{kind=link}
基于基本要素方法的中文自动文本摘要模型
[程倩倩 , 田大钢]
, 田大钢]
, 田大钢]
|
|


提出一种基于基本要素方法的中文自动文本摘要模型(BESM)。该模型主要借鉴基本要素的思想进行建立,和单纯的基于词的自动文摘模型相比,它将语义信息作为评估句子重要程度的一部分,实现基本要素中提出的将语义信息和统计方法的结合。通过与普通方法的实例对比,突出基本要素方法的优越性和BESM模型的可行性。
The article proposes a model of automation Chinese summarization based on the basic elements method(BESM). The model uses the basic elements method theory, and it has some advantages that comparing with the model based on words, the model shows more symantic information. Combining the symantic information with statistic approach makes our summarization more precise and quick. Finally,the experiment results show that the BESM is better than common method.
随着Internet的迅速普及和信息量的激增,信息的自动化压缩处理亟待解决,自动文本摘要是运用计算机手段对大量信息进行压缩后得到的有用信息,是现代化管理工具中最重要的技术之一。本文将DUC2005提出的基本要素(BE)方法运用于中文自动文本摘要,提出了一种基于基本要素方法的BESM模型,最后用实例验证了BESM模型的有效性。
自动文本文摘技术主要分为两类:需要领域知识库作为支撑的基于理解的方法(Abstracting)和不依赖于具体领域的基于统计的方法(Extracting)[ 1]。由于环境和资源的限制,基于统计的方法有其便利之处。而文本理解在很大程度上是个未解决的问题,所以抽取的方式对于自动文本摘要的生成仍然很重要。在基于句子抽取的方法中,经常采用聚类的方法去除冗余信息。而在句子或者段落等级别上的聚类,一般来说都选择词作为最小元素来进行[ 2],即将句子或者段落拆分成词的集合。但是词往往有多个含义,不利于精度的提高,所以其运用有一定的局限性。
基于对上述问题的考虑,DUC2005提出了基本要素方法(Basic Elements, BE)[ 3, 4]。BE描述的是基本要素中心词(Head)及其修饰(Modifier)之间的关系(Relation),表示为一个三元组“中心-修饰-关系”(Head| Modifier| Relation),其中中心词是主要的语法元素,通常为名词、动词、形容词或副词短语。
BE的优越性在于:
(1)BE是直接通过语法分析得到的,不需要语料库的支持,所以比词作为聚类最小单位更为准确;
(2)BE作为自动文摘评测的手段可以很好地克服人工评测方式带来的不足,由于BE是依据句子的结构信息得到的,所以这个三元组中不仅有语义(词)的信息,还含有句子的结构信息,一个更重要的方面是,这些单元可以自动构造而不需要人工进行。
MSBEC是文献[6]提出的基于基本要素向量空间的英文多文档自动摘要,本文提出的BESM模型主要借鉴该模型的方式来处理中文文档,因为英文和中文有很多不同之处,所以本文主要做了如下改进工作:
(1)国外学者一般运用BE Package[ 3]对英文文档进行处理,它是一个工具包,可以通过注册获得,整合了BE Breakers、BE Scorers、BE Matcher、BE Score Integrators等主要功能[ 3]。但是由于它对中文文档进行处理的技术很难得到,所以本文借鉴了基本要素的思想,设计了一种简单的剪枝方法对基本要素进行自动抽取,即直接选取4类基本要素的中心词-名词词组中的名词、动词词组中的动词、形容词词组中的形容词和副词词组中的副词。
(2)对MSBEC中计算句子分值的公式进行了改进,量化了句子在文档中的位置重要性。
(3)提出了一种客观的抽取句子方法,使文摘长度更为合理。
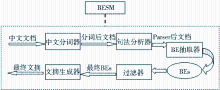
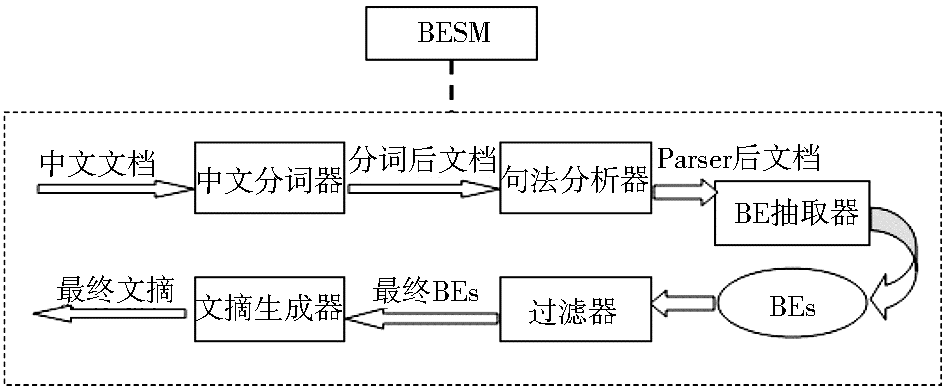
按照中文自动文本摘要的一般步骤[ 7]来实现BESM模型,其具体步骤如下:
(1)中文文档分词。首先将中文文档中的句子分成一个个词的形式,便于后续处理。
(2) 句法分析。将分词后的文档以句子的形式输入句法分析器,此处采用Stanford Parser软件,得到句法分析后的文档。
(3)抽取基本要素(BEs)。将句法分析后的结果剪枝处理,抽取出基本要素。抽取原则按照基本要素的定义来进行,这里直接选取4类基本要素的中心词,即需要抽取出的是名词词组中的名词、动词词组中的动词、形容词词组中的形容词和副词词组中的副词。
抽取的具体过程用伪代码表示如下:
File BEGIN
Sentence BEGIN //句子循环开始
Find “NN”, “NR” in “NP”, Extract them;
//抽取出名词词组“NP”中的名词,“NN”为名词,“NR”为人名处所等名词
Find “VV”, “VA”, “VC” in “VP”, Extract them;
//抽取出动词词组“VP”中的动词,“VV”为动词,“VA”为程度动词,“VC”为施动词
Find “JJ” in “ADJP”, Extract them;
//抽取出形容词词组“ADJP”中的形容词“JJ”
Find “AD” in “ADVP”, Extract them.
//抽取出副词词组“ADVP”中的副词“AD”
Sentence END //句子循环结束
File END
(4)过滤掉停用词。根据停用词表进行过滤,得到过滤后的基本要素。
(5)计算BEs分值。用经典的TF×IDF公式[ 8]进行BEs分值计算,设D为中文文档,si表示文档D中的第i个句子,BEij表示句子si中第j个基本要素,则其TF×IDF公式如下:
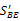
其中,文档频率TF(BEij)是绝对频率,即BEij在文档D中出现的次数;IDF(BEij)为反文档频率,计算方法如下:
IDF(BEij)=log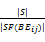
其中,SF(BEij)为D中所有包含BEij的句子数,|S|为D中所有的句子数。
最后需要对公式(1)进行归一化处理,得到基本要素的最后权重分值:
SBE(BEij)= 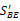
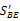
(6)计算句子分值。用一种考虑句子在文档中位置信息的方法来进行句子分值计算。具体过程如下:
Ss(si)=

其中,α+β+ε=1,li为句子中含有BEs的个数,SBE(BEij)为公式(3)中的基本要素权重分值, 
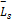
笔者添加了Ss(location)部分,它量化了句子在文档中的位置信息,具体表示如下:
Ss(location)=θ×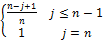
公式(5)中的θ为表示句子所在段落在文档中的重要程度,根据中文一般文档的习惯,文档的首段和末段是最重要的[ 9],可以分配θ一个大的权重,而中间的段落相对来说比较不重要,可以分配θ一个相对较小的权重。n代表一个段落中所有句子总数,j代表这个段落中的第j个句子。除了末句外,越靠近段首的句子越重要。
(7)句子聚类。建立句子列表SL,其中的句子按照各个句子在中文文档中的位置来排序。本文将整个文档D中的BEs作为句子向量的特征空间来建立向量空间模型(Vector Space Model,VSM)[ 10, 11]。为了减少一些信息量少、不重要的基本要素的影响,只选取权重分值高于平均分值的基本要素,共N个。
句子列表SL中的M个句子,每个句子si表示成一个向量VSi,这样整个文档就成了一个有M个向量的N维向量空间。VSi=(WBEi1,WBEi2,……,WBEiN),i=1,2,……,M。其中,WBEij为SL中第i个句子si中第j个基本要素的特征值,j=1,2,……,N。该特征值的计算公式也采用TF×IDF[ 8]的形式,如下所示:
WB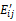

其中,前一部分为绝对频率,TF(BEij)代表si中第j个基本要素在该句子中出现的次数;后一部分为反句子频率,Mj表示该基本要素BEij在文档D中出现的句子数。同样对公式(6)进行归一化处理,得到:
WBEij=WB 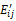

选取最经典的K-Means[ 11]方法进行句子聚类,K的选择用一种枚举适应法。通常句子的相似性用两个句子对应的向量间余弦表示[ 12],如下所示:
SIM(VSi,VSj)=cos(VSi,VSj)=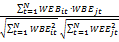
而句子间的距离[ 12]可以定义为:
DIS(VSi,VSj)=1-SIM(VSi,VSj)(9)
类内聚合度和类间离散度[ 6]如下:
SI(ci)=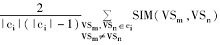
SO(ci,cj)=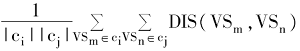
其中,ci为K-Means Cluster产生的第i个类;|ci|为ci类中的样本个数。
本文的聚类效果评价函数定义[ 6]如下:
F(C)=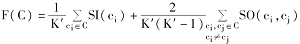
在评价函数中,当聚类个数为K'时的聚类结果为C。而实际上类的个数则是使评价函数值最大的聚类个数[ 6],即:
K= 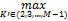
(8)句子抽取。自动文本摘要对于句子抽取的一个常用方式就是根据用户的需要长度来抽取,但是由于用户并不知道什么长度是合适的[ 12],因此这种方式有很大的主观性。
本文考虑了一种方法,即综合分析文档中句子的平均长度 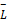
①得到用户想要的长度指标;
②根据句子的平均长度 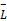
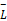
③确保K类中值最大的句子都已经抽取一遍后,如果K× 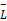
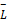
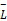
④根据用户提出的长度要求调整抽取长度。
针对上文所述的模型技术实现,需要以下系统和软件环境作为BESM的实验基础:
(1)Windows 98以上环境;
(2)JDK 1.5以上的Java环境:运行中文文档分词和句法分析软件的必需环境;
(3)Stanford Parser网站的ChineseSegmenter软件包:用来对中文文档进行分词处理;
(4)Stanford Parser句法分析软件:对分词后的中文文档进行句法分析;
(5)Excel:用VBA程序模拟抽取BEs,求取BEs和句子分值等中间步骤;
(6)SPSS统计专用工具:用K-Means Cluster对句子进行聚类处理。
本文主要对两组中文文档做自动文摘实验,这两组数据是有关上海世博会的相关资料:温家宝总理在第七届中国2010年上海世博会国际论坛的发言[ 15]和国务院副总理、中国2010年上海世博会组委会主任委员王歧山发表的第七届中国2010年上海世博会国际论坛闭幕式闭幕词[ 16]。
为了突出句子分值公式的改进效果,对比实验了一种BESM’方法,该方法是用改进前的公式[ 6]来计算句子分值,其他过程完全和BESM类似,是引申于本文BESM的方法。
为了突出基本要素方法的优越性,另外对比实验了普通方法,即以普通词为最小特征单位,基于普通词的分值来计算句子分值(也用改进前的公式[ 6]),最后的VSM模型是以普通词为特征空间得到的句子向量,然后进行聚类抽取句子。
本文采取内部评价的方法[ 14],内部评价虽然主观性太强,不利于对多个文摘系统进行客观评价,但是对于自动文本摘要系统的改进有很大的帮助,比较有针对性,其本身的评价过程也是对系统的一种深入研究学习过程。该评价方法主要有召回率、准确率和基本要素覆盖率等几个指标。
设专家抽取句子数目NE,自动文本摘要抽取句子数目为NS,同时被自动文摘系统和专家文摘抽取的句子数目为NSE,则召回率和准确率[ 14]公式如下:
R=NSE/NE(14)
P=NSE/NS (15)
由于本文是基于基本要素方法进行的自动文本文摘,所以这里的主要词覆盖率就是本文最后自动文本文摘中抽取句子中的基本要素与整个文档自动文本要素的数目NBED比。
G=NBES/NBED(16)
具体实验结果如表1所示:
| 表1 BESM和普通方法的评价对比 |
实验中θ表示句子所在段落在文档中的重要程度,根据文献[9]所述,为了区分出首末段比中间段重要,本文将首段和末段的θ值设为1,而中间各段的θ值设为0.5。这样在实验的第一组资料中,专家文摘共有14个句子,根据设定的抽取原则,BESM聚类得到7类,抽取第一轮后得到7个句子,长度为692,大于设定的最小长度,即类别和文档中句子平均长度的乘积——7×52=364;但是7个句子远小于文档中所有句子数的一半,所以再抽取一轮,最后得到12个句子。用同样的方法,BESM’和普通方法也都抽取出12个句子。BESM与专家文摘相同的共有12句,BESM为10句,普通方法为9句。第二组资料中,专家文摘共有7句,BESM和BESM’都抽取出7句,普通方法抽取出8句,BESM和BESM’有6个和专家文摘一样的句子,总共1句不同;普通方法也有6句和专家文摘相同的句子,比专家文摘多出1句,总共有2句不同。这些实验情况反映在召回率、准确率等指标就得到了上面的结果。召回率、准确率越高,说明得到的文摘与专家文摘越相似,即效果越好。
BESM和BESM’的对比突出了句子位置信息的重要性;BESM’和普通方法的对比突出了基本要素方法的效果。总体上来说,BESM比普通方法得到的中文自动文本摘要好。
在实验中还发现,BESM处理大规模的文档时效果更好,即资料一比资料二的效果要明显。
本文研究了一种基于基本要素方法的中文自动文本摘要模型,该模型考虑了句子中词的语义信息,比普通方法得到的效果更好。在今后,仍要继续研究的是强有力的基本要素匹配原则和让BESM模型适应更为复杂的中文自动文本摘要要求,无论是从准确性还是从抽取摘要的速度上都需要进行深入性的研究改进。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|