{kind=link}
{kind=link}
MeSH词表的语义相似度计算研究
[孙海霞, 钱庆 , 吴英杰, 李军莲]
, 吴英杰, 李军莲]
, 吴英杰, 李军莲]
|
|


Based on Rodriguez and Egenhofer’s semantic similarity measuring, combing with the characteristics of MeSH,this paper puts forward a semantic similarity measuring of MeSH,and the experiment result shows that this method is effective.
词语语义相似度是对两个词语所表达的概念内涵之间相似紧密程度或关联程度的一种度量,它可以将概念词间语义关系量化,表现为具体数值,以对不同关联程度的概念进行区分,在信息检索、信息推荐和过滤、数据挖掘、机器翻译等领域有着广泛的应用,已成为当今信息技术研究的一个热点[ 1]。
语义词典能够揭示其收录词条的概念内涵和语义关系,已成为计算词语语义相似度的主要基础资源。利用语义词典来计算词语语义相似度的基础是两个概念词间具有一定的语义相关性,它们在概念间的结构层次网络图中存在一条路径,计算效果则依赖于所用语义词典的完备性[ 2]。具体来讲,主要是利用语义词典中的同义词和树状层次体系结构,即词语在树中所处的位置、属性、上下位节点等语义特征项,通过计算两个词语所表达的概念之间的共享信息内容、在树中的路径距离、以及共同属性项来计算词语间的语义相似度[ 2, 3, 4, 5, 6, 7]。目前,基于语义词典的词语语义相似度计算的研究主要基于通用语义词典进行,如WordNet和知网(HowNet)。
《医学主题词表》(Medical Subject Headings,MeSH)[ 8]是美国国立医学图书馆编制的权威性主题词表,是一部规范化的可扩充的动态性叙词表。在医学文献检索系统中,MeSH主要起规范主题词、使标引者和检索者在用词上达到尽可能的一致及联系检索者与IM 主题索引的作用,是标引和检索医学文献的依据。基于MeSH主题词表的权威性和应用的广泛性,许多学者将MeSH称为医学领域的本体。本文在借鉴Rodriguez和Egenhofer的语义相似度计算模型的基础上,结合医学领域主题词表MeSH的特点,提出了MeSH词表的语义相似度计算方法并予以实证,其实验结果表现较佳。
(1)MeSH主题词的种类
MeSH是依叙词法编制而成,而叙词法是在吸取元词法、标题法及分面组配式分类法等情报检索语言优点的基础上产生、发展的一种现代高级检索语言[ 9]。因此,MeSH主题词在种类上既有反映单一概念的单元词用于后组标引或检索,又有相当数量的反映复合概念的先组词用以提高标引的一致性和专指性,并依据单元词法的组配原理和组配分类法的概念组配,以表达或描述现代生物医学各领域文献中的主题[ 10]。
(2)MeSH主题词描述
在MeSH中,每一个主题词下设该主题词的树状结构编码(Tree Number)、主题范围(Scope Note)、入口词(Entry Term)、建立的年代、历史注释及各种参照系统等来揭示主题词的历史变迁、族性类别及同其他词之间的逻辑关系。其中的树状结构编码能够揭示主题词所属学科分类树(族性类别)、在学科分类树中的位置(深度)、与其他主题词的上下位层次关系。入口词也称为款目词,是主题词的同义词、近义词、缩写、不同的拼写形式及其他用代形式。在MeSH中,一个主题词可以对应多个入口词,但一个入口词只能对应一个主题词。注释(Scope Note) 是对主题词所揭示的概念范畴的描述。
从宏观角度来看,MeSH词表由三个部分组成:主题词变更表、主题法字顺表和分类法范畴表(树状结构表)。其中,MeSH树状结构表是一种分类体系,它将主题词及一些非主题词按其所属的学科体系和逻辑关系分类排列,将它们归入15大类,即15棵分类树,分别用A、B、C等字母表示。有的大类按需要再进一步划分为一级类、二级类,最多分至9级。树状结构的每个类目中,主题词按等级从上位词到下位词逐级编排,表达主题词之间的逻辑隶属关系。MeSH主题词表树状结构的一个片段[ 11] 如图1所示:
 | 图1MeSH树状结构示意图 |
公式(1)是Rodriguez和Egenhofer提出的语义相似度计算模型,基本思想是通过计算两个概念词的同义词集(Synonym Sets)相似度、语义邻结点(Semantic Neighborhoods)相似度和区别特征项(Distinguishing Features)相似度来计算其语义相似度。
S(ap,bq)=wwSw(ap,bq)+wuSu(ap,bq)+wnSn(ap,bq) (1)
其中,ww、wu、wn≥0,分别表示同义词集、特征项、语义邻结点间相似度对整体相似度的贡献大小,且ww+wu+wn=1。ap表示概念词a属于本体p,bq表示概念词b属于本体q。函数Sw、Su和Sn用来计算概念词a和b的同义词集、特征项、语义邻结点间相似度,采用词集合相似度计算方法中的集合运算模型。
之所以将Rodriguez & Egenhofer计算模型作为借鉴模型,主要是因为该方法适合跨本体语义相似度计算,即适合计算不同概念树中主题词之间的语义相似度,符合MeSH有多棵学科分类树的特点。
结合MeSH主题词表概念语义信息揭示特点,选择通过入口词、注释和上下位主题词三个语义特征项计算MeSH主题词表中两个概念主题词间的语义相似度,如下所示:
Ssemantic (a,b) = wet Set ( 
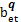
wscope Sscope( 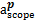
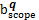
wnm Snm( 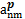
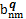
其中:a和b表示被比较MeSH主题词,aet和bet分别表示a和b的入口词集合,ascope和bscope分别表示a和b的注释集合,anm和bnm分别表示a和b的直接上下位主题词集合,p和q分别表示a和b所在学科分类树,Ssemantic(a,b) 表示a和b的语义相似度,Set ( 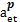
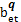
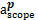
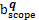
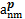
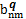
Sim(A, B)=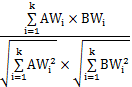
其中,AWi表示词项Wi在词集合向量A中的权重,BWi表示词项Wi在目标字符串向量B中的权重,一个词的权值即为其在当前集合中出现的次数,k表示向量A和B的维数,是动态变化的,由被比较集合并集中所含的不同词的个数决定,即:
k =|A|+|B|-|A∩B| (4)
关于Set、Sscope和Snm的计算,之所以不选用Rodriguez & Egenhofer计算模型中所采用的集合运算模型,主要是因为集合运算模型没有考虑某词项出现的次数对词集合相似度值的影响,而就语义理解的角度来说,词项在某集合中出现的次数在一定程度上能够反映该词项对该集合的贡献大小。
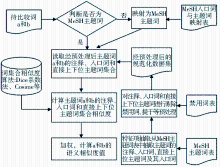
测试数据是Angelos Hliaoutakis等人采用的32对主题词[ 14],入口词、注释和直接上下位主题词的抽取与预处理是基于MeSH 2008版进行。算法流程主要分为数据预处理、概念映射、词集合相似度计算、加权与结果输出4个步骤,如图2所示:
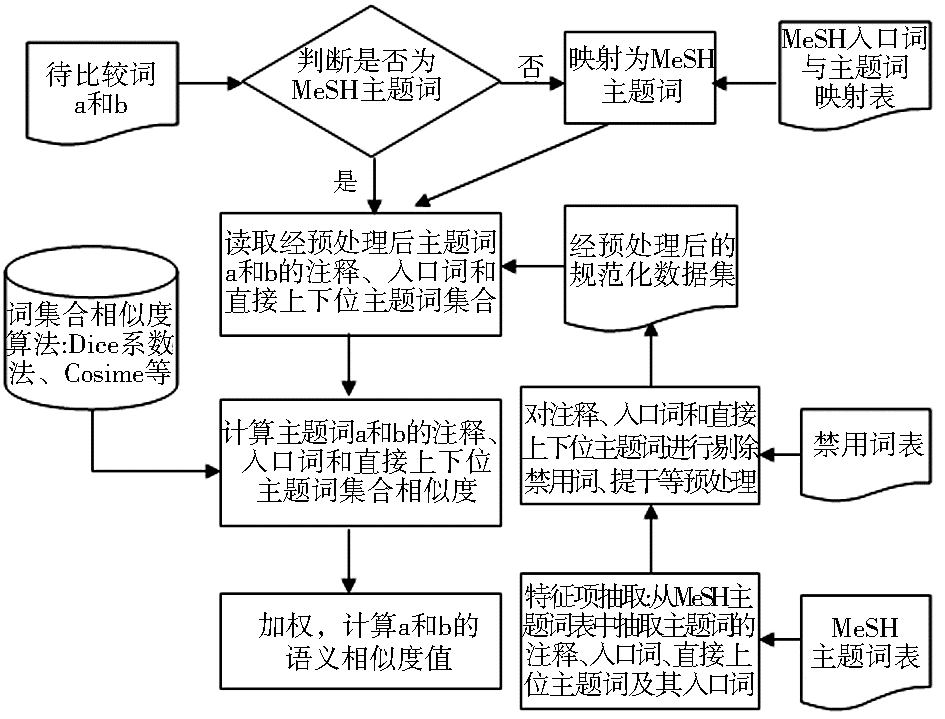 | 图2算法实现流程 |
关于禁用词表,经比较测试,选择中国医学科学院医学信息研究所构建的医学禁用词表;关于提干算法,采用现有比较成熟的滚雪球算法(Snowball Stemmer)[ 15];为了验证某词项出现的次数对词集合相似度值的影响程度,除了余弦相似度法,还选用了Jaccard系数法[ 15]、Rodriguez & Egenhofer所用的方法[ 12]和Dice系数法[ 16]参与测试分析;关于权重值设置,经多次测试,表明在权重之和为1的条件下,当wet:wnm:wscope为3:1:2时效果最佳;关于结果评估,分别采用Pearson积差相关系数[ 17]和Kendall等级相关系数[ 18],计算其与人工主观判断结果间的关联程度。
Pearsons积差相关系数:假设有两个变量X和Y,与之对应的均值变量 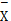
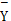
r=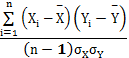
其中,X和Y分别代表各算法计算的相似度结果和人工评估的相似度结果。
Kendall等级相关系数:假设给定两条阶次序列X={x1,x2,…,xn}和Y={y1,y2,…,yn},则Kendall等级相关系数为:
τ=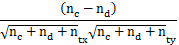
其中:
Nc=∣{(i,j)∣xi﹥xj且yi﹥yj,1≤i﹤j≤n}∣+∣{(i,j)∣xi﹤xj且yi﹤yj,1≤i﹤j≤n}∣
Nd=∣{(i,j)∣xi﹥xj且yi﹤yj,1≤i﹤j≤n}∣+∣{(i,j)∣xi﹤xj且yi﹥yj,1≤i﹤j≤n}∣
Ntx=∣{(i,j)∣xi=xj,1≤i﹤j≤n}∣
Nty=∣{(i,j)∣yi=yj,1≤i﹤j≤n}∣
表1是wet:wnm:wscope为3:1:2时的32对主题词的语义相似度计算结果。
| 表1 wet:wnm:wscope为3:1:2时获得的语义相似度值 |
其中:H表示人工评估结果;Dice、Jaccard和 Rodriguez & Egenhofer分别表示利用Dice系数法、Jaccard法和Rodriguez和Egenhofer所采用的词集合相似度计算方法获得的结果,未考虑词项在集合中出现的次数对词集合相似度的影响;Cosine表示基于向量空间模型,利用余弦相似度法计算词对相似度时获得的计算结果,考虑了词项在集合中出现的次数对词集合相似度的影响。
表2是采用Pearson积差相关系数和Kendall等级相关系数对wet:wnm:wscope为3:1:2时32对主题词的语义相似度计算结果与人工主观判定结果关联程度的评估结果。
| 表2 wet:wnm:wscope为3:1:2时相关度评估结果 |
(1)虽然语义相似度计算值与人工主观判定结果相比,绝对值偏小,但就相关系数值来看,无论是Pearson积差相关系数还是Kendall等级相关系数,其相关度均表现较佳。
(2)就词集合相似度计算模型的选择来看,无论是基于何种预处理方案,也无论是Pearson积差相关系数还是Kendall等级相关系数,利用Cosine词集合相似度算法获得的语义相似度值与人工评估结果的相关度显著高于其他算法。这表明,与Rodriguez和Egenhofer提出的计算模型相比,本文关于词集合相似度计算的优化选择是正确的。
本文在借鉴Rodriguez和Egenhofer提出的语义相似度计算模型基础上,结合医学领域主题词表MeSH的特点,首次重点从语义特征项的选择、词集合相似度计算模型着手,提出了MeSH主题词表中词语语义相似度计算方法,且实验结果表现较佳。目前采用的评估方法是与人类的主观判断结果进行关联分析比较评估,而一种技术的优劣,关键是其在应用中的表现,因此,笔者将进一步考察其在查询扩展或文献聚类等方面的实际应用表现,从实用的角度对其作出评判和优化探索。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|