
{kind=link}
{kind=link}
{kind=link}
{kind=link}
集群与负载均衡技术在国际科学引文数据库服务系统中的应用研究
[张建勇1 , 廖凤1, 2  , 刘小兵
, 刘小兵1 , 陶超全3 ]
, 刘小兵|
|


从国际科学引文数据库(DISC)面临的负载压力和扩容需求出发,通过对相关技术进行调研分析,选择当前常用的开源集群和负载均衡技术构建DISC服务系统;对采用的Web服务器负载均衡技术、MySQL Cluster技术及基于Solr的分布式索引技术进行介绍,并对其性能进行理论分析和实验验证;测试结果证明DISC的系统架构方案具有良好的可扩展性、可用性和可靠性,能够较好地满足当前的应用需求。
Based on the load pressure and capacity expansion requirement of Database of International Science Citation (DISC), this paper chooses the popular technologies of load balancing and clustering to construct the service system. Web server load balancing mechanism, MySQL Cluster technology and distributed indexing technology of Solr are introduced in detail. The performance of architecture solution is explored both through theoretical analysis and experiment testing. The test results show that the system architecture of DISC has good expansibility, availability and reliability, which can support current application requirements well.
① 国家科技图书文献中心,2009年NSTL工作总结报告。
根据当前增长趋势预测,NSTL建设的国际科学引文数据库(Database of International Science Citation,DISC)数据规模在2010年底将超过1亿条,并以每年3 000万条的速度增长①。同时作为面向公众服务的Web服务系统,现实和潜在的访问用户量将是一个较大的数字,日访问量可能会达到几十万人次。因此当前DISC服务系统需要着重解决以下两方面的问题。
(1)数据扩容:需要实现一个具备可持续扩充能力的服务器体系结构,保证大量数据的有效存储和检索获取。
(2)负载均衡:确保在大量用户访问系统时,不会因为系统并发能力弱或响应缓慢造成系统易用性降低。
本文主要研究如何利用集群技术和负载均衡技术搭建一个大规模可扩缩的服务器体系架构,以解决大容量数据的存取、全文检索的效率和高并发访问问题。
针对DISC系统目前面临的问题,首先对集群和负载均衡技术的应用现状进行深入调研和比较分析;结合DISC的应用需求,选择适合的技术构建可扩缩服务器体系结构,并根据应用情景进行方案优化;在该方案的指导下部署实现系统;最后采用标准方法对系统性能进行测试,验证设计方案的可用性和可靠性。
本文整合开源的集群和负载均衡技术,建立了可扩缩的服务器体系结构,为面临类似瓶颈问题的系统提供了参照;同时在充分考虑现状和需求的情况下对关键技术进行了优化配置,帮助提升系统性能。
文献服务系统体系结构的核心组件包括Web服务器、数据库服务器以及搜索服务器。Web服务器直接和用户交互,是系统访问压力的直接承担者;数据库服务器负责结构化数据存储,扩容效率至关重要;搜索服务器完成全文索引和全文检索功能,搜索任务和索引文件的有效分发是基本要求。因此,本文着重调研了现有的Web服务负载均衡技术,数据库集群技术和全文索引技术及相关产品。
Web服务器的负载均衡技术主要是按照一定策略将Web访问负载分配到几台服务器或服务器实例上,负载处理对用户透明,整体上对外如同一台Web服务器在提供服务。目前比较流行的负载均衡方法分别是:
(1)DNS轮循。基本思想是多个内容完全镜像的服务器拥有相同的域名和不同的IP地址[ 1]。因此发起单个的域名解析请求,可以返回集群内某台机器的IP地址。这种方式廉价、简单并且容易配置,但并没有提供服务器之间的联系和高可靠性能力。
(2)硬件负载均衡器。硬件负载均衡器[ 2]有一个单独的IP地址,映射到集群内的每一个节点上,负载均衡器接受请求后通过重写头部来指向集群内其他机器。优点在于服务器之间的联系性和高效性,缺点是昂贵并且设置复杂。
(3)服务器自带负载均衡机制,如Apache2的mod_proxy和mod_rewrite、Tomcat的Balancer应用[ 3]等,服务器自身具备负载均衡能力,在一定量的负载程度上可以达到很好的负载分配。
数据库集群技术使用特定的连接方式,将价格相对较低的硬件设备结合起来,提供高性能的任务处理能力。基于数据库引擎的集群技术[ 4],比较流行的有Oracle RAC、Microsoft MSCS 、IBM DB2 UDB以及开源的MySQL Cluster。
(1)Oracle RAC采用了“Sharing Everything”的实现模式,通过CPU共享和存储设备共享来实现多节点之间的无缝集群,用户提交的每一项任务被自动分配给集群中的多台机器执行,用户不必通过冗余的硬件来满足高可靠性的要求。
(2)Microsoft MSCS:通常情况下,群集中的计算机能够按照“活动-活动”方式共享相同的存储子系统与功能,这意味着所有集群计算机(节点)均可主动通过共享负载的方式协同完成工作,并在某个节点出现故障时分担它的工作。MSCS的主要用途是通过自身提供的容错能力提高应用程序的可用性。
(3)DB2 UDB支持Unix, Linux 以及Windows等主流操作系统;支持各种开发语言和访问接口,同时具有良好的数据安全性和稳定性。利用DB2数据分区部件实现横向扩展,可以支持多达1 000台服务器组成的庞大数据库群集。
(4)MySQL Cluster技术允许在无共享的系统中部署内存中数据库的 Cluster。通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求。此外,每个组件都有自己的内存和磁盘,不存在单点故障。
在全文检索技术方面,主要有如下三种解决方案:Solr、Oracle Text以及Sphinx。
(1)Solr[ 5]是建立在Lucene基础上的开源企业搜索服务器,它支持通过XML、JSON和HTTP的查询获取结果,提供了一个与平台无关的接口。Solr提供分组搜索、复制、缓存和大规模分布式搜索等特性,可以组建各种容量的系统。
(2)Oracle Text[ 6] 利用标准 SQL 来索引、搜索和分析存储在 Oracle 数据库、文件和 Web 上的文本。Oracle Text 可以对文档执行语言分析,使用各种策略搜索文本,用各种格式显示搜索结果。Oracle Text 支持多种语言并使用高级的相关度排序技术来提高搜索质量。
(3)Sphinx[ 7]是由Andrew Aksyonoff开发的一个全文检索引擎,旨在为其他应用提供高速、低空间占用、高结果相关度的全文搜索功能。Sphinx可以非常容易地与SQL数据库和脚本语言集成。当前系统内置MySQL和PostgreSQL 数据库数据源的支持,也支持从标准输入读取特定格式的XML数据。
DISC在搭建服务器体系结构时,一方面必须充分考虑当前及潜在的应用需求,另一方面也需考虑成本效应,尽量选用开源技术。由于负载情况还没有达到足够大,利用服务器自带的负载均衡模块就可以实现很好的负载分配,而且服务器在10台以下时速度也足够快,因此Web服务器的负载均衡方案选用Tomcat自带的Balancer应用。
DISC系统对数据库系统的要求一方面是在并发响应上要足够稳定,另一方面是能支持在大数据量上扩充。开源的MySQL Cluster可以很好地满足上述要求,尽管Oracle等商用集群方案在数据的处理能力和容量上都优于开源的MySQL,但是对单台服务器的硬件要求高,维护成本也高。相对来说,MySQL对单台服务器的硬件要求很低,而且对于几乎是只读系统来说,效率并不亚于Oracle。此外,MySQL单台容量的逐步扩充也比较符合DISC现在数据增长的速度。
搜索引擎的选择要点是结构化文本信息的全文检索能力和索引速度。根据实际测算,索引速度最快的引擎首先是基于Lucene的Solr,其次是Sphinx,然后是Oracle Text。鉴于Oracle单机维护成本高并且不是开放系统,本文重点评估了Solr和Sphinx的检索能力,DISC要求的最大检索结果集合是10万量级,并在此基础上要求能分组和排序,但是Sphinx无法一次返回如此大的数据集合。另外从搜索引擎的使用广泛程度来说,Lucene有更多的使用者,稳定性和今后的扩展性更值得信赖,因此搜索方案选择Solr。
根据上述分析,DISC系统全面采用开源技术搭建可扩缩的系统体系结构,主要包括基于MySQL数据管理系统、全文索引引擎Lucene和Web服务器Tomcat,并在充分论证和验证的基础上认为数据的存取效率取决于系统各个部分的效率,只有任何一部分不形成瓶颈问题,才可能全面提高系统的性能。基于此,在系统扩展时全面采用可扩缩的系统结构来构建新的DISC服务系统,首先是可扩充的Web服务器,其次是可扩充的搜索引擎和可扩充的数据库系统。Web集群技术与负载均衡技术选择开源的Tomcat负载均衡方案,重点解决大量请求的负载均衡;分布式索引采用Solr分布式搜索引擎技术,管理日益庞大的Lucene全文索引;数据库管理系统选择MySQL Cluster数据库集群方案,扩展数据库的存取能力。DISC的服务器体系结构如图1所示:
 | 图1 DISC分散式服务器体系结构 |
不论是负载均衡能力还是容错能力的需求,都使得Web服务器集群和负载均衡技术的应用成为必要。DISC选择使用Tomcat 5自带的Balancer Web Application[ 8]来重定向Web请求到集群内各节点。该Web应用需要Servlet 2.3或其后版本的容器支持,是一个基于规则的纯Java应用,简单并易于扩展。默认安装下的Balancer使用一个过滤器BalancerFilter,它作用于所有的请求,并读取配置文件中的规则,根据特定的负载均衡算法(如Random、Round-Robin)将请求快速重定向到不同的服务器。同时引入Session复制机制,以便于在会话层解决集群的失败重启问题。
(1)DISC的Tomcat集群架构
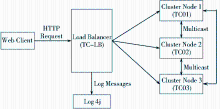
为了搭建DISC的集群环境,安装了4个Tomcat Server实例(分别用TC-LB,TC01,TC02,TC03表示),使用垂直扩展方式,即在单台机器上运行多个Server实例。为了便于会话复制等操作,各个Server下Web应用的目录结构和内容都是完全一致的。DISC Tomcat集群架构图及各组成要素如图2所示:
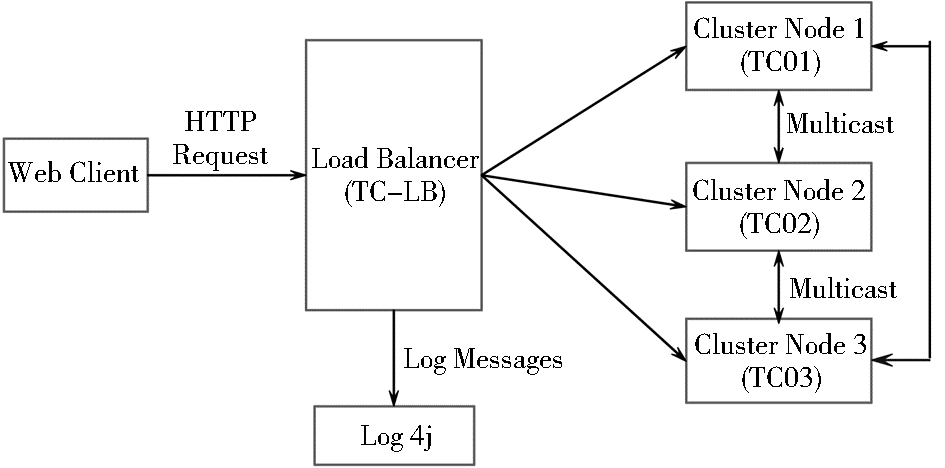 | 图2 DISC Tomcat集群架构图[ 9] |
①负载均衡器(Load Balancer):一个Tomcat实例,主要负责将网络负载按一定策略分发到集群中的成员节点,代号TC-LB。这样应用不再在单一服务器上执行,而是动态选择服务器。负载均衡器为集群提供单一入口,如同直接和独立服务器交互,对于客户端来说是透明的。
②集群成员(Cluster Node):集群成员包含三个Tomcat服务器实例,代号分别是 TC01, TC02 和 TC03。这些服务器实例是实际处理Web请求的节点,节点之间通过组播(Multicast)方式通信,发送者和每一接收者之间是一点对多点的网络连接。
③会话复制(Session Replication):Session状态复制允许在原来的服务器失败时,能够无缝地从集群中的另外一台服务器上取得客户的Session数据,从而保持服务的连续性。这里使用的是基于内存的复制机制,当Session对象改变时,Session数据将被复制传播到所有三个集群成员。
④失败重启(Fail-Over):目前Tomcat并没有提供内建的失败重启机制,可以自己编写工具类来检测服务器状态。
(2) 配置文件及配置参数
在Tomcat集群中,当多个用户请求传入服务器后,由负载均衡器上的BalancerFilter来决定将请求重定向到哪里,这里涉及三类配置文件:
①Web.xml: 在Balancer上用于定义和映射BalancerFilter,在各个集群节点上用于指明Web应用的Session数据是否需要复制。
②Server.xml:用于对各个Tomcat服务器实例进行集群配置,包括:Port、Connector、Logger、Cluster Manager、mcastAddr、mcastPort、mcastFrequency以及Receiver信息等。
③Rules.xml[ 10]:Balancer节点上的该配置文件用于定义具体的负载均衡规则,包含不同的规则和重定向的URLs。BalancerFilter按照Rules.xml中指定的顺序检查规则,找到第一个匹配的规则后,不再继续匹配,这个请求马上被重定向。可以修改Rules.xml,使其遵循Round-Robin或者Random算法。基于Round-Robin的规则配置文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<rules>
<!--Redirect to server instance based on RoundRobinRule-->
<rule className="org.apache.webapp.balancer.rules.RoundRobinRule"
serverInstance="1"
maxServerInstances="3"
tcpListenAddress="127.0.0.1"
tcpListenPort="4001"
testWebPage="http://localhost:9080/clusterapp/start.jsp"
redirectUrl="http://localhost:9080/clusterapp/search.jsp"/>
……
<rule className="org.apache.webapp.balancer.rules.RoundRobinRule"
serverInstance="3"
maxServerInstances="3"
tcpListenAddress="127.0.0.1"
tcpListenPort="4003"
testWebPage="http://localhost:11080/clusterapp/start.jsp"
redirectUrl="http://localhost:11080/clusterapp/search.jsp"/>
<!-- Default redirect if none of the above rules match -->
<rule className="org.apache.webapp.balancer.rules.AcceptEverythingRule"
redirectUrl="http://localhost:8080/balancer/test.jsp"/>
</rules>
DISC Tomcat集群配置的详细参数如表1所示。由于所有Tomcat实例都运行在一台机器上,因此实例的tcpListenPort属性需要设置成唯一。mcastAddr, mcastPort等属性都用于集群节点之间的多播通信,而tcpListenAddress, tcpListenPort等属性用于Session复制。
| 表1 DISC Tomcat集群配置参数 |
(3) 集群方案性能分析
该集群配置方案采用Tomcat自带的Balancer应用,其简单易于扩展的特点非常适用于DISC目前的应用环境。随着用户访问量的增加,DISC将面临集群扩展的需求,只需增加集群节点,修改配置文件即可,简单易操作。通过修改Rules.xml,也可以自定义和扩展负载均衡策略,如Round-Robin、Random、Weight-Based等负载均衡算法。同时,该方案中采用了会话复制和持久化的方法,以达到会话级别的容错。在目前集群规模较小的时候,采用基于内存的复制策略,即Tomcat的SimpleTcpCluster来进行会话复制;将来如果有必要扩展到更大规模,可以采用会话信息持久化的方法。
由于硬件条件限制,该方案也存在一些缺陷。由于仅仅设置了一个负载均衡器,当用作负载均衡器的 Tomcat 实例挂起时将没有途径转发请求到集群节点,引发单点失败。由于所有Tomcat实例(包括负载均衡器)都是配置在同一台机器上运行,不能很好地保证集群的效率,更好的设置就是在一台独立的机器上运行负载均衡器。同时,基于内存的会话复制,对于小规模集群是可行的,但是面对更大型集群时,就需要考虑其他策略。
Solr是一种开放源码的、建立在 Lucene之上的企业级搜索服务器,它支持分面搜索、智能缓存、命中突出显示和多种输出格式。Solr在充分发挥Lucene的功能上做了很多工作,特别是在处理大规模应用方面,Solr以简单易操作的方式提供了高度可伸缩性的搜索方案。
(1) DISC的分布式检索构架
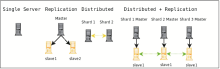
影响检索系统性能的两个主要因素是查询请求量和索引量。Solr通过分布(Distributed)和复制(Replication)策略,能够很灵活地处理各种需求[ 11]:
①通常情况下,由一台服务器负责索引更新和请求响应。
②当有大量的查询请求时,通过将索引复制到多台机器(Slave)上,形成Master/Slave结构,由Master负责索引更新以及将更新反映到Slave,而Slave则负责处理所有查询请求。
③当索引过大而一台机器处理能力不能应对时,可以将索引分割放置在多台机器上(Shards),每个Shard自行负责索引更新和请求处理,将各个Shard返回的结果合并形成最终结果。
④将分布策略和复制策略结合起来,可以同时应对请求压力和索引扩展问题,即将每个Shard复制形成各自的Slave,由Master负责处理索引更新和优化,而通过负载均衡调度,可以将查询请求分配到合适的Slave节点上。
图3是Solr从简单到复杂的结构扩展图,可以根据不同的需求组建不同容量的系统。
 | 图3 Solr容量扩展过程中的4种架构方案[ 11] |
在DISC系统流程中,Solr主要负责对检索点字段如题名、作者、刊名、ISSN、文摘、机构、关键词、出版时间等进行索引。目前面临的主要问题是索引量较大,且处于持续增长中,因此采用分布式策略,将索引按一定策略分割存放于两台机器上,检索时由两台Shard上的结果合并而成。DISC Solr Shards配置详情如表2所示:
| 表2 DISC Solr Shards配置 |
索引分割存放之后,检索过程就相当简单[ 5]:只需要将Shard的URL参数放在一起,用逗号分割,如:http://localhost:8080/solr/select?shards=localhost:8080/solr,localhost:8...,那么RequestHandler将会独立地检索列出URL,将结果合并输出,如同在一个大索引文件上执行检索一样。
(2) Solr配置分析及扩展方案
在大规模索引问题上,Solr提供的解决方案简单且成熟,足以扩展到10亿级的索引量。构建分布式的Solr服务器极其简单,只需在每台机器上安装Solr即可,每台机器都被Solr视为一个Shard,Shard数目可以从1到n不等。目前没有立即可用的对分布式索引的支持机制,但可以选择使用最简单的方法,如Round Robin:将每个Document依次放到下一个服务器进行索引。需要注意的是,Solr并不会计算全局的TF-IDF。在数据量较大的情况下,基于Shard层次的TF-IDF计算不会存在太大偏差,但是如果索引分布极不均匀,可能就需要特别重视相关度计算问题。
目前的配置解决了索引量大的问题,下一步的扩展需要考虑请求量增大时的负载均衡问题,解决办法是Distributed + Replication,即在索引分割的基础上为每个Shard复制1…n个副本(Slave),在每个Master上索引和更新索引文件,然后将更新反映到每个Slave上,由每个Slave负责具体的检索请求处理。为了提高可用性,可以设置负载均衡器并为每个Shard的Slave集合设置虚拟IP,当一个Slave节点发生错误时,负载均衡器将会检测错误,并将查询请求重定向到剩余可用的Slave节点。
尽管简单易操作,但是Solr的分布式搜索目前仍存在一些缺点:
①Master 节点不容错,因此它一旦停止,系统就不能为新的文档创建索引或执行复制;但是对于可以手动或通过脚本和外部监控工具来管理Shard的较小分布式配置而言,这并不是太严重的问题。
②并不是所有的 Solr 1.3 版本中的 SearchComponent 都是分布式感知的,搜索、分类、调试和突出显示组件是分布式感知的;而其他不常用的组件,正在努力实现这个功能。
考虑到DISC的开发历史和今后的数据扩展速度,选择MySQL Cluster数据库集群方案。MySQL Cluster[ 12]采用了NDB Cluster存储引擎,允许在无共享(Shared Nothing)的体系结构中部署“内存中”的数据库。MySQL集群一般由分布的多个节点组成,由于每个组件有自己的内存和硬盘,因此不存在单点故障,具有高可用性、高可靠性和易扩展性等特征。
(1) 集群架构及节点功能
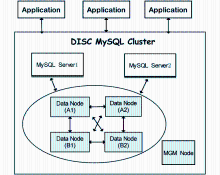
MySQL Cluster具有较高的可配置性,可以根据实际需求更改集群内计算机的数量、存储节点数量或应用程序数量。DISC的MySQL集群共包含三类节点,配置详情及节点结构如图4所示:
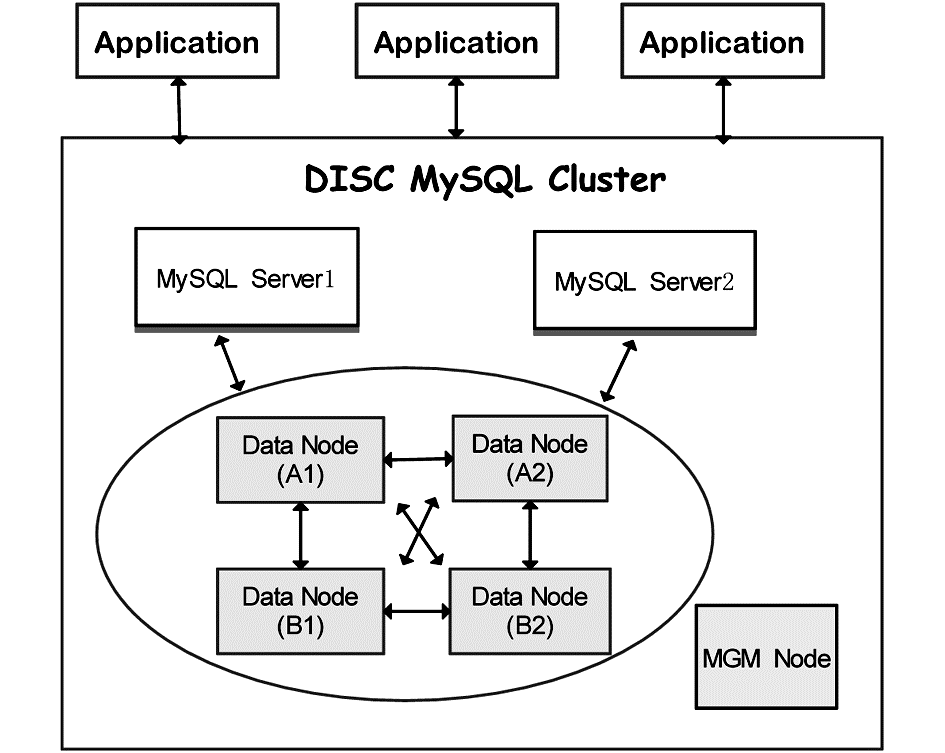 | 图4 DISC MySQL Cluster节点 |
①MGM Node:管理服务器节点,在两个MySQL Server节点上均安装了该类节点,用于管理Cluster内其他节点的配置,控制系统的初始化,是集群系统中应首先启动的节点。管理服务器节点只在系统启动和重新配置的时候起作用,即数据节点工作的时候无需管理服务器节点的介入。
②MySQL Server Node:MySQL服务器节点,访问集群内数据节点的MySQL服务器,每个服务器节点都和所有的存储节点相连接。MySQL服务器节点给开发者提供了标准的SQL访问接口,直接处理应用程序请求而屏蔽了与存储节点交互的所有底层细节。方案中设置两个MySQL服务器实例,如果其中一个失效,另外一个还可以继续工作。
③Data Node:数据节点或存储节点,所有数据库中的数据表被划分为两份(用1、2标识),并建立两组冗余备份(用A、B标识)。这样{A1,A2}和{B1,B2}保存的均为完整的数据内容;节点A1和B1、节点A2和B2存储的都是相同的数据划分;{A1,B1}、{A2,B2}称为节点组,节点组内的节点互为备份节点。当节点A1失效时,节点B1将替代节点A1执行任务;同样当节点A2失效时,B2节点将起到支撑作用。通过这种存储节点设置,既解决了数据容量问题,也能很好地解决故障恢复和负载均衡问题。
数据节点配置文件示例如下:
#Options for mysqld process:
[mysqld]
ndbcluster
ndb-connectstring=192.168.101.202
[mysqld]
ndbcluster
ndb-connectstring=192.168.101.201
[mysqld]
ndbcluster
ndb-connectstring=192.168.101.200
[mysqld]
ndbcluster
ndb-connectstring=192.168.101.109
#Options for ndbd process:
[mysql_cluster]
ndb-connectstring=192.168.101.203
(2) 配置方案特征及性能分析
单点故障的避免,使得MySQL Cluster在理论上可以保证99.999%的可用性。DISC系统的配置方案结合DISC的特定需求,充分利用了系统架构的优点。
①高可用性
MySQL Cluster具有高可靠性特征,体现为不存在单点失败,任何节点可以被杀掉,而不会丢失数据或者造成应用程序中断[ 13]。这种特征的实现得益于其节点架构设计:
1)每个MySQL服务器节点和所有的存储节点相连接,如果一个存储节点失效,MySQL服务器可以很容易地使用其他节点来执行事务。
2)每个存储节点都有备份节点(允许至多备份数为4),在事务执行过程中所有数据都会同步备份,即事务执行的结果将会传播到所有相关存储节点。如果一个存储节点失效,总是会有其他存储节点保存有相同的数据。
3)只要存储节点启动并开始运行,管理服务器节点可以被杀掉、重启甚至停止,都不会影响到存储节点上正在执行的事务。
②易扩展性
MySQL Cluster基于无共享的组织架构,每个节点具有自己独立的处理器、内存和磁盘,系统中的各节点可以独立地处理自己的数据。这种结构具有优良的可扩展性:只需增加额外的处理节点,就可以以接近线性的比例增加系统的处理能力。因此,通过增加存储节点服务器,可以有效地解决DISC数据系统面临的持续扩容问题。
③数据独立性
应用程序通过Server节点连接到集群系统,由Server节点负责接收和处理应用程序请求,因而屏蔽了应用程序与存储节点交互的所有细节,这很好地维护了数据的独立性和透明性。数据存储引擎负责处理所有底层的事务,如数据复制和自动故障恢复等,应用程序不必了解数据的存储详情,实现了数据存储透明;Server节点负责处理网络分割和数据分布,实现了数据分布透明;应用程序在编码时也不必在意数据是如何备份的,就像操作一个独立完整的数据库一样,从而实现数据备份透明。此外,独立通用的SQL接口使得任何底层编程语言的开发者都可以实现MySQL集群的这些高可用性特征。
④快速故障恢复
MySQL Cluster具有高可靠性,同时也具备快速故障恢复机制。当Server节点出现故障时,由于每个服务器节点都与全部的存储节点建立了连接,因此可以由其他服务器节点接管并提供数据库服务,同时通过重启节点来建立与MySQL Cluster的连接。当存储节点宕机时,所有其他节点都将收到消息。由于数据是同步复制的,总会找到其他可用的存储节点来执行事务请求,故障恢复时间一般少于1s。由于服务器节点和存储节点运行时与管理节点是相互独立的,因此管理服务器节点失败或重启任意次数都不会对集群节点运行造成影响。
从上述分析可知,从理论上来看,MySQL集群技术方案既解决了DISC的数据扩容问题,也可以保证数据库系统的高可用性和高可靠性。但由于MySQL Cluster使用基于内存的数据库引擎,即所有表的数据(包括索引)都保存在内存中,因此对内存要求较高。如果一个数据节点上的内存使用超出了可用的范围,则操作系统会使用交换内存来达到上限值 DataMemory,将导致性能严重下降,并且可能导致响应时间变慢。此外,NDB 表目前还存在诸多局限性,如不支持临时表;不支持 Full Text 索引、前缀索引以及不支持部分回滚和回滚到保存点等,这些局限性将随着技术的发展被进一步解决和完善。
DISC服务系统经过一定时间的编码和调试,正式进入测试阶段。参考集群服务器的常用性能指标,如吞吐量、响应时间、CPU利用率、内存使用率等,本文选择较具代表性的平均吞吐量和平均响应时间作为测试指标。平均吞吐量指单位时间内处理的客户请求数量,直接体现系统的承载能力;平均响应时间指完成一个请求任务所用的平均时间。测试环境及参数配置如表3所示:
| 表3 测试参数配置 |
| 表4 测试结果 |
(1) 150个线程完全并发的情况下,虽然线程ID越大平均响应时间有越长的趋势,但都执行良好,说明在系统承载能力范围,可以预测系统平均吞吐量大于150;
(2)各线程平均响应时间为571.10毫秒,且平均响应时间在700毫秒以内的线程占90%,说明并发线程整体执行性能较好,响应较快。无论在平均吞吐量以及平均响应时间方面,DISC集群服务器均达到了较好的负载均衡效果,能够满足应用需求。
本文选择开源集群和负载均衡技术构建可扩缩的DISC服务系统,以解决DISC大规模数据存取的压力和服务系统高并发及快速访问的问题,详细分析了当前DISC系统架构中采用的Web服务器负载均衡技术、MySQL Cluster集群技术以及基于Solr的分布式搜索技术,搭建了可扩缩的服务器体系架构和应用系统,在实际开发过程中又进一步完善了该系统架构。完成后的服务系统在严格的条件下(平均吞吐量和平均响应时间)测试了大量密集访问对系统效率的影响,从测试结果可以看出DISC的系统架构方案是成功的,具有良好的可扩展性、可用性和可靠性,总体来看较好地满足了目前的应用需求,并预留了一定的扩展空间。在系统正式运行中,还需要进一步验证服务的效率。目前的实践可以证明DISC系统的扩容技术方案可以作为建立类似系统的一个有效参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|