
{kind=link}
{kind=link}
{kind=link}
社会网络搜索关键技术研究概述
[杜一鸣 , 滕桂法, 马建斌]
, 滕桂法, 马建斌]
, 滕桂法, 马建斌]
|
|


在介绍近年来社会网络搜索总体研究情况的基础上,从社会关系获取、社会网络可视化及社会关系搜索三个方面,较为系统地分析和比较实现这三部分的关键技术,并提出一种对人际关系进行数值化处理的思路,指出进一步的研究方向。
This paper reviews the research of social network search in recent years, then analyses and compares the key technologies systematically in the aspects of social relations extraction, social networking visualization and social relationship search.It also proposes a method which can weight the relationship. Finally, some future directions are pointed out.
近几年,基于六度分隔理论(Six Degrees of Separation)[ 1]和150法则(Rule of 150)[ 2],以认识的朋友(一度关系人)为基础,在已有朋友的基础上扩展自己的关系网,从而得到强大而有效的SNS(Social Network Service)网站逐渐成为Web2.0中最受欢迎的应用之一,基于SNS的应用也遍布于互联网的各个角落[ 3]。
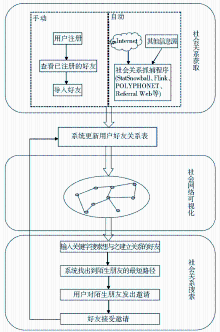
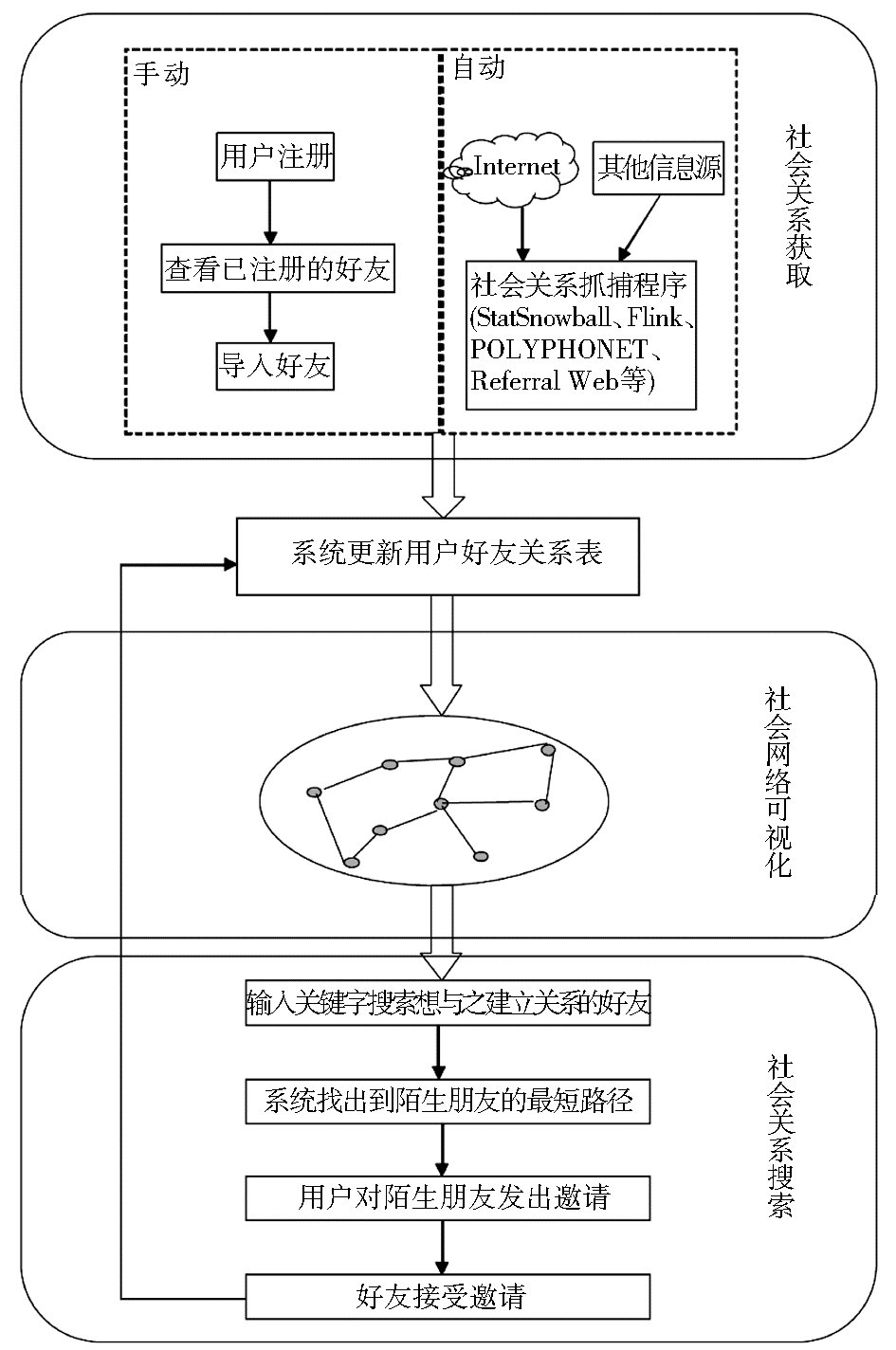
社会网络搜索是SNS网站的一个关键技术,目的是帮助用户通过在SNS网站中已构建的社会网络社区,找到想与之建立联系的朋友,使其成为自己的一度好友,然后再通过已经建立联系的一度好友,与其一度好友的朋友建立联系,从而建立用户自己的六度关系群。用户可以通过不定期地更新这种六度关系群进行初步的社会和商业的应用,该部分设计的好坏直接关系到SNS网站的质量和发展。基于上述背景,社会网络搜索技术成为了当今国内外研究的一个热点问题。本文通过分析和研究近几年来国内外的一些理论成果,总结出社会关系网络搜索机制的整体框架、每部分所采用的关键技术及发展方向。笔者着重介绍关键技术和思路,相关技术细节可参考相应的文献。
社会网络搜索是一种以互联网上的海量信息为计算基础,基于传统搜索的信息挖掘技术,以人物为中心的信息聚合的垂直搜索,搜索的目的是将人和人之间的关系抽取出来,针对要查找的目标人物给出围绕该目标人物的丰富信息,包括人物简介、人物关系等内容,并可以根据指定关系查看详情。目前的SNS网站中都把社会关系搜
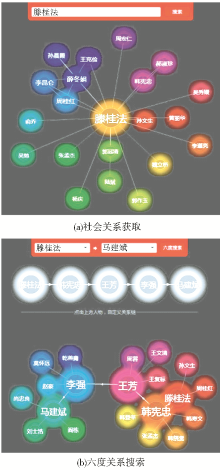
索作为一项最重要的服务。已经发布的比较著名的社会网络搜索引擎主要包括雅虎人物搜索、微软人立方(EntityCube)、腾讯搜索华尔兹、Ucloo搜人、Spock等。图1是通过人立方搜索出来的“滕桂法”的社会网络关系和六度分隔效果图。社会网络搜索的具体流程如图2所示。
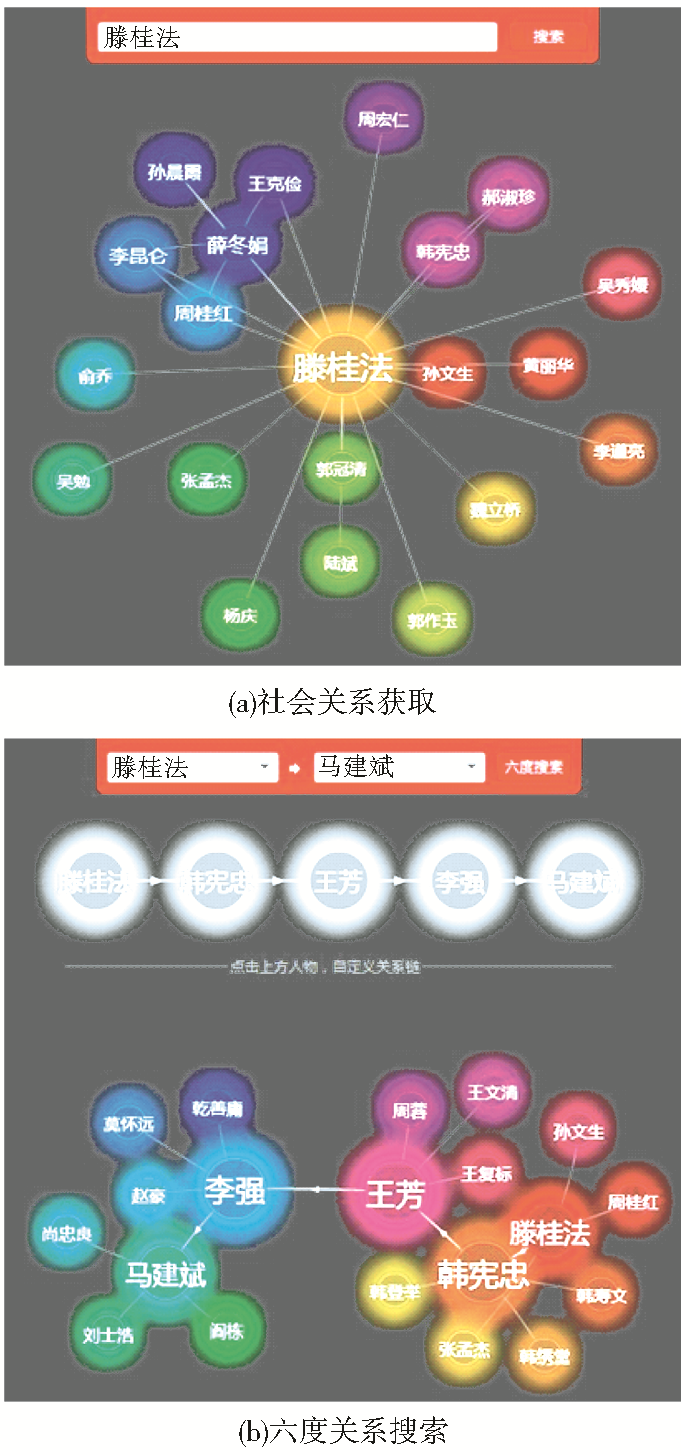 | 图1 人立方效果图 |
 | 图2 社会网络搜索流程图 |
社会关系获取是一种将人、团队、部门、企事业和社区等视为“本体”,从相关信息源中抽取各种本体,建立每个本体的信息剖面,通过分析每个本体的各种特征和属性,挖掘各个本体间的各种关系,包括二元关系、多元关系和传递关系,建立本体间的社会关系网络,该部分是整个社会网络关系搜索中的核心部分。关于社会关系的获取可以归纳为确定网络中的节点和边的问题,也就是社会网络中的实体和实体之间的相互关系。目前国内外对社会关系获取的方法主要分为手动获取社会关系和自动获取社会关系两大类。
手动获取社会关系首先要求用户填写丰富的个人信息来描述自己的社会关系,用户之间可以通过有意的(好友关系)和无意的(用户间的对话)方式建立联系[ 4, 5, 6],最后用户通过静态搜索的方式找到好友。这类方法常见于现在的各类社交网站中,要求用户注册为本SNS网站的用户,然后要求用户从已经注册的会员中查找自己的朋友,向他发送邀请,朋友接受邀请,进而构建用户自己的好友关系表。该方法的优点是操作简便,信息准确率较高。缺点是用户有时不能完全找到他的好友,仅仅是因为他的朋友没有在这个网站中注册,或者是因为朋友太多而忘记了好友的名字,或者是因为他的朋友在这个网站中使用了其他名字而无法找到。另外,在这类网站中,有些人指定了众多好友,而有些人却指定了几个好友,造成了社会关系的不对称。可见,构建海量的用户群和如何让用户很容易准确地找到好友是这类方法成功的关键。
自动获取人际关系主要采用互联网上的海量信息作为计算基础,基于传统搜索的信息挖掘技术,将人和人之间的关系抽取出来,建立实体间的社会关系网络。该类方法获取的信息量大、省时省力,正逐渐成为今后社会关系获取的主流技术。国内外对自动获取人际关系的研究也进行了多方面的探索。根据采用的信息源的不同,归纳起来主要有以下三个研究方向:
(1)以Internet中的Web文档(Blog、Profile、News、Thesis等)为信息源构建社会关系网
基本思想是从Web中提取人名实体,通过共现的人名在Web中的热点程度排序等构建社会网络;该类方法也是诸如人立方、雅虎关系搜索等垂直搜索引擎中普遍采用的方法。目前代表性的抓捕程序主要有:文献[7]的Referral Web是第一个在Web上进行社会关系获取的程序。这个程序的基本思想是将两个联系人A和B在搜索引擎中定义为“A and B”进行搜索,其人物间的关系由人名在网页中的共现标识。缺点是未注重页面的重名现象。文献[8]的Flink抓捕系统主要是从各种语义网络中抓捕人际关系,该系统加入了重名分析,将一系列名字作为输入,然后用搜索引擎计算出潜在关联度。缺点是对在搜索问句中容易产生歧义。文献[9]的POLYPHONET定义了4种科研人员间的简单关系,基于人工标注的训练集得到分类器,根据任意两个人物相关网页的特征,对其进行分类。缺点是文中定义的关系只面向一个较小的领域,若扩展到一个大的领域,则不适用。文献[10]从中文Web中提取人名实体,设计了三种人物间关系定义,并以此为基础构建人物间的关系网络。这种人名实体是网页中出现的名人,判断名人之间是否存在关系的依据是判断两个人名是否存在于同一个网页、句子中或是否由连词连接;对于一些非名人,涉及他们的网页较少。微软人立方从Web网页中自动抽取出人名、地名、机构名以及中文短语,并且通过StatSnowball[ 11]模型自动计算出它们之间存在关系的可能性,但是,这种简单通过人名、地名挖掘人与人之间关系的方法存在局限性和非真实性,而且这些人名都是一些名人,由于普通人的网页较少,因此无法挖掘他们的社会关系,对于重名现象也无法得到很好的解决。文献[12]和[13]主要以论文作者为实体,作者之间的共同作者或作者之间的引用关系为关系构建网络,难点是对文献数据库的获取和重名现象的解决。
(2)以E-mail为信息源构建社会关系网
基本思想是通过挖掘E-mail的From、To等头部信息,建立社会关系网络并对其进行分析。目前代表性的方法有:文献[14]通过挖掘E-mail的信息建立社会关系网络,但是From、To等头部信息无法真实反映人的身份,不能作为判断人与人之间关系的可靠依据。文献[15]通过邮件头信息(From、To、Cc、Bcc等)构建社会网络图,但是简单通过邮件头信息中的From、To表示社会成员身份是不确切的,因为多人共用一个邮箱地址或一个人有多个邮箱地址的现象很常见。文献[16]提出了一种基于个性特征的仿真邮件模拟系统,该系统可以根据不同用户的性格特征来推测其对邮件收发的影响,但随机性较大。
(3)以一些即时聊天工具和论坛为信息源构建社会关系网
基本思想是根据聊天对话的数据内容及存在的回复关系,分析聊天数据间的时序关系,进而引入相似内容来推断聊天数据用户间的社会网络关系。代表方法有文献[17]和[18]提出的基于启发式规则,通过分析聊天数据的时序关系,推断聊天数据用户间的社会网络关系,但是,建立的启发性规则很难涵盖聊天对话中的时序关系,进而造成社会网络建立存在误差。文献[19]使用混合过滤模型对BBS数据进行过滤,并引入社会网络技术进行辅助分析,这些工作仅是使用社会网络分析技术对BBS数据进行分析,而不是对其中的社会网络进行挖掘。
通过对自动获取人际关系方法的分析和总结,可以得到该类方法需要解决如下几个难点问题:人物重名消解;同一身份识别问题(如:周董和周杰伦是否为同一个人);外国人名的音译问题(如:约翰逊和约翰孙);所参考信息源的准确性判断和隐私保护问题。
社会网络可视化的最初研究可以追溯到20世纪30年代, Freeman 阐述了社会网络可视化发展的进程,总结了社会网络在各自时期的显示方法,并提出了进一步的研究方向[ 20]。经过几十年的发展,社会网络的可视化技术已经达到了一个较高的水平,文献[21]-[26]代表了当今国内外发展的现状。但也存在一些问题,主要有:如何显示人物之间的关系及多维属性(包括性别、年龄、职业、兴趣爱好、通讯地址等);如何在有限的页面中显示社会网络的主要结构。解决上述问题的主要方法有树状列表显示和二维图形显示两种形式。
树状列表形式在目前的大多数即时通信软件中被普遍采用,通过对好友分类,把好友以列表或者树状图的形式进行显示。用户通过点击每个类别,该类别中的好友将以树状图的形式进行展开,用户通过点击每个好友的头像可以进一步查看用户的详细信息,该方法的优点是易于实现,简单清晰;缺点是缺乏互动性,不能充分展现出好友之间的亲疏程度和社会网络结构。
二维图形显示则是用节点表示用户和好友,用边表示好友之间的关系。目前使用较普遍的主要有以下几个方向:
(1)六度拓扑显示方法(相关网址参见http://www.6dtop.com/6dtop/)[ 29],该方法以用户为圆心,首先在外围一圈罗列出用户的好友,即一度好友;然后是更外面的一圈,罗列出好友的好友,即二度好友。以此类推,最多可以到六度好友。但是,随着好友度数的上升,好友数量将呈几何级数增加,因此该方法对硬件的要求很高,而且随着好友的不断增减,页面的布局也显得异常凌乱。
(2)一种基于Force-Directed-Layout的算法[ 27],节点之间可以相互挤压,而节点之间的边可以像弹簧一样进行缩短和拉伸,这种算法不仅可以很好地解决页面布局的问题,而且各用户还能够产生动态的效果,使网络更加形象生动。目前比较流行的Douban Link、Facebook Visualiser、Flickr Graph 都是以社交网络为数据基础,以Force-Directed-Layout为核心算法实现的社会网络可视化系统。例如:LinkBar[ 28]就是基于上述算法开发出来的一种社会网络可视化工具。用户可以根据需要在节点中显示出好友上传的头像和昵称,单击好友则在右边的显示面板中显示出他的一些属性信息,此外,用户还可以通过拖动在右上角的好友度数按钮,设定工具只显示用户的一至六度好友。社会网络可视化具体的效果如图3所示:
 | 图3 社会关系可视化效果图 |
在社会网络可视化部分,为了避免各个元素出现交叉或重叠的冲突,可以采用三维显示技术代替目前的二维图形显示。三维立体图形可以通过旋转、放大和切换视角来从不同的角度观察单个元素的相关人际关系,这样既能增加每个元素关系的显示数量,又能方便查看和搜索。三维立体可视化技术将是该部分今后的发展方向。
社会关系搜索主要是根据在六度关系中每个人可以看作是关系图中的一个节点,两个节点通过线直接相连表示他们存在相互联系。这样就可以把社会关系网看成是图论中的点和边的相互关系。在路径图中,连接两个节点的一条边可以根据这两个节点的亲疏度赋予权值,通过定义路径上多个边的权值计算规则,这样两节点之间的路径就变成有权值的,最后根据最短路径算法从加权的社会网络图中找到一个用户到达另外一个用户的最少链接。
社会关系搜索主要分为两大部分,即最短加权路径算法和对人际关系的加权处理。目前最常用的最短路径算法主要有:Di jkstra算法、A*算法、 SPFA算法、Bellman-Ford算法、Floyd-Warshall算法等,国内外大量的文献都对上述算法进行了详细的介绍和改进,这些算法已经比较成熟,本文不再具体叙述。在对人际关系的加权处理上,由于加权与朋友间的亲疏程度和他们所处的社会关系密切相关,而他们的亲疏程度和社会环境又随着时间和空间不断动态变化,因此对朋友间的权重很难数值化,目前尚无法很好地解决如何设定用户朋友权重的问题,此领域的研究也很少。
如何利用已经构建的社会关系网络,对人物关系进行精确而有效的分类,并设定不同关系的权重,是社会关系搜索的关键。比较流行的解决办法是事先定义各种关系类型,然后根据人工构建的社会关系体系进行加权。但是构建一个精确全面的关系体系往往是很困难的,甚至是不可能的。例如Relationship[ 29]规定了40多种人物关系,如果对每种关系都设置关系,那么对实例来构建关系体系将是相当大的工作,而且在Web中展示的人物关系往往也不是如文献[29]规定的人物关系。笔者认为,对于人际关系的加权处理,可以根据Web的不同信息源来进行加权。对于BBS、论坛、博客、E-mail等各种自治的社会网络,朋友之间往往越亲密,相互之间的交流也越多,可以通过统计用户一段时间内发起对话的多少(回帖数、消息数、邮件数)进行关系加权。而对于通过特定的数据集在无意间构成的在线论文社会网络,可以根据论文作者之间的共同作者或者排列顺序进行关系加权(往往两个作者共同发表的论文数量越多,他们的关系越紧密;往往第二作者与第一作者要比第三作者与第一作者的关系紧密);而对于根据各种新闻资讯构建的社会网络,对关系进行加权比较复杂,可以根据在一定段落或一句话里同时出现两个以上的人名就认为他们有关系,通过统计两个人名共同出现的频率来进行亲疏度的判断。由于社会关系随着社会环境的变化而变化,今后还可以考虑更多的因素进行研究:
(1)社会关系本身所属的类型:根据不同社会关系类型(血缘关系、同事关系、同乡关系等)其亲密程度是不同的进行加权。
(2)信任的影响:往往对朋友越信任,双方之间的关系也越紧密。
(3) 熟识度:往往双方越熟悉,其关系就越亲密,信任度也越高。
(4)声望和地位:一个人的声望和地位越高,则会吸引他人愿意与其交往,并被赋予较高的信任度。
(5)关系时间量:包括交互频度和持续时间。花在关系上的时间量越多,则关系越亲密,反之则越疏远。
社会网络搜索已经成为SNS服务中的一个非常具有前景和挑战的研究领域。本文从社会关系获取、社会网络可视化和社会关系搜索三个层面,较为系统地梳理并介绍了各部分的主要技术和优缺点,并对其发展方向进行了展望,以期为将来社会网络搜索的进一步研究提供参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|