{kind=link}
{kind=link}
{kind=link}
基于缩略语转换的手机图书馆发布信息预处理机制初探
[白如星 , 张成昱, 王茜]
, 张成昱, 王茜]
, 张成昱, 王茜]
|
|


为解决小屏幕的手持式数字设备有效显示大量文献信息时的局限性,尝试利用缩略语转换的方式来压缩在手机上展示的文献信息以方便用户使用,并为此设计缩略语转换系统。从系统的运行时间和不同领域文章的压缩效果进行对比实验。
In order to address the limitation of handheld digital devices to display the literature information effectively, this paper designs a system to use the abbreviations to shorten the texts and makes the users read comfortably. Finally,it compares the computation time and compression rate of the articles in different fields.
手机作为一种普遍应用的信息设备为人们泛在地使用信息资源带来极大便利。手机自身在信息显示容量上存在先天不足,因此要求信息的发布者更为有效地对相关发布信息进行符合手机界面特点的预处理,以便为用户提供一个友好方便的信息使用环境。在清华大学移动数字图书馆系统(TWIMS)项目中提出了利用缩略语转换来实现手机发布信息压缩的方法,作为手机图书馆发布信息预处理的一个组成部分。
缩略语[ 1]这种语言现象在日常生活中经常遇到,其不论在文字表达还是在口头表述方面都给人以极大的便利。事实上,这种语言现象不光在中文中常见,在英文中缩略语的使用更加普遍,很多较长的英文单词都会有其自身的缩略语形式。这些固有的语言现象如果合理利用有可能为实现压缩文献信息长度提供一个可行的方案。另外,由于缩略语的形成是在人类语言长期使用下自身演化的结果,因而一方面很多词组的缩略语表达是人们所
熟知的,另外一方面,人们的思维中也逐渐有一些缩略语形成的规律,这对于人们推测缩略语的含义有一定的帮助。本文设计了一个从原文到缩略语压缩文的转换系统。
目前,在国内外缩略语的研究比较热门。缩略语作为对某些词语的缩写,在词语构成和书写上都有一定的变化,在一定程度上意味着新词语的产生;另外,缩略语简写的同时,不可避免地会带来原来词语含义的丢失,因而容易产生歧义。面对各个学科日益增长的缩略语,必然需要对缩略语和其原词组的映射进行系统管理,自动从文献中抽取新的缩略语、原词组对是很多机构研究的热点,另外由于缩略语和原词组混用的现象很多,因而建立两者之间的关联是信息管理等相关研究领域所关注的问题。如文献[2]和[3]针对专业领域内日益增多的缩略语信息而设计了能够自动抽取和更新的缩略语获取系统,主要用于建立类似数据库的查询机制。
Sun等人对中文的缩略语现象进行了研究[ 4],其研究重点是利用模式识别的方式能够根据原词组自动预测其缩略语的表达形式,这一技术在各类信息搜索、关键字提取等方面具有重要用途。朱江涛等人设计实现了基于网络的英文缩略语信息自动抽取方式[ 5],其信息抽取的范围更广,更能全面地获取缩略语的原词组形式,并且能够从英文的缩略语直接找到其中文表达方式,是一种更新的缩略语还原方法。
本文的主要目的是探索缩略语在压缩文字信息的过程中的效果,在选择缩略语和原词组的对应关系上比较保守,考虑到各类方法均存在一定的错误率,因而选择某些确定的缩略词库作为缩略词转换的基础。
在TWIMS项目中,手机图书馆信息提供主要有以下几个特点:
(1)信息类型以题录信息为主,包括题名、作者、摘要等。
(2)信息内容以学术类信息资源为主,包括论文、专著等。
(3)语种包括中文和英文。
(4)检索结果以中英文混合、不同来源信息混合的方式提供给读者。
来自基于Web的数据库的检索结果信息在返回给读者手机时要经过以下处理:
(1)信息提取:按信息发布要求提取检索结果的相关元数据。
(2)缩略语转换:将返回结果中可转换为缩略语的词或者词组进行转换。
(3)格式转换:将转换结果变为WML格式。
(4)信息发布:将转换结果返回给读者手机。
系统建设的基本考虑是能够把人们常用的或者人们容易理解的词语原句转变为该词语的缩略语形式,最理想的方式是能够找到缩略语形成的基本规律,然后由计算机基于一定的算法自动得到。考虑到缩略语形成的复杂性,虽然在相关领域也有人做过缩略语形成规律的研究,并取得了一定的成效[ 5, 6],但其中可能更多要涉及语言分析、语法等一系列问题,过深研究也非本文的重点。因此,笔者考虑建立一个大的原词句和其缩略语的对照库,根据此对照库,用一一对比的方式把在原文中找到的某些词语转换为缩略语表达。
在选择原型系统所针对的目标文献方面,考虑到中文语句结构的复杂性,在组合判断某个有意义的词语方面需要很大的信息库投入。在寻找适合的对照库方面,没有找到好的资源。出于分析的便利性和现有对照库资源的易获取性等多方面考虑,最终选择英文论文文摘作为待处理的原文库。
在缩略语转换机制中,内容丰富和专业的对照库是有效实现功能的关键。从读取速度和信息容量两个主要方面来考虑,面临三种选择:
(1)建设本地缩略语对照数据库
这种方式的优点是读取速度快,方便日后开发更新更好的查询算法,能够进一步提高系统效率。缺点是系统信息不容易得到及时更新;为了完成各类学科的缩略语查询,需要庞大的信息量;即使是在某一专业领域,其专有的缩略语库也会是一个庞大的系统。某一领域的最新论文中出现新生事物、新的专有名词的几率很高,对更新速度和信息库的容量有很大的要求。笔者曾尝试用一个8 000多条记录的专业缩略语库对一篇通信方面的文摘做缩略语转化,结果压缩率为0。
(2)利用网上开放的专业提供缩略语查询的Webservice服务端口
相对于网页分析来说,Webservice方式直接提供需要查询的数据,不需要页面结构分析,从大量的数据中抽取需要的缩略语信息,从而大大节省时间。相对于在本地建立数据库来说,因为Webservice的服务端口与页面信息一致,所以可以保持其缩略语信息与网页信息都是最新的。一般开发Webservice的单位有专门的机构来随时保持系统信息的更新,因而可以尽可能地保证缩略语信息的全面。
(3)利用网页分析的方法
网页分析的方式是利用爬虫工具,向服务网站发起查询请求,对网站返回的结果页面,通过页面分析的方式,抽取需要的查询信息。这种方式的优点是服务站点比较丰富;一般能够成为服务站点的网站本身就是很丰富的缩略语库,并且有专门的机构来添加新的缩略语信息,能够保持信息的更新。缺点是查询速度很慢,除了网络访问的时间外,还有页面分析的时间。需要在整个页面中去除不必要的信息,抽取所需要的信息。
在权衡三种方式的利弊之后,笔者选择第三种方式建设系统的对照库。相对于第一和第二种方式,网页分析方法的资源容易获取,可供选择的信息库相对比较多一些。对于访问速度的问题,因为本系统主要用来探讨缩略语这种方法的可行性,因而速度方面的要求可以略微降低一些。选择“http://www.acronymfinder.com”作为本系统的缩略语转换信息源。
确定系统的基本运行方式和框架之后,进入对每个部分的详细设计和开发阶段。本系统主要分为三大部分:
(1)原文预处理,包括对原文中语义层次分段和原文格式统一化处理。
(2)爬虫设计,包括爬虫程序的实现和运行方式。
(3)转化策略,设计实现匹配效率尽可能高的转化策略。
在文摘原文中,往往一段文章包括多句文字,而每句文字的含义都是独立的,因而在匹配过程中,真正的处理单元是一句话。这里的一句话并不以句号结尾,一个逗号或分号足以造成语义的截断,在逗号或分号前后的单词不会出现组合成为缩略语的情况。
在文章分析中不可避免地会出现一些有特殊功能的标点符号,需要特殊对待。如“(”和“)”,在一个句子中括号中的文字独立成句,出现在括号前后的句子可能是一个语义连贯的句子,因而在实际的处理中需要考虑连接括号外的句子;“it’s”和“can’t”或者单词中的连字符“-”等都需要特殊处理。
原文处理的结果是一整段文章被分割成意思独立的最小单元,其每个单元中所包括的符号只有空格和形如“it’s”的形式。
本系统的爬虫采用HtmlParser和HttpClient来实现。其中,HtmlParser 实现网页分析功能,而HttpClient主要实现网络连接和网页下载。由于网络环境的不同,在连接某些网站时需要特殊的设置,比如Cookies的保存,或者HTTPs连接等。本系统由于是教育网内,所以需要代理服务器的设置,HttpClient作为本次爬虫的网络连接方,在这方面具有专业的优势。事实上,HttpClient作为专业的网络连接库,支持HTTPs、自定义数据、自定义报头、代理认证方法、Cookies和重定向等[ 7],完全可以胜任绝大多数的网络连接。
HtmlParser被认为是高效的网页分析工具,其主要功能有信息抽取和信息转换[ 8],在程序中主要利用其信息抽取的功能。利用HtmlParser分析网页,最主要的工作是设计用户自定义过滤器,从而对网页的特定内容进行过滤,最后以链表的形式返回信息抽取的结果。实验中选用“http://www.acronymfinder.com”网站,在正确返回信息的情况下,查询结果放在id=“ListResults”的“table”中,因而可以构造一个含有属性“id=ListResults”的“table”过滤器来抽取其中的内容。根据该网页的格式所返回的第一条记录,基本是最符合查询目标的,所以固定选取第一条记录作为查询结果。
一个基本的实现缩略语查询的网络爬虫构造至此完成。在单线程程序中,当程序实现页面分析和匹配等操作时,网络基本处于闲置状态,这极大地浪费了网络资源,故在实际工作中考虑使用多线程的方式。考虑到一段文章往往会分成数个短句,而每个短句才是缩略语转化的基本单位,因此可以为每个短句开放一个线程,从而实现程序资源的高效利用[ 9]。
考虑到系统设计的特殊性,对一篇很短的文章的转化就需要大量地访问网络,这对于实际运行来说,势必会由于网络环境的限制,大大地影响系统转化的速度。为了尽可能地减少网络访问量,需要考虑把过去在网络访问中所获取的结果保存下来,当下次遇到重复的查询条目,可以不必再调用网络查询,直接在本地完成。
为此,特别设计了一个本地数据库作为辅助的对照库。本程序利用MySQL 数据库,保存所有访问成功的结果,对于每次的缩略语匹配来说,系统按如下规则运行:在本地数据库中查找,如果没有,则通过网络爬虫来找;对于网络爬虫查找成功的结果,要保存到数据库中,以方便下次的重复词条。
在最初设计的时候,数据库中只保存查询成功的结果,而没有保存查询失败的结果。考虑到现在失败的结果,并不能保证经过一定时间后,会变成新的缩略语词条,如果保存查询失败的结果,就不能及时获取网站中更新的资源。然而,对一篇文章来说,大部分词条是匹配不成功的,真正需要查询成功的词条只是很少一部分,在实际的转换过程中,仍然需要大量地利用爬虫程序上网查询,这样对于程序本身速度的改善并不明显。因此,设计了两个表结构,一个保存成功的信息,另外一个保存失败的信息。两个表的结构相同,如表1所示:
| 表1 成功和失败信息的表结构 |
其中,org表示缩略语的原词组;abbre代表缩略语;type取1或者0,分别代表成功的缩略语和失败的缩略语;savetime表示该记录的入库时间。再建立一个视图结构,包含了所有成功的缩略语记录和最近5天内的失败记录。在实际查询中,可以通过查询该视图,判断某一词组的缩略语是否存在。同时,另一个程序每天把超出5天的失败记录通过爬虫验证是否有更新,并更改保存时间。这样可以在速度和更新度方面保持一定的平衡。
在匹配方式上,寻找英文缩略语词组更类似于中文的分词法。因为在中文中每一个汉字都是独立分割的,但是不同的汉字组合可以表达一定的单词含义。因而在对中文的分割中,人们更加倾向于分割出中文词组。同理,在英文中虽然每个英文单词都有固定的含义,但是作为缩略语转化来说,缩略语的组成很有可能是多个单词的组合。本程序中所用的查找缩略语词组的方式和中文中分词的方法类似,因而可以借鉴其中的算法,如正向最大匹配分词法[ 10]。
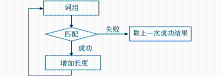
正向最大匹配分词法的基本思想是:从某一个单词开始查询是否有匹配结果,如果有完全匹配结果则保存,并继续增加单词,重新查询;一直到没有查询结果时结束查询,并将最近找到的完全匹配结果实现缩略语转换。这样做的目的,一方面可以利用对照库来分词,而不需要判断单词之间的关系;另一方面,考虑到一些长的词组的开头某几个单词也可以匹配到某个缩略语,如果单纯判断是否匹配,程序可能直接在开头那几个单词处完成匹配,从而使整个长句不能匹配,甚至会破坏语义结构,而最大匹配法则必须找到最大的匹配词组才能进行转换,可以有效避免这种现象发生。本算法流程如图1所示:
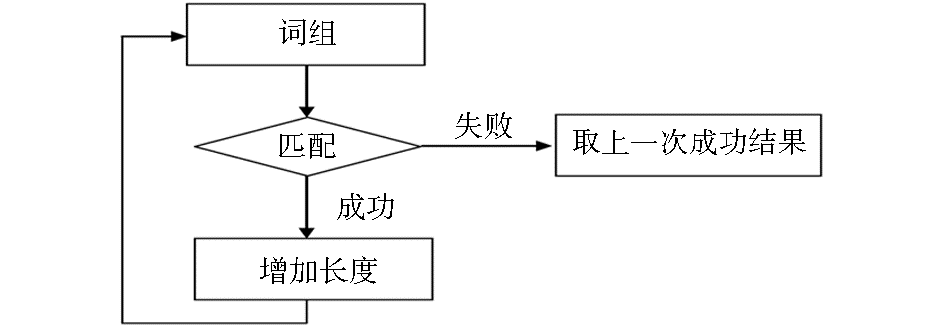 | 图1 最大匹配算法流程图 |
本程序在Windows 2003的环境下构建,其中用到的软件有:Java 1.6.0版本, MySQL 5.0, HtmlParser 1.6和HttpClient 3.1。
为了测试本程序的效果,从IEEE上查找“face detection”,找到其前25篇论文的文摘作为本次测试的原文库,同时从不同的角度考察本设计的效果。对于转换的速度方面,分别设计了单线程并且数据库中只保存缩略存在的词组信息、多线程并且数据库中保存了缩略语存在和不存在的词组信息、多线程系统第二次运行这三种情况。其测试结果如表2所示:
| 表2 系统运行速度对比表 |
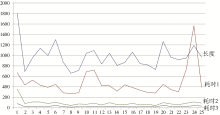
三个测试结果的对比如图2所示:
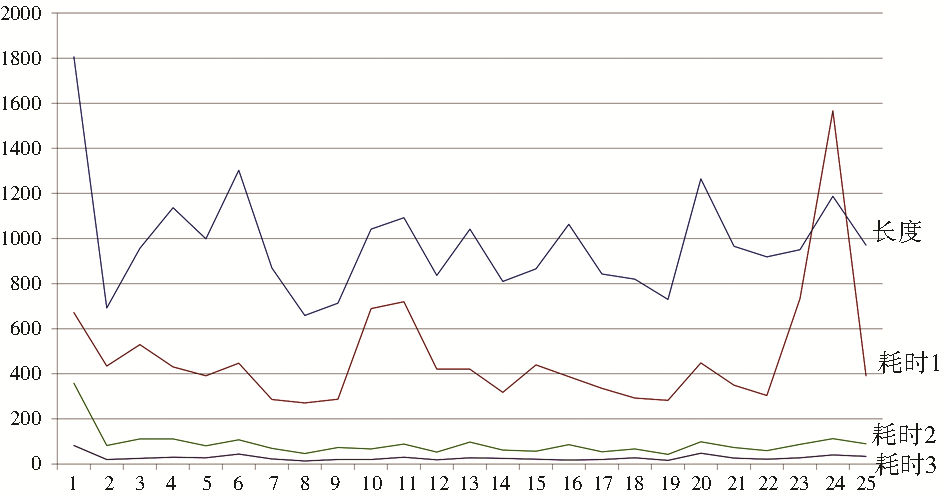 | 图2 系统运行速度对比 |
耗时1是原始系统转化的消耗时间,耗时2是新系统初次运行的转化时间,耗时3是新系统第二次运行的转化时间。从图2可以很明显地看出来,在增加了成功和失败的数据库,并且采用多线程的方式之后,程序的运行速度显著提高,基本的运行时间都低于200s,相比之下,没有采用类似措施的系统运行时间都在300s以上。
为了考查不同文章之间缩略语查询的影响,也就是说前面的文章查询缩略语成功和失败的信息,在新的文摘的转化过程中其影响有多大,故删除数据库中的所有信息,单独对最后一篇文章做了转化。其实验结果为:单独处理运行时间是238s,从上面的数据看到,在已经有了前面24篇文章的转换数据的情况下,最后一篇文章的转换时间为90s,除去系统受到网络环境的影响而对结果有某些不确定的干扰外,这一改进效果是很明显的。
实验还考察了各文章转换前后总长度的变化,以减少的长度比原文总长度作为压缩比,25篇文章的压缩效果如表3所示:
| 表3 “face detection”类论文文摘压缩率 |
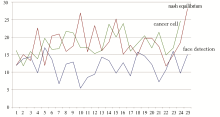
考虑到不同学科的差异性,利用IEEE中的24篇生物医学、25篇经济学应用数学论文文摘进行测试。生物医学方面通过输入“cancer cell”获得,经济学方面则通过“nash equilibrium”这个在博弈论中比较热门的关键词获得。三者的压缩率如图3所示:
 | 图3 三类论文文摘压缩率对比 |
从所得数据可以发现,不同领域的文章其压缩率也各有不同,这74篇文章总的平均压缩率为15.85%。其中,三类论文各自压缩率的统计信息如表4所示:
| 表4 三类论文文摘压缩率统计表 |
从压缩率来看,作为一个简单的转化程序,有15%的平均压缩率,效果还是很明显的。
以下是一篇通过“cancer cell”检索获得的论文摘要原文:
This research assesses image analysis and pattern recognition methods that eliminate the image segmentation step normally required before parameter measurement and object classification for use in cancer cell detection in imagery with cell overlaps and clusters. A region of interest finding method previously developed for cancer cell detection in low resolution 3 colour “Pap” smear imagery containing isolated cells has been retrained and assessed on imagery containing computer generated cell overlaps and clumps in addition to isolated cells. The approach taken involves representation of key characteristics of objects to be recognised (or rejected) in terms of complex receptor fields and a flexible decision logic structure suited to high speed implementation. The ultimate goal of this work is to develop methods that work equally well on problems such as cervical cytology where cells tend to be isolated or in clusters and on problems such as tissue analysis where cells are arranged in complex structures where segmenting individual cells accurately is often not possible.
进过转换后,对该文转换前后逐句进行对比,如表5所示,字体加黑的部分为实现了转换的部分。
| 表5 缩略语转换前后对照表 |
本段摘要原文共长1 079个字符(不包含除空格外的标点符号),经过本系统转换,缩减了257个字符,其压缩率为23.8%。其中,很多常用的单词或词组转换成了其缩略语的形式,如method→METH,region of interest→ROI等。本程序在一定程度上也可以做到对英语单词变形的包容,如methods→METHs,arranged→ARRd,rejected→Red等。但在同时也因为单词形变过多而导致信息偏差,如characteristics→CHAR。另外,也注意到在一些单词的转变上有较大的偏差,如individual→A。从网站的实际查询来看,individual所对应的内容不同、范围不同就有不同的缩略语形式,如在网站中出现的有A,C,B,IND,INDIV等,在具体的选择过程中就需要更多信息的提取,这也是本系统的不足之处。
从以上的测试数据来看,平均的压缩率可以达到15%左右。这个结果对于真正投入实际的应用来说性能上还有一定差距,但效果还是明显的。由于本系统所采用的匹配算法比较简单,在处理英文自身格式的多样性,尤其是英文中有同一个单词的各种形态变化的现象时,势必会造成一定程度的漏判的现象,从而降低了系统的压缩率。如果考虑这方面的改进,压缩率会有进一步的提高。
在经过优化的结构设计后,其运行速度得到极大改善,但即使是分析过的文章,再次转换仍然需要几十秒的时间,这个速度在投入实际的系统运行中很难满足实时需求。为此,考虑两点的改进,一方面改变本地查询依靠数据库的方式,而采用自定义数据结构的方式,如两层哈希表结构算法等[ 10]。另外也考虑用多个处理器并行工作的方式进一步提高运行速度。
本系统的缩略语转换的准确度问题,很可能出现某个词组在不同的应用环境中有不同的缩略方式,单纯依靠第一个查询结果作为其缩略形式,在实际应用中会有语义歧义的现象。因此,一方面要改进查询判断的方式,并且考虑能够按照专业分类来查询;另一方面本系统作为未来手机信息展示的预处理机制,必须要利用其他手段来辅助展示信息的准确性,例如在手机端显示时,每个缩略语词组都会有自身原词组的链接,一旦用户不清楚该缩略语的含义,可以由该缩略语获取其原词组的信息。这样可以保证在缩小展示信息的同时,又完整传达了信息。
总体来说,利用缩略语来压缩文章长度的办法,对于解决小屏幕阅读的问题不失为一种有效的探索。作为一种方法,缩略语转换在解决手机图书馆信息发布容量的问题方面是可行的,值得进一步的研究和探索。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|