
{kind=link}
{kind=link}
{kind=link}
西太平洋地区医学索引设计与实施
[钱庆 , 方安, 代涛, 王军辉, 李亚子]
, 方安, 代涛, 王军辉, 李亚子]
, 方安, 代涛, 王军辉, 李亚子]
|
|


分析西太平洋地区生物医学期刊分布现状,制定生物医学期刊题录信息的采集策略,并采用基于概念的赋词方法为题录信息建立索引,利用空间向量模型设计基于MeSH的生物医学题录数据扩展检索算法。最后将该算法运用到WPRIM系统的设计与开发中,实验证明能够提高系统检索的召回率。
This paper analyzes the current status of the distribution of biomedical journals in Western Pacific Region, develops the strategy of information collection, and indexes the collected information using concept-based method. Based on MeSH,it also designs the extended query algorithm with the space vector model,then puts the algorithm into the design and implementation of the WPRIM. Finally,the experiment results prove that the above key algorithms can improve the recall of system.
西太平洋地区医学索引(Western Pacific Region Index Medicus,WPRIM)收集世界卫生组织(World Health Organization,WHO)西太平洋地区(简称西太区)各成员国[ 1]出版的生物医学领域期刊及灰色文献的题录信息,促进西太区医疗卫生领域相关信息的全球共享,实现世界范围内健康相关信息的传播利用,让人们获得可靠的健康信息。WPRIM的目标与任务主要包括:筛选西太区成员国生物医学期刊,并建立索引;建立生物医学期刊题录数据库,并进行全文链接;通过同行评议,提高WHO西太区生物医学期刊的编辑出版水平;促进西太区国家医学图书馆、医学信息中心以及地区与国家间卫生科学信息网络的形成;加强合作与交流,包括WHO西太区与其他5大区域之间、西太区各国之间、国内各相关机构之间乃至同一团队内部不同专业人员之间的合作[ 2]。
本文分析了西太区生物医学信息分布的状况和建立医学索引的必要性,根据地区的实际情况设计和实施医学索引,阐述了西太区生物医学期刊题录数据采集、题录数据标引以及题录数据检索采取的算法,开发了WPRIM系统,并通过实验证明系统的适用性。
西太区作为世界卫生组织6大地区[ 3]之一,由27个国家/地区组成,各成员国家/地区在政治、经济和文化方面差异较大,在卫生信息方面的交流与合作相对较少,语言的差异阻碍了各成员国之间生物医学信息资源的共享与利用。目前,WHO西太区成员国生物医学期刊的编辑出版水平和期刊质量参差不齐,需要整合具有一定水平
而又能反映各成员国实际情况的期刊,加强各国之间、国内各相关机构之间乃至同一团队内部不同专业人员之间的合作。
目前,西太区医学索引检索平台[ 4]采用的是韩国医学期刊编辑协会(Korean Association of Medical Journal Editors,KAMJE)的KoreaMed系统[ 5],整体功能未能满足WPRIM的需求。
(1)不支持各成员国家/地区分别上传各自的数据,难以做到信息的及时搜集和更新,影响了系统的时效性。
(2)不具备主题词检索和跨语言检索功能,也不提供数据更新信息的自动推送服务和对检索结果的综合分析功能,难以满足西太区各国不同层次用户的需求,影响了系统的易用性。
(3)该系统未整合PubMed和全球卫生图书馆[ 6](Global Health Library, GHL)提供的检索接口。
上述系统自身的缺陷影响了平台的整体功能,限制了西太区各国生物医学信息知识的传播和利用。
从整个WPRIM长远发展的角度考虑,迫切需要进行系统的重新设计,以促进西太区甚至整个WHO内生物医学信息的共享。中国医学科学院医学信息研究所长期从事医学文献资源建设,并拥有自主知识产权的生物医学文献系统SinoMed[ 7],在生物医学信息资源建设与服务方面具有丰富的经验。鉴于已有的基础,WHO西太区委托中国医学科学院医学信息研究所重新设计西太区医学索引,开发WPRIM医学索引系统。
西太区医学索引系统收录来自27个成员国/地区的生物医学期刊,对其内容建立索引,并提供对外服务,满足目标用户对生物医学文献信息的需求,系统建设主要解决以下三个问题:生物医学期刊数据采集、数据索引以及数据检索。
(1)数据采集
在西太区成员国/地区医学索引中以中国、韩国、日本的期刊为主,这三个国家拥有较为完善的国家级生物医学文献检索系统:中国的SinoMed、韩国的KoreaMed[ 5]、日本的J-STAGE[ 8]和NII[ 9]。而老挝、蒙古等国家网络基础薄弱,软件建设上还没有成熟的生物医学文献检索系统。因此在数据采集时采取不同的策略,中国、韩国和日本入选的期刊从已有的数据里采集,利用网络爬虫等技术,对采集的结果按照指定的格式导入到系统中备用。为老挝等国家开发离线的加工工具,通过工具将入选期刊按照指定的格式人工输入,以XML的格式存储,方便系统的后续处理。
(2)基于概念的赋词标引
对WPRIM生物医学期刊题录信息建立索引。通过对文献的分析,选用确切的检索标识(类号、标题词、叙词、关键词、人名、作者所在机构等),用以反映该文献的内容。建立索引的过程即是对题录信息进行标引。标引从原理上分为抽词标引和赋词标引,两种方法和技术都是以自然语言的规律为基础,构建在相应的数学模型上。
WPRIM系统的设计结合基于概率[ 10]和基于概念[ 11]两者的优点,以中文MeSH为依据,避免训练词表的工作,以中文MeSH词表中的概念建立特征词的同义词,提高检索的查全率,并为跨语言检索奠定基础。
建立索引的实质就是建立倒排文件,其设计主要集中在:特征词的提取、特征词权重的赋予以及特征词的组织(索引文件的设置),下面分别阐述。
①fd,t为题录 d 中词条 t 的出现频率;
②fq,t为检索条件q中词条 t 的出现频率;
③ft为包含词条 t的题录总数;
④Ft为题录中词条 t 出现的总次数;
⑤N为题录中文档总数;
⑥n为题录中参加索引的词条总数。
对每个词条来讲,倒排索引包含两个主要组成部分:包含该词条的文档有多少篇;一个指向倒排列表的指针。指针中包含相连的若干节点,每个节点中都含两项:包含该词条的文档的ID;该词条在该文档中出现的次数,即形如:Term,ft,
①Pancreatic cancer has a poor prognosis.
②Improving survival will require diagnosis of early pancreatic cancer which can be defined based on respectability, size or curability.
③Pancreatic cancer progresses from non-invasive precursor lesions to invasive cancer over a variable time period.
对上面三篇文档(由一篇文档生成)进行特征词提取,计算在各文档中出现的频率,生成倒排文档,如表1所示:
| 表1 实例生成的倒排文档 |
表1是对实例文档建立的倒排文件,在建立倒排文件的过程中已将虚词剔除,例如a、of、or等。其中列“文档数ft”表示包含特征词Term文档总数,列“特征词倒排列表”为特征词在各个文档中出现的情况。以特征词cancer为例:列“文档数ft”的值为3,表明有3篇文档包含caner;列“特征词倒排列表”为cancer在各文档中出现的情况,<1,1>表示在第1篇文档中出现1次,<2,1>表示在第2篇文档中出现1次,<3,2>表示在第3篇文档中出现2次。
(3)基于MeSH的WPRIM生物医学题录数据扩展检索
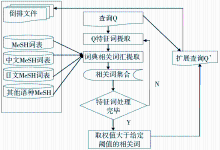
WPRIM系统题录信息的检索采取空间向量模型。该模型是目前比较流行的相似度计算算法,其特点较为清晰,利用TF×IDF作为特征词权重的计算方法。基于MeSH词表查询扩展的过程如图1所示:
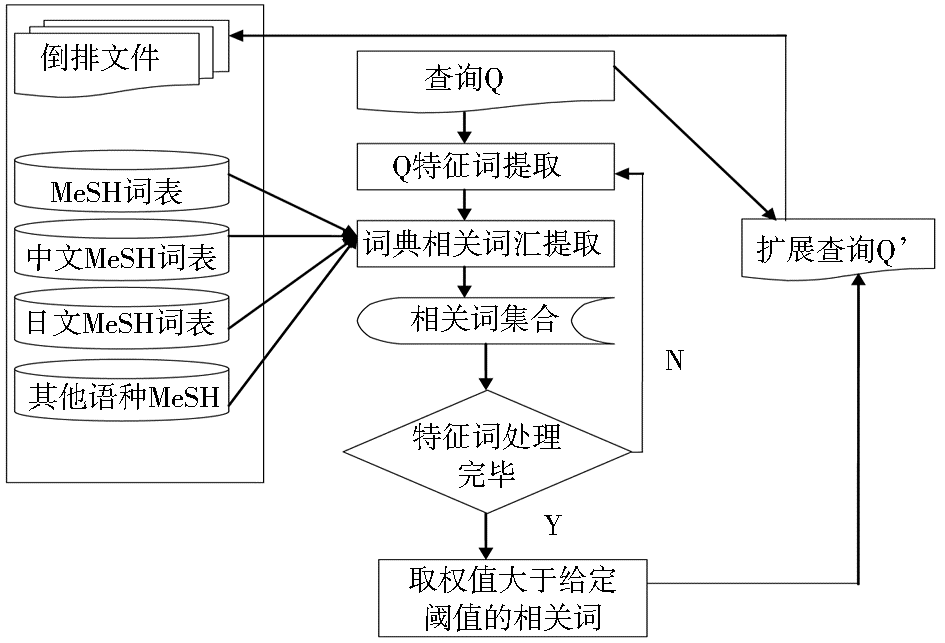 | 图1 基于MeSH词典的扩展查询 |
用户输入查询Q,给定查询Q={q1,q2,…,qi,…,qn},由系统将qi与MeSH词典进行匹配,在MeSH词典寻找qi的同位词和上位词,根据实际需要可能会将qi的下位词作为扩展的对象纳入到Q中,完成整个流程生成查询扩展Q’。Q’={q1,q2,…,qi,…,qn,q(n+1),…,q(n+m)},以Q’作为最终查询,将空间向量模型算法作用于倒排文件,检索与Q’相关的文档。
在实际的查询过程中可以设置关键词权重,在检索表达式中显示指定各个关键词的权重系数,例如不同字段中的词可以选择不同的权重系数来突出某些标引字段的份量。通过不同版本的MeSH词典,实现跨语言检索。
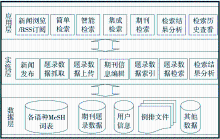
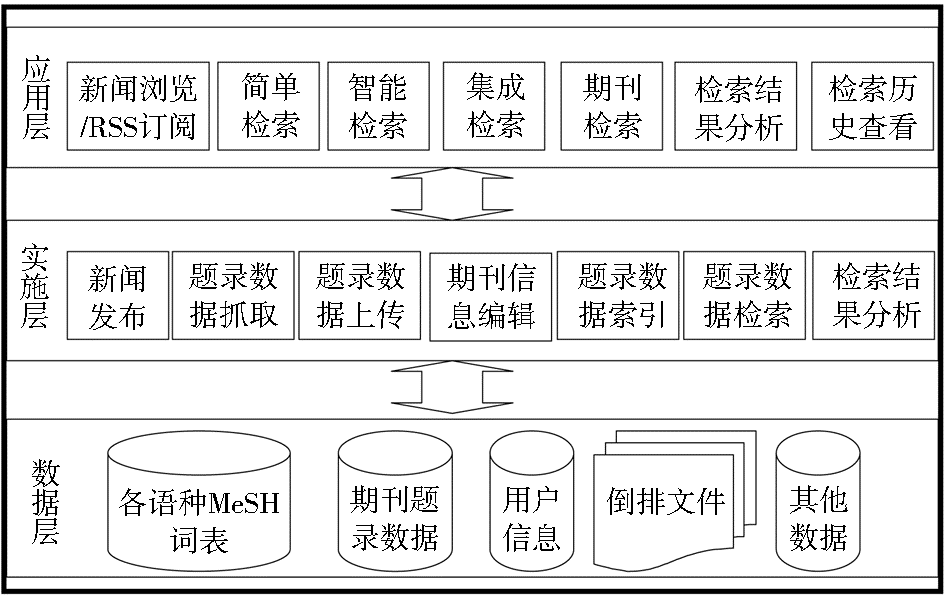
WPRIM采集西太区成员国/地区生物医学期刊题录数据,建立题录数据的索引,为医学科研人员提供文献信息服务,并能够实现跨语言检索。WPRIM系统体系结构如图2所示:
 | 图2 WPRIM系统体系结构图 |
WPRIM系统由三个层次构成,分别是数据层、实施层和应用层。其中,数据层是整个系统的基础;实施层是系统的支撑,提供数据采集、加工,以及系统管理等功能;应用层直接面向用户,满足用户的信息需求。
(1)数据层
词表是实现概念标引和扩展检索的基础,是跨语言检索的依据。数据层包括各语种的MeSH词表,系统通过对检索语句语种的判断,实现多语种检索;期刊题录数据存放从SinoMed、KoreaMed以及J-STAGE等生物医学数据库中抓取的题录信息;用户信息包含用户的基本信息,如系统管理员、注册用户等;对题录信息建立索引形成的倒排文件;其他数据包括检索历史、期刊信息等内容。
(2)实施层
实施层对底层数据进行加工,是数据层和应用层的中间层。其中新闻发布负责发布西太区医学索引建设的情况;题录数据抓取根据SinoMed、KoreaMed以及J-STAGE数据库的特点,通过纵向搜索引擎抓取期刊信息及期刊题录信息,对开放获取的期刊/论文,抓取部分全文,并将数据存入数据层;题录数据上传提供题录信息离线加工,将以指定格式的XML文件上传到题录数据库中;期刊信息编辑对收录的期刊信息进行更新;题录数据索引通过上文分析的算法对题录数据建立索引,形成倒排文件;题录数据检索提供各种检索功能;检索结果分析对检索到的结果进行分析,如可按照作者、机构或期刊等字段对某一主题的文献记录进行排序。
下面给出网络爬虫对题录数据进行采集的算法,采用伪Java语言描述。待抓取内容的更新流程与初始化相似,这里不再详述。
算法名称:期刊题录抓取
输入:期刊网址(期刊列表所在网址)
输出:收录期刊的题录(题录信息的主要内容)
步骤:
①输入待抓取期刊的网址;
②分析该页面的HTML代码,寻找其规律;
③得到指向具体期刊的链接集合LinkCollection
while(LinkCollection不为空);
④URL url = new URL(LinkCollection的元素),
getCookie(url),setCookie(url),//有些网站的访问需要设置Cookie
URLConnection urlConn = url.openConnection();
⑤分析urlConn得到的指向期刊卷的链接link的HTML代码,提取该期刊卷的详细信息journal_volume;
⑥在数据库中查重,将journal_volume存储到题录库中;
⑦进入卷页面,得到该卷中所有的期信息;
⑧根据期信息,得到文章标题等,并抽取题录信息;
⑨将link移出LinkCollection集合;
⑩ 如果LinkCollection不为空则转向④,如果为空则跳出循环。
(3)应用层
应用层为用户提供信息浏览与检索。通过新闻浏览/RSS订阅,用户可以查看西太区医学索引系统设计的最新情况,系统可以公布数据加工的情况,并提供新闻聚合功能;简单检索针对用户输入的关键词进行查找,提供方便的入口,默认以英语语种进行检索;通过智能检索,用户可以组配复杂的查询条件,根据MeSH词表进行扩展查询,其次根据对查询语种的判断可以实现跨语言检索;系统集成了PubMed、GHL、SinoMed的查询接口,实现集成检索功能;期刊检索能够根据ISSN和题名查看指定期刊的信息,并能浏览指定期刊的过刊信息;检索结果分析帮助用户发现核心作者、研究机构或核心期刊;检索历史查看为用户提供了检索条件回顾的功能,并提供打印、保存为TXT文档和发送到E-mail三种检索结果保存方式。
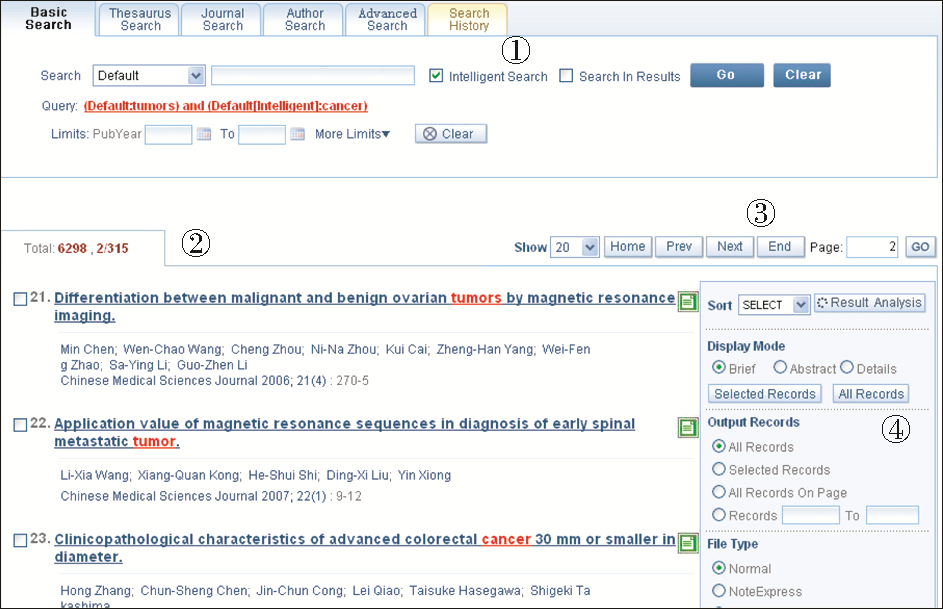
WPRIM系统运行的硬件为IBM X3650,新闻等内容存储的数据库为SQL Server 2005,题录信息的索引文件存储系统为TRS Server,操作系统为Windows Server 2003,开发语言为Java,采用基于MVC框架的J2EE架构。以“cancer”为关键词进行检索,WPRIM系统智能检索结果如图3所示:
 | 图3 检索结果展示 |
智能检索实现检索词、检索词对应主题词及该主题词所含下位词的同步检索。如:在 “Default”字段输入“cancer”,勾选①处“Intelligent Search”后点击“Go”按钮,系统自动检索出“Title”、“Abstract”、“Keyword”等字段中含“neoplasm”和“tumor”的所有文献,系统可以控制出版年的范围;②处为系统检索结果的提示;③为检索结果显示界面控制,如每页显示的条数、结果排列的顺序;④处为检索结果分析入口“Result Analysis”,分析本次检索结果集中的核心作者、研究机构或核心期刊,以及检索结果在其中的分布情况。其他期刊检索(Journal Search)、作者检索(Author Search)以及检索历史(Search History)的处理在此不一一举例。
本文通过分析西太区生物医学期刊分布现状,根据期刊分布不均衡的现状制定了期刊题录数据的采集策略。分析了现有索引和检索的方法,采用基于概念赋词的标引方法和空间向量模型的检索算法,并成功运用到WPRIM系统的设计和实施中。目前系统在多语种MeSH词典维护方面尚有一定的欠缺,提供了部分文章的全文获取功能,WPRIM收录期刊全文提供的版权问题还在进一步的讨论中。总体来说,系统实现了西太区甚至是全球生物医学期刊题录数据的采集、索引以及检索功能,笔者将在未来的工作中逐步完善改进系统的不足之处,为用户提供一站式文献服务做出贡献。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|