
{kind=link}
{kind=link}
{kind=link}
基于概念格的数字图书馆用户检索行为序列模式挖掘研究
[黄微, 毕强 , 滕广青]
, 滕广青]
, 滕广青]
|
|


提出一种基于概念格的数字图书馆用户检索行为序列模式挖掘方法。该方法采用“基于概念格的自顶向下与分治相结合”的挖掘思想,通过自顶向下的概念格迭代,利用概念格的复用性和提取频繁项集的优势,获得数字图书馆用户检索行为的序列模式。该方法不需要遍历原始用户信息数据库,能够大大压缩挖掘时间,有助于数字图书馆提高用户检索速度、改进个性化服务。
This paper presents a method to mining the sequential patterns from the user’s retrieval behaviors of digital library based on concept lattice. This method searches out the sequential patterns of the user’s retrieval behaviors by mining ideas of “combining top-down and dividing-and-ruling based on concept lattice”, using the application of the re-usability of concept lattice and its advantage in the extraction of frequent itemset. The method does not require comprehensive scanning to the original user information database, and it greatly reduces the time of mining that can help digital libraries to enhance the user retrieval speed, and improve the personalized services.
序列模式挖掘在数字图书馆用户服务建设中的相关研究和应用尚没有像聚类和关联规则挖掘那样成为研究热点,这主要是由于传统的序列模式挖掘活动中的时间因素使得挖掘工作空前复杂。然而,序列模式对于现实生活中的趋势分析、相似性查询、周期分析等工作具有不可忽视的指导意义。如何更方便可行地从数字图书馆用户检索行为中挖掘序列模式,帮助改进和完善数字图书馆用户服务,是本研究的目的所在。
序列模式挖掘的概念由Agrawal和Srikant在1995年率先提出,并同时提出了序列模式发现的经典算法AprioriAll[ 1]。其目的是在现有的有序事务的集合中寻找满足支持度阈值的频繁序列模式,这种序列模式实际上是一种带有时间约束的关联规则。其后,序列模式挖掘在算法上不断更新改善,陆续出现了基于“候选码生成-
测试”的GSP算法[ 2]、PSP算法[ 3]、SPADE算法[ 4]等,这类算法需要多次扫描数据库,资源开销极大,挖掘耗时;以及基于模式增长策略的FreeSpan算法[ 5]和PrefixSpan算法[ 6]等,这类算法采用分治思想,通过数据库投影技术提高了算法效率。
随着概念格理论在数据挖掘领域的兴起,许多学者在聚类、关联规则挖掘等研究中引入了概念格的思想,然而目前基于概念格的序列模式挖掘研究的成果并不是很多。其中具有代表性的成果包括:文献[7]提出了外延约简的概念,扩展了概念格模型;文献[8]设计实现了基于多维概念格结构的增量式多维序列模式挖掘算法;文献[9]提出了基于兴趣度的序列概念格模型及其构建算法;文献[10]提出了一种基于概念格的挖掘时间序列的周期关联规则的算法;文献[11]提出了对象相关的趋势概念格概念并提出了相应的建格算法和决策规则提取算法等。
目前,基于概念格的序列模式挖掘成果主要体现出两个特征:
(1)大多数挖掘思想和算法虽然已经不需要多次扫描数据库,但一般至少要遍历数据库一次。这在今天以TB、PB计算的海量数据中仍然制约了挖掘活动的实际可操作性。
(2)各种挖掘思想几乎都是把建格过程等同于挖掘过程,概念格建成则挖掘工作完成。加入多种因素、通过多种方式构建的特殊结构的概念格,忽视了概念格强调复用性的初衷。
数字图书馆用户检索行为的序列模式挖掘就是给定一个由用户检索行为组成的数字图书馆用户信息数据库DB。根据领域专家确定的最小支持度阈值(Minimum Support)在数据库中挖掘出所有频率不小于给定支持度阈值的序列,即频繁序列。当然,最终的序列模式应该是最大频繁序列。
定义1:在用户信息数据库DB中,项集(Itemset)是由若干个项(Item)组成的非空集合,记作I=(i1,i2,…,im),其中ik(1≤k≤m)是一个项,代表一个检索对象。长度为k的项集称为k-项集。
用户在某时刻发起的一个包含检索行为的Session在数据库DB中以一条记录描述,内容包含用户号(U_ID)、访问时间(S_TIME)和用户提交的检索对象的集合(S_ITEM)。规定同一个用户发起不同的Session被视为该用户的另一次检索行为,并且不考虑用户在一个Session中所提交的检索对象(项)的数量。例如,某Session中用户提交的检索对象为“莎士比亚、戏剧、哈姆雷特”(分别为3个检索式,提交了3次),用e、h、k表示,则该用户的项集为:3-项集(ehk);若另一Session中提交的检索对象为“莎士比亚.and.戏剧、哈姆雷特”(分别为2个检索式,提交了2次),则该用户的项集为:2-项集。用户信息数据库的示例如表1所示:
| 表1 用户信息数据库示例 |
定义2:序列(Sequence)是由项集组成的有序表,即不同项集的有序排列,记作S=
| 表2 用户检索行为序列 |
定义3:给定两个序列A=
例如,序列<(e)(m)>包含于序列<(e)(k)(mps)>,因为(e)⊆(e),(m)⊆(mps);而序列<(e)(m)>与序列<(em)>互不包含。
定义4:如果一个序列S包含于一个数字图书馆用户检索行为的序列中,则称该用户的检索行为支持序列S。序列S的支持度(Support)是指数据库DB中支持序列S的用户数(称为S的支持数)与用户总数之比。支持度大于最小支持度(Minimum Support,由领域专家指定的阈值)的序列称为频繁序列(Frequent Sequence)。
例如,给定最小支持度为35%,则所得的序列模式在数据库DB的5位用户中至少被1.75位(2位)用户检索行为的序列支持,由此得出序列模式如表3所示:
| 表3 支持度大于35%的序列模式 |
序列模式<(e)(m)>被用户1和用户3所支持。用户3在项e和m之间还检索了项k,并且在检索项m时还检索了项p和s,但仍然支持模式<(e)(m)>,这是因为所找的模式并不要求一定连续。序列<(e)>,<(e)(k)>,<(k)(ps)>,<(e)(k)(s)>等虽然满足最小支持度(即是频繁的),但并不是序列模式,因为它们不是最大的。
本研究主要采用“基于概念格的自顶向下与分治相结合”的挖掘思想,利用数据库投影技术生成投影数据库,通过自顶向下的概念格迭代,分别求出满足支持度阈值的“上层概念格”的“上层频繁项集”和“下层概念格”的“下层频繁项集”,最终获得全局最大频繁序列,即序列模式。研究中“上层(Upper)”与“下层(Lower)”的关系描述的不是概念格内部“超(Super)”与“子(Sub)”的关系,而是不同概念格之间“自顶向下”的关系。其核心思想的拓扑结构如图1所示。
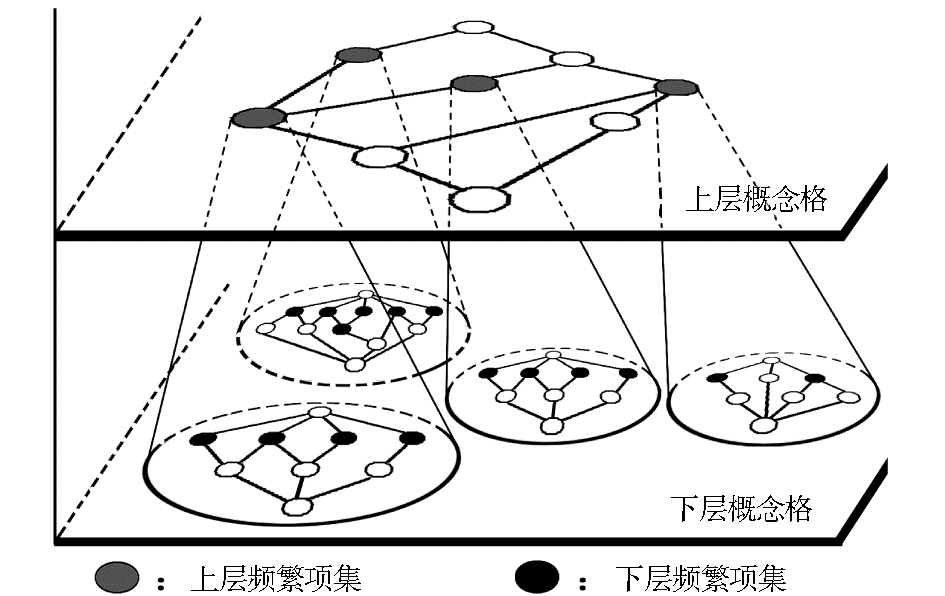 | 图1 “基于概念格的自顶向下与分治相结合”挖掘思想的拓扑结构 |
基于概念格的用户检索行为序列模式挖掘的具体技术路线如下:
(1)将包含用户检索行为的数字图书馆用户信息数据库按照用户ID进行归集,生成投影数据库。
原数字图书馆用户信息数据库以用户ID和Session时间为主键,归集后得到的投影数据库以用户ID为主键。由于现实数据库中每个用户会有多次检索行为,因此得到的投影数据库在规模上被大大压缩。
(2)以投影数据库为形式背景,通过形式概念分析(Formal Concept Analysis, FCA)[ 12]构建“上层概念格”。
因为此时构建的概念格是站在原始数据库的投影库的高度上完成的,并且其概念的对象为粗粒度的各个数字图书馆用户,因此,此概念格被定义为“上层概念格(Upper Concept Lattice)”。
(3)根据设定的支持度阈值从“上层概念格”中提取“上层频繁项集”。
由于“上层概念格”中的各频繁项集的外延集合是粗粒度的数字图书馆用户ID的集合,其所代表的是数字图书馆的具体用户,而不是细粒度的各用户的检索行为,因此,此处“上层概念格”中的频繁项集被定义为“上层频繁项集(Upper Frequent Itemset)”。
(4)从原始用户信息数据库中抽取某个“上层频繁项集”的外延集合所对应的数字图书馆诸用户的所有检索行为(包括用户ID、Session时间和检索对象集合),并以此为形式背景通过形式概念分析[ 12]构建“下层概念格”。
此时构建的概念格是在全局高度之下针对一部分用户检索行为完成的,同时其概念的对象为细粒度的各个数字图书馆用户具体的检索行为,因此,此概念格被定义为“下层概念格(Lower Concept Lattice)”。
(5)在“下层概念格”中提取满足最小支持度阈值要求的“下层频繁项集”。
由于“下层概念格”中的各频繁项集的外延集合是细粒度的数字图书馆用户具体检索行为的用户ID和Session时间的集合,因此,“下层概念格”中的频繁项集被定义为“下层频繁项集(Lower Frequent Itemset)”。
(6)根据提取的“下层概念格”中的“下层频繁项集”求出“下层概念格”对应的最大频繁序列。
此步骤中,首先根据“下层频繁项集”穷举“下层概念格”中对应用户所支持的长度不小于2的可能序列;然后找出其中满足支持度阈值的所有频繁可能序列;通过比较得到该“下层概念格”对应的最大频繁序列。
(7)重复步骤(4)-(6),直至步骤(3)中提取的各“上层频繁项集”所对应的数字图书馆用户检索行为逐一建立了“下层概念格”并提取了每个“下层概念格”对应的最大频繁序列。
(8)将各个“下层概念格”中提取的最大频繁序列进行比较,从而获得所有用户检索行为当中的全局最大频繁序列,即为数字图书馆用户检索行为的序列模式。
数字图书馆中存储用户检索行为的用户信息数据库DB可以理解成为一个三元组K=(U,D,R),其中U为所有检索行为的集合,D为所有检索对象的集合,R是U和D之间的一个二元关系。
这样的一个三元组显然是典型的形式背景。然而,若以此来构建概念格,则需要遍历整个数据库,而且只能生成1-序列,这相当于完成了AprioriAll[ 1]和GSP[ 2]等算法的初始工作。而作为序列模式挖掘研究而言,单纯的1-序列并没有现实意义。
将DB数据库中的记录按照数字图书馆用户ID进行归集生成投影库,由于现实中每个用户都可能进行过多次检索行为,因此所得到的投影数据库规模将被大大压缩。表1的用户信息数据库的投影库对应的形式背景如表4所示:
| 表4 用户信息数据库的投影库对应的形式背景 |
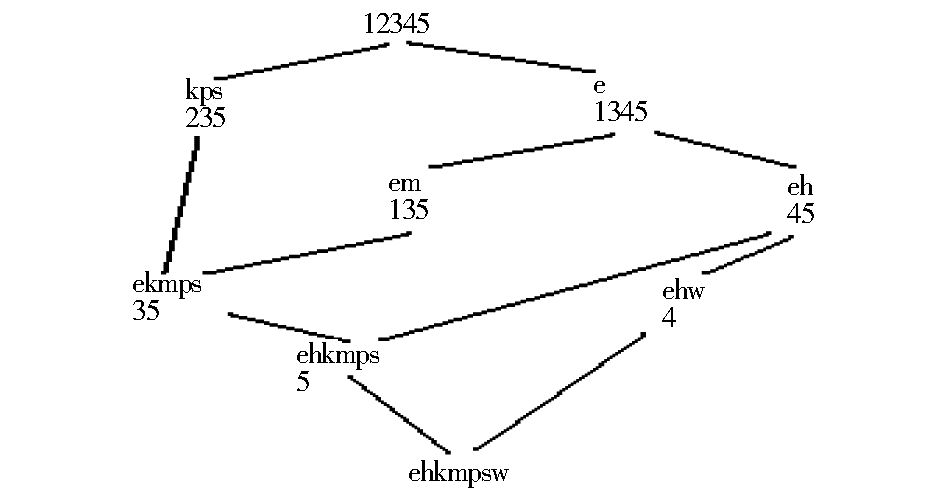 | 图2 形式背景对应的“上层概念格” |
在设定支持度阈值为35%的情况下,得到长度不小于2的“上层频繁项集”为(ekmps)、(eh)、(kps)和(em),项集内项的排列遵照字典序。1-项集(e)虽然满足最小支持度阈值,但单纯的1-序列在序列模式挖掘中没有实际意义,因此此处忽略1-项集。然而,频繁项集还不是序列,只是序列的可能。分别以“上层频繁项集”的外延集合所对应的用户检索行为构建“下层概念格”。“上层频繁项集”(ekmps)的外延集合所包含的用户3、5的检索行为所对应的形式背景如表5所示:
| 表5 用户3、5的检索行为对应的形式背景 |
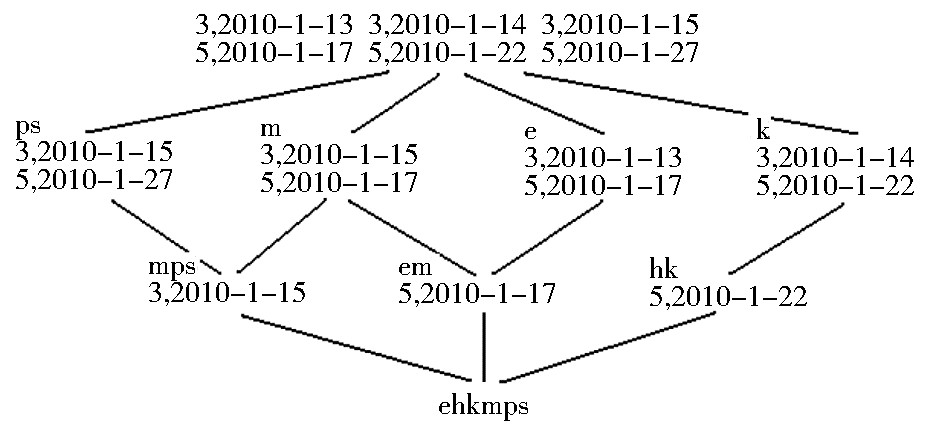 | 图3 形式背景对应的“下层概念格” |
在设定支持度阈值为35%的情况下,图3“下层概念格”得到的“下层频繁项集”为(ps)、(m)、(e)和(k)。将图3“下层概念格”中的各“下层频繁项集”按照其所对应用户检索行为的时间排序,并分别穷举各用户所支持的长度不小于2的可能序列。由于此处只针对“上层频繁项集”(ekmps)的外延集所包含的用户检索行为,因而不需要遍历原始用户信息数据库。
在“上层频繁项集”(ekmps)对应的“下层概念格”中,用户3支持的长度不小于2的可能序列包括:<(e)(k)>、<(e)(k)(m)>、<(e)(k)(ps)>、<(e)(m)>、<(e)(ps)>、<(k)(m)>、<(k)(ps)>。用户5支持的长度不小于2的可能序列包括:<(e)(k)>、<(e)(k)(ps)>、<(e)(ps)>、<(m)(k)>、<(m)(ps)>、<(m)(k)(ps)>、<(k)(ps)>。其间用户3和用户5同时支持(满足支持度阈值)的频繁序列为:<(e)(k)>、<(e)(k)(ps)>、<(e)(ps)>、<(k)(ps)>。由于<(e)(k)>⊆<(e)(k)(ps)>、<(e)(ps)>⊆<(e)(k)(ps)>、<(k)(ps)>⊆<(e)(k)(ps)>,所以其中最大频繁序列为:<(e)(k)(ps)>。
同理,针对“上层频繁项集”(eh)、(kps)和(em)的外延集合所对应的用户检索行为分别建立“下层概念格”,并求出各“下层概念格”对应的最大频繁序列。其中,“上层频繁项集”(eh)对应的“下层概念格”没能生成满足支持度阈值要求的最大频繁序列;“上层频繁项集”(kps)对应的“下层概念格”得到了两个满足支持度阈值要求的最大频繁序列,分别是由用户2、用户3和用户5支持的最大频繁序列<(k)(s)>,和由用户3和用户5支持的最大频繁序列<(k)(p)>;“上层频繁项集”(em)对应的“下层概念格”得到了由用户1和用户3支持的最大频繁序列<(e)(m)>。
但是在全局所有用户的检索行为中,序列<(k)(s)>和<(k)(p)>是序列<(e)(k)(ps)>的子序列,因此舍去。最后,得到数字图书馆用户检索行为的序列模式为:<(e)(k)(ps)>和<(e)(m)>。
(1)就挖掘时间而言,传统经典的序列模式挖掘算法如AprioriAll算法[ 1]、GSP算法[ 2]等没有采用“分治”的思想,并且挖掘活动是“自底向上”的。在挖掘活动中,可能产生大量的候选序列,同时算法的每一次迭代都需要遍历数据库,使得挖掘时间冗长,实用价值低。“基于概念格的自顶向下与分治结合”作为一种挖掘思想与具体算法无关,文献[7]-[9]已经论证了相关的基于概念格的挖掘算法的优越性。本研究中提出的思想采用数据库投影技术生成投影数据库(如果每个用户有100次检索行为,则投影数据库的记录个数就被缩减为原数据库的1/100),挖掘过程中仅需遍历缩减后的投影数据库一次。从原始用户信息数据库到被大规模缩减后的投影数据库,从多次大规模遍历到仅有一次小规模遍历,新挖掘思想大大压缩了挖掘时间,最大限度地提高了挖掘效率。
(2)就挖掘效果而言,由于概念格在提取频繁项集方面具有强大的优势,而序列模式恰恰是建立在频繁项集的基础之上,因此基于概念格的序列模式挖掘能够比其他传统方式更精准地提取数据源中满足阈值要求的频繁项集,提高了挖掘工作的感知有用性(Perceived Usefulness)[ 13]。同时,概念格的另一特点在于相同的形式背景(背景中各元素的顺序则可以不同)无论采用何种方法,最终得到的概念格一定是唯一的、稳定的。正是因为如此,本研究通过概念格迭代多次反复使用概念格提取频繁项集,强调以概念格为工具,而不是试图构建与众不同的概念格,最大限度发挥了概念格的复用性,简化了挖掘工作的技术复杂程度,改善了挖掘工作的感知易用性(Perceived Ease of Use)[ 13]。
(3)就应用前景而言,数字图书馆用户检索行为的序列模式挖掘与关联规则挖掘不同,目的是为了寻找一段特定时间以外的可预测的用户检索行为模式。尽管序列模式和关联规则都是建立在频繁项集的基础之上,但是序列模式挖掘更强调探究多个事务之间形成的频繁序列,即先后次序问题。这些序列模式可以帮助改进数字图书馆的检索词表的结构,如果用户在检索“维多利亚”(前英国女王的名字)之后经常检索在检索词表中距离较远的“双城记”(狄更斯的代表作品),就有必要缩短它们之间的距离,增加链接或查询扩展选项,在维多利亚和维多利亚时期的文学作品之间建立联系,从而提高用户检索速度,改进用户服务。
针对数字图书馆用户检索行为进行序列模式挖掘,可以帮助数字图书馆优化拓扑结构、提高用户检索速度、改进用户个性化服务、构建智能化数字图书馆。研究中采用“基于概念格的自顶向下与分治相结合”的挖掘思想,通过自顶向下的概念格迭代,利用概念格的复用性和提取频繁项集的优势,分别求出满足支持度阈值的频繁项集,并最终获得数字图书馆用户检索行为的序列模式,具有良好的挖掘效果。采用该思想方法进行数字图书馆用户检索行为序列模式挖掘不需要遍历原始用户信息数据库,大大压缩了挖掘时间。
随着概念格理论的不断完善和序列模式挖掘研究的不断深入,其在具体领域的实证研究也必将成为今后研究的一个热点方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|