


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于意见挖掘的城市形象网络监测系统初探
[李纲 , 陈婧, 程明结, 寇广增]
, 陈婧, 程明结, 寇广增]
, 陈婧, 程明结, 寇广增]
|
|


针对无法对舆情信息进行有效搜集、分析等难题,利用意见挖掘的相关技术,采用分步骤、分模型的设计方法,构建出城市形象网络监测系统。通过对与城市有关的评论进行挖掘和分析,识别其情感倾向和演化规律,并以可视化的界面将结果展现给相关政府部门。
For it is hard to extract and analyze public information effectively,the paper uses the opinion-mining and the step-by-step sub-model design method to build a system of city image network monitoring. By city reviews mining and sentiment analysis, the paper can identify tendencies and evolution of emotions,and provide the results to government departments using visual interface.
城市形象的提升一直是各级政府长期的工作重点,良好的城市形象不仅是对政府工作的肯定,而且是政府形象的代表。随着博客、论坛、点对点网络和其他各种网络社会媒体的快速形成和应用,越来越多的民众选择网络平台去发表和表达自己对各种事物的意见、情感和态度,而这些具有一定影响力和倾向性的共同意见即被称为网络舆情[ 1]。通过互联网了解民情、汇集民智已成为政府想问题、做决策、办事情的重要渠道。
目前,政府部门主要通过网络舆情监测来帮助其了解和把握城市各方面的形象和口碑。很多科研机构、公司和高校都纷纷致力于网络舆情分析系统的设计和实现。现有的舆情分析系统主要有如下几个:
钱爱兵设计实现的基于主题的网络舆情分析系统,以江苏省法院系统为实例阐述[ 2]。该系统以《中文新闻信息分类标准及代码》的一级、二级目录作为默认的舆情主题,从网上自动采集相关的舆情信息,有效地分析网络舆情的发生、发展和变化规律,通过分析能够得到某段时间内人们最关注的舆情主题,关注度发生很大变化的舆情主题以及应该引起相关部门高度重视的舆情主题等。
方正智思舆情预警辅助决策支持系统是由北大方正技术研究院设计开发的,该系统基于三种平台:内容管理平台、知识管理平台和辅助决策支持平台,分别对应于舆情信息的采集与存储、舆情分析与处理和舆情服务[ 3]。
北京拓尔思(TRS)信息技术股份有限公司正致力于TRS舆情监控系统[ 4]。该系统采用基于内容相似度的智能分析技术,及时发现网络上新出现的热点新闻事件,并在舆情信息自动分类的基础上,将一些用户并不关注的热点信息过滤,提高热点发现的准确性。对于已知的热点信息,通过其主题特征进行持续跟踪,并对热点的传播链路进行分析,建立热点的运动轨迹和发展趋势模型。及时监控用户关心的信息或关系到国计民生的敏感信息,对其中的一些负面新闻发出预警信号,辅助相关人员对舆论进行引导。
虽然这些系统已基本开发完成,个别也已投入试验性使用阶段,但针对城市整体形象的网络舆情检测工作还存在诸多难题。
(1)信息分散无序,结构各异。城市形象的影响指标繁多,相关的评论和意见在网络中的分布更是杂乱无章。信息源间的异构及格式变化,要求彼此不同的包装器软件及时更新,这将造成网络文本获取的巨大工作量。
(2)信息片面,缺乏时效。目前政府部门对网络舆情的监测多采用浏览新闻、论坛或通过搜索引擎直接搜索等方式,信息源单一或被动给予。由此得出的评论结果十分片面,无法在第一时间发现新信息,所获取的往往是失去意义的过时信息。
(3)情感倾向性评论获取困难。对政府真正有帮助的往往是那些带有网民情感性倾向的意见和评论,而这些语句可能只是一篇帖子中的某几句话,网络舆情监测的主要目标就是挖掘出这样的文本。而网民言论质量水平不齐、真假掺杂,需要检测其中与事实差距较大的虚假信息;另一方面还要分析言论内部意见相互杂糅的情况。
(4)现有网络舆情监测系统的不足。市面上的几大网络舆情监测系统,大多都只能根据已有主题从网上收集舆情信息,而很难实现对网上突发事件的监控;无法对网络舆情主题之间的关系进行分析,进而剖析民众情感倾向;另外辨认网络虚假信息的能力也较差。
因此,本文拟在现有的数据挖掘、文本分类等相关技术的基础上,实现对系统开发理念与过程的创新。基于Java技术平台,通过对Weka开源程序的组合与应用,设计并实现了基于意见挖掘的城市形象网络监测系统(City Image Network Monitoring System,CINMS)。
CINMS的构建主要应用了意见挖掘的相关方法与技术。通过对网上各种主观性文本进行表示、特征提取、内容总结、分类、聚类、关联分析、语义分析以及趋势预测等[ 5],发现民众情绪、意见以及社会热点、焦点,预警不良信息,预测事件趋势。
意见挖掘是数据挖掘与文本挖掘技术的延伸和发展,它所针对的对象是非结构化数据,例如互联网论坛中那些反映作者对事物、人物、事件想法和观点的主观性文本,这些文本中包含表达意见的语句,即具有褒贬态度倾向的语句[ 5],而意见挖掘就是结合自然语言处理的相关技术去发掘这些情感倾向。
意见挖掘的过程主要包括以下4个方面[ 6]:
(1)主题抽取(Topic Extraction):识别相关主题术语和与指派领域相关的本体概念;
(2)意见持有者识别(Holder Identification):确定意见表述的作者;
(3)陈述的选择(Claim Selection):确定意见表述的范围,过滤无关信息;
(4)情感分析(Sentiment Analysis):判断意见的语义倾向(即情感极性)。
意见挖掘涉及到词汇层(如分词和词性标注)、句法层(如命名实体识别和句法分析)、语义层(如语义分析)和篇章层(如跨句指代消歧)等多个自然语言分析层面[ 7]。它不同于那些对文本主旨提炼的挖掘方法,而是细化到每一个语言片段,分析提炼其中的情感倾向[ 8]。
意见挖掘的相关方法和技术是CINMS构建的基础与核心:
(1)将网页评论转换成结构化文档。可以生成XML形式的描述性信息,从而方便下一步的属性分类,实现文本的智能采集。
(2)语料库建设。通过对语料进行人工标注,形成训练数据集和训练模型,用来与处理中的数据进行比照分析,提高结果准确度,优化结果;利用分词功能构建测试数据集[ 7]。
(3)情感极性分析。采用分步骤、有序化、前后衔接分工配合的处理流程,通过主题识别、城市设定、属性判断、情感分析模块逐个判断分析,对测试集中的数据逐条过滤筛选,提取情感极性。
(4)对信息的关联性分析。从时间与空间两个角度分析事件的关联性,发现从时空角度关联事件的发展规律及趋势[ 9]。
利用数据挖掘技术中的意见挖掘方法能较好地实现CINMS的各项功能,其优势如下:
(1)目标驱动,面向决策。系统是面向任务的,采用目标驱动的方式展开。网民的言论数量巨大而且分散、结构各异。针对不同的任务,意见挖掘技术能提供智能化的指标体系构建和信息源选择。
(2)基于知识,高效整合。意见挖掘技术选取的指标之间有粒度和层次关系,分析结果更加贴近用户需求,而且可以在不同的粒度和层次上对数据进行分析。
(3)实时运行,动态更新。对网络文本进行定时自动采集,保证了核心的信息源覆盖到尽可能多的信息,时效性强。
CINMS以互联网上的新闻、博客、论坛或者其他网页中的评论为抓取对象。
(1)通过信息源选择,确定所抓取的目标信息。目前笔者主要选择了奇虎论坛相关版块中的评论帖子进行信息的智能化抽取。
(2)对抓取的信息进行结构化处理及信息过滤,形成结构化的文本形式,过滤无关信息。
(3)对所抓取信息进行分析,判断出评论的情感倾向,并对各属性指标对应的情感极性元素进行分析处理,将结果存入数据库中[ 10]。
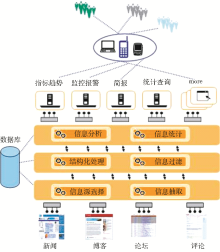
(4)将指标趋势图、简报、监控报警、统计查询等以可视化的方式呈现,如图1所示。从而实现对网络热点、公共决策舆论、重大事件舆论、公共服务舆论的监测和分析。
 | 图1 系统功能架构 |
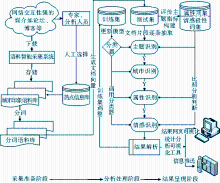
该城市形象网络监测平台的流程如图2所示:
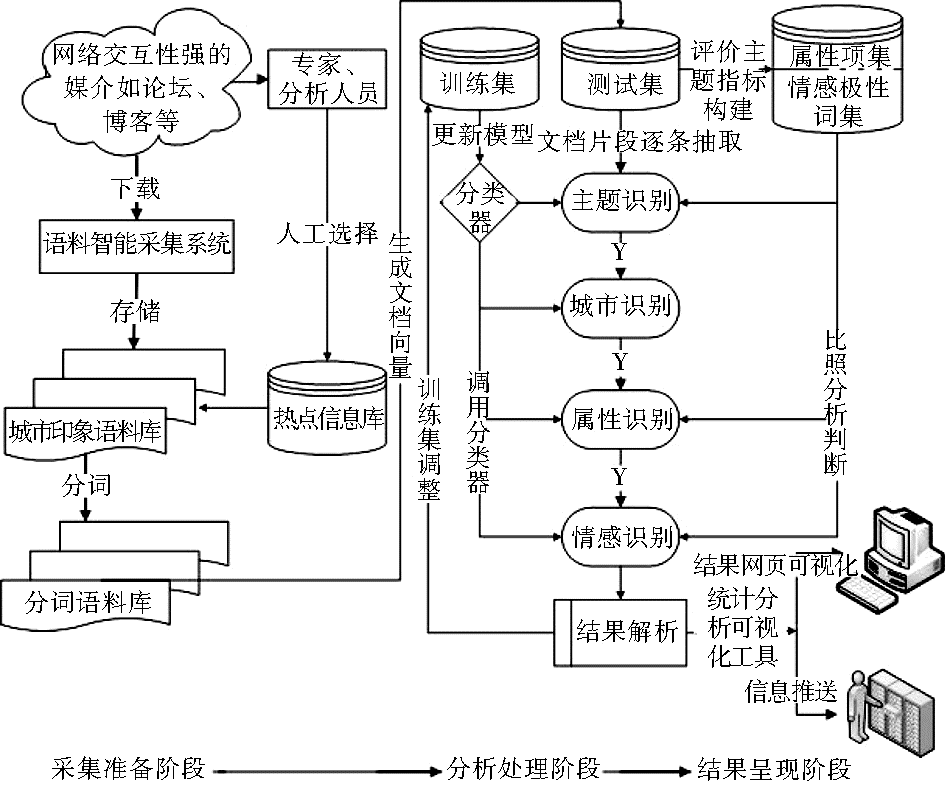 | 图2 系统模型架构 |
CINMS的流程步骤主要分为三个大的阶段:
(1)采集准备阶段,主要通过语料自动采集系统,实时获取固定时段内论坛中涉及到关于城市的相关评论、热点新闻、突发事件等信息,按时间顺序排序[ 11]。同时需要数据分析人员对相应评论中的信息关键字进行人工采集,并对自动采集系统获取的数据进行初步筛选。信息被保存为含有帖子标题、发帖人、帖子来源、帖子链接、发帖时间、点击次数、回帖数量、发帖内容和回帖内容的格式化文本形式[ 12]。另一方面对获取语料进行分词处理,其结果生成测试数据集。
(2)分析处理阶段,是本系统开发的核心环节。利用测试数据集中的数据构建主题指标和情绪字典,然后利用现有的文本分类的方法和技术,通过主题识别、城市识别、属性识别和情感识别4个模块对传入的每条数据依次判断筛选[ 13]。本系统主要采用了贝叶斯算法来对文本进行分类,主要利用了Weka开源程序包,相关核心算法如下:
Classifier classifier = new NaiveBayes(); //初始化,调用贝叶斯分类器
Instances trainData = new DataSource(trainPath).getDataSet(); //得到训练测试数据集
classifier.buildClassifier(trainData); //对训练数据集构造贝叶斯分类器
Instance inst = new Instance(trainData.numAttributes());
inst.setDataset(trainData); //构建测试实例
score = classifier.distributionForInstance(inst); //调用分类过程,得到分类结果
利用循环反馈的方法调用分类器对筛选分类识别的结果进行纠正和调整,将数据与之前通过人工标注形成的训练集进行比照分析,然后根据每一次反馈的最新数据集更新训练模型,以提高最终分类数据的准确性。
(3)结果呈现阶段。通过后台管理系统对最终的解析结果进行处理,生成报表,并以可视化方式呈现。
CINMS在意见挖掘的过程中采用了文本分类、自然语言处理等方法,来识别与城市有关的网络文本情感。在对结果数据的分析中运用了SPSS统计分析软件进行结果的二次处理。
从网络论坛中挑选了500篇与城市相关的文章,邀请专业人员对文章进行了人工的标注,标注结果形成训练数据集。通过调用训练算法对训练数据集进行处理,生成初始训练模型。该调用算法核心步骤如下:
/**加载训练数据集*/
TextDirectoryLoader loader = new TextDirectoryLoader();
loader.setDirectory(inDir);
trainDataset = loader.getDataSet();
trainDataset = toWordVector(trainDataset); //生成文档向量集
trainDataset = toNominal(trainDataset); //将数据属性进行离散
writeArff(outArff, trainDataset); //将得到的训练模型写入文件
初始的训练模型中属性数量庞大且表征性差异较大,需要对其进行筛选和整合,形成特征项集合。CINMS采用在特征选择方面表现良好的信息增益(IG)算法来实现。IG表示文档中包含某一特征时文档内的平均信息增量,它被定义为某一特征在文档中出现前后的信息熵之差。例如特征项f,其信息增益IG(f)可以表示为[ 14]:
IG(f)=H(C)-H(C|f)= 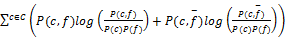
删除训练模型经过特征选择后低信息增益的属性,保留高信息增益的特征项,形成最终的训练模型。此步骤的特征选择核心算法如下:
Instances dataset = Utils.loadArff(arffName); //加载初始训练模型
InfoGainAttributeEval infoGain = new InfoGainAttributeEval(); //初始化信息增益方法
infoGain.buildEvaluator(dataset); //对数据集构造信息增益
Ranker ranker = new Ranker(); //对数据进行初始化排序
ranker.setNumToSelect(numAttribuesSelected); //设置城市属性筛选个数
Remove remove = new Remove(); //初始化数据剔除器
int range[] = ranker.search(infoGain, dataset); //计算信息增益
/**剔除低信息增益的属性*/
remove.setInvertSelection(true);
remove.setAttributeIndices(rangeList);
remove.setInputFormat(dataset);
for (int i = 0; i < dataset.numInstances(); i++) {
remove.input(dataset.instance(i));
}
/**过滤筛选后的属性,将结果写入文件*/
Instances newData = remove.getOutputFormat();
Instance processed;
while ((processed = remove.output()) != null) {
newData.add(processed);
}
writeArff(arffName,newData);
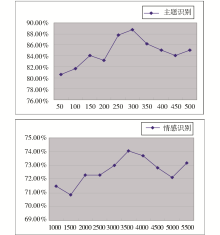
为了给每个分类模型筛选出合适数目的特征项,本文尝试了特征项数目的若干种不同组合,通过10折交叉法验证了选择不同项目数下的模型准确率。最后选取分类准确率最高的模型作为最终的分类模型。实验结果如图3所示:
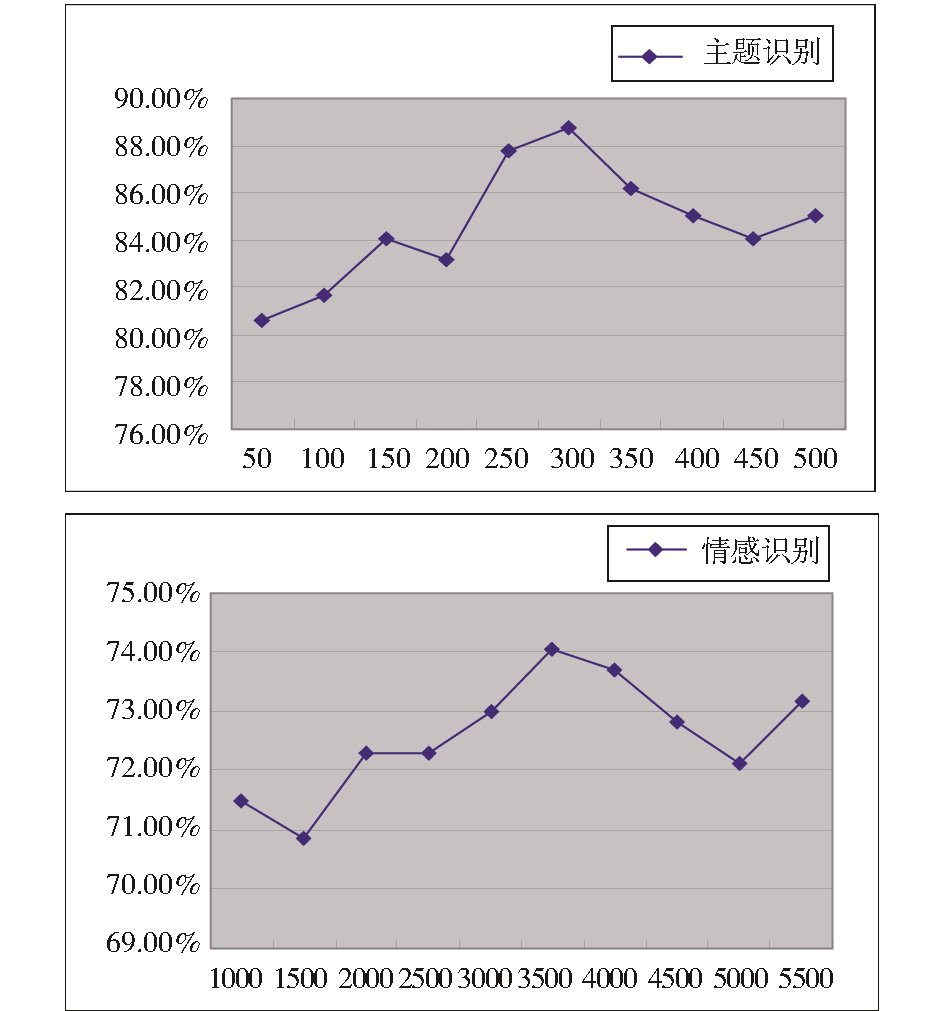 | 图3 各分类模型选择不同数量特征项情况下准确率变化曲线图 |
实验结果表明,在属性识别模块中,特征项一般选取150-200个就能达到较高的准确率,主要包含了涉及城市形象的相关指标。而在情感识别模块中,特征属性一般选取2 000-3 000个才能取得比较满意的结果,这是由于情感词极其丰富,需要兼顾前后出现的许多属性才能识别出结果。由于选取的训练语料的不同,会造成在特征属性的选择以及分类结果上有差异,但总体上不会偏离太远。
同时笔者使用了中国科学院计算技术研究所研制的汉语词法分析系统(Institute of Computing Technology, Chinese Lexical Analysis System,ICTCLAS)对存储的语料数据进行规范化预处理。其中文分词、词性标准、命名实体识别、新词识别等功能保证了分词的准确性和有效性。分词结果生成测试数据集。
本文使用了自主开发的工具CaseTool辅助人工进行属性和情感词筛选。
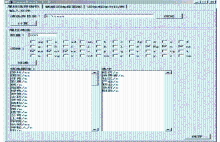
CaseTool可以自动调用测试数据集中的数据,根据词性限制进行过滤,再由人工从过滤后的词集中挑选出主题指标词,如图4所示:
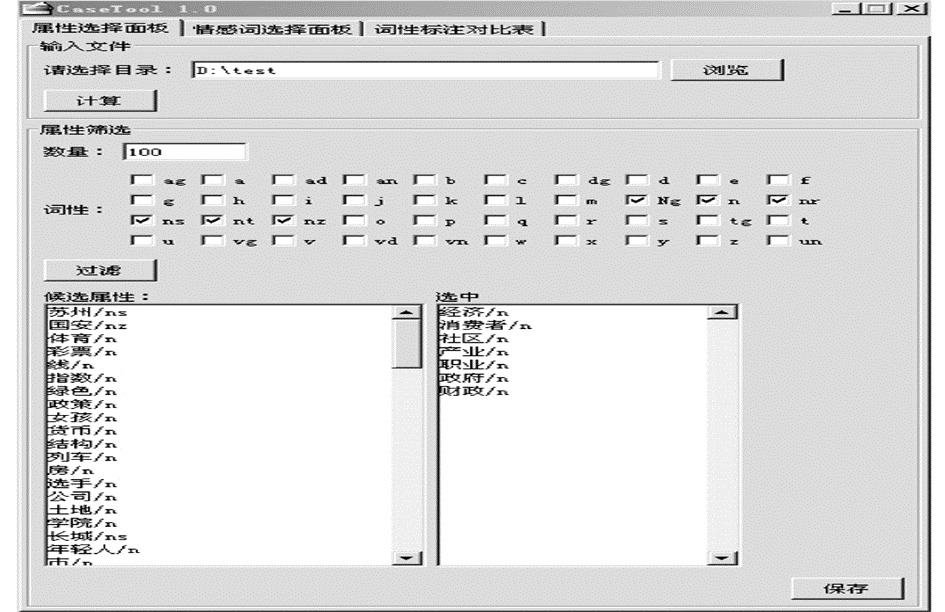 | 图4 CaseTool评价主题指标选取 |
再次调用原数据,将选定的主题指标词文件设为属性文件,将词性过滤更改为形容词形式,这时CaseTool就会计算出与筛选出的每个主题指标相应的情感评价词,再由人工对情感词进行极性判断,筛选形成正面、负面、中性三类的情绪词集,如图5所示:
 | 图5 CaseTool情绪词集选取 |
同时可对生成的结果进行人工补充,形成最终的主题指标和情绪字典。在CINMS中最终得出城市形象指标,如表1所示:
| 表1 城市形象指标 |
属性指标构建完毕后,系统将对测试集中的数据逐条输入判断:通过主题识别模型,对传入的数据分类识别,若结果为城市的,则继续传给下一个模块,否则该条数据将被自动删除;限定城市模块对传入数据中属于笔者所规定城市的信息予以保留,其他丢弃;属性识别模块将传入的数据与之前构建的评价主题指标中的各属性比照分析,相同属性的信息保留;话题情感识别模块将传入信息与情绪字典进行匹配分类识别,并保存分类结果。
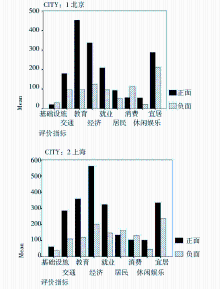
通过后台管理系统可以看到运行的最终结果,并对结果进行管理。同时将相关数据指标导出,利用SPSS统计分析软件对结果进行二次处理。例如实验中给出对京沪两地各项属性指标的网民态度倾向直方图(见图6),以及反映正面与负面评价比例的饼状图(见图7),还有一些关注度变化的趋势分析(见图8)等,结果分析以“周”为单位动态更新。利用RSS订阅或电子邮件等方式向相关政府部门进行实时的信息推送,保证政府部门能够及时、清晰、直观地了解各相关指标的变化情况,把握网民态度倾向,从而就各指标责权对应的政府部门当前的工作任务和重点给出合理的参考指导意见。
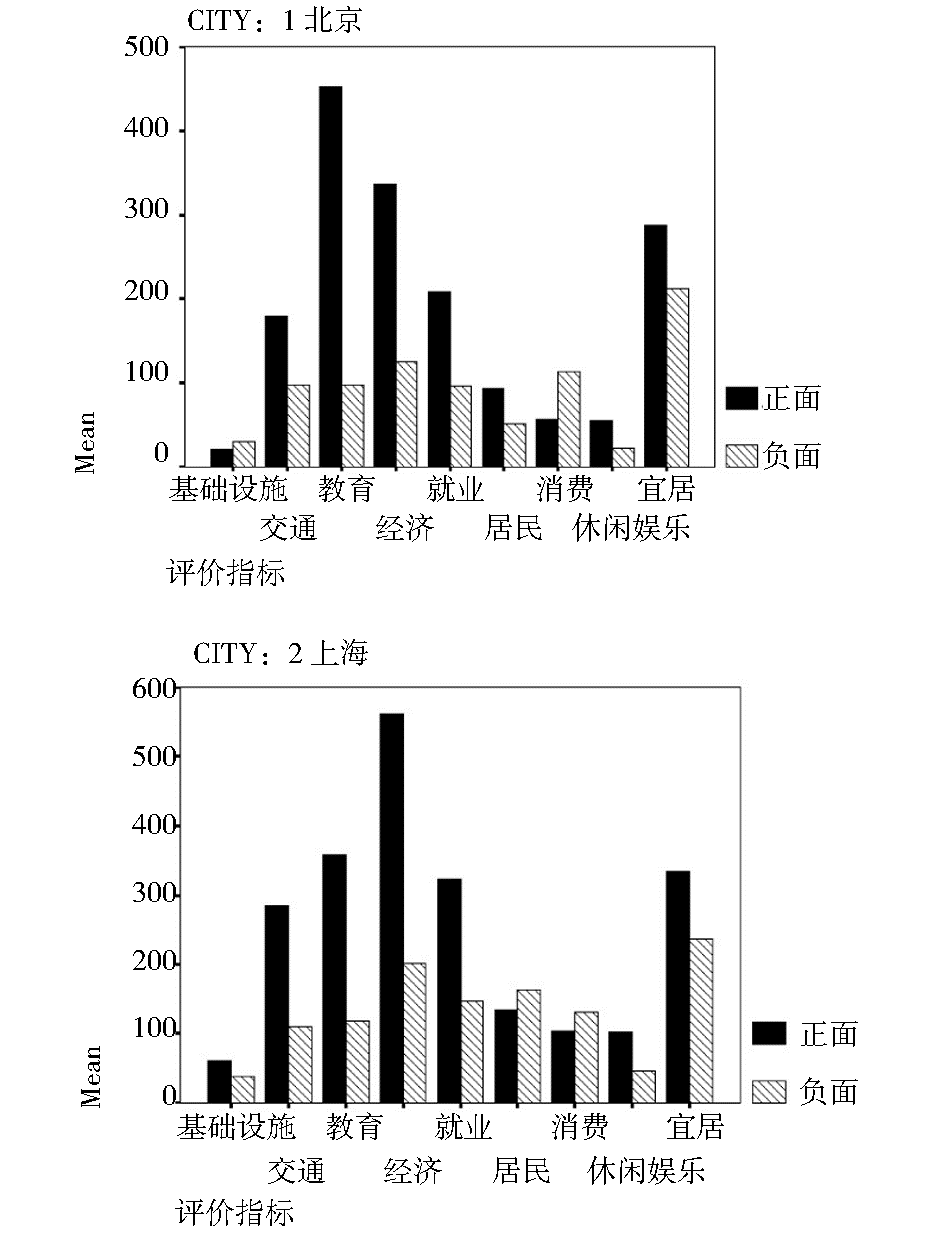 | 图6 城市情感倾向直方图 |
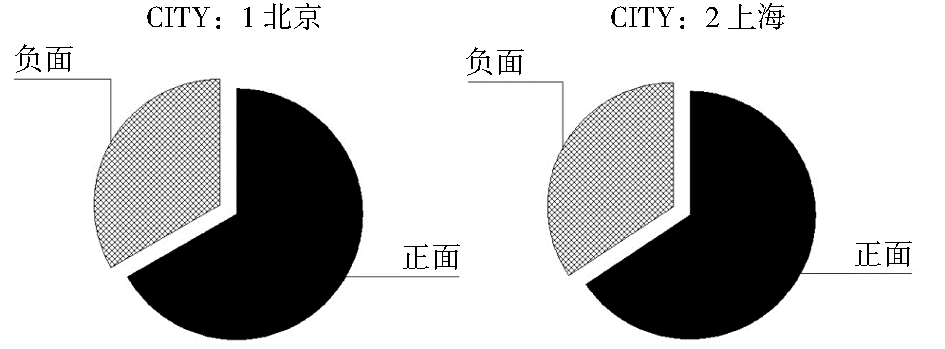 | 图7 城市情感倾向饼图 |
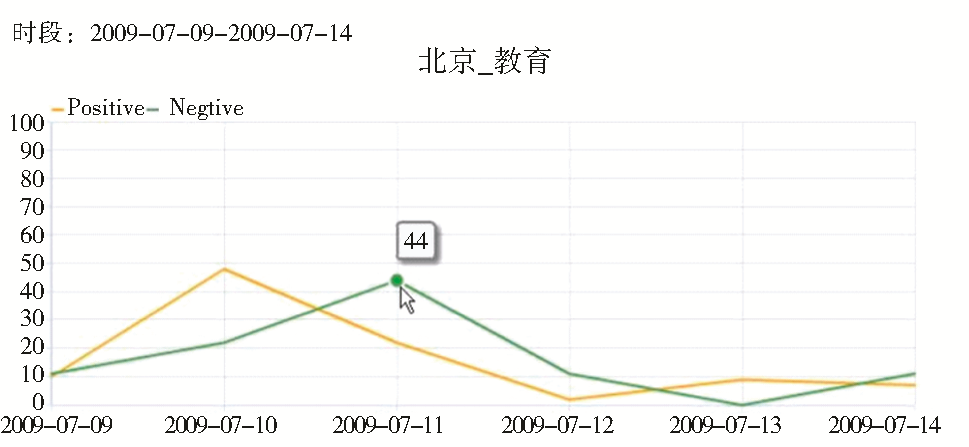 | 图8 关注度趋势分析 |
意见挖掘是文本挖掘、信息抽取、机器学习、自然语言处理、本体学、统计分析等多个学科的综合应用[ 9],它在产品服务分析、民情民意调查、企业政府管理等领域都有着广泛的应用。而网民对城市各个方面的议论与评价越来越多地影响了政府决策和政策制定,进而对政府形象、城市形象产生重要影响。
据此,本文利用Weka开源程序等相关技术,设计并实现了基于意见挖掘的城市形象网络监测系统(CINMS),该系统不仅能对城市属性指标的每日关注度进行跟踪分析,更重要的是能连续地、系统地挖掘出特定属性及用户对其的情感倾向。然而目前系统建设仅处于初级开发阶段,情感分类也主要借助的是机器学习和人工协助的方法,未用到词表分析和本体的构建[ 9],下一步将对该方面及语料库构建上做出改进,采用更加细化的粒度,如句子级别结合情感词表进行情感识别,提高结果的精确度,为政府部门提供更有价值的信息。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|