{kind=link}
{kind=link}
{kind=link}
{kind=link}
关联数据的自动关联构建研究
[白海燕 , 朱礼军]
, 朱礼军]
, 朱礼军]
|
|


介绍三种自动关联构建的方法——基于实体的文本映射、基于图相似度的映射和基于规则的关联构建。基于实体的文本映射是实现自动关联的基本方法,图映射是对单一三元组比较方法的扩展,这两种方法都具有很强的通用性,但创建的关系类型却非常有限。而基于规则的关联构建能够创建较为丰富和复杂的关系,但依赖于特定的数据模型和相关规则。
This paper introduces three automatic interlinking approaches,including mapping based on entity’s text, graph’s similarity and rules. Mapping based on entity’s text is the basic approach and mapping based on graph’s similarity is an extension of single triple comparing. These two approaches are general and common methods,but the relationship types they can create are very limited. The approach of interlinking based on rules can create richer and more complex relationship types, but it depends on specific data models and related rules.
2006年, Web的发明人Berners-Lee提出了一种URI规范,使得人们可以通过HTTP URI机制,直接获得数字资源(Thing)[ 1]。其基本特征包括:使用URI作为任何事物的标识名称;使用HTTP URI使任何人都可以参引(Dereference)全局唯一名称;当有人访问名称时,以RDF形式提供有用的信息,并且尽可能提供相关链接。关联数据(Linked Data)的概念由此而产生[ 2]。
关联数据最重要的价值是“连结”(Links),即支持结构化数据的任意关联,并通过“连结”(Links)变为“链”(Chains)而遍及整个网络;而关联关系可以更好地携带语义,从而支持基于关系的检索和浏览。通过RDF链接实现不同数据集之间的关联,是关联数据技术应用最大的价值所在。RDF链接可以使Web冲浪者使用关联数据浏览器从一个数据源中的数据游历到另一个数据源,从而获得更多、更全面的信息;RDF链接还可以供搜索引擎和网络爬虫追踪,爬行下来的数据可以进行更复杂的查询和检索。关联关系的构建是关联数据实现、发布和扩展的前提。互联网上和传统数据系统中的结构化数据总量非常庞大,因此,研究关联关系的自动构建具有非常重要的意义[ 2, 3]。
本文将关联数据之间的关联构建概括为以下两种情况:
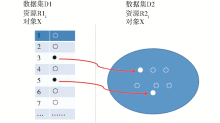
(1)映射关联。不同的RDF数据集之间,如两个数据集D1和D2,分别描述了一定数量的Web资源R1和R2。D2为目标数据集,D1为种子数据集,如果能够确定资源R1和R2所标识的对象是相同的,则可以在R1和R2之间建立owl:sameAs的关系。那么,关于R1的声明也可以应用于R2,反之亦然。各种应用、查询等就可以参引不同数据集中同一个事物的声明而获得更多的信息,数据集D1,D2则通过这样关联的建立而得到了扩展和增值。这种关联称为映射(Mapping),如图1所示。本文介绍和分析了基于文本匹配和基于图匹配的自动映射方法。
 | 图1 关联数据的映射示意图 |
(2)非映射关联。同一数据集内或不同RDF数据集之间,资源描述对象R1与R2之间存在某种非owl:sameAs的其他关系。例如《哈里波特与火焰杯》一书,具有多种语言的内容表现形式,存在翻译与原著的关系;具有多种载体的表现形式,存在印刷本、有声读物等参见载体关系;哈里波特系列作品之间存在丛书与单本的整分关系;哈里波特图书与电影作品之间存在改编关系等。发现、识别和显性构建这些关联关系,是十分有价值的,但也相当复杂,前提是获得相关的规则或数据模型。本文将以书目数据关系为例,介绍基于规则的关联构建方法。
关联数据以RDF模型来描述资源,RDF模型的基本结构是声明三元组的集合,即主语-谓词-对象。每一个实体,都通过多个三元组声明来描述和表达其各种属性特征,以及与其他实体之间的联系。数据集D1中某一资源R1x表示为{S1x,P1x,O1x}。而每一个实体都有一个名称或标签值。假设地理名称数据集Geonames为D1,参引为HTTP URI-http://sws.geonames.org/2991627/,得到实体“Moselle”(摩泽尔省,法国地名),以及它的相关地理信息;“Moselle”是该实体的名称,记为l,即R1x’l=“Moselle”。该资源可表示为{
这种基于实体的文本映射方法是在种子数据集D1中确定某一实体的l,以此文本为键值,在目标数据集D2中查找是否有相同l的实体对象,如果存在,则自动建立映射关系。因此,应用这种方法的关键是对不同的数据集进行文本检索,以确定是否具有共同的、可匹配的文本。关联数据集通常提供多种方式的文本检索功能。有的数据集通过Web接口服务来实现检索,如Geonames,Musicbrainz;有的通过SPARQL端点(End-point),利用过滤器(Filter)等对文本进行检索,如DBpedia;也有一些数据集通过内置的文本匹配功能实现对文本的检索。本文以支持SPARQL端点的数据集为例,具体说明实现方法[ 6]。
对数据集D1执行以下SPARQL查询,得到需要映射的对象
SELECT ?l where {
例如,D1为书目数据集,某一书目资源r1的名称为“Life of Palo Picasso”,表示为主语、谓词、对象的表达为{
简单文本匹配法是一种比较理想化的映射构建方法,实施简单,但实际应用中存在许多问题需要解决:
(1)精确的文本匹配,可能会遗漏由于文种、拼写或文本描述差异所导致的不匹配;
(2)当查询结果为多个时,无法建立一对一的映射关系;
(3)当文本形式相同而内容不同,即同名异义时,会产生错误的映射链接[ 5]。
扩展文本匹配法是在上述简单文本匹配的基础上,通过增加一些限定和条件,以避免同名异义的词语歧义引发的多匹配结果。限定的方法之一是利用SPARQL的限定查询语法,即增加一个或多个三元组描述,多个三元组之间用圆点分开[ 6]。例如:
Select ?r where {?r ?p1 ?l1. ?r ?p2 ?l2. … ?r ?pn ?ln }
此外,限定条件可以通过选择不同的谓词来实现。关联数据集通常引用其他本体、词表的语义关系作为该数据集的谓词。例如,DBpedia和YAGO(Yet Another Great Ontology)之间建立了关联。YAGO是一个大型通用本体,包括200多万个实体,如人、机构、城市等,以及2 000多万个关于这些实体的类型分面特征。因此,可以选用某一种特定的YAGO类型作为查询的条件限定。此外,DBpedia中也采用了与Wikipedia相对应的、用于格式化数据的模板Infobox,因此可以将资源限定链接到特定的Infobox URI。例如,Violet是一首以人名为标题的英文歌曲,采用上节所介绍的简单文本查询,对目标数据集进行查询,有可能得到人名、歌名等多个检索结果,如果能在查询中使用上述限定方法,则可以减少多重链接的产生。下面的语句使用了多种查询限定:文本表达限定为英文;限定实体的类型为歌曲;限定了具体的描述模板[ 7]。
PREFIX p:
Select ?r where {
?r ?P"Violet"@en. .//限定1
?r a UNION {?r P:wikiPageUsesTemplate http://dbpedia.org/resource/Template:single_infobox} }//限定3 扩展文本查询在简单文本匹配的基础上,借用分类、分面、类型特征、属性特征等进一步对资源进行限定,在一定程度上改进了简单文本匹配所产生的多重链接问题,但仍然不可能从根本上有效解决。
要对基于实体的文本比较方法进行改进,可以从两个方面着手:
(1)引入文本相似度作为量化指标,提高匹配判断的准确性;
(2)引入实体的其他描述信息,作为辅助判断依据,通过关联数据构造语境(Linked Data Context),提高比较的合理性。
RDF图具有“语境”的特点。RDF图的含义是对应的所有图中三元组包含声明的逻辑合取[ 4]。基于图的相似性比较是将待匹配的实体按图所包括的各个三元组进行全面的比较,同时每一个比较以文本相似度作为可排序的量化指标,从而选择最佳结果[ 7, 8]。
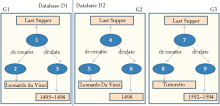
例如,在数据集 D1中,某一艺术作品的标签为Last Supper(《最后的晚餐》),以此为键值,通过类型限制为艺术作品,在数据集D2中查找到两个Last Supper。通过URI参引,获得这三个URI的三元组图,数据集D1中得到图G1,数据集D2中得到图G2、G3,如图2所示:
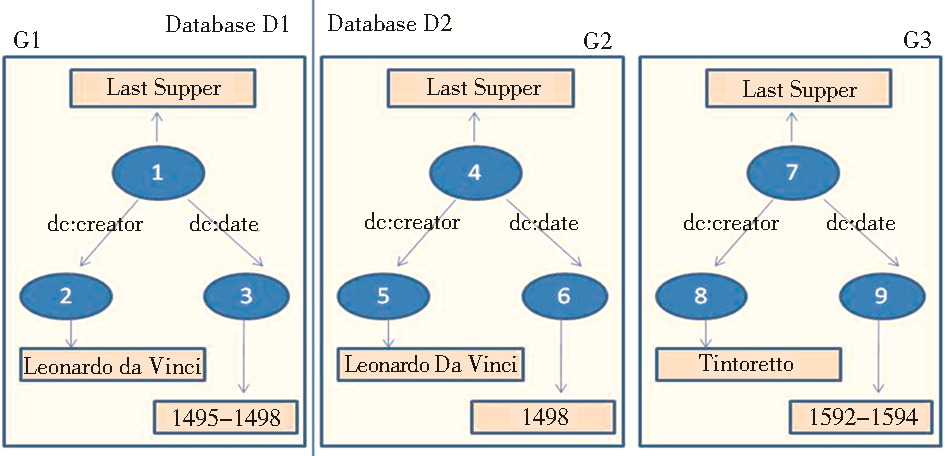 | 图2 RDF图[ 7] |
(1)整图比较是将每个图中的节点标注出来,如表1和图2所示。图G1中包括三个节点,节点1的标签为文本“Last Supper”,谓词dc:creator指向节点2,其标签文本为“Leonardo da Vinci”,谓词dc:date指向节点3,其标签文本为“1495-1498”,G2与G3的节点及文本如表1所示:
| 表1 图G1、G2、G3的节点标号与内容 |
(2)对整图的比较转换为对相同位置的节点的文本相似度Mgn的计算。图G1与G2的比较转换为节点1与4、2与5、3与6的比较,图G1与图G3的比较转换为节点1与7、2与8、3与9的比较,记为{(1,4),(2,5),(3,6)}, {(1,7),(2,8),(3,9)}。文本相似度的具体算法可采用目前通用和常见的文本比较算法[ 9]。例如节点1和4的文本完全相同,相似度记为1;节点2和5的文本有大小写之分,相似度为0.9。通过计算各个节点,得到节点相似度,如表2所示:
| 表2 节点相似度 |
(3)在节点相似度的基础上,计算图的相似度Mg,其值等于组成图的各个节点相似度的平均值,即 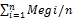
| 表3 图相似度 |
以上介绍了关联数据的映射实现方法,即owl:sameAs的生成方法,笔者还希望通过识别和确定不同对象间的属性关系,生成RDF谓词,从而构建一些更为丰富的关联关系。本文以书目数据为例,研究依据某种关系规则方法来自动构建关系的方法[ 10]。
以瑞典联合目录LIBRIS系统为例,该系统通过关联数据发布了其170多个成员馆的600多万条书目数据。书目数据集的数据类型为书目,URI为http://libris.kb.se/resource/bib/
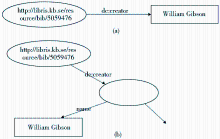
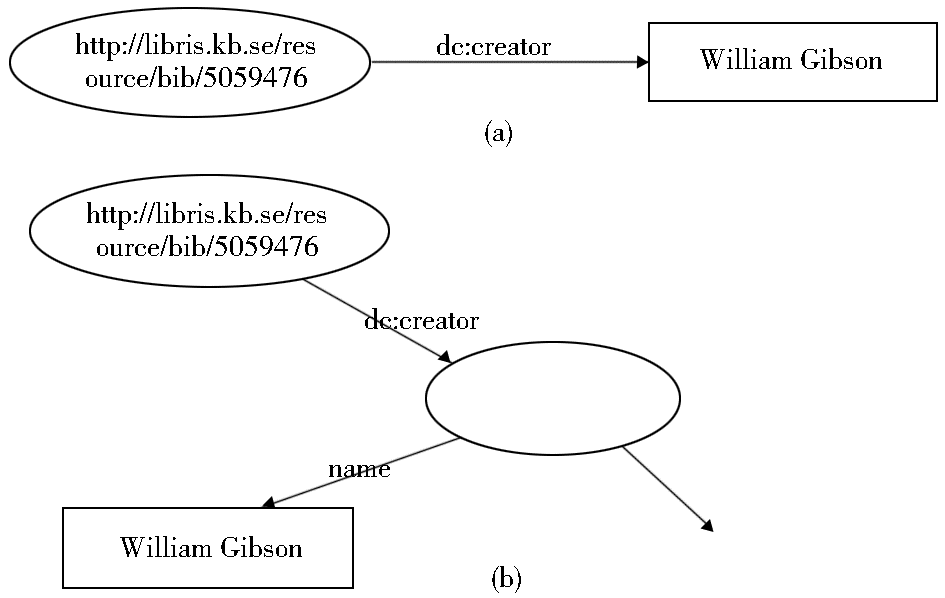 | 图3 RDF图及匿名节点的建立 |
为了构建关联关系,对作者文本字符串进行扩展。扩展后,作者的取值类型从原来的文本字符串变成了一个结构化实体,也就可以表示为一个资源。这个资源暂时为匿名的,用一个无标识的椭圆即空白节点来表示[ 4]。对这个匿名资源,只知道它的类型是人名(foaf:Person),有一个属性,即名称为“William Gibson”,如图3(b)所示。在人名规范文档数据集D2中进行查找,类型为foaf:Person,且名称为“William Gibson”的资源。具体查找语句使用2.2节介绍的方法。查询命中资源URI为http://libris.kb.se/resource/auth/220040,由此,可以作为资源标识符分配给匿名资源,并建立起两个资源之间的关联,即{
这种关联的构建是基于已有的关系dc:creator,扩展建立匿名资源,通过查找命中后,继承原有关系而生成的。采用这样的方法,还可以在书目资源与主题词表、地名、人名规范文档之间建立dc:subject等关系。
书目数据之间的内在联系,可以通过FRBR模型
来表达。例如,作品(Work)是一种特有的智慧、艺术的创作和抽象的实体,通过不同的内容表达(Expression)来实现;内容表达通过数字、音乐、声音、图像、动作或这些形式的组合来完成对智慧或艺术作品的实现,如同一作品的不同语种、版本等;而载体表现(Manifestation)是通过物理介质实例化内容表达的实体,如印刷本、光盘版等[ 13]。对上述实体之间的关系,本文引用了美国国家数字图书馆项目的词表注册系统的FRBR关系词表中的FRBR关系,如表4所示:
| 表4 FRBR关系及扩展 |
经过分析,这6个关系中存在互逆的逻辑规则,如frbr:isRealizedThrough与frbr:isRealizationOf是互逆的,frbr: isEmbodiedIn与frbr: isEmbodimentOf是互逆的,因此,将其中的两个关系确定为基础关系,如果能建立其中的某一种关系,则可以通过这种互逆的逻辑规则自动创建另一种关系。此外,还可以对上述关系进行扩展,如同一个作品的不同内容表达之间,即指向同一作品的各个Expression之间存在otherExpressionAs,同一个内容表达的不同载体之间,即指向同一内容表达的各个Manifestation之间,可以构建otherManifestationAs的关系。因此,只要找到三种实体的生成规则,就可以确定作品、内容表达和载体表达三种实体,也就可以自动地建立基础关系,并根据基础关系自动地进行逻辑扩展关系的构建。
为了确定作品、内容表达、载体表达这三种实体,可根据文献[13]等提供和总结的算法确定生成规则,以FRBR KEY作为划分作品的标准。本文进行了简化处理,主要是演示基本算法在关联数据集中的应用过程。本文使用某一资源的FRBR KEY对数据集进行查找,以查看是否具有多作品形式。以frbrkey=title+creator=Harry Potter and the Goblet of Fire.J.K.Rowling为例,在数据集中查找相同的题名作者,查询语句如下:
Select (count(?r) as ?W) where {?r, frbrkey, "Harry Potter and the Goblet of Fire.J.K.Rowling"}
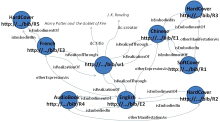
如果命中数量即变量?W大于2,则说明该作品存在多种表达形式,扩展一个匿名节点作为作品的声明,并可以确定其名称和责任者属性。根据数据集的URI命名规则,分配一个标识符,如W1,参见图4的http://.../bib/w1节点。假设该查询命中5条记录,对这5条记录按语种进行分组查询:
Select ?x, (count(?x) as ?E) where (?r, dc: language, ?x) group by ?x
分组结果显示有两个英语、两个中文、一个法语,共三个语种,则建立三个匿名节点作为内容表达形式的声明,它们都具有题名、责任者、语种属性。根据数据集的URI命名规则,为这三个匿名节点分别分配一个标识符,如E1,E2,E3,参见http://.../bib/E1,E2,E3三个节点。这三个内容表达和作品之间则自动建立isRealizedThrough和isRealizationOf的关系,而三个内容表达之间则自动建立双向的otherExpressionAs关系。E1,E2,E3每一种表达形式与相应的R1,R2,R3,R4,R5资源存在着isEmbodiedIn和isEmbodimentOf的关系。如果上述查询中的变量?E>1,说明同一内容表达形式具有多种载体表达,则在其载体表达形式之间建立双向的otherManifestationAs关系。
 | 图4 书目数据的关联 |
综上所述,基于实体的文本映射是实现自动关联的基本方法,图映射是对单个三元组比较的扩展,这两种方法都具有很强的通用性,但创建的关系类型却非常有限。而基于规则的关联构建能够创建较为丰富和复杂的关系,但依赖于特定的数据模型和相关规则。本研究尝试了对基于FRBR模型的部分关系的自动创建,下一步研究将引入更多的FRBR关系,同时将结合复合对象模型如OAI-ORE等,进一步完善自动关联的构建方法,并进行相关的评价研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|