{kind=link}
{kind=link}
Ajax站点数据采集研究综述
[夏天 ]
]
]
|
|


从Ajax链接元素的识别、页面状态标识、页面状态可控性转换、页面状态内容动态获取和状态重复检测5个方面介绍Ajax数据采集所取得的最新研究进展,总结系统的整体处理流程和支撑技术,探讨新的发展趋势,推动Ajax数据采集问题展开更为深入的研究。
This paper introduces the recent advances achieved from five aspects, which include Ajax link elements judgment, page state identification, page state controllable transformation, content extraction and duplicated states detection. The overall processing flow and the relevant supporting technologies are summarized, and the new research trends are discussed. This study will be helpful to promote the further research on Ajax data collection issues.
近年来,以Ajax(Asynchronous JavaScript and XML)[ 1]异步传输为典型特征的Web2.0网站已经成为互联网中的主流表现形式。与传统网站页面整体刷新、通过多页面导航不同,Web2.0网站在单一页面内采用局部刷新技术,仅传递在浏览器和Web服务器之间的少量必要数据[ 2],有效节省了网络带宽;通过充分利用客户端浏览器的功能,降低了服务器端的运算负荷,实现了类似于传统桌面程序的交互方式,改善了Web的用户体验。具有Web2.0特征的典型网络应用有谷歌地图、新浪微博、Yahoo! Mail等。
Web2.0在给用户创造出体验革命的同时,也为数据采集带来了新挑战。
(1)在采用Ajax技术的Web2.0页面(以下简称Ajax页面,并把包含了Ajax页面的站点称之为Ajax站点)中,通过客户端脚本可以在页面背后发起多次HTTP请求,并对网页DOM进行动态更改[ 3],因此无法保证在一次HTTP连接中获取页面在浏览器中所呈现出来的全部数据。
(2)一个Ajax页面可以拥有多个不同的内部状态,Ajax页面内部数据的变化并不一定会导致外部URL的更改,无法继续通过URL作为Ajax页面的唯一标识。
(3)Ajax页面呈现的数据经常与客户端当前状态相关,例如,客户端存储的Cookie不同,用户同一操作所得到的最终结果经常会有所差别[ 4]。可见,面向HTTP无状态连接的现有网络爬虫技术无法正常获取Ajax站点数据,如何解决这类数据的有效采集问题,愈加迫切并具有重要意义。
Ajax数据采集一般通过设计Ajax网络爬虫予以实现,根据适用范围和可扩展性的不同, Ajax网络爬虫可以分为两大类:针对特定站点的专用Ajax网络爬虫和与站点无关的通用Ajax网络爬虫。
专用Ajax网络爬虫面向特定的Ajax站点,通过程序人员观察和分析网页请求信息,寻找站点在数据传递方面的特殊规律,进而获取包含需采集数据的相关HTTP请求,再通过编程获取详细数据。专用Ajax网络爬虫无需对页面进行渲染并动态运行JavaScript脚本,效率较高,成为在面向特定站点的数据采集过程中的常用方式。但是,专用网络爬虫通用性差、规律寻找耗时费力,尤其是Ajax框架的大量引入,使得逆向工程式的专用Ajax采集程序的设计难度越来越大,因此,人们把研究重点放在通用Ajax站点数据采集处理方面。本文将从研究重点、处理流程和支撑技术三个方面对通用Ajax站点数据采集研究所取得的进展进行总结和介绍。
传统Web站点的数据采集可以看成是对特定转换图的遍历过程,转换图的节点由Web页面构成,导致页面转换的边则由超链接构成。对Ajax站点来说,浏览器客户端与服务器可以仅交换少量必要数据,并动态更改页面内容,因此,转换过程不仅可以在页面之间进行,也可以在Ajax页面内部由Ajax事件触发进行。针对Ajax页面状态的转换,瑞士苏黎世联邦理工学院的Frey[ 5]和Matter[ 6]先后进行了总结归纳,如图1所示:
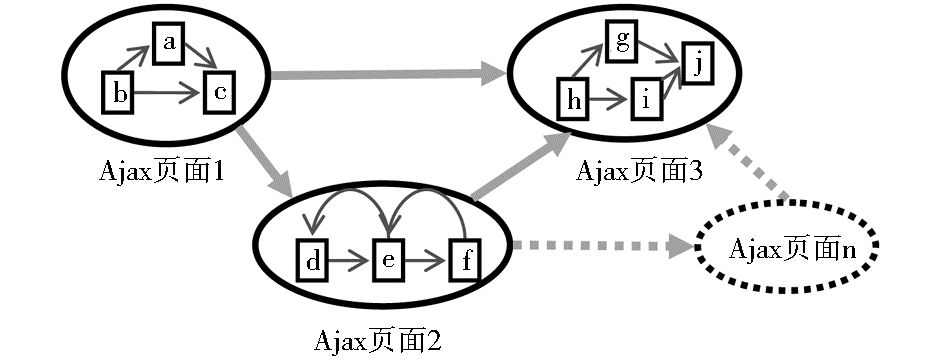 | 图1 Ajax站点页面状态转换图 |
在图1中,带箭头的粗线表示超链接,方框表示Ajax页面的某一特定状态,引起内部状态转换的Ajax事件信息则由带箭头的细线表示。由超链接导致的页面跳转问题在传统数据采集中已经得到了较好的处理,因此,Ajax站点数据采集的研究重点集中在Ajax页面处理方面,包括:Ajax链接元素的识别、Ajax页面状态的标识、程序可控性转换、内容动态获取和重复检测。
(1)Ajax链接元素的识别
在Ajax站点中,超链接并非导致页面内容变化的唯一元素,理想情况下,应能识别所有的相关元素与关联事件。为方便处理,现有研究仅对给定的候选元素集合(如A、Div、Span)和事件集合(如Click、Doubleclick、Mouseover)进行简单识别,以发现符合要求的元素[ 6, 7]。其中,荷兰Delft理工大学软件工程研究中心的Mesbah等人把导致Ajax页面状态转换的元素定义为可点击元素(Clickable Element)[ 7],瑞士苏黎世联邦理工学院的Matter则把由元素事件导致的状态转移称为Ajax链接[ 6]。事实上,除了点击事件外,鼠标移动、页面加载等事件同样会导致状态变化,因此,把与状态变化有关、附加了特定事件的元素称为Ajax链接元素更为合适。
由于Ajax链接元素与附加在其上的事件密不可分,文献[8]和[9]从Ajax事件探测的角度寻求页面状态的变化,本质上也可归入Ajax链接元素识别问题。
(2)Ajax页面状态的标识
单个Ajax页面可以拥有多个不同状态,这些页面状态取代传统的Web页面,成为Ajax数据采集的基本处理单元。页面状态标识用于实现状态的引用和定位,与之相关的研究又可分为两类:
①对相邻状态之间的转换过程进行描述,间接实现页面状态的标识,如Duda等采用的事件源元素、事件类型、目标元素和事件动作四要素状态转换表示法[ 9],夏冰等采用的事件和事件所在元素的XPath二元组表示法[ 10];
②直接设计特定标识用于表示Ajax页面状态,如Xia采用六元组(页面状态初始URL,状态锚文本,XPath列表,状态对应的DOM树,状态哈希值,处理标志)表示每一个页面状态,其中XPath列表存储了从页面初始状态到当前状态所经历的每一个元素所对应的XPath表达式[ 11],这一表示方式默认只处理元素的点击事件,要支持导致状态改变的其他事件,还需要进一步增加描述信息。
一般而言,状态标识会涉及状态所隶属的Ajax页面初始URL、父状态、进入该状态的事件源、事件等因素。页面状态的标识需要保证状态的可达性、可重现性、可理解性,并尽量简单。
(3)Ajax页面状态的程序可控性转换
Shah指出Ajax驱动的Web2.0站点爬取必须解决DOM事件的自动处理和分发问题[ 12],即当Ajax页面位于某一特定状态时,能够通过程序而非人工方式,转换到新的状态。状态转换依赖于JavaScript脚本在客户端的异步执行,因此,解决脚本的正常执行与解析是实现可控性状态转换的技术前提。
罗兵以基于协议的页面获取方式,抓取Ajax页面包含的JavaScript代码文件,并直接设计实现脚本解释器,模拟浏览器行为对脚本代码进行顺序执行,以实现页面状态的控制转换[ 13],肖卓磊在后来研究中也采用了相同的处理方式[ 14];曾伟辉、李淼基于切片算法构建程序层次模型,解决JavaScript脚本的有序执行问题[ 15]; Frey[ 5]和Matter[ 6]则对开源的JavaScript解释器Rhino[ 16]进行改进,用于实现脚本执行和状态转换。完整重现脚本解释器耗时费力,即使已经维护多年的Rhino项目,依然存在许多脚本代码无法正常执行,因此,更多学者尝试利用嵌入式浏览器组件实现Ajax页面的渲染呈现和脚本执行,达到状态自动转换的目的。
在转换控制方面,较简单的方法是采用事件过滤机制,对过滤后的事件逐一触发。为提高效率, Duda等[ 9]和Xia[ 11]分别提出了支持用户自定义规则,引入接收规则和拒绝规则,使状态转换只能在符合条件的有限集合中进行;Mesbah等使用全自动扫描、HTML元素注解和面向领域的手工配置三种不同方式控制状态转换[ 7];Matter则提出启发式爬行策略,力图避免从不同路径转入相同页面状态[ 6]。
(4)Ajax页面状态的内容动态获取
Ajax页面所呈现的数据依赖于当前的状态,动态获取有效页面状态的内容是Ajax站点数据采集的直接目的。Frey[ 5]和Matter[ 6]对Cobra工具集[ 17]进行扩展,实现了HTML代码的动态加载和解析,进而通过内部形成的DOM结构树获取状态所包含的数据内容。与状态转换问题相似,为充分利用已有技术,主流的状态内容获取方式利用嵌入浏览器作为Ajax运行容器,通过浏览器提供的外部接口与页面DOM树交互,并获取其完整数据内容[ 7, 8, 11, 18]。
(5)Ajax页面状态的重复检测
状态重复检测可以有效减少冗余数据,消除重复状态的二次采集,提高效率。重复检测可以通过对比DOM树的内容和结构的变化实现,Duda等以计算页面状态内容的哈希值是否相同作为简单的判重依据[ 9];基于树编辑距离算法[ 19]的重复检测方式应用更为普遍,如夏冰等把该算法应用于Ajax页面的结构相似性判定,进而归约出引向有效页面的页面元素的XPath特征,在效果上等同于状态的重复检测[ 10],Xia则把节点权重纳入计算过程,以改进树编辑距离算法的应用效果[ 20];另外,编辑距离及其改进算法[ 21]、基于Path Shingles[ 22]的方法等也可用于页面状态的重复检测过程[ 11]。
Ajax站点的数据采集还会涉及并行采集[ 6]、页面状态重要性评估[ 5]、结果表示与聚集[ 9]等许多问题,但它们大都归于性能改进和系统优化方面,本文不再细述。
在处理流程研究方面,罗兵设计的Ajax网络爬虫由网页抓取、网页分析、JS解析、DOM支持和页面生成5部分组成[ 13];Mesbah以伪代码方式给出了Ajax数据采集的流程描述,包括初始化嵌入式浏览器、进入指定状态、获取候选可点击元素、触发事件、获取DOM内容、更新页面状态等步骤[ 7];文献[11]进一步引入了保存状态标识和内容的状态仓库概念,在流程中增加了初始状态注入和状态检测与存储处理;文献[10]则明确给出了事件列表需要循环触发的处理步骤。
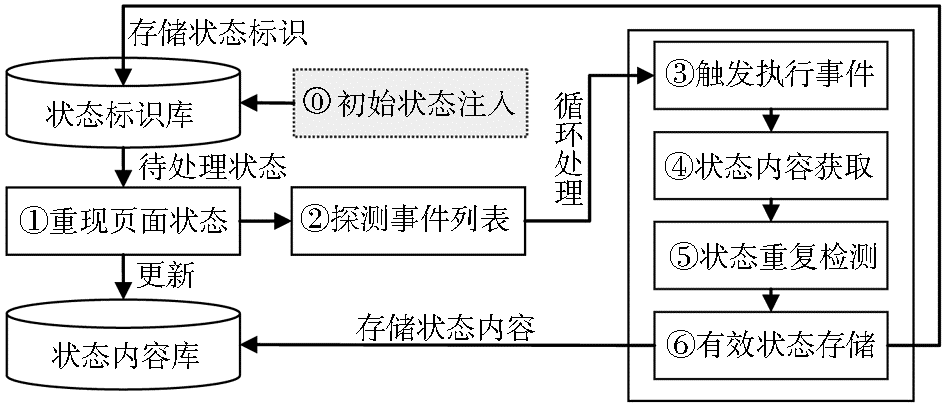 | 图2 Ajax站点数据采集处理流程 |
图2所示的Ajax站点数据采集处理流程涵盖了当前研究所提到的主要步骤,在该流程中,状态标识库用于存储Ajax页面的状态标识,状态内容库则用于存储最终获取的Ajax数据,它们的功能分别等同于传统网络爬虫系统中的URL链接库和网页内容库,合为一起则统称为状态仓库[ 11]。
Ajax站点的采集入口通过初始状态注入加入到状态标识库,形成最初的待处理页面状态集合(步骤⓪);对于每一条待处理页面状态,在Ajax运行容器中重现该状态,探测Ajax链接元素和可能导致状态转换的事件列表(步骤①、②);对于每一个事件,通过触发执行转移到新页面状态,并获取其内容,再经重复检测步骤决定新状态是否有效(步骤③-⑥);对于有效的页面新状态则存储其标识到状态标识库,同时存储其内容到状态内容库,页面状态内容也可在第①步重现页面状态的时候更新到状态内容库中,具体方式在不同研究中有不同实现。
上述流程是一个不断循环的过程,终止判断条件已有多种不同策略[ 9, 10, 11]:当前页面状态相对于起始状态的深度大于指定数值时,不再继续处理其子状态;有效页面状态总数量达到指定数值;处理时间达到截止时间点;用户指定的其他终止条件。
页面状态重现、事件触发执行和状态内容动态获取都依赖于对页面HTML代码的渲染呈现和JavaScript脚本的解析执行,这些功能可统一归入Ajax运行容器的作用范围,主流方式是以某个HTML渲染器作为Ajax运行容器,这使得HTML渲染器成为Ajax数据采集必备的支撑技术。然而,现有的HTML渲染器功能各异,分散于互联网上,缺少完整资料和对比介绍,因此,有必要对其作进一步总结整理。整体看来,应用较为广泛的网页渲染器可分为三类:基于Mozilla Gecko浏览器内核的渲染器、基于微软IE(Internet Explorer)浏览器内核的渲染器和开放代码实现的渲染器。
(1)基于Mozilla Gecko内核的HTML渲染器
该类渲染器通过对Mozilla组织开发的Gecko内核进行封装,提供HTML渲染访问API。Gecko内核具有跨平台、标准化、开放性等特点,因而得到了广泛应用[ 4, 7]。较有代表性的项目有WebRenderer[ 23]、Webclient[ 24]、JRex[ 25]。
其中,WebRenderer是由JadeLiquid发布的一款商业程序,提供了对HTML渲染、访问内部DOM树、执行脚本等功能的完整支持,使用较为方便。Webclient由Mozilla组织开发,致力于提供一款具有通用Web浏览功能的浏览器中立的Java应用编程接口,其功能包括HTML内容渲染、导航、进度通知等。JRex则利用JNI技术对Gecko引擎进行封装,并提供Java类库以供应用程序调用。与WebRenderer不同,Webclient和JRex都属于开源项目,用户可以免费使用,但易用性方面略有欠缺。
(2)基于IE内核的HTML渲染器
该类渲染器底层使用微软公司的IE内核,通过代码封装提供HTML渲染服务,其典型代表有JExplorer[ 26]、Watij[ 27]、Watir[ 28]。
JExplorer提供了一组便捷的Java应用程序接口,把IE与Java程序无缝集成到一起,用户无需深入掌握组件对象模型技术,就可以通过代码访问渲染后的网页DOM对象。Watij则是为实现Web应用程序自动测试而提供的一组Java编程接口,底层采用了JExplorer。Watij具有丰富的HTML访问接口,使得它在Ajax数据采集中也得到了广泛应用[ 7, 11]。JExplorer需要付费使用,Watij内核虽然基于JExplorer,但已经过特殊授权,可免费使用。Watir是比Watij更早出现的Web自动测试框架,但其面向的语言为Ruby。
(3)开放代码实现的HTML渲染器
基于Gecko或IE内核的渲染器虽然能够较好地实现页面渲染和脚本执行等功能,但依赖于特定的软件环境,增加新功能或扩展已有功能比较困难,对脚本事件的拦截和调试不便。因此,部分研究人员针对Ajax站点的数据采集问题,采用了开放代码实现的HTML渲染器[ 5, 6, 9]。该类渲染器主要以Java语言设计实现,以充分利用Java语言的跨平台、易复用等优点,典型代表有Cobra[ 17]、HtmlUnit[ 29]、Flying Saucer XHTML Renderer[ 30]。
Cobra是一个纯Java实现的HTML渲染器和DOM解析器,支持HTML4.0,JavaScript以及CSS2等。Cobra中许多功能模块直接使用了已有开源项目,其脚本解析执行基于Rhino[ 16]实现,CSS解析采用了CSS Parser[ 31]。HtmlUnit最初是一个Web应用程序自动测试框架,底层使用了Cobra,但屏蔽了运行时的图形用户接口以提高效率,同时提供了一组丰富的API,便于上层模块调用。Flying Saucer目前仅能对结构良好的XHTML和CSS进行渲染,不支持JavaScript,需要额外增加脚本解析模块才可应用于Ajax数据采集之中。
随着Web标准的不断发展,重新完整实现一个HTML渲染器并非易事,因此,开放代码实现的HTML渲染器还存在不少功能限制,例如,通过Cobra解析腾讯评论页面内容时,仍然无法正常获取Ajax动态内容。具体选择哪种渲染器,可根据Ajax站点的Web标准规范化程度、效率、易用性、可扩展性等因素综合考虑。
在HTML渲染器使用方面,部分文献并没有给出确切版本说明,在此,笔者仅把可以确认并有一定代表性的使用分布情况进行汇总,如表1所示:
| 表1 HTML渲染器使用情况统计 |
根据现有文献资料和应用需求分析,Ajax站点数据采集的进一步研究方向集中在以下4个方面:
(1)Ajax页面状态的标识问题
目前,研究中所采用的XPath、正则表达式或元素的ID属性定位方式并不能作为页面状态的独立完整标识,页面状态标识既要足够简单,又必须包含完备信息,探索一致认可的Ajax页面状态标识及其对应的数据结构十分必要。
(2)Ajax页面状态的重现问题
该问题既包括在Ajax运行容器中重构特定标识所对应的运行状态及其上下文环境信息,也包括如何面向用户呈现所获取的数据结果,例如可以采用分类、聚类技术对相似结果进行聚合处理。
(3)状态膨胀问题
自动采集方式会导致大量无关状态的遍历和快速膨胀,尤其是会存在许多没有表面关联关系的事件,它们所转向的新状态在本质上可归为一种状态,这一问题将会导致采集效率低下,难以大规模实际应用。优化重复状态的检测算法、设计灵活可配置的通用Ajax状态转换规则,是解决该问题的可行途径。
(4)页面状态的事件触发和执行问题
Ajax页面状态的执行大都通过HTML渲染器实现,但现有的HTML渲染器还存在许多不足,例如速度、控制粒度、跨平台、扩展性、交互性等。为进一步改善性能,人们开始尝试浏览器的扩展功能,设计Ajax运行容器插件以实现与浏览器渲染结果的直接交互,并通过Socket进行封装,为其他模块提供中立的渲染服务,其中,MIT设计的Crowbar[ 32]和开源的FireWatir[ 33]可以为研究人员提供参考。
Ajax数据采集可以纳入Deep Web的范畴,所涉及的数据往往更具价值。Ajax数据采集的相关研究集中在Ajax链接元素的识别、页面状态的标识、页面状态的程序可控性转换、页面状态的内容动态获取和状态重复检测5个方面。HTML渲染器是目前Ajax运行容器的主要实现方式,在采集处理中负责页面状态的重现、事件触发执行和状态内容获取,是设计Ajax网络爬虫不可或缺的基础部件。
总体看来,Ajax站点的数据采集问题已经引起国内外研究人员的关注,并取得了一定成果,但还处于起步阶段,较有代表性的研究机构有荷兰Delft理工大学软件工程研究中心和瑞士苏黎世联邦理工学院。随着Web2.0相关技术的进一步普及,Ajax站点数据采集研究必将引起人们的更多关注。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|