


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
数字文本资料修复中的字符分割法及应用
[王文哲 ]
]
]
|
|


研究数字文本资料修复模型,提出基于投影预分割和基于字符连通性二次分割组合的方法,实现对英文数字文档中基本英文字符的准确分割,并通过实验验证该方法的有效性和实用性。该方法具有很强的可扩展性,也可用于中文单字的分割。
In this paper, the model of repairing digital textual material is studied firstly. In order to accurately extract each single character from English textual material, a segmentation method based on projection and characters connectivity is presented. Experimental results show that this method is effective and practical, which can be used to extract each Chinese character because of its extendibility.
计算机技术和网络技术的飞速发展,为图书馆数字化建设提供了广阔的发展空间。图书资料数字化既是图书馆数字化建设的基础,也是其核心技术问题[ 1]。扫描文档的检索是文档数字化、数字图书馆建设的一项重要内容。纸质文档经过扫描后转换成图像格式,此时不能直接采用纯文本的检索方法,但纯粹基于图像内容的检索方法又不成熟,因此该问题在最近几年成为一个关注的焦点。
目前,扫描文档的检索方法主要有基于光学字符识别(Optical Character Recognition, OCR)的检索方法和基于词形状编码的检索方法[ 2]。基于OCR的检索方法早在20世纪90年代就形成过一次研究的热潮。当前,该技术有了长足发展,而且有相当高的识别准确度。然而,基于OCR的检索方法仍有一些应用上的缺陷[ 3]。例如,对于大型文档文献,OCR技术需要较高的人工校正代价;另外,基于OCR的检索方法是针对整篇文档进行分析、识别,但如果检索目标仅仅是一些对阅读有重要意义的文本(例如:报纸的标题),那么对整个文档做完全的字符识别将是一种严重的资源浪费。因此,针对实际需要,改进或避免OCR的整体处理特性是亟需解决的问题。基于词形状编码的检索方法是最近几年研究领域的一个热点并取得了一些进展,其主要思想是选取特征准则对整个词进行匹配或对疑似字符单元进行编码。不论是针对OCR的检索方法的缺陷改进,还是基于词形状编码的检索方
法,对文本文档进行分割、获取识别的基本单元是首先要解决的问题。
字符分割是将字符序列图像分解为单个符号子图像的过程。文献[4]总结了经典字符分割方法及策略,典型的字符分割方法可分为三类:基于图像的分割、基于识别的分割和基于整体的分割,而投影方法和基于区域的方法是基于图像分割方法中的两个基本技术。基于投影的方法采用文本行直方图,依据阈值快速定位文本行中字符间空格位置,由于此方法简单、高效,目前已得到广泛应用[ 5, 6, 7, 8, 9],但此方法对重叠字符和粘连字符缺乏有效性。基于区域的方法就其本质而言是依据字符图像连通性的处理[ 10],该方法对重叠字符有较好的分割效果,但区域处理(如区域分组和区域分离等)仍需较大的计算量。对基于区域方法的改进是对文本图像直接采用图搜索方法[ 11]。
本文建立了数字文本资料修复模型,充分利用数字文本文献的特点,研究文本字符细化的二值化阈值选取方法,提出组合投影预分割和基于字符连通性的二次分割方法,达到对英文字符的完全、准确分割,为实现数字文本资料的识别、修复提供了必要的技术基础。
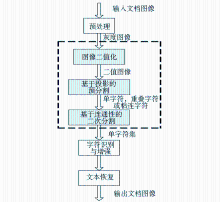
数字文本资料修复模型包括三个主要部分,如图1所示:
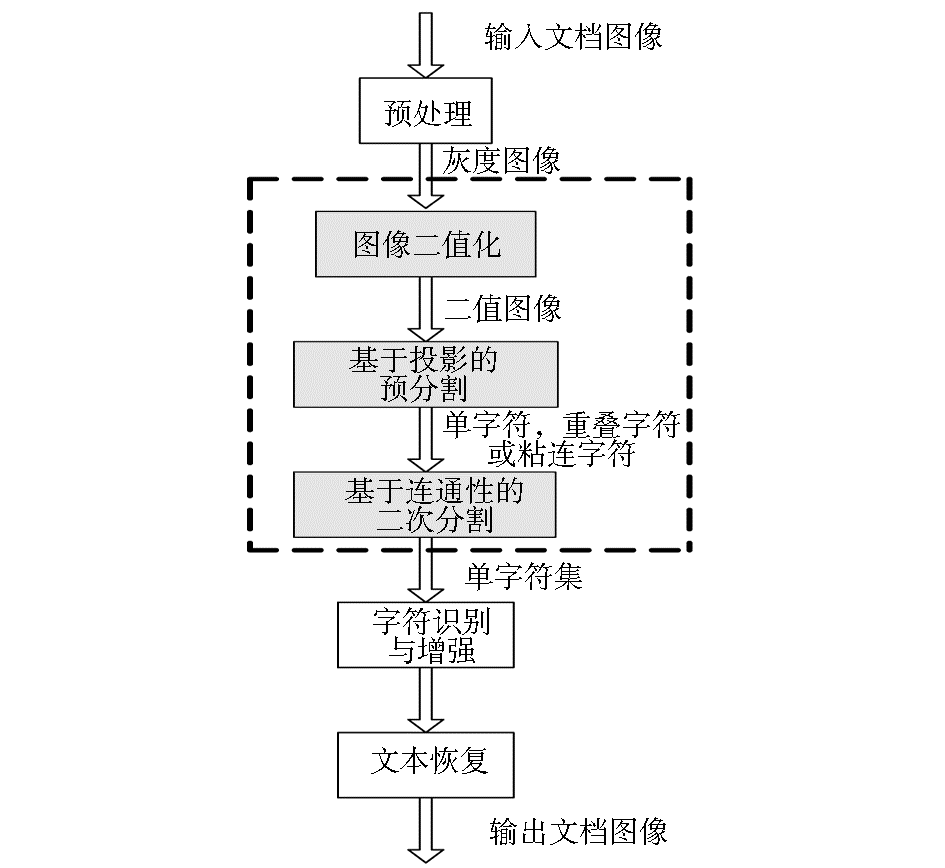 | 图1 数字文本资料修复模型 |
(1)将纸质文献经由扫描设备数字化为输入扫描文档图像,即待修复图书资料(通常输入的扫描文档图像是彩色图像)。在图书资料数字化过程中,由于扫描设备、光电转换装置、工作环境等因素,会导致图像不均匀、对比度不足等问题,使图像的清晰度差,还原度和可视性降低;另外由于光电敏感元件载荷粒子随机运动产生的噪声、传输信道的干扰等原因,会使数字化的文档图像含有一定的噪声,因此,在图书资料图像处理之前,应对输入的文档图像进行去噪处理,并产生相应的灰度图像。
(2)为了后续处理效率及算法实现方便,对所得灰度图像进行二值化处理,随后对二值图像进行基于投影的预分割,产生基本字符(单字符,重叠字符或粘连字符)。对重叠字符或粘连字符进行基于字符连通性的二次分割,以获取数字文本资料的单字符集,如图1虚线框所示。
(3)识别、增强、重排字符,从而实现文本恢复,重构原图书资料。其中,图像二值化处理和对二值图像进行的两次字符分割是整个修复过程的核心,是后期识别、重构、修复图书资料的基础,也是本文的研究重点。
字符细化可以使文本文档中字符间隔增大,更好地体现单个字符骨架结构。图像细化可采用形态学处理中的腐蚀方法[ 12],但容易破坏字符连通性。采用Log-Gabor滤波器[ 13]对字符进行细化具有较好的效果,但仍存在参数选择问题。出于字符细化和计算复杂度及效率的考虑,在分割字符之前对灰度图像进行二值化处理[ 14],中间所有操作都基于二值图像。虽然二值化过程会使得字符变得模糊[ 11, 13],但选择适当的阈值,可以达到细化效果和计算复杂性的平衡。
设预处理后的灰度图像中点(x,y)处的灰度值为g(x,y),G=[g(x,y)]M×N是灰度级为L的数字图像,选择阈值T,令b(x,y)= 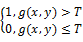
由于文本图像是由对比强烈的背景和字符对象构成,因此非常适于二值处理。图2描述了灰度文本图像选择不同阈值二值化处理后的结果,其中(a)为原始灰度图像, (b),(c),(d)分别为选择阈值依次减小所得(a)的二值图像。为了便于显示,二值化之后进行了图像反转。
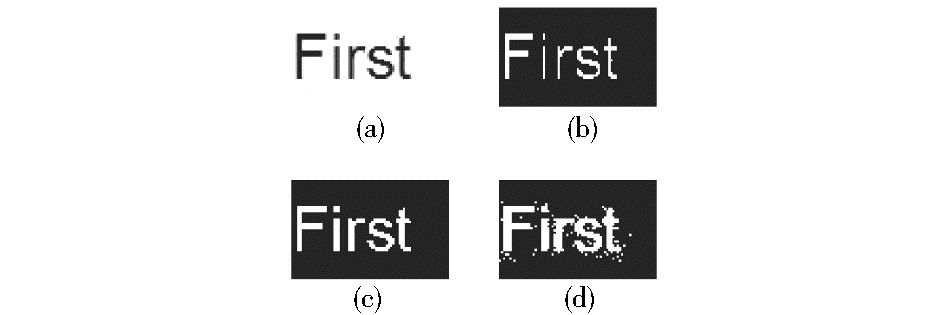 | 图2 不同阈值对二值化图像的影响 |
结果表明,灰度图像二值化处理时,当阈值选择过大时,二值图像会出现类似椒盐噪声,且独立字符间有重叠或粘连现象,如(d) 所示;当阈值选择过小时,二值图像虽然有稍许失真(细化太大),但字符间间距较大,有利于投影分割,如(b)所示;(c) 是采用Otsu算法产生的全局阈值(此处T=0.5588)处理后的结果,既保证字符连通性,又使得细化后骨架较为清晰,效果较为满意。
数字文本资料具有显著特点:无论文本行是否扭曲,都有较大行间距;行内字符间存在空格。为了分离文本行和行内字符,计算文本二值化图像向其显示坐标系的坐标轴的投影曲线 (直方图)。
设二值图像为B=[b(x,y)]M×N,并假设图像背景为黑色(像素值为0),字符对数据为白色(像素值为1)。令H1(x)= 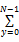

投影曲线H1(x)与x轴相交,选择相交点实现文本按行分割(见图4);同理,选择适当阈值,在二值图像失真尽可能小的情况下,依据每个文本行子图像在y轴上的投影曲线H2(y),可以定位字符间的空格,从而分割基本字符(可能会出现重叠字符或粘连字符)(见图5)。
由于文本行子图像在y轴上的投影分割可能会出现重叠字符或粘连字符,如“re”等,因此分割此类字符成为整个字符分割的关键。在26个英文大、小写字母中,除“i”和“j”外,其余都为连通字符。因此,向y轴上投影分离出的子图像中的字符,如果判断不为“i”或“j”,则都可认为是重叠字符或粘连字符。事实上,“i”和“j”虽然各具有两个连通分支,但各自的两个连通分支面积差距都较大,因此可对连通分支的面积比率设置阈值并做出判断,以确切分割出“i”和“j”。
设n(n≥2)为文本行子图像在y轴上的投影预分割子图像的连通数,Ek为第k个连通分支的面积,令rk= 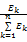
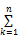
若rk较小,则Ek所对应部分不是真正的连通分支(可视为噪声等)[ 10];否则,Ek所对应部分为独立字符。为了使基于连通性的字符分割达到较好的效果,文本行子图像二值化时所取的阈值应尽可能大。
本文选取纸质图书文献《Thinking in C++》序言部分中的几行文字作为例证。将彩色图像变换为相应的灰度图像,采用Otsu算法产生的全局阈值对该灰度图像进行二值化处理,并进行反转操作,其结果如图3所示:
 | 图3 输入扫描文档处理后的二值图像 |
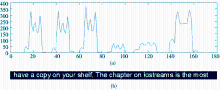
 | 图4 向x轴投影曲线及分割的第二行文本行子图像 |
将二值文本图像向显示坐标系中的x轴投影,实现二值图像的文本行子图像分割。在图4中,(a)显示二值文本图像向x轴的投影曲线,(b)显示分割出的第2行文本子图像。
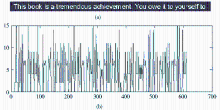
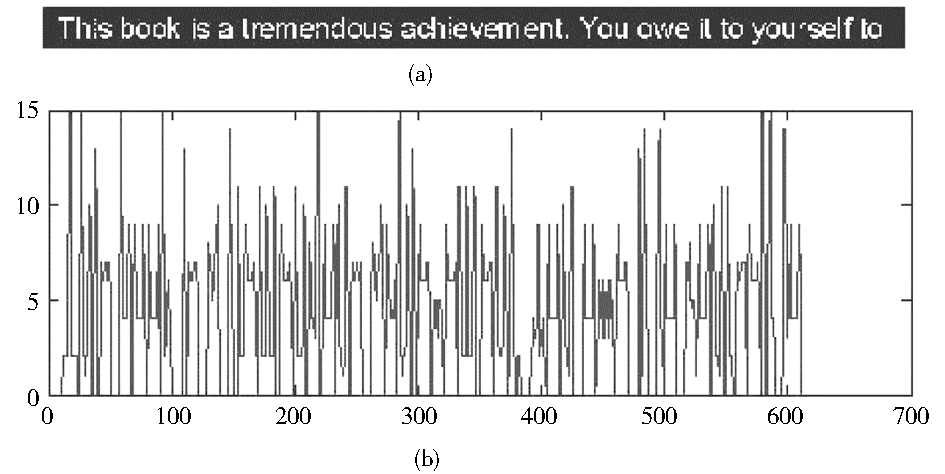 | 图5 第一行文本子图像及其向y轴投影曲线 |
将二值文本行子图像向显示坐标系中的y轴投影,实现文本行子图像的独立字符或重叠字符和粘连字符分割。在图5中,(a)显示第1行文本子图像,(b)显示该子图像向y轴的投影曲线。
文本行子图像向y轴投影预分割会产生单字符,重叠字符或粘连字符。基于字符连通性,可实现重叠字符或粘连字符的分割。图6显示第1行文本子图像投影预分割产生的重叠字符“re”,随后基于连通性二次分割后的结果。
 | 图6 基于连通性的重叠字符分割 |
实验结果表明,基于投影预分割和基于字符连通性二次分割组合的方法实现了英文数字文本中字符的完全、精确的分割。
本文所提出的基于投影预分割和基于字符连通性二次分割组合的方法,可以实现英文数字文本图像中字符的完全、精确分割,为英文字符的识别、增强,进而实现数字文本资料的机器修复提供基础。该方法简单、高效,且具有很大的灵活性和可扩展性。本文虽然仅以英文数字文档为例说明该方法的有效性和实用性,但对于中文数字文档,由于中文汉字具有方块化的字形和多种结构特性(如独体结构、左右结构、左中右结构等),如果在修正投影方向后采用该方法,也可实现其单字及其基本构造单元的准确分割和中文字符的有效识别。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|