

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Nutch的专题网页资源采集服务系统的设计与实现
[常智荣1  , 马自卫
, 马自卫2 , 李高虎3 ]
, 马自卫|
|


在数字图书馆系统集成应用的框架下,提出基于Nutch的专题网页资源采集服务系统设计方案。该方案引入信息过滤模块、基于计算机通信领域专业词典的中文分词模块、GUI信息定制模块、词典和关键词管理模块等,保证采集和获取过程中资源的专题性和系统的可管理性以及易用性。重点对文本解析过滤、Plugin插件开发以及搜索结果的层次化自动聚类等相关技术进行深入研究。通过基于Webservice的服务接口,实现其在数字图书馆资源层的集成应用。
This paper proposes the design of Nutch-based Website Harvest and Service system in Special field under the framework of digital library systems integration. It introduces information filtering module, dictionary-based Chinese analyzer module, GUI information module,topic-knowledge based information processing module as well as the Webservice-based search service modules to improve function and performance of the system. It focuses on text parsing filters, plugin development and applications of the level-automatic clustering of the search results. Finally, integration with other subsystem in digital library is realized through the Webservice-interface, which can provide comprehensive and professional services.
网页资源成为一种重要的学术资源形式,在数字图书馆的资源建设中日益受到重视,搭建能够对中文网络信息资源进行处理的网络信息资源采集与服务平台,是一项非常有意义的研究课题。常用的开源采集工具有
Nutch[ 1]、Heritrix[ 2]、WCT[ 3]、NetarchiveSuite[ 4]、Smart Crawler[ 5]、Wget等[ 6]。上述软件各具特色, 其中Nutch不仅提供了抓取网页的功能,还提供了解析网页、建立链接数据库、对网页进行评分、建立Lucene索引和提供检索界面等丰富的功能,提供了一个完整的搜索引擎基本框架。自Nutch 0.8.0 版本后的核心代码基于Hadoop[ 7]架构实现,支持分布式集群扩展。
Nutch具有突出的功能特征和性能指标,吸引国内外学者对此做了大量的研究和实践,在种子站点的发现、过滤、抓取过程控制、中文分词、网页去噪、结果排序、内容聚类分类等领域积累了大量的算法和技术成果。目前对于Nutch的应用更多的是停留在基本功能的实现,本文的设计方案充分与实际应用相结合,力求功能的完善和性能的提高,并将具有独立功能的专题网页资源采集服务系统与其他数字图书馆应用系统集成,以提供全面、专业的服务。
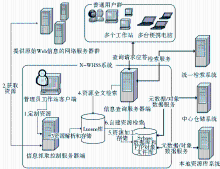
基于Nutch的专题网页资源定向采集服务系统(Nutch-based Website Harvest and Service system in Special field,N-WHSS)是北京邮电大学数字图书馆集成系统的一个子系统。它作为本地专题网页资源的提供者与数字图书馆集成系统的其他子系统交互,为其提供网页资源的数据源。系统的部署情况和满足的业务功能需求如图1所示:
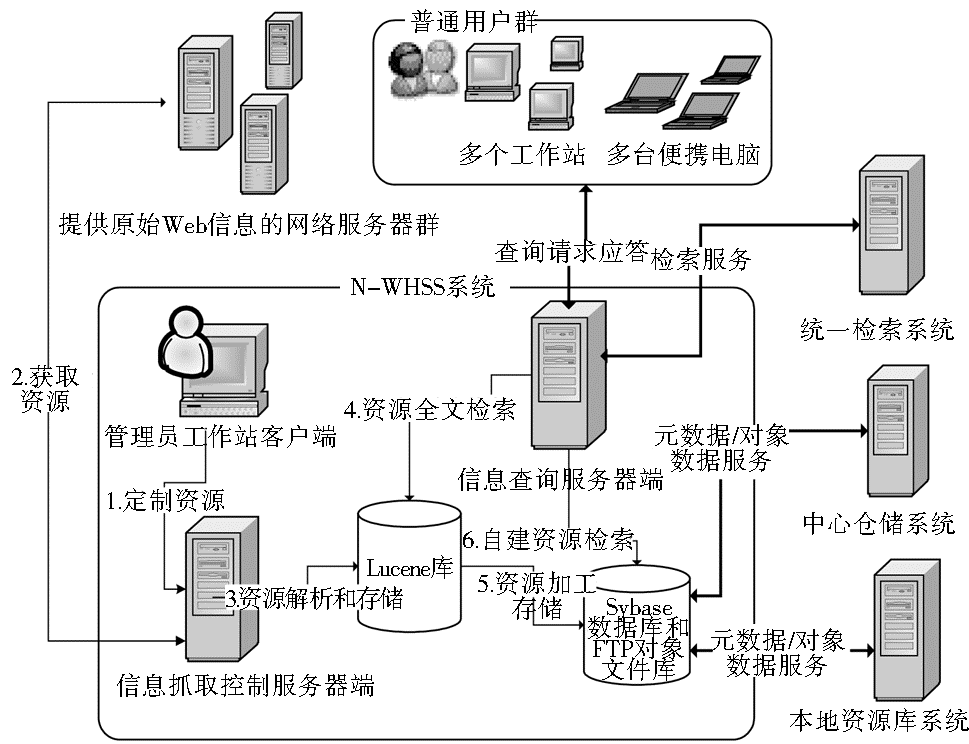 | 图1 N-WHSS系统总体框架设计部署图 |
N-WHSS系统主要实现4方面的功能:
(1)专题学术网络信息的监控和获取
管理员用户通过管理员工作站提交资源定制信息给信息抓取控制服务器,由信息过滤模块,根据主题关键字和种子网站将网络上的信息进行过滤,然后通过信息抓取控制模块根据一定的搜索策略将信息采集下来存储到本地Lucene库。对于主题相关URL的过滤策略和抓取过程的集中配置,抓取的时间、空间效率是重要的影响因素。
(2)专题资源的加工和分类存储
管理员用户通过专题资源信息加工模块对有收藏价值的专题资源进行加工标引、审核发布,发布后的元数据写入Sybase数据库,对象数据上传到FTP文件服务器,作为本地专题资源的一种永久保存。对抓取网页资源元数据的信息解析提取和存储以及如何与专题资源信息加工模块进行数据交互是功能实现的重要保证。
(3)计算机通信行业专题网页资源的中英文检索
普通用户通过发送查询请求,查询服务模块调用基于词典的中文分词模块对用户提交的Query进行解析,封装成符合Lucene API[ 8]参数要求的检索式查询本地Lucene库,返回用户需要的网页记录集合。在为采集的网页信息建立索引存储的过程中以及用户发送检索请求时,都会自动调用中文分词模块,中文分词模块根据嵌入其中的计算机通信行业专业词典进行分词和匹配,保证了返回结果的准确性和专业性。
(4)作为本地专题网页资源的提供者与数字图书馆其他子系统集成
该功能主要通过专题资源信息加工模块和系统服务接口模块来实现。前者为中心仓储系统和本地资源库系统提供专题网页资源元数据和对象数据,后者通过Webservice接口,为统一检索系统提供Server端检索服务。该功能体现了系统的集成性和实用化。
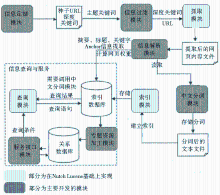
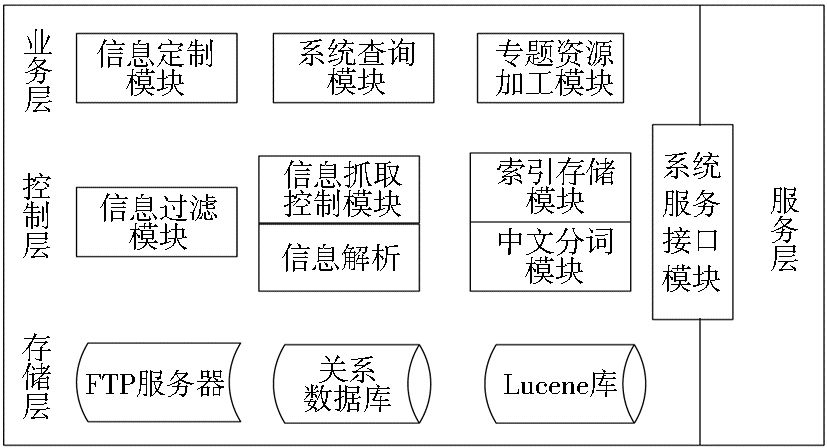
根据N-WHSS系统的设计思想和主要功能目标,将系统的体系架构分为4层:业务逻辑层、控制层、存储层和服务层[ 9],如图2所示:
 | 图2 N-WHSS系统体系架构 |
为方便用户使用的同时有效地进行集中控制,实现业务逻辑与控制功能模块的分离,系统采用B/S模式设计。前台部分展现业务逻辑,以JSP页面编程实现,通过浏览器窗口以UI的方式直接供用户使用;后台主要实现功能模块的控制内核部分,以Java语言编程实现。
(1)业务逻辑层主要包括:信息定制模块、系统查询模块、专题资源加工模块。
(2)控制层主要包括:信息过滤模块、信息解析模块、信息抓取模块、中文分词模块、索引存储模块、系统服务接口模块。
(3)存储层由关系数据库和基于全文索引的文件系统Lucene库实现。
(4)服务层由基于Webservice的系统服务接口模块来实现。
基于对主题搜索引擎技术和开源搜索引擎框架Nutch等关键技术的深入研究,结合数字图书馆系统集成应用的背景,在N-WHSS系统总体框架设计和体系架构的基础上,将N-WHSS系统分为9大主要模块:信息定制模块、信息过滤模块、信息解析模块、信息抓取模块、中文分词模块、索引存储模块、系统查询模块、专题资源加工模块和系统服务接口模块。
N-WHSS系统功能模块总体设计思想如图3所示:
 | 图3 N-WHSS系统功能结构图 |
信息抓取模块、索引存储模块、系统查询模块是引入搜索引擎的基本架构模型,在Nutch和Lucene的抓取器、索引器、查询器的基础上实现;根据数字图书馆系统集成应用的实用化要求,主要设计开发了GUI信息定制模块、信息解析模块、信息过滤模块、基于词典的中文分词模块、专题知识库信息加工标引模块和基于Webservice的系统服务接口模块等6大功能模块,保证采集和获取过程中资源的专题性和系统的可管理性以及易用性。
(1)信息定制模块
该模块主要是对某个学科分类的信息如:种子URL、关键字以及抓取深度的定制。
①种子URL:具有代表性的URL,被用作抓取器爬取的出发点,也叫做根URL。
②关键字:关键字的选择很重要,描述了抓取任务的所属分类的主题方向。
③深度:由于抓取模块采用的是广度优先的策略,抓取深度的选择决定了抓取时间的长度和抓取网页数量的大小。一般根据所选取的种子URL的类型和详细程度以及对网页抓取规模的需求来进行设置[ 10]。
信息定制模块将提交的所有信息保存到Sybase数据库表里,同时在服务器的D:/N-WHSS/nutch目录下生成相应的keyword.txt、url.txt、depth.txt三个文本文件,分别保存关键字信息、URL信息、抓取深度的信息,抓取线程通过文件流机制读取定制信息,开始抓取工作。
(2)信息解析模块
在页面采集完成后,需要从中提取出链接、元数据、正文、标题、摘要等信息,以便进行后续的过滤和其他处理。链接的提取首先要判别页面类型,只有 “text/html”的页面才有必要分析链接。页面的类型可由应答头分析得出,有些WWW站点返回的应答信息格式不完整,此时需通过分析页面URL中的文件扩展名来判别页面类型。遇到带有链接的标记如<a>、<href>、<frame>等,就从标记结构的属性中找出目标URL,并从成对的该标记之间抽取出正文作为该链接的说明文字(扩展元数据)。这两个数据就代表了该链接[ 11]。
(3)信息过滤模块
由于本系统在网络资源采集过程中支持个性化定制,只对感兴趣的目标站点进行采集,该模块主要实现对网页内容的过滤,只获取和处理相关内容的页面。
(4)中文分词模块
数字图书馆专题资源建设的目的之一是为用户提供专题化服务,使得用户在检索专业内容时,可以更全、更准、更有效地找到有用的信息,需要解决的关键问题就是中文分词问题以及专业词汇问题。为了提高中文分词的专业性,本系统中除了用含有20多万个词汇的dict.txt作为通用词典外,还引入了约含有28 994个电子、计算机、通信专业术语词条的专业词典。采用Plugin插件开发的方式实现了分词模块。
(5)专题资源加工模块
该模块的设计目标是为了实现数字图书馆资源的集成。通过N-WHSS系统采集本地的网页资源,一方面直接给普通查询用户提供主题相关的网页资源查询服务,另一方面选择具有学术收藏价值的网页经过专题资源信息加工模块,实现自动化标引审核。由于人工智能的参与,使得加工后的资源更具有学术收藏价值。该模块处理后的网页资源作为数字图书馆众多资源形式中不可或缺的一部分,由专题资源库系统统一管理,与学位论文、期刊、音频、视频等10余种资源一起以数字图书馆集成化资源库的方式提供综合性服务。
(6)服务接口模块
该模块提供数据服务接口和检索服务接口两种服务方式。这两种方式分别体现了数据集成和资源集成的思想。具体应用实现将在3.4节做重点阐述。
选择专题性的种子网站是保证信息有效性的必要条件,但还需要考虑到该种子网站所在页面解析出的新的URL同样是和主题相关的。信息过滤模块采用了关键词过滤机制,提取每个页面解析出的新的URL以及URL对应的链接文字,根据主题相关的关键字构造正则表达式过滤规则,对URL进行过滤[ 12]。
针对通信与信息系统领域——3G/4G移动通信专题,选择如下关键字:3G、4G、移动通信、WCDMA、TD-SCDMA、CDMA2000、WIMAX、LTE、标准、信息产业、通信、运营、3G应用、无线网络进行专题特征表述,同时作为过滤时判断主题相关性的依据。
信息过滤模块的作用是在信息抓取过程被调用。信息抓取模块内核是基于Nutch实现的,因此在信息过滤模块设计中必须要考虑与Nutch的核心配置以及方法调用接口的统一。
下面的XML文档片段来自于Nutch的核心配置文件nutch-default.xml,抓取模块的控制文件Con/crawl-tool.xml。
从XML文件的属性值和对应的描述中可以看出,有三个重要的文件regex-normalize.xml,regex-urlfilter.txt,crawl-urlfilter.txt分别对URL进行规范化和过滤处理的集中配置。
在信息过滤模块设计时,需要在nutch-default.xml文件中添加urlFilter Keyword属性字段。因为nutch-default.xml是个全局配置文档,具有很多重要信息,为了配置的安全性,并不直接在nutch-default.xml中设置具体的关键字值,而是指定在crawl-urlfilter.txt中进行设置。
RegexURLNormalizer.java继承URLNormalizer.java,实现对配置文档和资源文件的加载和读取;RegexURLFilter.java继承RegexURLFilterBase.java;结合过滤模块的设计需求,编写了keywordParserGetPageUrls.java,该类继承RegexURLFilter.java,最终实现关键字的过滤功能。
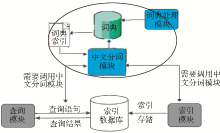
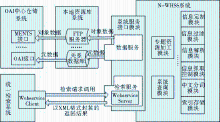
中文分词模块在系统中与信息查询模块、信息索引模块密切相关,如图4所示:
 | 图4 中文分词模块功能图 |
(1)对抓取到本地的网页资源进行索引前,信息索引模块会调用中文分词模块进行分词,分词之后的索引字段写入Lucene库。
(2)在用户发出查询请求后,信息查询模块也会调用中文分词模块对用户提交的请求进行解析和切分,然后转化为符合Lucene 检索接口标准的查询字段,在索引库中进行查询比较,返回相应的文档集合。
(3)中文分词模块按照词典中存在的词条对输入进行机械切分和匹配,若在词典中找到某个字符串,则匹配成功,即识别出一个词。记录该词的位置并返回该词的词典索引。
(4)词典管理模块主要实现对词典中词条数目的统计、词条的动态增加和删除功能。
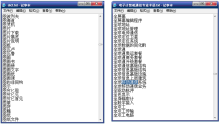
本系统中文分词模块的设计采用基于字符串匹配的分词方法,最重要的组成部分就是词典。中文分词模块通用词典和电子计算机通信专业词典如图5所示:
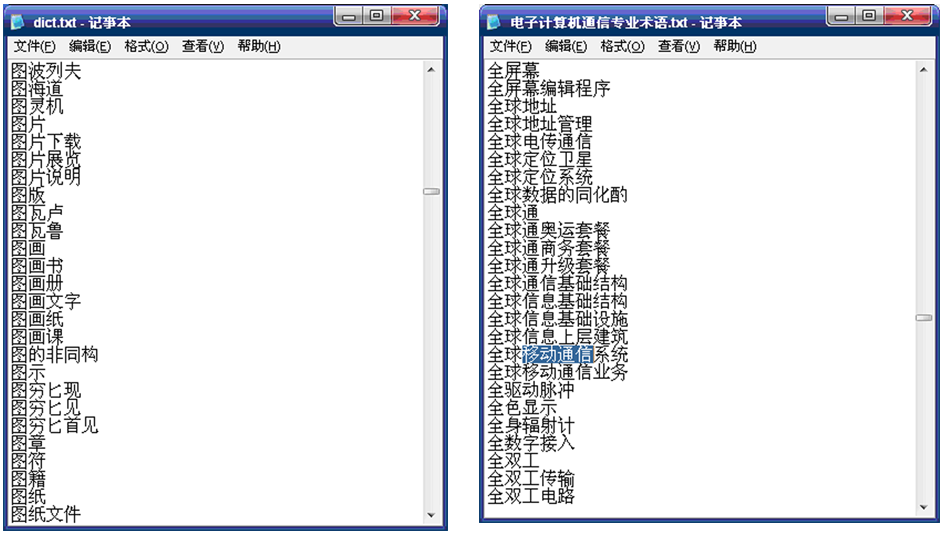 | 图5 中文分词模块通用词典和电子 |
计算机通信专业词典
从性能方面,本系统所采用的分词器是一款用Java编写的基于词典的中文分词器,可与Lucene一起使用来构建搜索引擎系统。目前,该中文分词器的最新版本是1.1.7,采用分词标准,能应用在百万级以上的大型搜索引擎系统中。从实现方式上,经过对Nutch插件机制和Nutch分词机制的研究分析,为了提高系统的灵活性,N-WHSS系统在引入基于中文词典分词器的基础上实现了独立的中文分词插件NWHSSAnalyzer,代替Nutch默认的NutchDocumentAnalyzer按字分词方式。当某个插件需要被加载时,Nutch会加载所有插件的相关接口到缓存,此后每个插件需要实例的时候,根据相关接口和相关接口实现实例在缓存内的记录,实现一个实例并返回。
(1)当第一次需要得到 NutchAnalyzer的一个子类的实例时,下面代码用来获得所有的实例(AnalyzerFactory.java中调用):
AnalyzerFactory factory = (AnalyzerFactory)conf.getObject(AnalyzerFactory.class.getName());
(2)如果为空,则试图从插件仓库中得到该插件的扩展点:
ExtensionPoint point = PluginRepository.get(conf).getExtensionPoint(NutchAnalyzer.X_POINT_ID);
在 PluginRepository.get(conf),返回插件仓库,如果仓库为空,会初始化所有插件:其中 NutchAnalyzer类是Nutch中扩展分析文本的扩展点,所有用于解析文本的插件都要实现这个扩展点。
(3)获得所有NutchAnalyzer的子类描述。
Extension[] extensions = point.getExtensions();
(4)循环获得每个插件的两个参数,fieldName和rawFieldNames,生成每个Filter插件实例。 至此,所有实现NutchAnalyzer的子类实例均被加载。
下面是以插件方式封装后的NWHSSAnalyzer中文分词插件的plugin.xml文档片段注释:
id="analysis-zh" name="NWHSSAnalyzer Plug-in" version="1.0.0" provider-name="bupt.dlib.czr"> name="NWHSSAnalyzer" point="org.apache.nutch.analysis.zh. NWHSSAnalyzer "> class="org.apache.nutch.analysis.NutchAnalyzer"> 用Luke索引查看工具查看Lucene索引结果,中文分词前后索引结果的对照情况如图6所示: 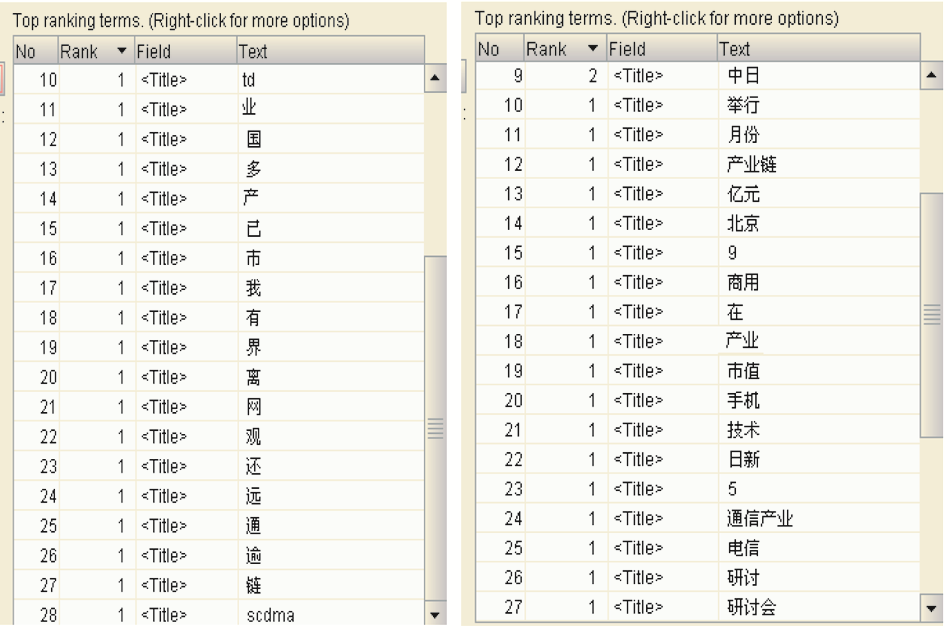
图6 中文分词前后索引结果对照图
其中,左边为分词前的存储结构,右边是经过中文分词模块处理后的索引存储结构。可以看到分词切分效果符合汉语语义,对专业性词汇切分效果也较好。
聚类形式大体上可归纳为三种[ 13]:目录结构、层次聚类结构和树状及网状结构。目录结构即将聚类类目简单罗列;层次聚类采用“自下而上”的方式将聚类结果再进行聚类,直到满足“类内最大相似,类间最大差异”的聚类目的;树状和网状结构是将聚类结果进行一系列的控制和优化处理,将类目间的关系揭示出来,通过类目列表的形式来展示搜索结果。
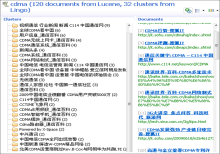
本文采用的 Carrot2[ 14]是一个开源项目,用于解决搜索结果层次化聚类。它能够自动把搜索结果组织成一些专题分类[ 15]。取样实验的聚类结果如图7所示:
 | 图7 检索结果层次化聚类图 |
聚类的关键词是cdma,聚类的文档数是120个,文档类型是Lucene索引文档,采用的聚类算法是Lingo聚类算法,形成32个聚类结果。实验表明该聚类能够较好地依据网页所包含的相应关键词作为类目名称,类目名称可以反映此类目下所包含资源的主题,并体现了类目间的逻辑关系。
检索结果的XML格式如下所示:
-
+
通信关键字:CDMA-C114中国通信网
-
-
通讯世界-百科-CDMA多址技术
-
-
通讯世界-百科-CDMA网络制式
-
-
其中,searchresult标签表示返回的所有结果集;query标签表示输入的检索词;document标签表示返回的每一条记录信息;id号是记录的唯一标识;title字段描述记录的标题信息;url字段描述记录的URL地址来源;field字段表明文档的类型;key=“lucene.doc”表明是对基于Lucene库索引的检索结果的聚类。
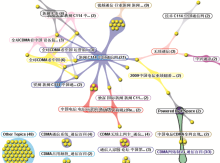
可视化技术在聚类结果展示方面发挥了巨大的作用,消除了传统列表形式不够“易用”的缺陷,使用户能够更方便地理解和使用聚类结果,形象地展示聚类结果,如图8所示。一块区域代表一个类目,区域中样本点的多少代表类目下结果的多少,面积愈大表明结果愈多,反之愈少。类目的远近代表类目间关系的紧密程度,愈近则表示类目间关系越密切,进而形成聚类组。
 | 图8 可视化聚类结果 |
依据网页所包含的相应关键词作为类目名称,体现类目间的逻辑关系,在原有搜索结果基础上再次聚类以满足用户的个性化需求,并使类目之间建立一定的逻辑关系,类目名称能够反映此类目下所含资源的主题。通过聚类, 达到减轻用户负担、快速定位所需搜索结果的目的。
系统服务接口模块提供数据服务接口和检索服务接口两种服务方式。这两种方式分别体现了数据的集成和资源的集成思想。这里主要分析数据服务和检索服务接口的设计思想和功能模块之间的关系。
(1)数据服务接口:主要提供数据层的服务,包括对象数据和元数据。服务对象主要是本地资源库系统和OAI中心仓储系统。
(2)检索服务接口:主要提供资源层的服务,资源类型是网页资源,服务对象是统一检索系统,如图9所示:
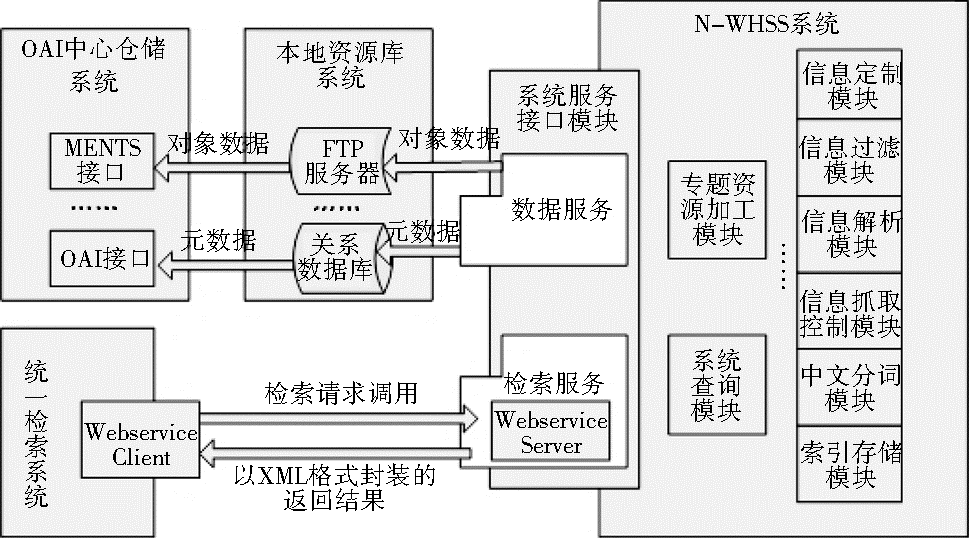 | 图9 系统服务接口模块集成应用设计图 |
本地资源库系统从面向最终用户服务的层面统一管理各种电子资源,包括网页资源、学位论文、期刊论文、音频、多媒体资源等,结合用户需求提供不同权限的个性化服务。网络资源是其中不可或缺的重要资源类型,N-WHSS系统主要作为网页资源的提供者为本地资源库系统提供数据源,既包括元数据信息,也包括对象数据。
OAI中心仓储系统从面向机构间大批量数据交互的层面作为数字图书馆保存和管理数字资源的中心,统一管理和存储数字资源。N-WHSS系统可以为仓储系统提供网页资源的元数据和对象数据。经过本地资源库系统,由该系统汇总各种类型的资源,按照元数据模板和对象数据格式进行加工标引,审核后统一发布。
统一检索系统是一个跨库检索平台,屏蔽不同的检索资源为用户提供一个统一的检索界面和检索结果。统一检索子系统拥有多个商业资源和本地资源,N-WHSS系统可以作为一种本地资源为统一检索系统集成。
根据Webservice服务创建、发布、调用的规范,在本地建立一个支持检索服务的Web Service 服务端,只需要从客户端接收相应的参数,包括:资源类型(Resource_name=website)、检索类型(Meta_name)、检索表达式(QueryString)这三个参数,然后触发本地的一次检索,把检索结果集按照客户端的要求封装成XML格式的数据,返回给客户端,这样就完成了一次Web Service服务的完整调用。
系统服务接口具有良好的扩展性,只要符合Webservice标准和参数调用规范的客户端都可以调用该服务进行本地专题网络资源的检索,极大地提高了系统之间交换的灵活性和资源的共享性。
通过对主题搜索引擎技术原理和应用的研究,对目前具有代表性的开源网络抓取软件进行了比较分析,最终选择在Nutch基础之上进行多种扩展和改进。在引入搜索引擎基本架构模型,即抓取器、索引器、查询器的基础上,根据数字图书馆系统集成应用的实用化要求,设计开发了信息过滤模块、基于计算机通信领域专业词典的中文分词模块、GUI信息定制模块、词典和关键词管理模块等。采用正则表达式过滤、Lucene全文索引、Plugin插件开发等技术实现,保证采集和获取过程中资源的专题性、系统的可管理性和易用性,并对搜索结果的层次化自动聚类进行了深入研究。此外,设计开发了专题知识库信息加工标引模块和基于Webservice的检索服务模块来为系统的集成应用提供服务接口,实现了数据的集成和资源的集成,为用户提供全面而专业的服务。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|