文件的可视化编辑,然后将编辑后的文件作为新的规则和词典文件,编译生成人工校正后的句法模型。该过程用到的方法来源于传统的句法分析技术开发方法。
(2)通过树形操作改变句法分析结果
平台要将抽象的句法分析结果转换成直观的树形显示,然后通过人工校验树形的正确与否,对于需校正的地方直接在树形上进行可视化操作,达到改变句法分析结果的验证目的。可视化验证后的句法分析结果准确率提升,该结果可以作为原来训练语料的补充,从而训练语料的质量和规模都得到提高,重新训练会得到准确率更高的句法分析模型。这种通过可视化技术来提升树库规模和质量的方法属于统计的句法分析技术开发方法。
因此,本文的主要研究目标是提出并构建一个中英文句法分析系统及验证平台,重点实现句法模式文件的编辑、句法分析结果的树形显示和可视化操作。
平台开发过程中用到的主要工具有OpenNLP工具包[ 5](英文断句)、Treebank Tokenizer[ 6](英文断词)、MXPOST[ 7](英文词性标注)、ICTCLAS[ 8](中文分词)、Stanford POS Tagger[ 9](中文词性标注)、Stanford Parser(训练语料生产)[ 10]和 Multilingual Statistical Parsing Engine[ 11](中英文句法分析)等。
平台对英文的处理遵循宾州树库词性集标准,对中文的处理遵循宾州中文树库词性集标准。平台的句法分析采用Bikel的多语言统计句法分析引擎,即Multilingual Statistical Parsing Engine(DBParser),它是由宾夕法尼亚大学的Bikel[ 12]设计实现的一个基于中心词驱动和线图算法的短语结构产生式句法分析器,提供了多种已实现的统计句法分析模型,包括对著名的Collins短语结构句法分析器[ 13]的模拟。目前的DBParser句法分析器通过Java实现,提供了英语、汉语和阿拉伯语的设置文件,并且分析性能较高[ 14]。
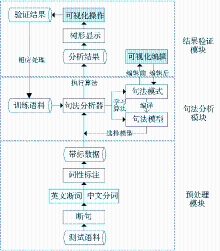
平台划分为三大模块:预处理模块、句法分析模块和结果验证模块。预处理模块的任务是通过词法分析和格式转换将待分析文本转换成句法分析器所需形式;句法分析模块能够训练句法分析模型,对预处理后的文本进行句法分析;结果验证模块对训练学习的规则和词典进行可视化编辑,实现句法分析结果的树形显示和可视化操作。其中,预处理模块和句法分析模块的实现是对上节中工具的整合和优化,一体化的设计避免了中间环节转换或操作的错误,比分别使用这些工具更加高效。结果验证模块的实现是本文的重点研究工作。平台的模块划分和总体架构如图1所示:
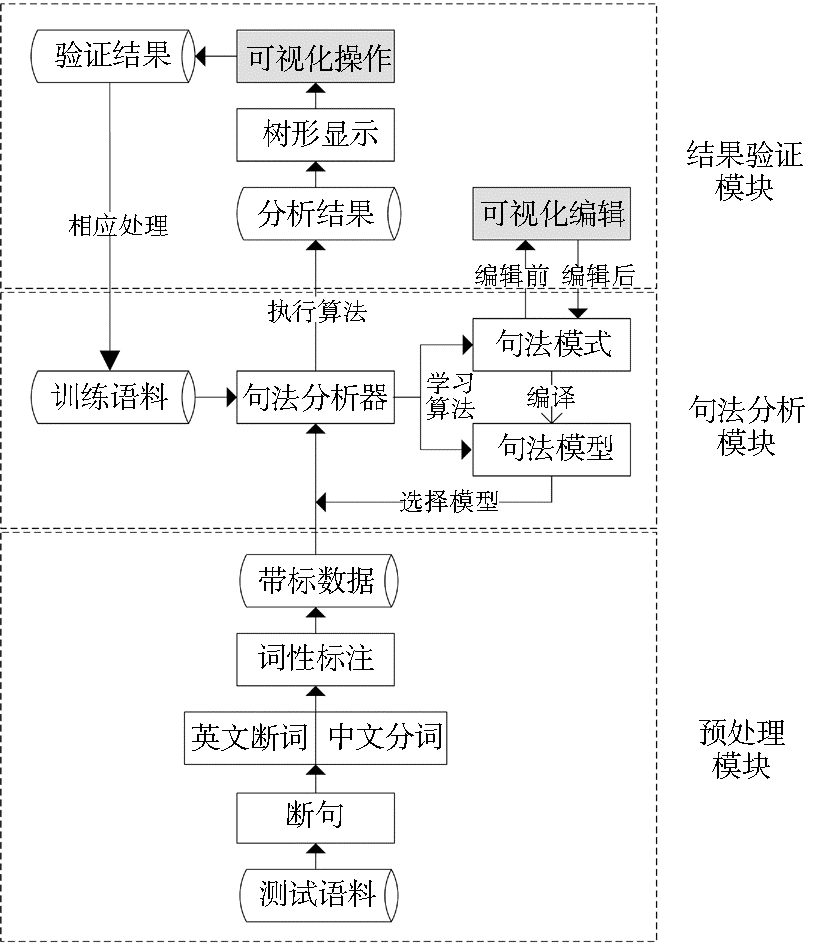 | 图1 平台功能模块和总体架构 |
根据对平台的总体设计,本文实现了中英文句法分析系统及验证平台,下面分别对平台三个关键技术模块的实现进行阐述。
预处理的任务是为句法分析器提供符合句法分析格式要求的文件。本文采用的句法分析器DBParser的格式要求为一行一个句子,每个句子的格式为((word1 (pos1)) (word2 (pos2))... (wordN (posN))),其中word表示单词,pos表示词性[ 15]。因此,预处理模块的目标就是将待处理文本转换成这种格式,比如对于“It’s a beautiful flower”这个句子,经过预处理需要得到((It (PRP)) (’s (VBP)) (a (DT)) ( beautiful (JJ)) (flower (NN)))形式的结果。
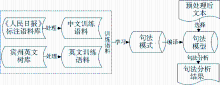
英文预处理模块包括断句、断词、词性标注和格式转换,中文预处理模块包括断句、分词、词性标注和格式转换,这些功能基本是通过对2.1节中工具的整合和调用来实现的,处理流程及对应工具如图2所示:
 | 图2 预处理模块处理流程图 |
预处理模块功能是将执行命令依次作为参数传入到指定函数运行实现的。Java中通过Runtime.getRuntime().exec(order)来实现调用本地命令和启动外部进程的功能,其中order是命令行参数。执行完命令后为了防止进程死锁要利用InputStreamReader来清空输入输出缓冲区。比如对中文进行词性标注,调用斯坦福大学的最大熵词性标注器Stanford POS Tagger,则调用命令order的赋值应为:
String order="cmd /c java -mx300m -classpath stanford-postagger.jar edu.stanford.nlp.tagger.maxent.MaxentTagger -model chinese/chinese.tagger -textFile CnSeg.txt > CnPos.txt";
其中,输入CnSeg.txt是分词后的文件,输出CnPos.txt是词性标注要生成的文件。平台将这些命令进行封装,只需点击相应的菜单项即可得到所需的结果。对于句法分析而言,中间的过程都可以忽略,因此平台提供一步执行的命令,即对于导入的文本平台可以一步得到句法分析所需格式的文件。
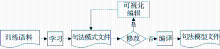
句法分析模块要实现句法模型训练和句法分析应用两大功能。本文选用的DBParser能够完成这两个任务,并选取中文和英文语言包分别用于实现中文和英文的句法分析任务。句法分析模块的处理流程如图3所示:
 | 图3 句法分析模块处理流程图 |
句法模型的训练首先需要准备训练语料:中文方面,选取1998年1月《人民日报》标注语料库[ 16]作为训练语料来源,去除语料编号、词性标记、专有名词标记等无用信息,合并姓氏和名字,经过断句转换成一行一句分词形式的语料,最后去掉长度过短的句子,通过Stanford Parser进行句法分析,最终得到含有42 212个句子的训练语料;英文方面,直接选取宾州英文树库[ 17]02-21部分共39 832个句子作为训练语料。
句法模型训练调用DBParser的danbikel.parser.Trainer类,用法为java -Xms800m -Xmx800m -Dparser.settingsFile=
句法分析调用DBParser的danbikel.parser.Parser类,用法为:java -Xms400m -Xmx400m -Dparser.settingsFile =
句法分析结果的形式为(S (NP(PRP It)) (VP(VBZ ’s) (NP(DT a) (JJ beautiful) (NN flower)))),可以看到括号的层级很多,不仅不容易看出句子的句法结构,而且修改起来很容易出错,因此有必要对该结果进行分析,并通过树形图显示和操作,直观地修改该结果。
结果验证模块是平台的核心模块,也是本文的重点工作,结果指的是从训练语料学习得到的句法模式文件和句法分析结果,前者操作主要是对模式文件的编辑和编译,处理流程如图4所示;后者操作包括对句法分析结果的树形显示、可视化操作和结果更新等功能,处理流程如图5所示:
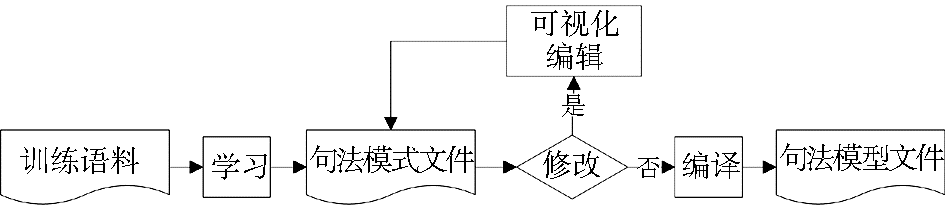 | 图4 结果验证模块处理流程(1) |
 | 图5 结果验证模块处理流程(2) |
(1)模式文件编辑与编译
句法模式文件编辑包括对模式文件的打开、修改和保存等操作,相当于一个文本编辑工具的功能。利用FileDialog对话框得到用户选择文件路径,通过字节数组输出流ByteArrayOutputStream将文件内容读取到平台的显示控件jTextArea上,用户即可进行编辑,编辑完成后用户点击保存,通过FileWriter将内容写入到新的文件中。
句法模式文件不能直接应用,需要对其进行编译,生成可用于句法分析的句法模型文件。该编译过程需要调用DBParser的danbikel.parser.Trainer类,用法为:java -Xms400m -Xmx400m -Dparser.settingsFile=
(2)树形显示及操作
树形显示和操作功能实现的基础是从句法分析后的结果获取所需的信息,包括节点编号ID、节点名称Label、节点深度Depth、节点高度Height、父节点Parent、子节点Child、兄弟节点Brother、节点类型Type(包含非终结符NT、词性标记POS和单词节点WD)和单词节点在句中位置Pos。除了Label定义为String,其余变量定义为Int,节点类型定义为全局静态变量。
获取这些信息的原理是利用句法分析结果中括号的对称性和层级性规律,通过括号的匹配,经过入栈、出栈、递归和回溯等处理,最终得到选定句子串中各个节点的信息,并存储在PTNode类中。限于篇幅,这里只给出分析句子串的部分代码,如下所示:
for (int i=0; i if (ptString.charAt(i)== "("){ //如果遇到左括号 if(j==0) j = i+1;//遇到第一个左括号,设置j为1 else{ String lb = ptString.substring(j,i).trim();//lb为两左括号间内容 if (lb.trim().length() !=0){//向PTNode添加节点信息 PTNode nt = new PTNode(nodeList.size(),lb,cdep,PTNode.NT); nodeList.add(nt); } cdep++;//深度加1 j = i+1;//j变为当前左括号位置加1 } } if (ptString.charAt(i) == ")"){//如果遇到右括号 String lb = ptString.substring(j,i).trim(); if (lb.contains(" ")){ String[] slw = lb.split(" ");//以空格为分隔符 if (slw.length == 2){//slw数组长度为2为词性和单词节点 PTNode pos = new PTNode(nodeList.size(),slw[0],cdep,PTNode.POS); nodeList.add(pos); PTNode wd = new PTNode(nodeList.size(),slw[1],cdep+1,PTNode.WD); wd.setPos(pos_in_sen);//单词在句子中的位置 pos_in_sen++; nodeList.add(wd); pos.setChild(wd.getID());//设置子节点 wd.setParent(pos.getID());//设置父节点 } } else......//遇到右括号的其他情况 j = i + 1;//j变为当前右括号位置加1 cdep--;//深度减1 } } 根据获取的节点信息,通过回溯和递归确定节点自上而下的层级位置,设定起始坐标,利用绘图机制绘制节点并画线,得到树形。树形显示及操作用到的是开源的、兼容Swing的纯Java开发的基于MVC体系结构图形组件JGraph[ 18]。JGraph具有相当高的交互性和自动性,对图的操作包括图显示、图交互、图布局和图分析等,包括5个基本Swing组件[ 19],平台用到的是基本的Graph结构和org.jgraph.graph组件。DefaultGraphCell和DefaultEdge用来定义图形中的节点和边,边通过setSource和setTarget来设置源和目标节点。通过树形操作来改变句法分析结果的功能是依据树形图中节点的位置和存储在PTNode中节点的序号ID的映射来实现的。对图形的操作实际上是记录改变节点的位置,然后根据PTNode中信息映射到括号形式的句法分析结果,执行操作命令该结果。最后对改变后的句子串重新进行分析,获取新的节点信息,并根据这些信息重新绘制图形,面板会显示新的图形。
平台主界面的效果如图6所示。菜单栏的菜单项对应上述的各个功能,其中文件菜单下包含导入和导出;模式修改菜单下包含导入文件、保存文件和模型训练,实现句法模式文件的编辑和编译;结果验证菜单下的结果验证实现句法分析结果的验证平台,如图7所示。本文中提及的文件均为文本文件,导入待处理文本把文本的内容读取到图6中的数据处理区域,然后点击菜单项中相应的功能来进行操作。
 | 图6 平台主界面 |
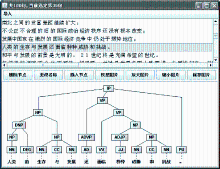
验证平台效果如图7所示,标题栏显示句子的总数和当前选定句子的序号;显示面板中,上面部分是句子列表,中间部分为可对树形进行的操作,下面部分显示选定句子的句法结构树。在句子列表中选择需要验证的句子,下面部分就会显示相应的句法结果树,如果发现错误,选定出现错误的节点,点击中间部分的按钮,平台会执行相应的操作,句子列表和图形都会刷新,显示最新的结果,而且后台的句法分析结果文件也会相应地进行修改。
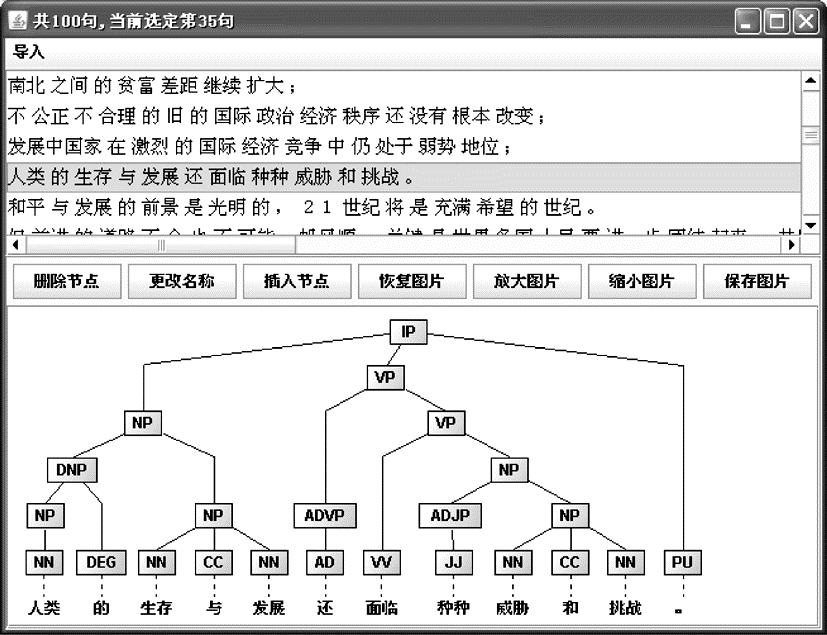 | 图7 验证平台界面 |
中间部分的“删除节点”用来删除选定的节点,如果删除选定的节点后树的形式不合规则,平台会自动删除其他相应的节点。比如图7中,选定“生存”,然后删除,则不仅会删除该词,其父节点词性NN也会随之被删除。“更改名称”用于修改选定节点的标记符号。“插入节点”即在选定节点的下方插入节点,完成一个节点的插入后平台会提示是否继续插入,直到插入的节点为叶子节点为止。“恢复图片”、“放大图片”、“缩小图片”是对树形显示大小进行的操作,另外还可对当前树形进行保存。
平台实现了预期的功能,尤其是验证平台,其界面简洁、操作简单。经测试,平台不仅能够对中文和英文文本进行词法分析、词性标注等预处理,进行句法模型的训练和句法分析应用,而且能够对句法模式文件进行编辑和编译,对句法分析的结果进行树形显示和可视化操作。
中英文句法分析系统及验证平台不仅提供从词法分析到句法分析的一系列功能,而且实现对句法模式文件的编辑、句法分析结果的树形显示和可视化操作。前者通过传统的方法来提升句法分析的性能,后者使句法分析结果的验证工作更加高效,而且避免了错误修改,提高了句法分析的准确率。不过平台的功能还不够完善,尚有许多需要增加和改善的地方:
(1)平台缺少Debug功能。平台增加Debug功能,将大大提高验证的效率。比如文献[20]中介绍了一个Debug工具Willex[ 20],它能够预先对句法分析的结果进行校验,并且能够输出错误的信息,这将大大减少人工验证的工作量。
(2)树形的可视化操作还不够完善。虽然现在可以对树中节点进行基本的操作,但是还不够完善,比如可以对节点进行拖动,然后以该节点为根节点的子树随之移动并定位到新的位置,这样可以方便地修改一些歧义的错误。
(3)平台缺少查询功能。为方便句法分析结果的验证,某些时候可能只需要针对性地查看某一类短语的正确性,人工操作可能会出现漏检的情况,如果增加查询的功能,并对查找的部分进行标红显示,能够进一步减少工作量,并且提高修正的精度。
综上所述,中英文句法分析系统及验证平台具有一定的可行性和实用性,下一步会对平台现有的功能进行完善,对需要增加的功能进行补充,使平台更加实用化。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|