一种基于类别信息的文本自动分类模型
[刘海峰 , 刘守生, 张学仁, 苏展]
, 刘守生, 张学仁, 苏展]
, 刘守生, 张学仁, 苏展]
|
|


从理论角度分析基于互信息的特征选择方法的不足,提出一种改进的互信息特征选择方法;针对向量空间模型在文本表示方面的问题,使用类别空间模型将文本表示为矩阵,有效利用文本的类别信息,实现一种基于类别信息的文本分类算法。对中文文本的分类实验结果表明,该文本分类方法具有良好的分类效果。
Firstly, the defects of method based on mutual information in the feature selection are analyzed theoretically,then an improved method is put forward. According to the problems of vector space model, the authors use a class space model to express text and take advantage of the category information. In this way, the paper realizes an algorithm of text categorization based on category,and the result based on the Chinese text categorization shows that this method has a better precision in the text categorization.
文本自动分类(Automatic Text Categorization,ATC)是指在预先给定的类别标记集合下,根据测试文本内容对其类属进行自动判定。文本自动分类技术广泛应用于自然语言理解与处理、信息组织与文本挖掘、信息过滤和信息检索等领域。基于Web的信息检索对文本自动分类技术提出了更高的要求。作为数据挖掘领域的一个主要研究方向,文本自动分类技术研究得到了学者的持续关注[ 1, 2, 3]。
文本信息是以自然语言形式存在的非结构化数据,文本自动分类技术研究主要集中在文本的结构化表示方法、文本特征降维方法研究以及文本分类器设计三个方面。其中文本标引水平影响着文本自动分类的效率,而文本特征高维性是制约文本分类技术的主要瓶颈,特征降维技术研究成为文本分类的核心问题。
文本特征降维方法主要有特征选择和特征抽取两种主要模式。其中,特征选择模式以其结构简单、易于解释、使用方便等优点在文本分类中得到了普遍使用,形成了一些分类效率较好的方法。比如词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[ 4]、信息增益(Information Gain, IG)[ 5]、互信息(Mutual Information, MI)[ 6]、χ2.Chi-square)统计及期望交叉熵(Expected Cross Entropy, ECE)[ 7]等模型均得到了较为深入的研究。结果表明[ 8]:除了MI模型,其他算法分类正确率随着特征项减少而增加,但是达到特征项维数约1 600维时,分类正确率下降;相比较而言,TF-IDF和χ2分类性能较好,IG对不同的语料分类波动较大,MI效果
最差;而在特征项维数较小时TF-IDF、χ2性能优势效果明显。
作为一种重要的特征选择模型,MI在实际使用中效果并不理想。因此,对该模型进行深层次的研究,提高其特征降维效率既具有重要的理论意义,也具有很好的实用价值。
在信息论中,互信息体现了两个统计量之间相互关联的程度。在统计语言模型研究领域,互信息方法得到了广泛的应用。在文本分类的特征选择方面,特征项ti与类别cj(j=1,2,…,s)之间互信息体现了特征项与类别之间的相互依存程度,计算公式如下[ 6]:
MI(tk,cj)=log
其中,p(tk,cj)为文本集里特征项tk与类别cj的共现频率,p(tk)为tk在文本集里出现的频率,p(cj)为文本集里文本属于类别cj的概率,而tk与文本集的互信息计算公式为[ 6]:
MI(tk)= 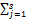
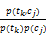
=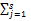

在特征选择时,互信息方法的物理意义是以特征项在不同类别中出现次数占其在整个文本集里出现的次数的比率作为该特征项判别文本类属的能力的度量标准:在类别cj内出现的频率越高、同时在训练集内出现的频率越低的特征tk对cj类文本的标引能力越强。互信息值MI(tk)越大,说明特征项tk对文本的标引能力强,对确定文本类属的作用就越大。
该模型的显著优点是考虑了特征与类别共现频率、特征与类别在整个训练集里出现的频率,有效利用了文本的类别信息,同时也考虑了低频词所带有的信息量。
但是,MI方法在文本特征选择方面的缺点也相当明显[ 8]:
(1)与其他常用的特征选择方法如TF-IDF等相比较,互信息方法吸收了低频词所含有的文本标引信息,这是它的优点。但是在应用中发现这种方法的缺点也在这里:该方法对低频词过于敏感。分析式(2)可以看出,MI(tk)主要决定于p(tk)以及在类别cj下的条件概率p(tk|cj)。当-logp(tk)较大时,MI(tk)较大,因此低频词对MI(tk)的影响较大,也就是说低频词的作用被放大。其实文本里大量的低频词对文本分类作用很小,但在MI(w)的计算模式下其作用却被放大。本来这些大量的对类别判定贡献小的低频词在特征选择时应该被剔除,但是式(2)却不能解决这一问题,这一缺陷在训练样本类别分布不均时尤为明显。
(2)这种方法忽视了训练样本类别分布均匀与否对互信息值的影响。互信息方法是在训练样本类别分布相对均衡的前提下考察类内该特征tk出现的频率p(tk|cj)与在所有类别内出现频率p(tk)之间的差异,但是却没有考虑训练样本类别分布失衡条件下该模型存在的问题。事实上,在样本类别分布倾斜条件下常常会造成以下的现象:假定类别ci和类别cj所含的文本数差别很大,前者在数量上远远大于后者;此时,假定特征项tk与cj的关联程度远远小于其与cj的关联程度,但是通过式(1)的计算却反映出tk与ci的互信息优于其与cj的互信息。这种不合理的现象是由于训练集里不同类别文本之间的分布不均衡而造成的。因此必须调整在训练文本类别分布不均的条件下该模型的特征选择效率。
针对上述问题,考虑引入修正因子来调节由于文本集里不同类别之间文本的分布不均而造成互信息量不能正确反映特征项对文本类别的表达能力的问题。为了避免式(2)里各项之间正负项的相互抵消而引起的信息损失,将其改进为:
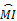


同时,大类别样本在赋权时其特征项占优,为此应该对大类别进行抑制。考虑特征项在不同类别内出现的频数差异,引入修正因子来调节由于文本集里不同类别之间文本的分布不均而造成互信息量特别是低频词相应的互信息不能正确反映特征项对文本类别的表达能力的现象。为此,记 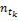
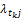
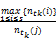
式(4)体现了tk随着类cj内文本数量变化而变化的趋势:对于训练文本集的一个具体类别cj来说,随着类内文本数的增加,权重 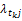
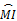

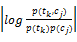
同时要注意这种方法有可能把一些低频的生僻词放入特征集合里。因此应该采取适当方法在使用这种特征选择方法时首先过滤掉生僻词,比如构造词典或者适当进行人工干预。
由此,通过对训练文本集进行分词处理,对得到的特征项集合S={t1,t2,…,tN}使用式(5)进行特征赋权,取权重最大的p<<N个特征项用于文本表示。这样将文本向量从N维降到了p<<N维。
将文本表示为由其特征项(通常以文本里的词或词组表示)权重为分量的向量形式,这种文本标引模型通常称为向量空间模型。向量空间模型以其语义完整、结构简单、易于数学处理而得到了广泛的应用,成为目前文本分类研究中用于文本表示的主流模式。但是该模式的一些固有缺陷影响了其对文本标引的效果。
作为文本结构化表示的主流模型,向量空间模型存在两个主要问题[ 9]:
(1)文本的向量表示带来的一个问题是文本向量维数太高,高维特征带来的困难是数据稀疏现象和计算开销问题。面对数千维甚至上万维的向量集合,一些常用的性能优越的文本分类器在高维特征空间内其性能常常急剧下降,而庞大的计算开销使得各种算法难以处理大规模文本集。
这个问题可以使用第2节提出的改进互信息方法进行降维处理得以解决。
(2)训练文本不同的类别分布所含有的类别信息差异在向量空间模型里没有或者很少得到体现。因为在向量空间模型下的相关技术研究主要集中在特征项的赋权方法上。此时训练集被表示成所谓文本-特征项矩阵A=(wij)p×n形式。其中,元素wij表示特征项ti在文本dj中的权重,i=1,2,…,p;j=1,2,…,n。文本最终被表现为由诸特征项相应的权重构成的文本向量dj=(w1j,w2j,…,wpj)T,向量的各个分量wij的取值是基于整个训练集而得到。因此这种向量形式的文本表示没有充分利用文本的类别信息。这一不足之处影响了向量空间模型对文本的标引能力,当训练文本类别分布发生倾斜时,这一问题尤为突出。
事实上,同一类别的文本之间的相似性较大,而不同类别的文本之间的相似性较弱。这一事实显示出不同类别之间的类别信息的差异,对判断待分类文本的类别归属的作用是不言而喻的。训练文本的类别分布常常是非均匀的,特别是基于Web的文本自动分类中类别偏斜问题尤为突出。一种普遍现象是:在大类中经常出现的特征,也许在小类别文本中很少出现甚至不出现。因此,从整个训练集角度出发所选择的特征集对训练文本进行标引,没有或者很少包含文本之间的类别差异的信息,最基本类别信息没有得到充分的利用。这种方式产生的一个现象是分类器常常向大类别样本倾斜而小类别样本被淹没。因此,有效利用训练样本的类别信息对文本进行表示成为提高文本标引能力的重要手段之一。
基于上述分析,将文本d的向量表示d=(w1,w2,…,wp)T形式改变为用矩阵形式进行表示:
d= 
其中,wij表示特征项ti(i=1,2,…,p)在第j类文本里的权重(j=1,2,…,s),这样列向量dk=(w1k,w2k,…,wpk)T则为文本d相对于第k个类别ck的标引。即:文本d在每个类别下都有相应的向量表示形式。权重wij(i=1,2,…,p)可以使用下式赋权:
wij=
其中,fik表示文本d的特征项ti在第j类训练文本里的频数,i=1,2,…,p; k=1,2,…,s。
这种以文本在各个类别下的类别属性度量为行向量的表示形式,不仅考虑了文本特征在训练集上的重要程度,同时考虑了文本在各个类别上的类别属性,体现了文本在不同类别之间标引上的差异。因此,这种以矩阵形式表示文本提高了特征项对文本的表示能力。
向量空间模型下整个训练集被表示成文本-特征项矩阵形式A=(wij)N×n。其中,N表示特征项个数,而n表示训练文本数。一般来说,对于规模在2 000篇左右的文本来说,特征向量的维数在10 000维左右。即使进行了特征选择,矩阵的阶数也在200×2 000左右。对于如此高阶的矩阵进行处理,无论是在速度、时间上还是内存上,普通的计算平台都难以承受。而在类别空间模型里,由于通常的文本分类中文本类别数只有10个左右,这样从模型上根本解决了矩阵的阶数过高问题。
在上述模式下,文本d在每个类别上都有相应的向量表示形式。此时需要对各个类别构造相应的类别特征向量。即对于每个类别以类别特征向量构造一个“伪文本”表示该类别,而待分类文本d的分类问题只需要计算d的各个列向量(在各个类别下文本的向量表示)与各个类别特征向量的相似度即可完成。
考虑在各个类别内使用合适的特征选择方法,从特征集T={t1,t2,…,tN}里选择相应的诸类别特征用于文本的矩阵表示,同时达到文本特征的降维目的。
式(5)是基于整个训练集的角度进行特征选择,用以表示待分类的文本。这种特征选择方式是基于各个类别信息的综合考量,不适合构造类别特征向量。由于式(1)考虑的是类别cj内的各个特征项与该类别的相互信息,度量的是该类别内各个特征项与类别cj的相互关联程度,因此使用式(1)进行类别特征选择能更好地体现该类别文本的类属信息。因此,使用式(1)计算类别cj内出现的所有特征项与cj的互信息MI(tk,cj)=log 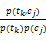
综上所述,提出一种基于类别空间模型的文本分类方法:
(1)对训练集进行预处理,分词、删除特高频词以及冷僻的特低频词、并剔除虚词、助词等得到特征项集合S={t1,t2,…,tN}。
(2)通过式(1)计算特征项在类别cj里的互信息MI(tk,cj);取其前p个最大值相应的特征项构成类别cj的类别文本向量,j=1,2,…,s,特征项的赋权使用常用的基于频数的TF-IDF因子计算[ 4],得到类别特征向量βj=(w1j,w2j,…,wpj)T,j=1,2,…,s。
(3)将文本d表示成矩阵形式:d=(wij)p×s。
其中,wij表示使用式(5)进行特征选择得到的p个特征项中的第i个特征项ti在第j类文本cj里相应的权重,使用式(6)进行赋权,i=1,2,…,p; j=1,2,…,s。
(4)计算矩阵d=(wij)p×s的第k个列向量dk=(w1k,w2k,…,wpk)T与第k个类别特征向量βk=( 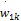

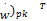
Sim(dk,βk)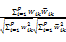
(5)假定j=arg[max{Sim(dk,βk),k=1,2,…,s}],则将文本d划入类cj内。
为了检验本文提出的分类方法的效果,同时使用机器学习领域常用的Naïve Bayes[ 10]分类器在相同的训练集和测试集进行了实验。Naïve Bayes是一种基于概率模型的算法,计算文本属于各个类别的后验概率,将文本划入后验概率最大的类别。
本文对上述文本分类模型的分类效果进行了实验。实验数据为从新浪、百度下载的2 130篇文本,其中分为经济(410篇)、环境(220篇)、体育(325篇)、计算机(420篇)、文艺(370篇)以及军事(385篇)共6类。实验采用4折交叉检验法,将2 130篇文本分为4份,3份为训练集,1份为测试集;每份轮流作为测试集循环测试共4次,取平均值为测试结果。使用东北大学自然语言处理实验室提供的分词软件(http://www.nlplab.com/download.html)进行分词,使用禁用词表过滤停用词、人工删除冷僻的特低频词,并剔除了虚词、助词、人称代词、特高频词等预处理后建立候选特征项集合得到特征个数N=6 217。使用式(1)计算特征项在类别里的互信息MI(tk,cj);取其前p=175个最大值相应的特征项构成类别cj的类别文本向量,类别数s=6;使用式(5)进行文本特征选择用于构造待分类文本d的特征向量,维数p=175。
分类效果评估指标使用常用的查准率、查全率以及F1测试值。
查准率=分类的正确文本数/实际分类文本数
查全率=分类的正确文本数/应有文本数
F1=(查准率×查全率×2)/(查准率+查全率)
将方法的实验数据放在统计表的下面,以下标NB表示,以示两者区别。
实验数据结果统计如表1所示:
| 表1 文本分类实验结果统计 |
从表1可以看出,本文提出的文本分类模型在经济、文艺、计算机类别的文本分类效果较好,环境类查准率略低一点,可能是由于该类文本数略少造成的。平均查准率、查全率与F1测度均在0.84左右,与经典的Naïve Bayes方法相比较,查准率提高了5.9%,查全率提高9.6%,F1测度提高7.6%,该模型的分类效果还是令人满意的。
特征降维的合理性和有效性是文本分类技术研究的核心问题,是制约文本分类效率的瓶颈。文本的基于类别信息的表示方法研究对提高文本标引能力是有益的。特征选择和特征抽取作为文本特征降维的两种主要模式在文本分类中已经得到了广泛的应用。两种方法各有其优点,同时也各自存在不足之处。如何有效地利用两类模型的优点,使之相互补充而提高特征降维的效率,考虑各种方法的组合型、混合型等方式的使用,同时对具体模型进行必要的改进使其更好地表示文本,这些工作的研究有待深入,这也是笔者今后要努力的方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|