

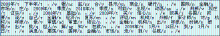

{kind=link}
{kind=link}
{kind=link}
政务领域本体术语的自动抽取
[翟笃风1  , 刘柏嵩
, 刘柏嵩2 ]
, 刘柏嵩|
|


提出一种新的政务本体术语自动抽取的方法。首先通过中文分词技术和单字合并法提取政务文本中的词作为候选术语;通过C-value求解法和TF-IDF算法对候选术语进行过滤抽取,从而实现政务领域术语的自动抽取。通过实验比较,发现该方法在不影响领域术语抽取召回率的同时可以提高抽取术语的正确率。
This paper introduces a new method to extract the administrative-domain Ontology term automatically. Firstly, some words that are representative of the candidate terms should be extracted through the technology of word segmentation and the characters merger method. Secondly, the candidate terms are filtered by the way of C-value method and TF-IDF algorithm to achieve the automatic domain-specific term extraction in administrative-domain Ontology. Finally,the experiment shows that this method can improve the accuracy of the extracted terms and do not affect the recall-rate.
近年来,随着知识共享、信息集成、语义Web和Web服务等技术的快速发展,本体技术被广泛应用到人工智能、知识共享、语义检索中。
领域本体被认为是解决“信息和知识孤岛”问题最有效的方法,它能够有效地解决知识内在的异质性和分布性,从而实现知识在多主体和软件实体之间的共享和重用。政务领域本体的构建研究也得到了广大学者的重视,被认为是电子政务知识管理最有效的方法,欧盟制定并实施了“E欧洲2002行动计划”[ 1];我国信息化领导小组第一次会议决定,把电子政务建设作为今后一个时期我国信息化工作的重点,并强调电子政务本体建设在电子政务系统中对信息资源的整合作用。
我国电子政务所包含的资源非常广,科学技术文献出版社2005年出版的《综合电子政务主题词表(试用本)范畴表》将全部主题词按学科、知识领域以及部门职能划分成若干个范畴,其中一级范畴包括:01综合政务,02经济管理,03国土资源、能源,04工业、交通,05信息产业,06城乡建设、环境保护,07农林、水利,08财政、金融,09商业、贸易,10旅游、服务业,11气象、水文、测绘、地震,12对外事务,13政法、监察,14科技、教育,15文化、卫生、体育,16军事、国防,17劳动、人事,18民政、社区,19文秘、行政,20综合党团,21综合用语[ 2]。
在一级范畴的分类中,无论个人还是企业,只要与政府服务有关的都是电子政务的范围,信息量非常庞大,而且随着今后电子政务的进一步发展,其所对应的知识库所包含的信息量会更加庞大,单纯使用手工构建本体的方法费时费力。因此,如何使用知识获取技术,即利用本体学习方法来实现电子政务本体的自动构建具有很强的现实意义。
在领域本体构建过程中,无论是关系的获取、概念属性的分析,还是实例的获取都离不开本体概念的自动抽取。术语的抽取被认为是进行本体构建的先决条件,是后续执行更复杂的本体关系构建的基础[ 3]。因此,进行电子政务本体的自动构建过程,有必要对电子政务术语的自动抽取进行研究。
目前,大多数本体学习方法和本体学习系统是直接将术语识别为概念。术语的抽取被认为是进行本体自动构建的关键。针对术语抽取的研究主要有基于语法规则的方法、基于统计的方法和两者相混合的方法[ 4, 5, 6, 7, 8, 9, 10, 11]。
基于规则的方法建立在语言学知识研究之上,通过分析领域文本来建立规则,使用浅层的文本解析、机器学习等技术来查找符合语法规则的词句。
在国外通过语法规则的方法抽取概念的研究中,主要使用浅层解析技术或模板方法获取术语。浅层解析技术[ 4]是在已进行词性标记的文本中,探测句子中词语边界、发现词语间语法关系的技术。Bourigault[ 4]认为术语单元有一个固定的词法形式,他在“表面语法分析”基础上第一次抽取出了最大长度的名词短语。模板方法[ 5]根据领域术语的特殊词法结构或模板,在文本中找寻并抽取语法结构符合这些特定模板的字符串。
利用语法规则的方法来进行术语抽取具有提取术语准确度较高、处理过程简单、计算量较小、能够有效提取低频术语等多项优点。但是,由于语言学规则本身难以掌握,尤其是针对开放性的语料,语言学的规则更是难以准确应用,利用人工来研究语言学的规律越来越难实现。目前,有学者提出利用机器学习的方法来自动学习语言学规则,但是所开发出的机器学习方法存在可移植性差的问题。
基于统计的方法根据领域相关概念和普通词汇拥有的不同统计特征,识别出领域的概念。大多数基于统计的方法关注多字词汇的抽取,主要采取的方法是计算各组成部分之间的联系程度。
这种方法在国内外的研究比较多,主要有:Frantzi等人[ 6]提出利用术语的上下文信息,通过NC-Value来识别术语,利用C-value值统计方法来对多词术语进行抽取;Justeson和Katz[ 7]所提出计算相关词的词频的方法,即计算词在语料库中出现的频率,并使用一个词性过滤器来筛选候选术语,这种方法对于固定短语的抽取效果较好;Rezgui[ 8]提出采用计算相关词的TF-IDF值的方法来计算相关文本中的候选概念,该方法先计算相关词语在前景语料和背景语料出现的次数和文档数,通过计算TF-IDF值来抽取术语,这种方法使那些具有前景语料特点的单词获得较高权重,使得那些常用普通词受到抑制;Pantel 等人[ 9]提出将互信息和对数似然两个参数相结合进行术语提取,采用互信息的方法来度量在一个文本中两个相邻词之间的相互依赖程度,从而估算出频繁出现的相邻词语构成术语可能性的方法。
使用统计的方法来抽取术语可以高效地识别领域术语,只要一个词在文本集中出现的频率高,就可以被有效抽取出来,而且这种方法不需要句法和语义上的信息,不局限于某一特定专业领域,可移植性较好。但是,这种方法必须通过对整个语料库进行统计才能得到相关数据,所以存在计算量大的缺点。同时,该方法在处理低频术语的时候,效果较差;处理高频术语的时候,提取的结果未必是具有完整意义的字符串,准确率较差。
基于统计学的方法和语言学的方法都在本体自动抽取术语过程中发挥一定的作用,但是也存在着各自的缺点。因此,在实际抽取本体术语的过程中,这两种方法必须结合使用,相互补充。
针对基于混合方法来抽取本体术语的研究中,杜波等人[ 10]提出先通过假设检验或互信息来检验两个字符串是否独立,如果不独立则认为其合串是一个候选术语,最后通过C—value的方法对候选术语集合进行过滤。Missikoff等人[ 11]在本体学习系统OntoLearn中,采用了浅层解析技术从文本中获取候选词语,再采用统计方法对术语进行过滤,从而在提高术语抽取召回率的同时,提高正确率。
这些研究成果虽然很好地利用了语法规则和统计方法两者的优点,大大提高了多字词术语的抽取召回率及通用术语抽取的准确率,但是由于这些方法缺乏无关领域文档集,即背景语料的支撑,在抽取领域术语时正确率较低,并不适合于针对领域术语的抽取。
本文针对现有基于混合方法抽取术语的不足,提出了综合使用单字合并法[ 12]、C-value算法[ 6]和TF-IDF的方法[ 8]。与先前研究成果相比,该方法增加了对领域术语的独占性和相关度的计算,筛选出与领域相关度低的术语,从而提高了领域术语抽取的正确率。
本体学习是以自动或半自动方式来构建本体,从而有效克服在本体开发过程中所出现的本体获取的瓶颈问题。本体学习的重点主要集中在概念抽取和概念关系抽取[ 3],相关术语的抽取也是本体学习的第一步,是后续执行更复杂的学习任务的基础。术语抽取阶段的任务是发现相关语言集合或表示概念和关系的符号集合。本文提出采用基于混合的方法来获取政务领域概念,基本策略如下:
(1)采用语法规则的方法提取相关候选术语,采用ICTCLAS系统来对相关文本中的政务信息进行分词处理;
(2)在分词过程中,针对ICTCLAS系统无法有效识别的词而切分成的单字和词串,采用单字合并法对这些被切分成散串的词进行概念抽取并合并成新词;
(3)利用C-value算法对文本中的合并词和切分的词进行初步过滤,筛选出那些具有实际语义的词作为候选术语;
(4)对通过基于规则方法所提取的概念使用统计的方法进行与领域相关度的计算,即使用TF-IDF算法对候选术语进行计算,求出每个候选术语在政务领域文本中的相关性,抽取出具有政务领域独占性强的词作为政务领域术语。
(1)中文分词
汉语与其他语言最大的区别在于汉语是以字为基本的书写单位,词语之间缺少明显的区分标志,而在文本中词是最小的能够独立活动的有意义的词语成分。在政务中文文本相关概念抽取过程中,中文分词既是基础也是关键。由于ICTCLAS系统较好地将汉语分词、切分排歧、未登录词识别和词性标注等词法分析任务融为一体,因此本文主要采用ICTCLAS分词系统对领域文本集进行分词及词性标注。在分词之前将领域词典加入到分词工具中,对政务领域中文文本集中的每个文本进行处理。
在一段关于政务方面的网络文本中,有关人员提取相关文本信息用ICTCLAS系统进行分词处理,结果如图1所示:
 | 图1 中文分词处理 |
(2)去除停用词
经过分词及词性标注后的文本还存在高频词,这些词虽然在电子政务领域中频繁出现,却不能反映政务领域相关知识,比如“是”、“的”、“与”这些词都属于无用的高频词。在采用统计方法抽取文本集中的政务领域概念时,这些词影响了抽取结果的正确性,所以需要将文本集中的这些与政务领域无关的高频词进行过滤。将领域文本集中的每个文本和包含叹词、虚词等高频词的停用词表进行对比,在领域文本中发现停用词表中的词,将这些词从政务领域文档中删除。
对上述经过分词处理的文本信息与停用词表进行对比,去除文本中的停用词,如图2所示:
 | 图2 去除停用词 |
从图2可以看出,去除停用词后文本明显消除了冗余信息,在对政务领域术语提取的过程中可以大大减少这些无用词对抽取结果的影响,在文本集中文档数量很大的时候,可以提高程序的运行速度。
(3)去除数词
文本中往往存在一些在概念抽取过程中基本没有积极作用的数词,在单字合并过程中会产生大量有歧义的词,因此,相关研究者在合并单字的时候,这些数词也要进行相应处理。把相应的带有m标记的数词去除掉,进一步降低文本中的冗余信息,如图3所示:
通过使用ICTCLAS对文本进行处理后,发现文本中包含了很多由两个、三个字组成的有实际意义的词,如:下半年、提示、商业等。把这些已经正确切分的词直接作为政务候选术语存入相应的文档内;在处理后的文本中,还包含了一部分通过语义切分而成的散串,这些散串并没有实际意义,需要使用一定的方法对这些散串进行处理。
在对文档进行预处理后,有部分字是因为分词工具不能有效识别的领域概念而被切分成的散串,这些散串本身并没有实际意义,如:银、监、会。本文提出使用单字合并法对这些散串进行适当处理,判断文本中的单字能否进行合并组成词,并把合并后的新词作为候选的政务领域术语,相关过程如下:
(1)以标点符号对句子进行切分
在文本中,句子与句子之间用标点符号来标识,而表示成概念的被切分的那些单字只可能出现在同一句话中,也就是说,只有出现在一个句子中的单字才能被合并成有具体意义的词。将文本按标点进行适当切分,每句话存为一行,同时删除标点符号,这样在对单字进行合并的过程中,只需要针对每一行句子进行操作,大大方便了对单字进行合并成串的操作。
(2)单字合并
在对句子进行切分完成后,开始对单字进行合并。通过观察发现,通常对一个概念进行拆分时,会将一个概念拆分成若干个单个的字或者是被切分成单个的字和词。针对这两种情况,要分别进行合并处理。
如果一句话中有几个相连的单字,那么要把这几个单字合并成一个新词[ 12, 13]。例如在对上述文本中,以经过标点符号切分后的句子为单位,对句中每个切分的单字进行相连的合并,则可得到一些新词汇,如:银监、监会。
如果一句话中有一个单字与一些词相连,它很可能和前面的词或后面的词组成一个概念,则要分别将这个单字和前面的词、后面的词进行合并存入文档中[ 13]。例如:将“银 监/nr 会/v 提示/vn 商业/n 银行/n”这句话内的单字和词分别组合,即可以得到“银监会”,“会提示”两个新词。
通过单字合并法对政务语料库进行处理会得到多个合并后的新词作为政务领域的候选术语。这些候选术语有些是有实际汉语意义的词,有些则是没有任何意义的词语,而对新词是否有意义的区分是无法通过使用单字合并法进行解决的,必须通过相关统计方法或者语义方法进行过滤,进而从这些词中筛选出政务领域术语。
(1) C-value算法
通过单字合并法和语义切分的方法对政务语料进行处理,得到大量的政务领域的候选词,这些词不仅包含政务领域术语,也包含与政务无关的词语,甚至还包含了一些没有任何意义的词语,比如:通过单字合并得到的“会提示”这个新词。这就要求对文档中的词进行适当的过滤。
本文提出通过计算每个候选术语的C-value值的方法,对候选术语的C-value值进行排序,设定阈值对候选术语进行过滤,选出那些有实际汉语意思的词作为候选政务术语。
C-value是一种可以更准确地在相互嵌套的字串中抽取领域术语的方法,它能够有效地从文档中抽取出有实际意义的词汇,比传统的单纯使用词频的方法更精确地抽取出相关术语,尤其在多字词术语的抽取方面更能体现出它的优越性[ 6]。
C-value的定义为[ 6]:
①如果词a没有任何可能在文档中与其他单字或词组成新的合并词,那么它的C-value值的计算公式如下:
C-value(a)=log2g(a)×f(a)(1)
②如果词a在文档中与其他单字或词有可能组成新的合并词,那么它的C-value值计算公式如下:
C-value(a)=log2g(a)×(f(a)-1/p(Ta)× 
其中,a为词;g(a)为词a所包含的单字个数;f(a)为候选术语a在文本语料中出现的次数;Ta为包含词a的更长的合并词;p(Ta)为那些由词a和单字组成的新的合并词的个数; 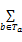
根据C-value方法,对已经通过语言切分工具进行切分、通过单字合并法得到的候选术语在领域文本中出现的次数和对包含这些候选术语的字串出现的次数进行统计;再计算出每个合并词的C-value值。
在关于“银监会”的相关文档中,首先统计出“银监”和包含“银监”这个候选术语的更长的词在文档中出现的次数,如表1所示:
| 表1 词频统计结果 |
据式(1)计算出上述包含“银监”这个词的新的合并词即“银监局”、“银监会 ”、“银监部门”的C-value值:
C-value(银监局)=log2g(银监局)×f(银监局)
=log23×41
=64.98
同理可得:C-value(银监会)=90.34,C-value(银监部门)=156。
据式(2)计算包含在上述字串中的词“银监” 的C-value值。
C-value(银监)=log2g(银监)×(f(银监)-1/p(T银监)× 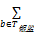
= log22×(205-1/3× 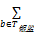
=1×(205-1/3×(78+57+41))
=146.33
通过计算,得到关于上述词的C-value值,如表2所示:
| 表2 C-value值求值结果 |
在本研究中,从维普、万方、CNKI抽取的近10年内有关政务的300多篇文章作为语料库,为避免所抽取的文章在某一领域的类同性过强而导致计算出的候选术语值缺乏正确性,所抽取的文章尽可能均匀地涉及到了政务的各个领域。
通过计算,可以得到相应候选术语的C-value值,并对相关候选术语进行C-value 值排序,结合汉语言学知识对相关候选术语进行实验分析。研究发现,当相关词串的C-value值小于11.45时,都是一些没有实际意义的词。因此,选取11.45作为C-value阈值, 选定候选术语中大于该值的词进行下一步处理。在表2中,相关政务领域候选术语的C-value值都较大,远远大于通过实验所设定的阈值11.45,可以认为这些词都具有实际的意义,都可以作为政务领域候选术语存入新的文档中。
(2)TF-IDF算法
对多个政务领域文本中所提炼出的候选术语的C-value求值并进行筛选,得到大量有实际意义的词作为新的候选术语存入语料库中,但是由于C-value本身只能对词的正确性进行一定的筛选,缺乏对词是否是领域类别信息的处理,无法将与政务领域无关的词排除在语料库外,使语料库中还存在大量虽然有明确的中文语义但是与政务领域无关的词,对于这些词,本文使用TF-IDF算法进行排除。
TF-IDF=TF(i)×IDF(i)= 
通过式(3),可知TF-IDF算法包括TF和IDF两部分[ 8]。TF表示给定的候选术语在前景语料中出现的频率,也就是该候选术语对于前景语料的绝对贡献,TF值越高,该候选术语对于前景语料就越有代表性;而IDF等于背景语料中的文本数n和在背景语料中含有该候选术语的文本数量的比值取对数的值。如果一个候选术语在背景语料中经常出现,那么对于任何领域来说就没有代表性,可以认定这个候选术语不是所要领域的真正术语。通过TF-IDF的乘积计算,可以使那些真正代表专业领域特性即前景语料特点的词获得较高权重,使得那些常用的普通词即背景语料中的词受到抑制[ 8]。
鉴于此,将与政务领域相关的文本作为前景语料,抽取出4 000篇与政务领域无关的文章作为背景语料,同样这些背景语料涉及经济、生物、军事等领域,以保证计算结果具有客观性。通过计算并比较每个候选术语的TF-IDF值。操作过程如下:
①统计出每个政务候选术语在前景语料中出现的次数。
②统计出背景语料中包含相关政务候选术语的文本数量。
③计算每个政务候选术语的TF-IDF值。
如果一个候选术语在背景语料集中不出现,那么这个候选术语的dfi为0,无法计算出TF-IDF值,需要对这种情况做出特殊规定:如果一个政务候选术语在背景语料集中出现的次数为0,那么将其IDF值设为常数m。在此,将m取值为10。
TF-IDF的计算公式根据dfi的取值情况进行如下定义[ 8]:
TF-IDF=
在式(4)中,tfij表示候选术语i在前景语料文本j中出现的次数;n表示背景语料中所包含的普通文本数;dfi表示含有该候选术语i的普通文本数目[ 8]。
④对每个候选术语的TF-IDF值进行排序。
⑤设定阈值,将TF-IDF值大于阈值的政务候选术语保存到文本中作为最终的政务领域术语。
通过上述操作过程,对“银监”等候选术语进行TF-IDF求解,结果如表3所示。
对所得到的政务领域术语进行TF-IDF求解并进行排序,将小于这个阈值的候选术语全部排除,则可得到政务领域术语,上述“银监”、“银监局”、“银监会”、“银监部门”、“银行”等词的TF-IDF值都大于通过实验所得出的阈值34,具有很强的类别区分性,这些词在政务中具有很强的独占性,可以认为是政务领域术语。
| 表3 TF-IDF求值结果 |
在实验中,分别选取300篇前景语料,400篇背景语料,使用中文分词技术和单字合并法对术语进行抽取;再使用C-value值求解法、TF-IDF求解法对文本中所抽取的概念进行过滤,实现政务领域术语的获取,相关结论如表4所示:
| 表4 政务领域术语抽取过程比较 |
从表4可以看出,使用单字合并法和中文分词技术对术语进行抽取,所得的术语个数虽然较多,查全率较大,但是由于是对文本中的词进行不加区分的并入,因此错误率较高;在后续实验中,使用C-value和TF-IDF方法对所抽取的词进行过滤,很好地提高了政务领域术语抽取的正确率,将原来的正确率提高了40多个百分点,虽然相应的查全率有所下降,但是并不明显,在对概念的抽取方面有明显的效果。
本文提出了一种新的中文领域本体学习中术语的自动抽取方法,并将其应用到政务领域的术语自动抽取。通过中文分词技术和单字合并法从相关文本中抽取词语,并将这些词语作为候选术语;使用C-value求解法和TF-IDF算法对相关候选术语进行筛选过滤,从而找出与领域相关度高的词语作为领域术语。该方法与传统方法相比,能够在不影响领域术语召回率的前提下,大大提高领域术语抽取的正确率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|