{kind=link}
{kind=link}
基于PLSA的大众标注资源主题挖掘
[王嵩 , 代逸生, 李保珍]
, 代逸生, 李保珍]
, 代逸生, 李保珍]
|
|


针对大众标注中用户生成标签的随意性以及无规则性所导致的标签混乱问题,引入潜在语义索引分析PLSA算法,得到特定资源主题下的标签集,为网络信息组织及用户获取提供有效的途径。通过抽取Delicious网站中的用户标注信息,证实PLSA方法对于特定资源的主题特征具有比较好的效果。
Due to the random of mass tagging user-generated tags and non-regularity of confusion arising from the label, this paper introduces the Probabilistic Latent Semantic Analysis (PLSA) algorithm for latent semantic indexing analysis,gets the label set of specific resources under the theme and provides an effective approach for the network information organization and the user’s access. By taking the user annotation information through Delicious site,the paper substantiates that the PLSA approach can achieve a good result for the subjects of particular resources.
随着博客、网络相册和网络书签等一系列Web2.0软件的出现,大众标注逐步引起了研究者的关注[ 1]。Web2.0环境下每个用户都能够参与互联网的构建,使每个人可以真正地作为网络社会的主体。对这些网络标签进行分析,不仅为个性化搜索提供数据源,而且能更准确地获取用户行为,加速知识共享、知识学习、知识创造的能力,因此具有重要意义。
然而在用户标注过程中,由于生成的标签存在大众化、个性化,因而会存在不精确性和不一致性,表现为同义、歧义、含义模糊、缺乏结构等弊端[ 2]。这些弊端对于用户行为的获取产生很大障碍。如何有效地将这些标签进行组织,形成有序的、有组织的群体,是研究者面临的一个难题。
为了解决上述问题,研究者开始对标签集所呈现的相关结构进行分析。Sam H.Kome提出一种等级式主题关系的方法应用于大众分类中[ 2]。Paul Heymann则通过网络标签的共现性发现其等级结构[ 3]。Grigory Begelman提出了自动标签聚类的方法来改善自由分类法的检索和浏览[ 4]。此外,Christoph Schmitz等人通过对标签间语义关
系的挖掘,揭示用户群体的小世界现象、兴趣发展趋势、标签词汇间的关联规则等[ 5, 6]。上述研究对大众标签能否有效地组织和访问资源等问题进行了深入的分析,但对于其中所存在的缺失值问题却不能进行较好的处理。本文将概率潜在语义分析(Probabilistic Latent Semantic Analysis,PLSA)算法应用到大众标注环境下,有效地解决了标签矩阵的缺失值及稀疏性等问题,实验结果显示此方法对于解决大众标注的标签混乱问题是非常有效的。
随着网络标注的不断发展,不少学者开始分析网络标签能否有效地组织、访问资源。例如,分析可控词表所生成标签与由专家所指定的关键词二者之间的异同,Lin[ 7]等人对Connotea网站的标签与MeSH(医学标题表)中的术语进行比较,发现二者只有11%的相似度,他们认为这是因为MeSH是用来描述医学主题或内容特性的术语,而Connotea网站的标签则集中体现在用户所感兴趣的方面;Kipp[ 8]则将标签与文章作者给出的关键字及相关的索引词进行比较,结果显示35%左右的标签与作者提供的关键词以及索引词有关,而这些关系却没有在同义词典中给予明确的定义说明。另外,标签有效性方面的研究也成了热门,Brooks[ 9]等人发现标签对于将个人博客的文章进行广义分类是非常有效的。换句话说,用户不太可能只通过标签就获取到指定的个人博客信息。 除了对个人网络日志进行研究外,Sun[ 10]等人集中在对博客网应用标签进行分类,并将基于标签的分类结果与标签和博客的摘要共同作用下的分类结果以及单独网络博客的摘要进行比较,结果显示标签与博客摘要共同作用下分类精确度最高,而相比之下,单独的标签要比单独的博客摘要对于其分类更加有效。除了对标签在博客领域有效性的研究外,Razikin[ 11]等人应用SVM算法对Delicious网站数据进行验证,得出标签对于网络资源的分类是非常有效的,其精确度和召回率分别为90.22%、99.27%。
本文在上述研究的基础上,引入概率潜在语义分析算法,通过挖掘资源标签间的潜在语义关系对标签进行聚类,粗略地形成对应主题下的标签集,以解决上述研究中所存在的缺失值处理不足的问题。
潜在语义分析(Latent Semantic Analysis, LSA)是1988年Deerwest[ 12]等人提出的一种新的信息检索代数模型,它利用统计计算导出概念特征词索引文档并进行信息搜索,而不再是传统的索引词,削减了词和文档之间的模糊度,使得词与词之间、词与文档之间的语义关系更为清楚明确,在一定程度上实现了语义检索,消除了词语间的同一性和多义性所造成的影响[ 13]。潜在语义分析的核心思想是通过对原文档库的关键词——文档向量矩阵进行奇异值分解,取前K个最大的奇异值及其对应的奇异向量构成一个新的矩阵,用此新矩阵来近似表示原文档库的词——文档矩阵。由于新生成的矩阵削减了词和文档之间语义关系的模糊度,消除了关键词间的同一性和一词多义性所产生的影响。虽然潜在语义分析在很多领域都取得了突破性的成果,但也存在很多不足:LSA的核心在于SVD,而矩阵的SVD分解对数据的变化较为敏感, 同时缺乏先验信息的植入等而显得过分机械,缺乏稳固的数学统计基础。
概率潜在语义分析是Hofmann[ 13]于1999年提出的,从概率统计的角度对LSA进行了全新的诠释,它源于LCM的混合矩阵分解,考虑到Word和Document共现形式,概率潜在语义分析是基于多项式分布和条件分布的混合模型所得到的共现的概率。所谓共现是指Word和Document在一个矩阵中,矩阵中的元素代表Word在Document中出现的频数。PLSA模型同样利用最大期望(EM)算法进行参数估计,一定程度上表征了在共同观察数据之下的隐藏变量,而且计算了隐藏和实测变量之间的关系,并有效地解决了数据过拟合所带来的问题。
通过对上述研究方法的分析,本文将PLSA算法应用到相关主题的资源识别中。为了验证该方法的有效性,以Delicious网站为例,从中抽取其特定主题下的资源标签集。
基于概率潜在语义资源主题发现的基本思想如下:针对大众标注型网站用户生成标签的随意性,运用概率潜在语义技术来消除标签的同义性及一词多义现象,同时生成了标签及资源的潜在语义;在此基础上,依据生成的资源和标签解释了实测关系[ 10]的隐藏变量之间的关系,进行相似度计算,并加以聚类分析,从而有效、及时地发现主题漂移,更好地满足舆论监控的要求。具体而言,对PLSA模型进行了相应的改进,将其应用于资源主题确定的问题中,在对资源主题确定时,首先构建“资源-标签”矩阵,并基于改进的PLSA模型及所构建的“资源-标签”矩阵,确定相应资源主题的标签集合。实现过程如图1所示:
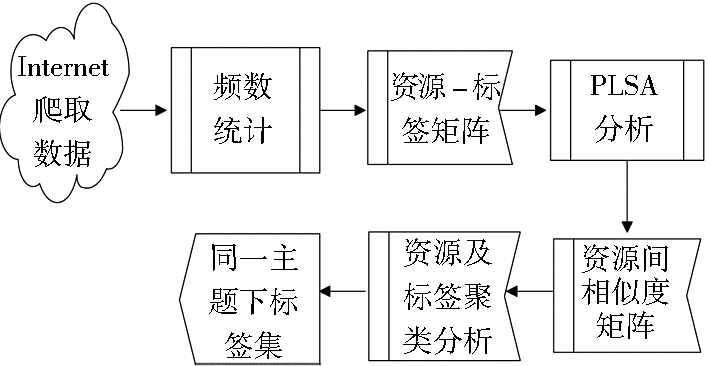 | 图1 潜在主题生成框架 |
概率潜在语义方法提供了一个单一的框架去量化标签之间、资源之间、标签和资源之间、以及标签或资源和“解释”了实测关系[ 13]的隐藏变量之间的关系。给出n个标签模型,m个资源
,PLSA模型与数据的检测一起关联着一套未知的因素变量
。每个观察结果对应于一个资源
模型中标签
的权重
。这个权重可以是标签在资源页面的重要性或与资源有关的标签频率。对于一个给定的资源i和一个给定的标签t,可以导出下面的联合概率(具体的推导过程参考文献[13]):
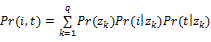
为了解释 
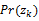


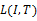
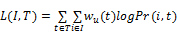
EM算法被用于估计参数的可能的最大值。基于 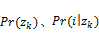
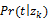
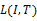
PLSA模型的一个主要优点是用上述估计参数进行概率推理,由此可以导出用户间、页面间、用户和页面间的关系。
(1) “资源-标签”矩阵的构建
借助网络爬虫从大众标注网站中获取原始网页,根据资源与主题的关系将每个资源作为一条记录按照一定的格式保存在Excel中。数据处理过程分为标签清理、词频统计、词语权重计算以及构造“资源-标签”矩阵4个步骤。具体算法如下:
输入: tag //标签集
输出: item //资源链,每个元素包含标签和该标签出现的频数
For i:=0 to length do //length是tag的种类数
If tag.index(i) in item//资源中包含的当前标签
The value of Current word in tag add 1 //value是标签集中对应词的频数
Else add list.index(i) to dic and set value 1 //不含该词,添入标签集,频数设为1
构造“资源-标签”矩阵Xm×n: 统计所有资源中出现的标签,建立空的“标签-资源”矩阵,其中m和n为资源和标签的种类;运用前面标签频数统计的结果依次填充每个资源向量,如果包含该标签,就在相应位置上填充权重值,如果不存在就设为0;最后得到“标签-资源”矩阵。
输入: tag,item//所有标签集;资源链表,元素为资源的词典
输出:x // 标签-资源矩阵
For i=0 to tag.length do
For j=0 to item.length do
If current tag.length contains current tag
x[j][i]=item.tag[i].value //value为当前标签在当前资源中的频数
Else x[j][i]=0
(2) 基于PLSA及“资源-标签”矩阵的资源主题确定
应用PLSA分析,可以得到隐含变量zk在资源ij已知的条件下的条件概率 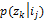
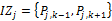
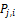
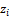
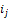
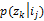
输入:资源-主题变量IZi,隐含因子k;
输出:产生10个潜在因素下的高频标签推荐;
① 利用PLSA算法和资源-标签矩阵X,计算每个资源的资源-隐含变量IZi;
② 在步骤①的结果中任意选择k个对象作为初始的聚类中心;
③ 计算剩余的对象与步骤②生成的聚类中心的距离,并将各对象划分到与其最近的类中;
④ 重复计算各类中的新的聚类中心的质心;
⑤ 返回到步骤②和③进行迭代运算,当k个类中的质心不再发生改变时,算法结束并输出最终聚类结果及10个潜在因素下的高频标签。
本文选择的数据集主要是在Eclipse环境下运行网络爬虫软件得到的典型的大众标注网站Delicious (http://www.delicious.com)上的三元数据集,研究对象主要集中在2007年8月期间的两周的用户访问情况,包括4 578个资源及20 950个标签。在使用该数据集前,对该数据集进行预处理,应用SAS 8.0软件对数据集进行抽取挖掘,将异常标签及乱码删除,从剩余数据集中选择标签数目较多的20个资源作为实验对象,具体的资源地址及标签样本格式如表1所示:
| 表1 20个资源地址及标签统计 |
根据上述实验过程得到了k个标签簇,也就是k个潜在主题下的标签集。经过多次循环发现,当k=5时结果最优,因此将实验数据分配到5个潜在主题下。在此基础上,同时将每个簇中标签频率较高的10个标签进行抽取,如表2所示,得到了潜在主题1的前10个标签及其对应的频率,并将其最高频率作为主题代表词。其他4个主题类似,不再一一列举。
| 表2 主题1标签及其频率 |
根据聚类结果将此5个潜在主题下的资源标签进行汇总,得到如表3所示的结果。
| 表3 相应主题下的10个高频标签 |
通过表3,可以很明显地观察到概率潜在语义分析法能够在一定程度上将具有代表性的标签显示出来,如作为排名第一的标签“Software”、“Photograph”、“Ruby”、“Google”、“Culture”可以在一定程度上表明它所在的潜在主题下的内容。
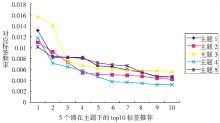
根据表3所描述的5个主题下的前10个标签情况绘制了图2所示的曲线图,可以看到在主题1-主题5下的10个高频标签。通过观察发现,有一些标签如“Design”出现在很多潜在语义下面,这有力地解决了一词多义的问题,在特定的某个标题下只有确定的某一个含义,同时也将具有相同或类似含义的标签根据选取的频率值进行过滤。
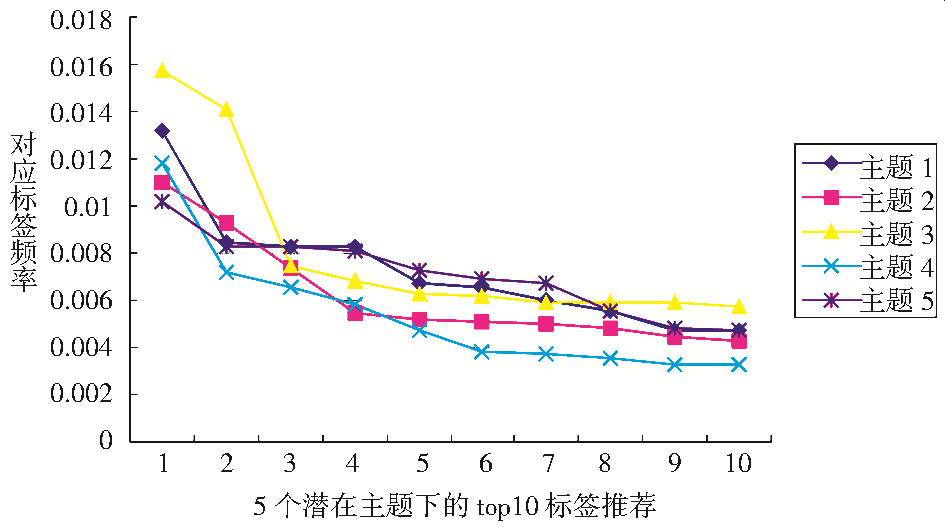 | 图2 10个高频标签的频率情况 |
同时在对应主题下的标签已能基本上将此资源在相应主题下的特征表示出来。比如对于主题1而言,它下面所属的“Software”、“OSX” 、“Apple”、“iPhone”、“Windows”和“Macosx”概况出了此标题主要是针对软件系统方面进行描述,在此将每组中10个标签里概率最大的作为主题元素。通过此模型的形成,用户在对于信息资源进行浏览或者标注时减少了时间,并能不断提升大众标注系统,使其不断优化。
本文将概率潜在语义分析应用到大众标注上,通过分析得出了网络资源(URL)相关主题下的属性特征,用具有表征的标签进行表示。从Delicious网站中爬取到一部分所需的大众标注数据集并将其进行粗略的分类。实验结果显示,将概率潜在语义分析应用到大众标注上已得到了基本的效果,能够较好地克服相关研究中所存在的缺失值及稀疏性等问题。后续工作将在此基础上进一步对资源进行细化,以期达到更精确的效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|