



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
用于计算机辅助文献标引加工系统的自然语言词表构建
[杨贺1, 2 , 杨奕虹1, 2  , 乔晓东
, 乔晓东1 , 李宁2 , 朱礼军1 ]
, 乔晓东|
|


讨论计算机辅助标引文献加工系统中自然语言词表系统的建立过程。基于海量文献人工标引,运用计量分析法对多年来积累的人工标引词从词频、词长、词类型、词共现等多方面进行分析,重点阐述运用字面相似度计算词间关系来建立适用于机标和后控词表的自然语言词表的过程。
The paper mainly discusses the construction of natural language thesauri for automatic assistant indexing literature system. Based on years of massive manual indexing keywords, it analyzes the rules of word frequency, length, type, co-occurrence, and proposes a method for constructing a thesauri of automatic assistant indexing and post controlled vocabulary.
本文的研究内容是计算机辅助文献标引加工系统(简称机标系统)中词表建设的一部分,旨在通过提取多年来海量文献中的人工标引关键词,采用计算机辅助算法,建立词间关系,构建一部自然语言词表,用于辅助机标系统工作,提高文献标引效率和一致性,降低人工标引的工作量和主观性错误。
传统词表修订是一项耗时费力的知识密集型劳动。在目前文献信息迅猛增长的环境里,传统词表在应用过程中衰老的速度远远比修订的速度快。然而也恰恰是在当前词表不能满足要求的情况下,反而凸显了词表的价值,其应用正在从沉寂转向热门,不加以限制地滥用自由词终会导致检索迷失。因此积极推进自然语言与传统叙词表的结合,制作出自然语言词表便是当前的工作目标。
自然语言词表指含有自然语言成分的各种词表,或者说自然语言应用于情报检索所需的各种词表[ 1]。这种含有自然语言成分的词表仅作少量控制,它区别于传统的叙词表,无需将标引人员或用户使用的自然语言转换成规范化的、人工语言编制的系统语言,可以充分展示自然语言在网络环境下通用性好、标引方便的优势。具体到标引来说,它大量使用作者自身的用词,不存在受控词汇或类目滞后的问题;可随时增加新词;对标引员的专业素质要求较低、标引速度快,大大降低了标引员的劳动,易实现自动标引[ 2]。在检索方面,自由词的使用也符合用户的思维习惯,调查发现,普通用户对于上位词和下位词比较陌生,需要检索系统为他们提供检索词调整方面的帮助[ 3]。
现已出版的叙词表老化情况严重,国内从20世纪50年代、60年代开始编纂的行业/学科或综合词表至今大约有100多部,目前除了极少数词表尚在定期维护出版之外,其他绝大部分的词表都已经不能在实际工作中直接应用。而且几家比较知名的词表建设单位(多为各行业的信息情报所)目前也没有重修再版词表的计划。
在这样的前提下,本文提出研究构建一部可供机标、检索应用的自然语言词表,即一部拥有传统叙词表框架,由自然语言组成的、有立体关系的词表。
词表以万方数据公司《中国学位论文数据库》的人工标引词为数据基础。截止到2010年1月,该库共收录论文110万篇,学科以理、工、农、医、生物为主,涵盖人文社科。每篇论文规定标引3-8个关键词,由人工标引审核完成,保证了基础词汇的质量。课题组选取了截止到2008年11月底的930 849篇人工标引审核完毕的文摘数据库作为基础数据加以分析。
基础数据库的元数据结构包括:馆藏号(每篇论文拥有唯一馆藏号)、题名、关键词、分类号、授予学位年代。论文授予学位时间从1981年-2008年,主要集中分布在1999年-2007年,保证目标关键词具有时代意义。
统计之前,需将基础数据库中每篇论文的关键词词串一一拆开,保持元数据结构不变,形成一个馆藏号对应一个关键词的记录集,如图1所示。下文称此记录集为DATA1,共有4 487 005条记录。
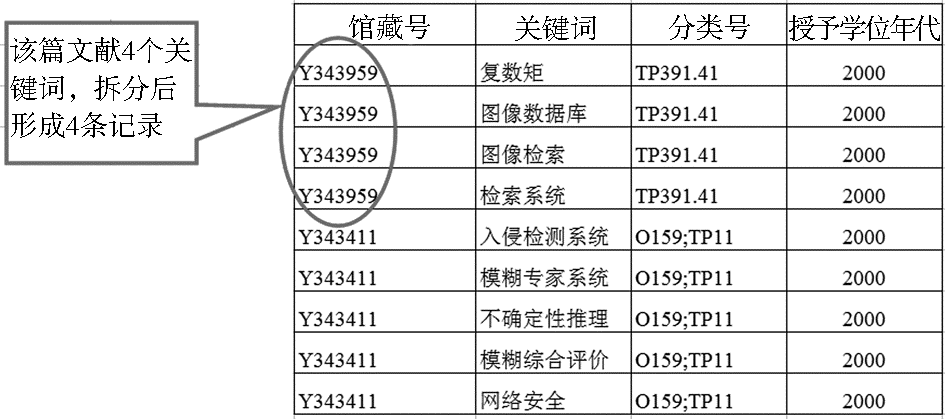 | 图1 基础数据库拆分关键词图示 |
通过对基础词表的词频次、词长、词类型、词共现4方面的统计分析,为计算词间关系做基础工作,可以减少部分词量、降低词噪音,为下一步工作做准备。
(1)关键词频次
DATA1统计基础词表关键词总量为1 094 881个,总频次为4 487 005次,按出现频次分组统计关键词,如图2所示。因为基础词表中的关键词均是人工标引得来,不能以一般意义上的低/高频词的办法处理,这里的频次可视为用户的认可度,在建设自然语言词表中可作为区分主题词和入口词的依据。
 | 图2 按频次分组统计关键词 |
(2)关键词长度
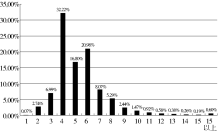
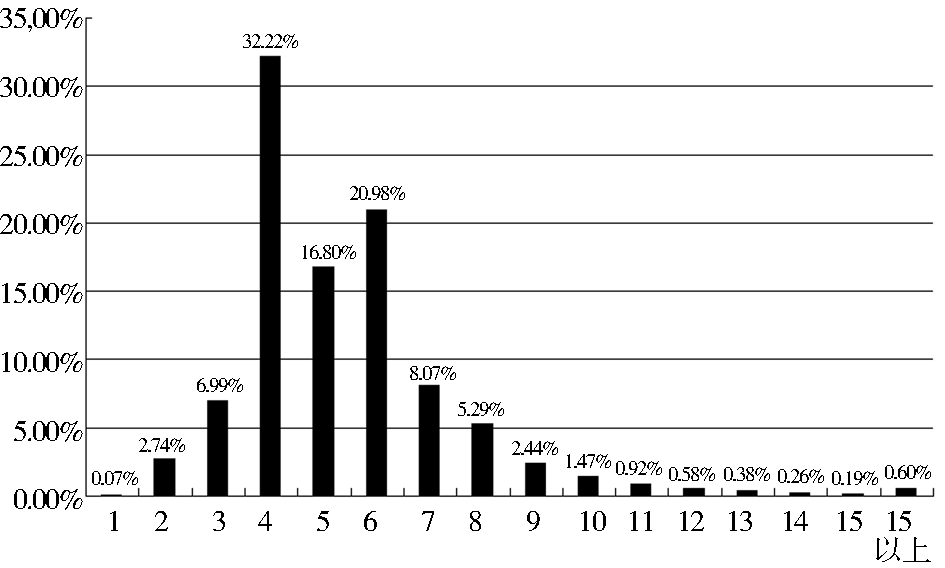
词长的统计可命中超短或超长词,基础词表中各长度关键词个数百分比如图3所示。统计中将1个中文字符或1个英文字符或1个符号均记为1个词长,如“(1→3)-β-D-葡聚糖”长度记为13。
 | 图3 按长度分组统计关键词 |
图3显示,约70%的关键词集中在词长4-6个字符的区间中,以4个字长的个数最多。长度为1的关键词多为动物名称和化学元素名称,如猪(621次)、镉(278次)。关键词最长的为79,是一个英文字符串“(Surface Enhanced Laser Desorption/Ionization-time of flight-mass spectrometry)”。纯汉字关键词(即不含标点符号和英文字符及其他字符)最长的是“交替同时最小化对角矩阵误差及协变矩阵误差算法”,计22个字符。
(3)关键词词类型
基础词表中词的组成元素有符号、字母、数字、汉字,这4者相互交叉组合,造成了词类型多样化。各类型词及例词如表1所示:
| 表1 基础词表词类型统计及举例 |
研究关键词的组成类型有两种用途:
①有助于规范自然语言词表,因为符号、字母缩写、大小写、数字格式等多种表达方式,导致了很多同义异型词,如表2所示。处理这部分词的词间关系时,可参考词频设置主题词和入口词,避免过多的同义词混淆于关系计算中。
| 表2 基础词表中部分同义异型关键词举例 |
②有助于修正机标系统对汉字夹杂特殊符号、数字或西文字母等混合型词汇的兼容性,包括建立起算法所需的英文字符字典和数字数学符号字典等辅助工具[ 4]。
(4)关键词共现
将基础词库按照出现在同一篇论文中的要求拆分成两两组合的词对,统计共有词对7 710 059对,总频次13 341 968次,平均每个词对1.73次。词对按频次分组统计如图4所示。高频词对如“数据仓库;数据挖掘”出现945次,“关联规则;数据挖掘”出现871次等。
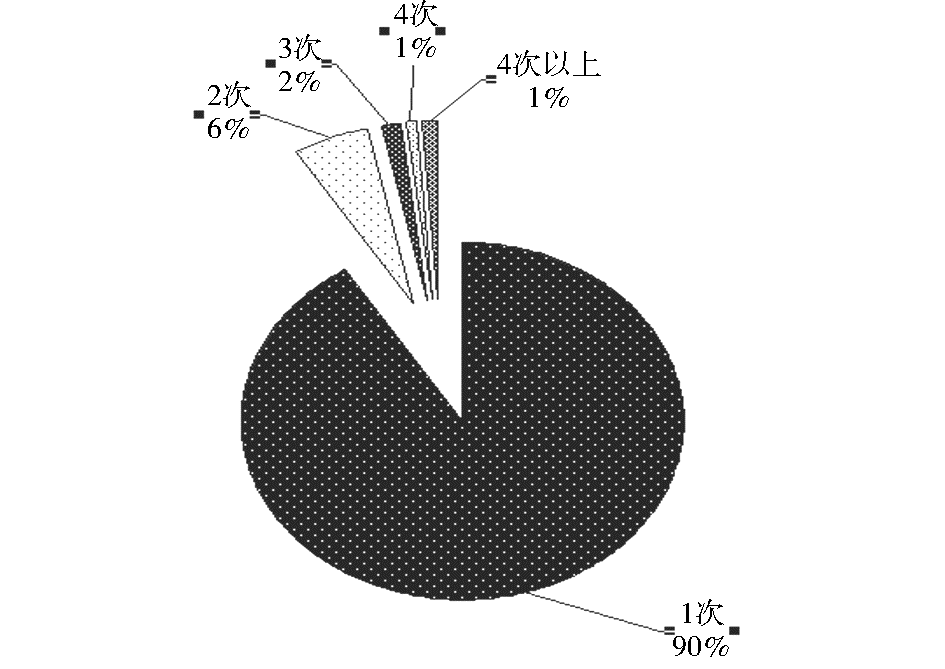 | 图4 词对频次分组统计图 |
有学者研究,两个词在文献中共现频度越高,形成同义、近义和相关关系的可能性越大[ 5],词共现分析法(共词分析法)即基于这个思想衍生出来的[ 6]。以此方法确认词间关系虽然简单方便,却并不全面,只能反映出相关的词关系,而且频次大于两次的总词对个数仅占总数的10%(见图4),即绝大多数词不能通过高频共现的方式确认词间关系,因此本方法只能作为辅助手段。
根据基础词汇的4种统计分析,暂时将部分超短、超长且低频词、非汉字词等放入待定词库,以便日后处理。其余词共计约95万,将作为下一步工作的主要目标来建立词间关系。
叙词表的词间关系包括等同、等级和相关三种关系,鉴于人工编表的困难,国内外学者就计算机辅助识别词间关系展开了诸多研究[ 7, 8],探索了如同义词词典法[ 9, 10]、模式匹配识别法[ 11]、词共现分析法[ 6, 12]、字面相似度算法[ 13]、词聚类算法[ 14]、相关度算法[ 15]、概念空间法[ 16, 17]、基于《知网》的语义范畴代码法[ 18]等。上述方法的运用极大地减轻了人工修、建词表的工作量,但还没有方法能够完全取代人工。
在前人研究的基础上,选用字面相似度算法,结合现有叙词表,通过统计计算和可视化分析,形成自然语言词表的雏形后提交人工修订,运用计算机辅助的方法最大限度地降低人工工作量。
可以利用两类工具词表简化工作:
(1)利用已出版叙词表
传统叙词表中词关系建立完善,“用、代、属、分、参、族”的关系均是经过各界专家反复推敲验证的,知识含量极高,是目前各种计算机辅助方法所无法比拟的。将现有各种叙词表电子化后与基础词表查重,命中词本身之间参照叙词表就具备了一定的词语关系,而在关系计算中,这部分词将提高对待级别,辅助判断计算过程中各种参数选择的恰当性。
(2)利用辅助词表
除上述已经出版发行的各专业、综合词表外,还可利用一些辅助词表,包括:地名、国名、民族、通用人名、朝代、企业名称、高校与科研机构名称、国家管理机构名称、基金名称等专有名称库,敏感词表(包括有关国家机密的、敏感的词语),停用词表(包括专指度或区分性低的不适用于文献标引的词)。以上这些辅助词表中的词均不需要参加词间关系计算。
(1)算法简介
字面相似度算法有两种:以单个汉字为基本单位进行的字面相似度计算和以词素为基本单位的计算。以汉字为基本单位的算法因不符合中文词语语义表达的特点,经大量实践证明效果不佳,因此只选用以词素为基本单位的计算方法。以宋明亮[ 5]、吴志强[ 19]、朱毅华[ 20]等人的研究成果为基础,在大规模自然语言词语的前提下,通过大量计算和人工判别,最终决定选用朱毅华的计算公式[ 20]:
xsd= 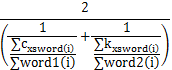
其中:xsword(i)表示word1和word2中相同词素所在位置;∑word1(i)表示word1所含总词素的位置之和;∑word2(i)表示word2所含总词素的位置之和;∑ 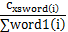

以“细胞癌”和“上皮细胞癌”两词为例,切分词素后变为“细胞;癌”和“上皮;细胞;癌”,计算结果为:
xsd= 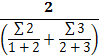
上述算法中,xsd取值区间为[0,1],值越大,说明两词关系越近。当xsd=1时,表示两词为等同关系,如早期食管癌和食管早期癌、卵巢上皮性癌和上皮性卵巢癌;当xsd=0时,表示两个词毫无关系。
(2)数据测试及树状关系图
如果以上述公式计算近百万条的目标词汇,运算量级将达1011,这样做既耗费大量的计算机资源,也不具备实际意义,因为相当数量的词彼此之间没有任何相同词素,即便有,计算结果也没有意义。宋明亮在研究中曾经提到过同语素词语族(简称同素族)的概念[ 5],即“成群的或若干个不同词语单位,由于含有同样一个语素,而彼此在意义上互相关联”,并且提到“许多叙词表中的词族绝大部分是由同素族构成”。基于此理论,预先将目标词汇根据汉语词汇构成重心后移的特点,进行后方一致的倒序排列,由此形成若干个同素族词汇,只计算同素族词之间的关系,以降低计算量。
选择基础词表中“细胞癌”的同素族词共计90个词关系计算,90个词之间的相似度计算结果共4 005条,部分内容如表3所示:
| 表3 “细胞癌”同素族词间关系计算结果(节选) |
为进一步区分词表中词间的层级关系,设计了可视化程序,将表3计算结果转化成树状关系图,如图5所示。图5中树状图的层级关系并非词表关系中严格意义上的属、分关系,而是根据实际使用需要,按照算法原理将平面化的词关系立体化的一种手段。从实践效果来看,这种方法确实有助于减少人工建表的工作量。
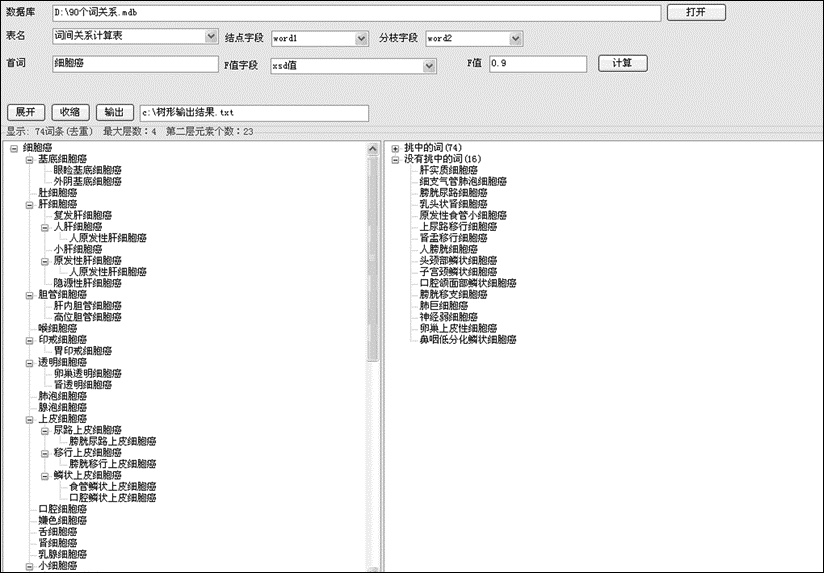 | 图5 词间关系树形图 |
区分层间关系时,需定义阈值F,它的作用原理是:设定首词和F值后,以首词为基准点,判断与其相似度xsd值大于等于F的词作为下一级,否则结束,另取第二层中的词逐个依次判断。树状关系中,同层词可以重复,上下层之间不可重复。首词相当于族词的概念,但并不等同于族词,这与选取同素族词的粒度大小有关。
研究过程中引入了4个参数辅助判断词间关系树及F值质量:词族总词数N、遗漏词M、最大层数L和第二层词汇数X2。其中,N指待计算的词族所含的全部词个数,遗漏词M指经过可视化程序后没有计入树状关系中的词量。在图5中,左侧栏中显示了涵盖入树状关系的词汇,右侧栏中显示了没有涵盖入树状关系的词汇。在词间关系正确的基础上,(N-M)值越大越好。最大层数L是指整个树状关系中最深的层数,首词记为第一层,根据阈值的界限,依次递降层级关系。第二层词个数X2是指首词之下的那一层词汇总数,这层词汇的确定基本奠定了词间关系的大体框架。该层词汇数量过多会导致整组词关系扁平化,从而L值会较小;反之,X2小,L值也不一定大,因为阈值的调节,M值可能会增大。
(3)应用于海量词间关系建立的算法改进
依据上述方法计算海量词间关系时,存在两个问题:F值需人为输入,且取值缺乏依据;发现同素族词中的词数量越多,词间关系越复杂,单一的F值就越难以控制。因此,将上述算法应用于海量词间关系计算前还需增加限制条件。
①阈值设定
| 表4 词间xsd值统计表 |
经研究分析,发现阈值F与xsd值本身的变化规律非常密切,更确切地讲,是与两词比较中可能出现的最大xsd值相关。表4模拟了一个拥有1-4个词素的同族词的最大xsd值统计表,其中用字母代替切分后的词素,采用后方一致的排序方法,变化规律如下:
1)两词相同词素数越多,xsd值越大;
2)当相同词素数相同时,两词词素数相差越小,xsd值越大;
3)x个与(x+1)个词素的两词间xsd差值随x增加而减小,即相比较的两词相同词素数越多,两者的xsd值差异越小,这符合树状关系中较低层词间关系的差异应比较高层词间关系差异小的预期。
基于以上规律,改进阈值控制办法,令区分层关系的F值变为Fend值。Fend值等于首词与同素族中其他词xsd值中的最大值(Max),这样随着词素的增加,避免了单一固定的F值难以区分逐渐趋近于1的xsd值中的细小差异性,同时也避免了同素族词无限制的层间关系。因为Fend值仅作用于形成树状图中的最底层词间关系,若Fend=0,虽然整个同素族词树状图中不会出现遗漏词,但会出现xsd值非常小的词间关系也被收入树状图中,造成准确率的降低。Fend值作用原理流程如下:
算法:以Fend为阈值生成词间关系树状图
输入:待运算的同素族全部词集合Ω及两两词间xsd值
输出:该同素族词符合限定的词间关系树状图及未计入树形图中的遗漏词
步骤:
初始化:Ω={An};T={Ai},i≤n,T∈Ω,令T初始值为仅含首词的集合;设词集T’为空词集;Fend=Max(首词与同素族中其他词的xsd值)
For each T[Ai]
Ω=Ω-T
取T[Ai]与Ω[An]的xsd值中的最大值赋予Max
If Max≥Fend then
将Ω[An]作为T[Ai]的下层词,且将T[Ai]放入集合T’中
T=T-{Ai}
If T={} then
if T’≠{} then
T=T’,T’={}
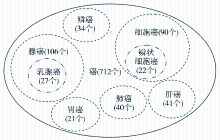
if T={} and T’={} and Max End 返回词间关系树状结构及Ω中剩余词改为选用Fend的阈值控制方法后,发现当待计算的同素族中首词与其他词的词素个数是连续变化的自然数时,计算的词间关系效果更好;否则,差异越大、间断越多,从人工的角度看,词间关系越松散失真。因此要保证该同素族中的所有词词素个数差异不能过大,于是采用另一种途径改善算法缺陷,即控制同素族的颗粒度。 ②同素族颗粒度 增加了同素族词的颗粒度k限制同素族词的规模,通常最大的同素族首词就是词素本身,拆分小词素族是在原词素的前方(后方一致排序,因此是从后往前加限制条件)加一个词素进行再次统计,凡出现连续两次拆分同素族词个数N大于k值的情况就继续拆分,直至满足k值。以“癌”同素族词为例,在共计712个词中,设k=20,从最高层的同素族词进行拆分。如图6所示,虚线圆圈代表第二层同素族词中需要拆分的对象,点线圆圈代表第三层同素族词需要拆分的对象,例如“乳腺癌”同素族N=27,再次拆分后没有大于20个词的同素族,于是拆分结束。图6中对于无需切分的同素族词未标出。 
图6 “癌”同素族词拆分示意图
③效果测试
依照上述改进方法,以“癌”同素族词为例,拆分成个体同素族计算的方式与整体计算方式比较效果,采用Fend值控制,由人工判断词间关系的正确数量。如果两个临近层之间的关系不正确,那么低层以下的全部词关系都记为错误。判断结果如表5和表6所示:
| 表5 词间关系各阈值拆分计算结果 |
| 表6 词间关系各阈值整体计算结果 |
由表5和表6可知,拆分计算的方法尽管造成了遗漏词数量增加,但确实提高了正确率。根据详细的统计分析,整体计算方法中全部338组错误关系共涉及88个词,其中47个词,即半数词都在拆分计算法的遗漏词中。换句话说,拆分算法中总共遗漏的214个词,尽管比整体算法多遗漏了74个词(214-140=74),但这74个词中有47个词反而降低了正确率。另一方面,从专家审核两种算法的词间关系总体反馈意见来看,大多数专家倾向于修正“少而精”的结果。因此可以得出结论:拆分计算优于整体计算。
综上所述,阈值设置的改进与同素族颗粒度的控制有效改善了海量自然语言词表词间关系的建立效果,并且将手动输入的参数改为系统自动输入,提高了效率和自动化水平。
字面相似度的算法直观、相对简便,应用于海量词关系计算中,其局限性如下:
(1)不能解析语义的相似度,如“电脑”和“计算机”、“中华人民共和国”和“中国”这样的同义词只能依靠同义词词典或已经编制好的词表来解决,而对于未编制的新词则仍旧需要人工辨别。
(2)切分词素颗粒度粗细问题,如词“大肠腺癌”切分成“大肠;腺;癌”或是“大;肠;腺;癌”将影响到该词在树状关系图中的位置,如选前者,该词将与“胃腺癌、腮腺癌”等词平级作为“腺癌”的下层词,若选后者则会造成偏失。因此词素的切分将是词间关系的一大要素,需要针对目标同素族词具体分析。
(3)k值的选取对于整体的计算量有很大影响。设置过小,求精而失去大量词会导致计算机运算量过大,同时也增加了后期专家审核的工作量;设置过大会造成待计算同素族中词的词素数差异大,则错误率就会上升。
(4)阈值的限定体现了词间上下级关系,减少了人工修表、建表的工作量,但缺乏语义概念的支撑,还不能等同于传统词表的属分关系。
(5)平层关系间的逻辑性差。比如“肝癌”的紧邻下层词出现了“抗肝癌、晚期肝癌、大鼠肝癌、移植性肝癌”等词,这些词作为平级词排在一起,缺乏人工分类的逻辑性,目前还没有办法改善。
(6)依照汉语词汇构成重心后移的特点,进行后方一致的倒序排列切分、选取同素族的办法会导致部分词汇关系的丢失。如图6所示“癌”同素族词中的“乳腺癌”和“乳腺鳞癌”两词,因乳腺癌和鳞癌均独自成族进行计算,所以割断了两词之间应有的联系。下一步工作可考虑结合前方一致的算法进行改进。
(7)基础词表数量虽然已接近百万,但具体到某个同素族还是会缺词,从而导致词间关系的错误或遗漏词。如“细胞癌”同素族计算树形关系时因为整族词中没有“膀胱细胞癌”,于是遗漏了“人膀胱细胞癌”进入树形关系,而“膀胱移行细胞癌、膀胱尿路上皮细胞癌、膀胱移行上皮细胞癌”三个词也就无法围绕“膀胱”建立起相应的关系。
(8)基础词表的质量关系到自然语言词表的质量,本文选取的基础词已是人工审核完毕的,但是仍出现了一些诸如“前殂腺癌”的错误词。同时随着科技的不断发展,如何为词表补充新词还需进一步考虑。
本文应用的字面相似度算法属于传统算法,今后的研究改进工作中还可利用其他各算法的长处,结合海量自然语言词语的特点对算法进一步修正。
总之,计算机辅助自然语言词表构建仅仅是减轻了人工工作量,但是到目前为止,专家审核仍是最终保证自然语言词表质量的唯一方式。
在计算机辅助标引文献加工系统中,词表系统是其中的重要模块之一。自然语言词表的构建符合现代文献组织的需要和检索系统的需要,可作为分词词表、词素词表、自动抽词词典、自动赋词用对应表、自动赋号用对应表、自动分类用对应表、检索系统后控制词表等多种用途词表的参考工具[ 21],兼具人工语言和自然语言的双重优势。随着计算机技术的提高与互联网的普及,普通用户的信息意识与信息素质越来越高,自然语言词表将有更广大的发展空间。
本文围绕计算机辅助标引文献加工系统中词表系统的建设,主要阐述了构建自然语言词表的过程。基于多年海量文献人工标引的基础,运用计量分析法对多年来积累的人工标引词从词频、词长、词类型、词共现等多方面进行统计,根据其特点优选自由词,而后通过计算机辅助计算词间关系,构成了自然语言词表。目前该系统还很不完善,词间关系仍需大量人工参与,希望能够通过进一步研究与实践,开拓词间关系算法,将各种已有研究成果应用于海量自然语言词语的计算过程中,利用大规模语料在题名、文摘及全文中持续开展统计关联、语义相似方面的相关研究,同时加强分析用户查询检索策略,以发现更多的隐性语义关联;同时加强整体系统的反馈机制,发现问题、解决问题,运用各种辅助手段进一步降低人工审核的工作量。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|