 ,
, 
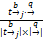
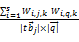
{kind=link}
{kind=link}
{kind=link}
一种基于向量空间模型的表格检索算法
[王凯 , 王朝飞]
, 王朝飞]
, 王朝飞]
|
|


针对目前信息服务机构只能提供文献的检索服务而不提供表格检索功能这一现状,提出一种基于向量空间模型的表格检索算法,并从表格特征抽取、特征词权值设置、检索结果匹配排序等方面进行讨论,为未来表格检索服务提供一定的理论依据。
According to the problem that most information institutions can only provide searching service for literature instead of tables, this paper proposes a table retrieval algorithm which is based on Vector Space Model(VSM).Discussions are implemented from the aspects of table character extraction, term value setting, and search result ranking, which provide theoretical basis of the table retrieval services in the future.
表格能够系统、简洁、集中地展现科学内容的逻辑性和对比性,是实验数据、统计结果和事物分类的一种有效表达形式,在科技文献中使用非常广泛。在科学实践中,研究人员对研究对象相关的实验数据、统计结果、对比分析等表格内容有很高的需求。但目前数字图书馆的搜索引擎只能提供文献检索服务,研究人员要想查看某类表格数据时,不得不通过检索相关文献,并通过对这些文献进行逐一游览,才能得到自己所关心的内容[ 1]。这种方法存在很大的局限性:
(1)一般文献的标题、摘要等元数据并不能展现出文献内部是否有表格以及表格的具体内容,这不仅加大了用户检索的难度,而且检索得到的结果很难保证包含用户关心的内容;
(2)为了不会漏掉重要的文献,用户不得不扩大检索范围和检索结果,手工浏览效率低下的弊端非常明显。
当前,数字图书馆中存储着相当数量的科技文献,其中蕴含着丰富的表格资源,如何高效获取读者所需的表格资源,已经成为数字图书馆面临的难题之一。
目前,国内外对于表格检索的研究还处于探索阶段,尚没有成熟的商用产品。国外对于表格检索的研究范围包括表格信息抽取和检索结果排序,重点在表格信息抽取。传统的表格信息抽取研究主要着眼于ASCII文件或
由光学字符识别得到的表格,围绕表格识别、单元格分类等展开研究。进入21世纪,随着网络资源研究的不断升温,国外逐渐提出了网页表格信息检索算法,主要通过基于Wrapper学习的方法、基于表格结构分析的方法和基于本体的方法进行元数据抽取,并做检索匹配。由于网页表格多采用HTML语言标记,形式规范,所以检索算法相对成熟。但是目前数字图书馆服务的科技文献多为电子文本,相比网页表格,信息检索的难度更大,研究论文也较少,除参考文献[2]和[3]外几乎没有其他的研究成果。
国内表格检索方面的研究远远滞后于国外,通过中国期刊网检索得到的相关度较高的论文不超过10篇,而且多数研究的是Web表格数据抽取,根据HTML网页中的Table相关标签进行数据抽取,没有针对电子文本中的表格进行抽取和检索方面的研究。
总之,国内外对于表格检索的研究尚不完善,虽然表格信息抽取技术日益丰富,但是仍然没有出现一套完整的表格检索算法。针对这一现状,本文提出了一种表格检索模型,具体流程如下:
(1)在充分考虑表格各类特征描述的基础上,建立基于向量空间模型的表格特征模型;
(2)制定合理的权值分配机制,提出相应的检索匹配算法;
(3)通过实验验证,该表格检索算法具有较高的精确度,可以很好地运用到数字图书馆检索服务中。
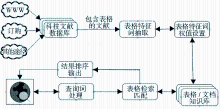
根据科技文献中表格的特点以及向量空间模型理论,构建表格的检索模型,具体步骤如图1所示:
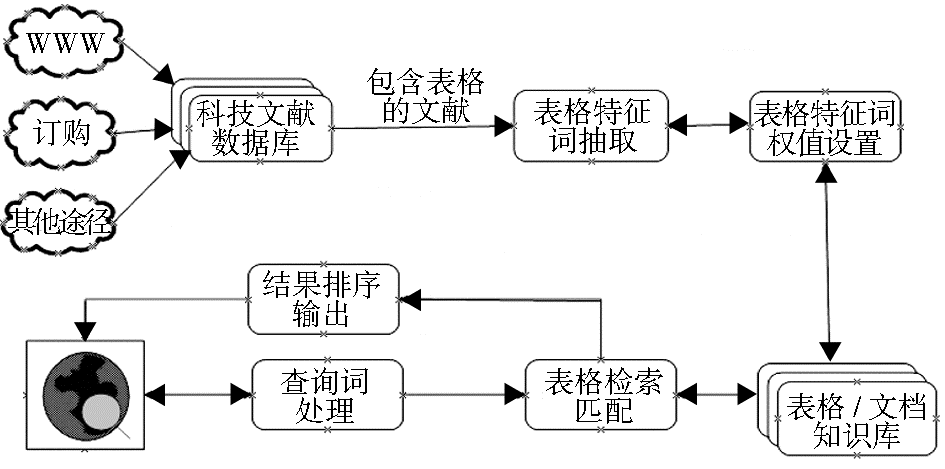 | 图1 表格检索模型 |
(1) 表格特征抽取
针对表格的特性,确定最能代表表格内涵的特征域,然后选择并提取其中重要的特征词。所有特征词的集合便将每个表格表示为对应的空间向量。
(2) 特征域权值分配
不同特征词因其词频、词性、所属特征域(如:表格标题和表格脚注等)的不同,对表格含义表达的贡献也大不相同。本文考虑两种层次的权值,即单词级权值和表格级权值。
(3) 表格检索匹配与结果排序
按向量空间模型的理念,每一个检索表达式都可以表示为一个空间向量,同代表表格的特征向量进行相似度匹配,从而得到想要的结果。对每一次表格检索结果,都要进行结果排序,排序的方法不光要根据相似度计算结果,也要考虑文献本身价值等因素。
表格检索模型建立的步骤同一般的文献检索模型建立步骤非常相似,主要的难点是表格特征描述的选择和特征词权值的合理设置,这也是本文论述的重点。
作为表格检索模型的基础,首先要解决的问题是如何提取表格的特征。表格特征不同于纯文本的特征,处于表格不同位置的词语,对表现表格的主题有不同的作用,应该分别处理,给予不同权重。经过大量的数据分析,发现具有区分力的表格特征词主要集中在以下几个区域:
(1)表格标题:表格数据的题目信息;
(2)表格列名:表格数据的列标头;
(3)表格参考文献:表格信息参照的其他文献名,一般以上标的形式指引;
(4)表格脚注:某些科技文献会对表格信息添加脚注,放在页角;
(5)文档标题:包含该表格的文档的题目。
基于该统计,本文将表格特征分为5组,每一组均设置一个单独的子向量,以方便不同位置特征词的加权。为了描述本算法,进行如下定义:文档集合D={dα,α∈[1,N]},N为文档的总数目;表格集合T={tbj,j∈[1,b]},b为从文档中抽取的表格的总数目;特征域R={ri,i∈[1,k]},i 为特征域的种类,文本k取5。其中,表格集合T来源于文档集D,每一特征域ri由对应区域中一组特征词组成。新的向量空间模型(见表1)中,矩阵的行代表了表格tbj或者查询条件q的空间向量,这些向量组成一个向量矩阵。ri(i∈[1,k])代表表格的特征域,每一个表格都有k个特征域,每一个特征域都由一组按照字母顺序排列的特征词(tz,k)组成。每一个Table的空间向量可以记为:
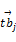
其中,wi,j,k指表格tbj的第k 个特征项的第i个词的权值。假如该词没有出现在该特征域中,则wi,j,k=0。同一个单词ti可能出现在多个特征域中,比如:表格名称、文档标题等,但在不同的特征域中出现,其权值也应该不同。对于提取表格特征项的方法,可以参照参考文献[3]和[4],在此不再详细介绍。
| 表1 表格及查询条件的向量空间模型 |
处在不同位置的词对表格内容的表征作用是不同的,即使同一特征集中的词,根据词频、词性等的不同对表格内容的表征作用也是不同的,因此有必要对表格特征的权值进行合理设置。
对于每一个词的权值wi,j,k,考虑两个层次:单词级信息权值 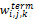
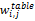
wi,j,k= 
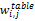
其中,Qk是第k项特征域的权值。
(1)单词级信息权值
对于特征词的权值计算,经典的方法是TF×IDF计算法。基于该方法,重点考虑单词在表格特征域中出现的频率,而不是该词在整个文档中的词频。本文归结如下公式:
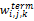
其中,TTFi,j,k表示第j个表格tbj的第k项特征域rk中,单词ti出现的词频;ITTFi,j,k表示含有单词ti的表格的反转频率,也就是说单词在越少的表格中出现,其表现力就越强。
为了提高算法对于不同质量的表格数据的适应性,防止计算时出现异常,对公式做出如下调整:
TTFi,j,k=p+(1-p)×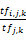
ITTFi,j,k=log2 
在公式(4)中,p为(0,1)之间的小数,根据参考文献[5],p值一般取0.5, 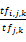
在公式(5)中,b表示集合中表格的数目,IDFi,j,k表示在第d项特征域rk中,出现单词ti的表格的数目。
综合公式(3)-(5),可以得到 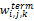
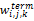
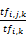

(2)表格级信息权值
表格本身的信息也很重要,它影响着其内部词语的权值。本文重点考虑两个表格特征:表格频率tbf;描述表格的文本长度trt。其计算公式如下[ 2]:
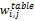
其中,wtbf表示表格频率的值,它的含义是假如同一篇文档中包含检索词的表格数目越多,那么该文档越能满足用户检索需求。在实际计算中,为了适应不同质量的数据文件,防止出现计算异常,对该公式作出如下定义:
wtbf= 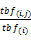

其中,tbf(i,j)表示在文档dj中,包含词ti的表格数目;tbf(i)表示文档dj中所有表格的数目;b为表格集合中所有表格的数目;bi为表格集合中所有元数据内出现单词ti的表格的数目。
wtrt表示描述表格文本信息的权值。一个表格在一篇文档中本身长度越大,或者其参考文献越多,则说明表格信息越完整,用户查询到有用表格信息的可能性也越大。因此,用如下公式计算表格相关文本信息的权值:
wtrt= 
其中,tableLen(i,j)表示文档j中,包含单词ti的表格的相关文本长度;totalLenj表示文档j的总长度。
综合公式(7)-(9),表格级信息权值归纳为:
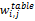
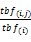


(3) 特征域权值分配
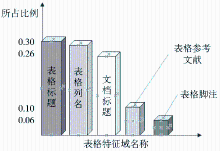
由于不同特征域的词语对表格的表征贡献不同,在对其加权时,应该设置不同的权值参数。具体来说,公式(4)中Qk的值需要进一步确定。为此,进行了人工实验:取5类科技文献,每类40篇文档,提取出最能代表其中表格的5个词语,共计1 000个词语;采取人工统计的方法,记录这些词语的来源分布。虽然学科不同,但是提取出的词语分布类似。“表格标题”、“表格列名”以及“文档标题”中的词语最能代表一个表格的主题,“表格参考文献”和“表格脚注”中的信息虽然也具有不错的表现力,但是相对较弱,而且这两个特征域有时并不出现。用每个位置特征项所含词语的数目除以基数1 000,可以得到每个特征项所占比例,其值为0—1之间的小数,分布结果如图2所示:
 | 图2 表格特征词分布比例 |
结合实验结果,可以初步确定每类特征域的权值,即5类特征域权值分别为(0.3,0.3,0.25,0.1,0.05),表格检索实验即采用这一权值分配。
运行环境为Windows XP操作系统, CPU主频 2.8 GHz, 内存512MB, 编程工具为Visual C++ 6.0。选择400篇含有表格数据的科技文献作为测试数据,这些文献主要分布在武器装备、计算机技术、历史地理、生物医学4个领域,且所有表格都经过人工标引。人工标引过程如下:从4个领域挑选比较常见的主题词20个,其中每个领域各5个,每4个不同领域的主题词组成一组,共5组。以主题词组“武装力量、数据挖掘、地震、基因序列”为例说明:分别查找并记录包含各主题表格的文献及文献数量,标引结束后即进行检索实验,分别以每一组的主题词作为检索词进行表格检索,对检索结果进行记录并统计。最后比较实验结果和标引结果并做出评价,其他4组主题词处理过程相同,以5组评价指标的平均值作为该检索算法的最终评价指标。
使用查准率P和查全率R以及F测量值为检索结果的主要评价指标,给定某一检索词,并人工确定含有与该检索词相关表格的文档n个。在检索得到的m个结果中,有m1个结果是准确的,则查准率P=m1/m,查全率R=m1 /n,F=2×R×P/(R+P)。对每一组的主题词分别进行实验后再计算该组结果的平均值。
在所得特征权值的基础上,以0.8为相似度阈值,得到实验结果如表2所示:
| 表2 检索结果评估 |
其中5组主题词对应关系如表3所示:
| 表3 主题词组说明表 |
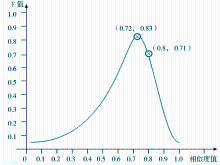
相似度阈值的设定对检索结果也有很大的影响,通过多次实验,得到相似度-F值曲线如图3所示。
 | 图3 相似度-F值曲线 |
由图3可知,最优阈值为0.72,并得到最优检索结果(见表4),当然该阈值会随着检索数据集的改变而改变。
| 表4 最优检索结果 |
本文提出了一种基于向量空间模型的表格检索算法,实验证明在科技文献表格检索中能够得到较好的检索结果。未来的工作将重点研究以下两个方面:
(1)目前的检索算法主要是针对PDF格式科技文献中的表格进行检索,实际互联网上拥有更多有价值的表格,其特征也与科技文献中的表格特征不同,改进一套适合网络资源表格检索的算法是很有意义的;
(2)该检索算法中的特征权值是通过简单统计得到的经验参数,随着数据的变化参数也会发生变化,有必要研究得到一套具有高适应性的参数,或者采用自适应的方法来调节参数。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|