


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于开源软件的中文学术文献计量软件的开发实践
[张云 ]
]
]
|
|


采用开源软件Lucene、IKAnalyzer、Luke进行中文学术文献计量软件的开发实践。介绍该软件的实现框架、数据准备、索引建立、自定义SemicolonAnalyzer分析器中的关键实现代码,并对该软件的不同计量效果进行分析。研究的主要目的是利用开源软件降低计量软件开发的复杂度,为研究人员提供一种自行开发中文学术文献计量软件的可行方法。
The paper develops a Chinese academic bibliometrics software based on the open source software such as Lucene, IKAnalyzer and Luke, introduces the implementation framework of this software, the work on how to prepare the data, the key codes in indexing and the analyzer named as SemicolonAnalyzer which is designed by the author. It also analyzes the different bibliometrics results of the software. The goal of the practice is to lower the complexities of coding by the open source software and to provide a feasible method of developing Chinese academic bibliometrics software.
科研人员为了解领域内的发展现状、确定研究课题或预测领域未来发展趋向,常常要在文献检索的基础上做一些初步统计工作,如对年发文量、发文期刊、发文作者、发文主题等的定量统计研究。目前适合研究者使用的中文开源学术文献计量软件较少,自行开发难度较大。本文介绍了基于开源软件进行中文学术文献计量软件的开发实践,即利用基于Java的系列开源软件,如全文索引/检索引擎Lucene、轻量级中文分词工具包IKAnalyzer、索引查看器Luke等进行中文学术计量软件的开发,在一定程度上降低了软件开发的复杂度。
目前,许多研究人员使用的中文学术文献计量的方式是半自动化方式,即利用Excel软件的排序、筛选、统计
等功能,结合手工处理来完成。这种研究方法的缺点是工作量大、容易出错、分析时信息粒度较大、不便于有效深入的定量统计研究,而且前期研究成果也不便于今后的重用。
国内一些学者积极地进行了定制化计量软件的开发尝试,如武汉大学信息资源研究中心的周春雷等人以CNKI中参考文献管理软件RefWorks提供的题录文件为数据来源,开发了CNKIRef的软件工具,实现了初步的文献计量功能[ 1]。南京理工大学经济管理学院的王曰芬等人利用PowerBuilder的前台开发软件、Sybase SQL Anywhere的数据库管理软件开发了实验性综合应用软件(SA),以对文献进行词频分析,并对文献外部特征进行数量统计[ 2]。
利用Excel结合手工方式进行定量统计,工作量大、易出错,而研究人员自行开发的软件又难以获得,因此本文提出一种基于开源软件的中文学术文献计量软件开发策略,主要目的是利用开源软件降低软件开发的复杂度,利用开源中文分词组件提高定量分析的质量,如采用Lucene降低索引生成的难度,采用IKAnalyzer提高中文分词的准确性,采用Luke简化计量统计工作。
为了便于今后的扩展,整个系统的框架分为4层,即显示层、业务逻辑层、数据访问层、数据层,各层中主要配置及功能说明如图1所示:
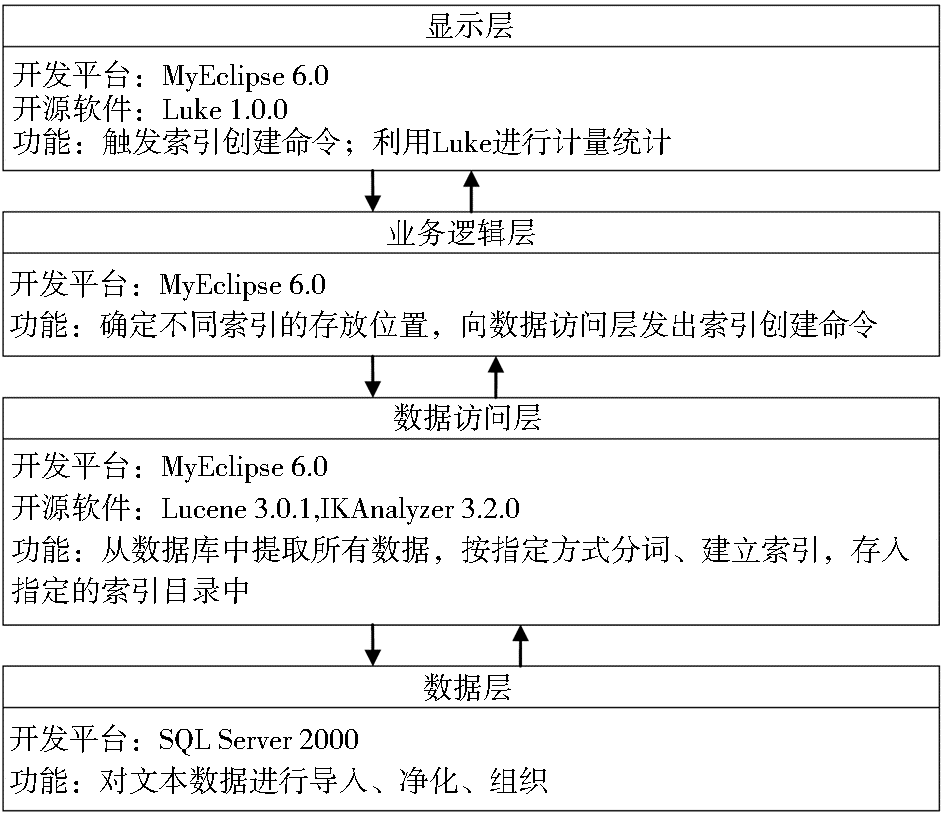 | 图1 系统总体实现架构 |
在显示层中,直接利用了开源软件Luke自身的统计功能以完成计量统计任务。Luke是一套开源的、可视化管理Lucene索引的软件。它能访问已存在的Lucene索引,并可按以下几种方式进行内容展示和修改,包括:检索高频词的排序列表;查看文档/拷贝至剪贴板;按文档编号或词进行文档浏览等[ 3]。在计量时笔者主要利用其高频词排序列表功能,选择待分析字段的部分或全部内容进行定量统计和展示。此外,其拷贝功能也便于研究人员将所得结果转入Excel中进一步处理。
在数据访问层中,选择Lucene简化索引建立步骤,并在Lucene索引建立过程中使用IKAnalyzer进行中文分词。
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎、部分文本分析引擎(英文与德文两种西方语言)[ 4]。选用Lucene的主要原因是简化开发步骤,便于根据需要进行文本分析接口的扩展。
IKAnalyzer是一个开源的、基于Java语言开发的轻量级的中文分词工具包。该组件具有多种优点,如采用“正向迭代最细粒度切分算法”,处理速度快;采用多子处理器分析模式,支持英文字母、数字、中文词汇等分词处理;优化的词典存储,支持用户词典扩展定义等[ 5]。选用IKAnalyzer的主要原因是期望通过该分词组件获得较理想的中文分词效果。
在反复实践中,笔者发现数据准备、程序编写是系统开发成功最为关键的两个方面。
本文选择了CNKI中的文献特征信息为数据来源,并进行了数据抽取、数据转化及清理工作,目的是将CNKI中的文献信息以固定格式导入到SQL Server 2000中。
(1)数据抽取
在数据抽取时,主要有以下几个方面的工作:
①主题确定
以CNKI中电子商务评价方面的文献为检索主题,确定了以中国学术期刊全文数据库为检索对象,以“模糊匹配”为检索模式,以1999年至2010年为检索时间范围,以主题为“电子商务”并且题名包含“评价”为检索点,共得到相关结果250条。
②计量统计指标选择
主要考虑常用且比较有分析价值的字段选择为主,由此确定了作者、题名、刊名、发表年、关键字、作者单位、基金7个字段。
③CNKI数据导出方式选择
为了便于对计量统计指标对应的字段数据进行有效导出,笔者分析了CNKI的几种导出格式,发现简单格式、引文格式、详细格式中包含字段较少,查新格式的字段无法满足设计的计量指标要求,CNKI输出的“RefWorks.txt”文件中则有记录格式不够规范的问题,这种不规范性增加了数据处理的工作量。最终选定自定义格式为主要的数据导出方式,在其中选择作者、文章题目等7个待分析字段。
(2)数据转换及清理
由于本文旨在利用开源软件并采用中文分词技术进行相关的文献计量统计工作,因此如何对中文文献数据进行转换特别是清理工作对于计量统计的结果有较大影响。
在数据转换时,首先将CNKI中以自定义方式导出的数据按50条记录一个文件的形式存放于Word中,将其转化为Word中的表格;然后将所有数据汇总复制到Excel中,形成一个总体文件;最后,利用SQL Server 2000企业管理器中的数据导入功能,完成数据向SQL Server的批量导入。
SQL Server导入数据时,有几种典型的噪音信息:第一种是每个字段值中均有字段名信息;第二种是部分字段中并无具体的字段值;第三种是部分字段中分隔标记不统一,如多值字段值中大多数以“;”为分隔符,但少量地方却使用了“,”为分隔符。为了对这些噪音信息进行处理,对第一种噪音信息采取删除方法,第二种噪音信息则设置了代表字符以统计空缺值的个数,如作者为空时设为“A1”,关键词为空时设为“K1”等。两种方式均采用了Update语句进行批量替换,其命令格式为:Update 表名 set 字段名=replace(字段名,‘替换前的值’,‘替换后的值’)。第三种噪音信息比较特殊,处理不当会影响正确的分词效果,而且量不是很大,主要进行手工修改。至此,得到了待分析的较干净的数据源。
在程序编写时主要按项目的显示层、业务逻辑层、数据访问层三层进行代码设计,其中显示层包括一个Index.jsp页面,主要功能是通过用户的点击,向业务逻辑层发出索引创建命令。业务逻辑层中有一个CNKIServlet.java文件,主要功能包括确定不同索引的存放位置,实现页面跳转,并向数据访问层发布按指定方式创建索引的命令。数据访问层中定义了一个CNKIDao.java文件,主要作用是从数据库中提取所有数据,按指定方式进行索引,并存入指定的索引目录中。下面主要介绍系统实现中最为关键的两部分,即数据访问层中索引建立以及为了改进分词效果设计的分号分析器的实现细节。
(1)索引的建立
由于采用了开源软件Lucene,索引建立时只需要调用Lucene公用API的几个方法即可完成。Lucene建立索引的步骤包括:将数据转换成Lucene能够处理的文件格式——纯文本字符流;分析,即将文本数据切分成一些大块或者词汇单元,按所用的分析器的要求对这些文本进行一些操作;将分析过后的数据写入索引中[ 6]。Lucene索引核心类的工作流程如图2所示:
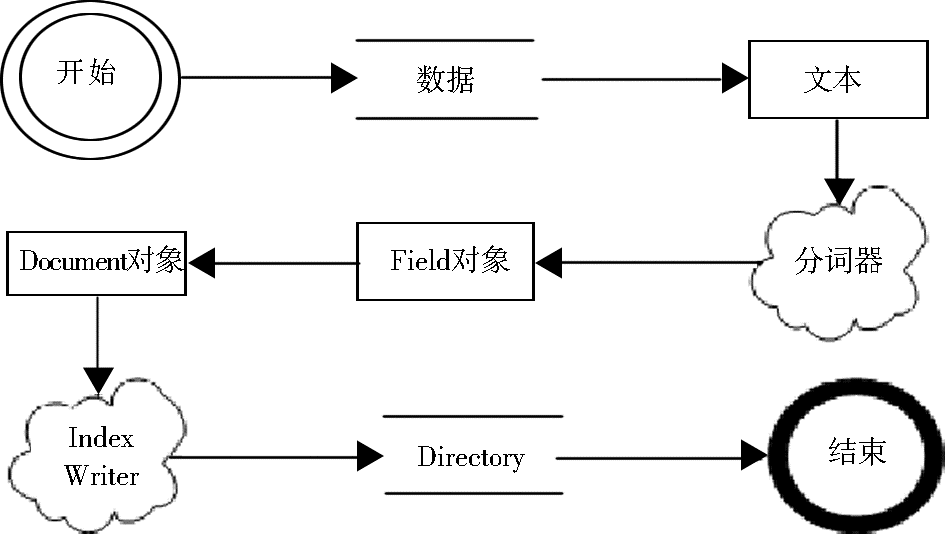 | 图2 Lucene索引核心类工作流程图[ 7] |
索引建立时的主要代码如下:
analyzer = new IKAnalyzer();//指定使用的分析器为IKAnalyzer
String sql = "select * from myresult$";//指定从SQL Server中提取数据的SQL语句
IndexWriter iwriter = new IndexWriter(dir, analyzer, true, IndexWriter.MaxFieldLength.UNLIMITED); //获取一个IndexWriter实例,并进行初始化
ResultSet rs = connection.executeQuery(sql);
while (rs.next()) {
Document doc = new Document();
doc.add(new Field("author", rs.getString("author"), Field.Store.YES, Field.Index.NOT_ANALYZED));//将SQL Server中每条记录的作者字段的字段值以存储、并不索引的方式放入Document中指定的Field中
...
iwriter.addDocument(doc);//向索引中添加已建好的Document
}
iwriter.close();//关闭索引器,将所有在缓存中的数据写入磁盘上,关闭各种流
(2)分词技术的处理与改进
为了提高计量效果,对于不同字段进行了不同的分词、索引处理,即将不同字段按计量特征进行使用分析器或不使用分析器的索引处理,如:
doc.add(new Field("keyword", rs.getString("keyword"),Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.add(new Field("keyword_token", rs.getString("keyword"),Field.Store.YES, Field.Index.ANALYZED));
其中,第一句为不使用分析器进行索引的字段处理,第二句为使用分析器进行索引的字段处理。
在对关键词、作者字段分析并索引时,笔者发现IKAnalyzer的分词效果并不是很理想。CNKI中自定义格式导出的多值类文献特征信息常以分号分隔多个不同选项,因此开发了分号分析器,包括两个类:SemicolonTokenizer类,主要作用是依次分析文本,并按分号将文本分成一个个token;SemicolonAnalyzer类则是利用SemicolonTokenizer类在分号处进行词汇单元的切分。其中SemicolonTokenizer类中提取分隔符的关键代码如下:
protected boolean isTokenChar(char c) {
if (c==';')
{return false;}
Else
{return true;}
}
索引建立成功后,利用Luke打开指定位置的索引文件,修改其“number of top terms”中的参数值,点击“show top terms”按钮,可观察到使用不同分词、索引技术后得到的计量统计结果。
实验结果表明,对于出版年字段、期刊名字段采用仅索引但不使用分析器的方法,计量效果较好。以年发文量统计为例,Luke中前12条记录清晰地显示出各年的统计数据,如2009年66篇,2008年48篇,从2000年至2009年电子商务评价论文呈逐年增长趋势,其效果如图3所示:
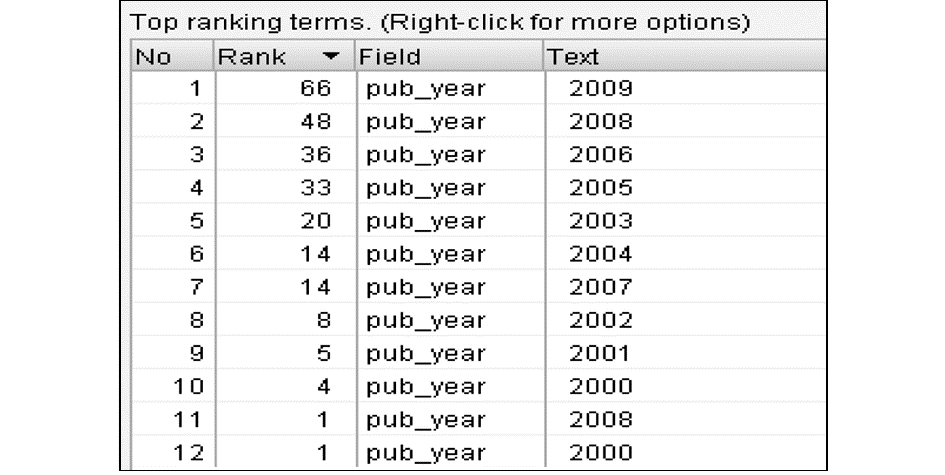 | 图3 年发文量统计结果 |
在对关键词进行计量统计时,采用了4种方式,即不使用分析器进行索引、使用IKAnalyzer进行分析并建立索引、使用极易分词组件进行分析并建立索引、以及使用SemicolonAnalyzer进行分析并建立索引。实验结果表明,使用IKAnalyzer、极易分词组件得到的分词效果均不是很理想,主要原因是这两种分析器对于自定义的关键词识别度不够;但采用SemicolonAnalyzer分析器后,效果有明显改进,其对比结果如图4、图5所示。SemicolonAnalyzer分析器是基于CNKI导出格式的特殊性而设计的,使用效果较好。如果对分词结果进一步加工,可用于进行专业领域内关键词、作者词典的建设。
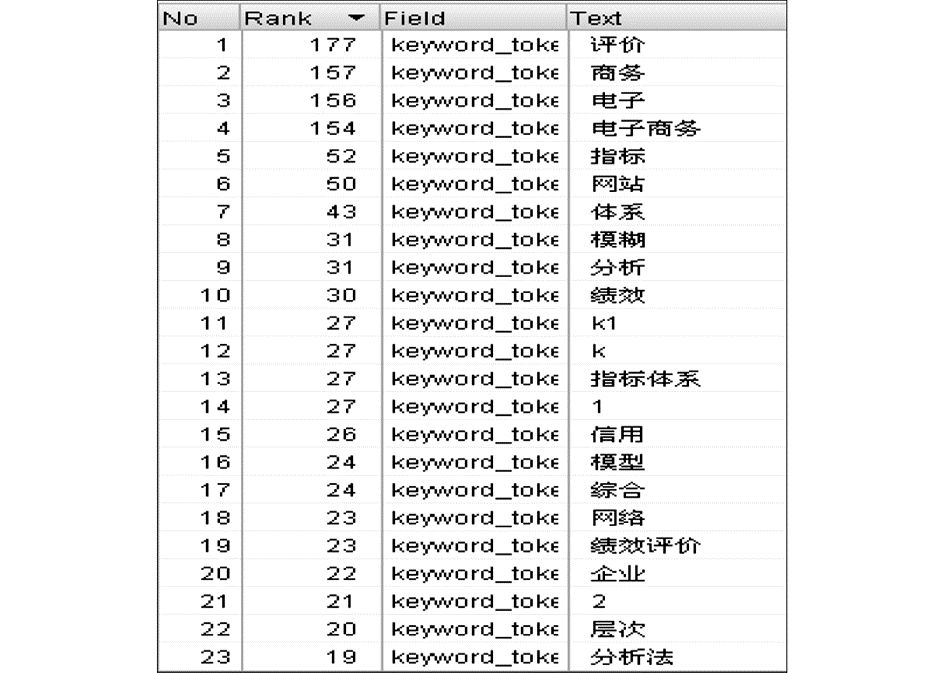 | 图4 使用IKAnalyzer分析器进行索引的 |
关键词统计结果
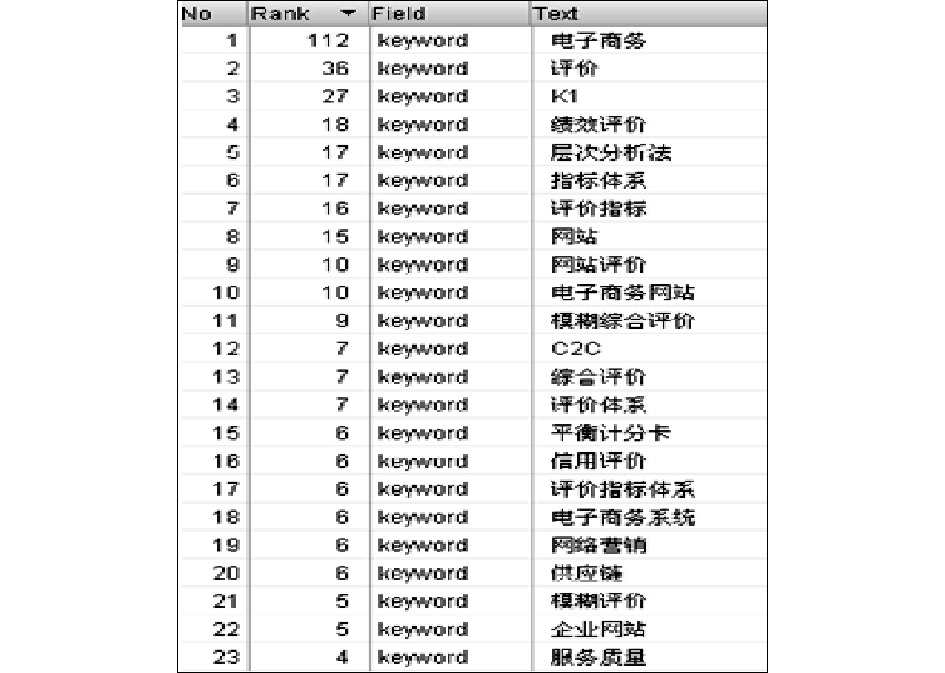 | 图5 使用Semicolon分析器进行索引的关键词统计结果 |
实验中笔者还发现对于单位、基金两个字段使用上述几种分词、索引处理方式,分词及计量效果均不理想,其原因是著录规则不统一,分析出来的结果较凌乱,难以直接进行有效的计量统计。但如果利用SemicolonAnalyzer的初步分析结果,加上适当的人工干预,并建立辅助的研究单位词典、基金项目词典,则分词、计量效果会显著提高。
开源软件的使用,为研究人员进行中文学术文献计量软件的自行开发提供了一条新的可行的方法,其主要特点是利用开源软件降低代码编写的复杂度,如
采用Lucene使得索引建立的代码编写工作仅需要简单几条语句,调用Lucene公用API的几个方法即可,而采用Luke则使研究人员省去了计量、统计代码的编写工作。但在实践过程中也发现,要进一步提高计量统计的效果,还需要进行研究机构、基金项目等专门词典的建设与开发。此外,如何利用开源软件实现中文文献中词语共现、参考文献间引用关系等的计量统计功能还有待进一步研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|