





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
多语言文本表示研究综述
[刘飒 , 章成志]
, 章成志]
, 章成志]
|
|


对多语言信息处理中的文本表示问题进行阐述。在分析单语言文本表示的模型和过程的基础上,说明多语言文本表示的过程,详细分类并阐述其中的各种方法,对其进行比较分析。概括多语言文本表示的特点,指出尚存在的问题,并对多语言文本表示的发展趋势进行探讨。
This article discusses the issues of document representation in multilingual information processing. Firstly, it describes the process of multilingual document representation, introduces different methods in detail and compares their strengths and weaknesses. Then it summarizes the characteristics of multilingual document representation, and points out some existing problems.Finally, it shows some development trends of multilingual document representation.
随着互联网的飞速发展和国际化交流的日益扩展,不同语言的信息交换也越来越重要。如何跨越语言障碍,实现信息共享和沟通,是多语言信息处理中的关键问题[ 1]。其中的文本表示则是多语言信息处理的基础,是解决跨语言障碍的重要阶段之一。
多语言文本表示,特指多语言信息处理中的文本表示。多语言文本表示与单语种文本表示最大的不同在于:前者至少涉及两种不同的语言,为了顺利进行后续的多语言文本处理,需要在文本表示阶段实现或部分实现多语言文本的关联,以消除语言障碍。因此,如何对多语言文本进行映射,实现跨语言的文本表示是多语言信息处理中的关键问题之一。
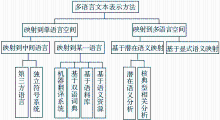
根据映射空间不同,将多语言文本表示方法分为两类:映射到单语言空间(包括映射到某一语言空间和映射到中间语言空间);映射到多语言空间(包括基于潜在语义映射和基于显式语义映射)。通过对国内外文献的分析,详细介绍多语言文本表示的各种方法,对其进行比较分析;阐述多语言文本表示的特点、尚存在的问题,并讨论今后的发展趋势。
多语言文本表示有两类方法:将多语言文本转换为单语言文本,在单语言空间进行文本表示;在多语言空间实现跨语言的文本向量表示。多语言文本表示与单语言文本表示有重要关系,需要借助单语言的文本表示方法或模型实现多语言文本的统一表示。单语种的文本表示模型有布尔模型[ 2]、向量空间模型[ 3]、概率模型[ 4]、语言模型[ 5]。这些模型仅考虑单词出现频率或概率,忽略词语的语义信息,与实际情况不符。因此,许多研究者尝试结合语义信息构建文本表示模型以提高文本表示质量,典型的方法主要有:基于图的表示[ 6, 7, 8]、基于概念的表示[ 9, 10]。
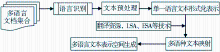
单语言文本表示一般包括两个步骤:文档预处理,提取特征项;文本结构化、形式化表示,如图1所示:
 | 图1 单语言文本表示过程 |
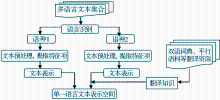
多语言文本表示过程与单语言文本表示过程类似,不同的是需要增加不同语种文本的映射,通常使用翻译资源、潜在语义分析(Latent Semantic Analysis,LSA)或显式语义分析(Explicit Semantic Analysis,ESA)等实现。多语言文本表示的主要过程包括:
(1)文本预处理之前,需先进行语言识别,这是因为不同语言在随后的文本预处理中采取的步骤不同;
(2)单语言形式化表示后,需要利用翻译资源或LSA、ESA等技术实现多语言文本映射;
(3)生成对应的语言表示空间。
对多语言文本表示流程进行归纳,如图2所示:
 | 图2 多语言文本表示流程 |
为了清楚说明多语言文本表示过程,以仅有两种语言的情形为例,以映射方法的不同对多语言文本表示过程进行图示说明。
(1)某一语言空间的表示过程
某一语言空间的多语言文本表示如图3所示:
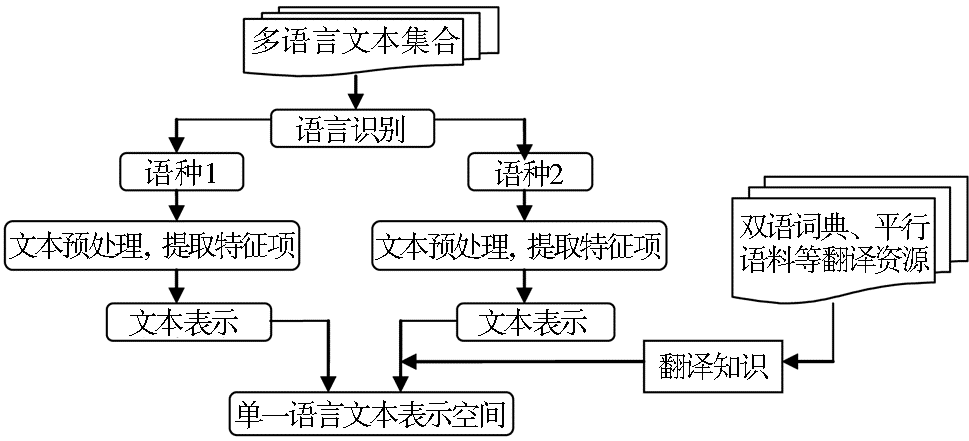 | 图3 某一语言空间的多语言文本表示过程 |
如图3所示,首先是语言识别,根据语言本身的特点,对每个单语种文本进行相应的预处理,提取特征项;然后借助双语词典、平行语料等翻译资源,获取翻译知识,将语种1翻译为语种2(或语种2翻译为语种1);最后将双语文本都映射在单一语言空间内。
(2)中间语言空间的表示过程
中间语言可以是一种实际存在的语言,如中日双语翻译可以将中文、日语都映射为英语,英语为中介语言(第三方语言);也可指独立于具体语种的某种符号标记系统。中间语言空间的多语言文本表示如图4所示,借助翻译资源如第三方语言或WordNet、EuroWordNet等词典知识库,获取翻译知识,从而将多语言文本都映射到中间语言空间。
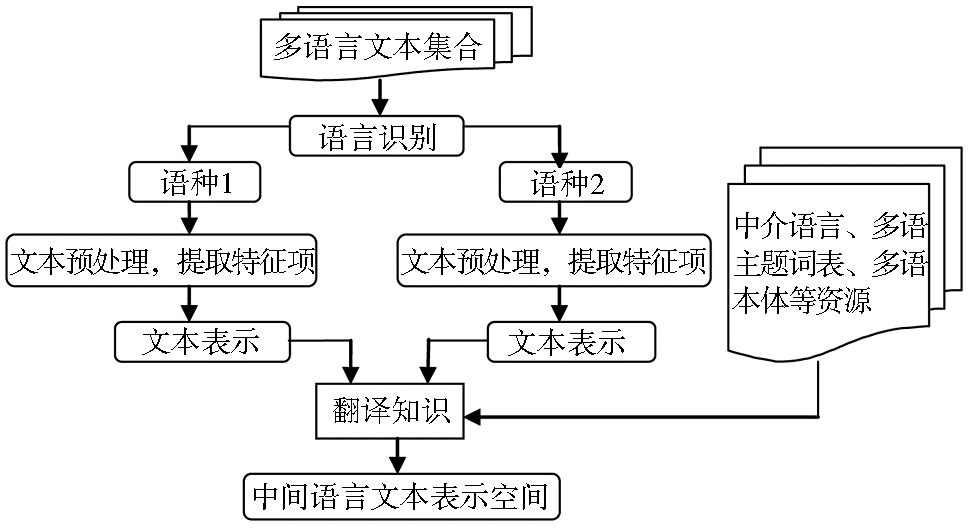 | 图4 中间语言空间的多语言文本表示过程 |
(3)多语言空间的表示过程
多语言空间的文本表示如图5 所示,借助多语言资源如平行语料、可比语料等,进行多语言文本映射(潜在语义分析或显式语义分析等),生成多语言空间;将不同语种的文本都映射到该空间,实现多语种文本在多语言空间的统一表示。
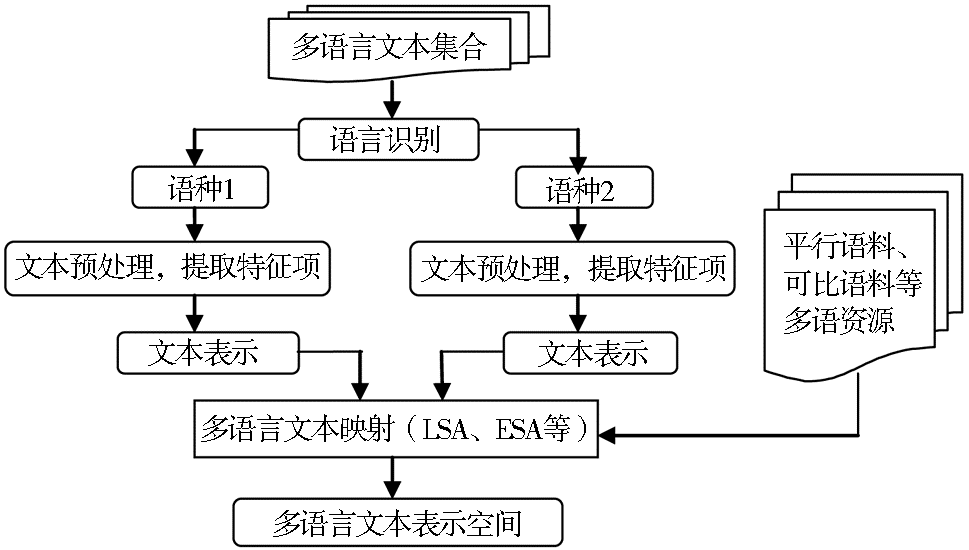 | 图5 多语言空间的多语言文本表示过程 |
根据文献[11]和[12]对多语言文本表示方法的分析及文献[13]对映射到多语言空间的表示方法分类,以映射空间的不同,将多语言文本表示方法进行归类,如图6所示:
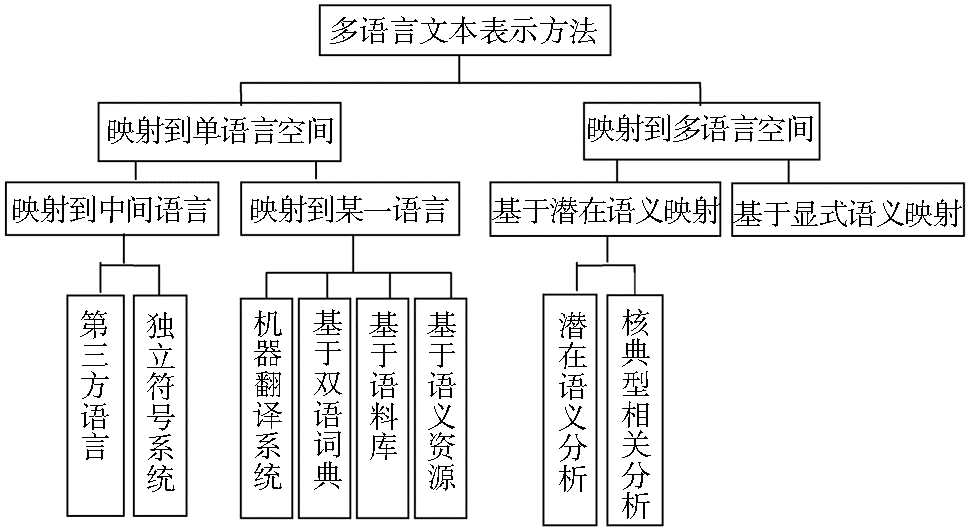 | 图6 多语言文本表示方法分类 |
(1)映射到单语言空间
该方法即通常所说的翻译转换。将某一语种的文本映射到另一语言空间,从而将多语言文本表示问题转换为单语言文本的表示。该方法可分为两种情形:将多语言文本(语种1,…,语种i,…,语种n)都翻译为语种i(语种i为多语言文本中的某一语种);将多语言文本都翻译为中间语言。
①映射到某一语言空间
根据所使用的多语言文本集合的不同可分为:基于机器翻译系统映射、基于双语(或多语)词典映射、基于语料库映射、基于语义资源映射。
基于机器翻译系统映射的方法是利用机器翻译系统(如Google在线翻译、SYSTRAN翻译),将一种语言的文本翻译成另一种语言,实现不同语种文本在同一种语言空间的表示。
基于双语(或多语)词典映射的方法是通过查找双语(或多语)词典、多语言主题词表等资源进行文本翻译,实现多语言文本的统一表示。2003年,Abdelali等基于多语言主题词表进行多语言文本表示,图7为多语言主题词表的一个片段。
 | 图7 多语言主题词表样例(片段)[ 14] |
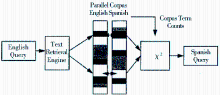
基于语料库翻译的方法是利用平行或可比语料中文本对齐信息和共现信息,提取翻译等价单元,构建统计翻译模型,选择相关的翻译,从而实现多语种文本在某一语言空间的表示[ 15]。早在1996年,Davis等假定语料中的术语服从χ2分布,从平行语料中抽取相关的翻译,将英语查询映射为西班牙语查询,实现基于平行语料的双语伪文档表示(将查询词语串视为伪文档),如图8所示:
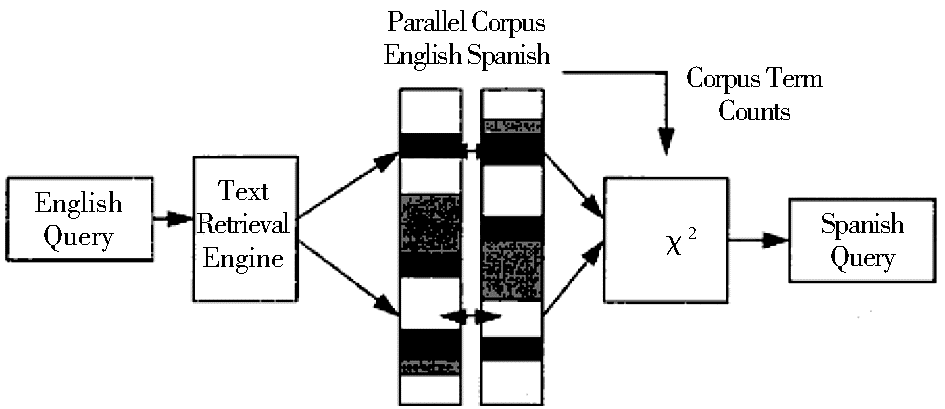 | 图8 基于平行语料的多语言伪文档表示[ 16] |
以上三种方法都只是单独依靠机器翻译系统、词典或语料库资源,没有将词语本身的语义信息考虑在内,导致翻译质量低,歧义现象大量存在,于是有研究者考虑结合语义资源来提高翻译质量,增强多语言文本表示能力。该方法所使用的翻译资源多为词典和多语言主题词表或词典、平行或可比语料的组合。王进等构建了一个英汉检索平台,包括一个英汉字典和中英双语本体库,使用字典初步翻译后再利用本体映射[ 17]。国外的一些学者则利用WordNet或Wikipedia作为词典的扩展,进行多语言文本表示[ 18, 19, 20]。
②映射到中间语言空间
该方法的基本思想是:将多语言文本都翻译为第三方语言或独立语种的符号系统,在中间语言空间中实现多语言文本独立于语种的表示。
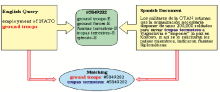
Ruiz等利用WordNet和EuroWordNet组织概念资源的层次结构,使用概念中间语言对词语进行不同语种的匹配,在此基础上实现跨语言信息检索[ 21],原理如图9所示,英文查询式通过概念中间语言(Concept Interlingua)可以对西班牙语文献进行检索。
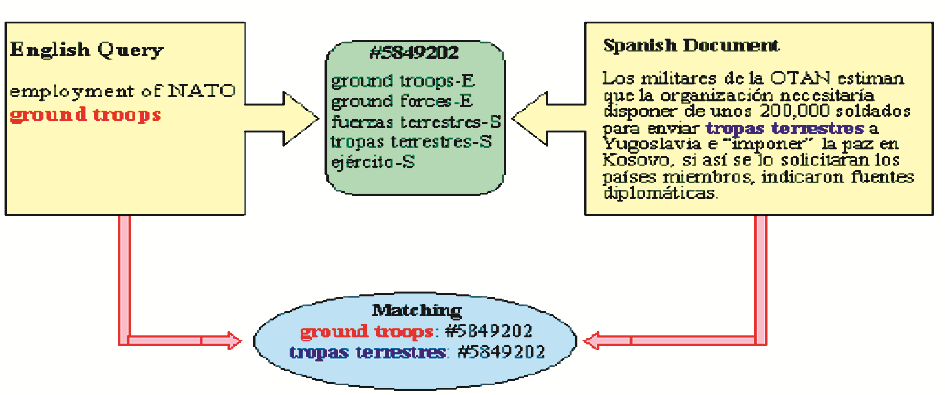 | 图9 通过概念中间语言进行跨语言匹配[ 21] |
1999年,Gonzalo等将不同语种的文档都用EuroWordNet的语间索引进行标引,实现多语言文本基于EuroWordNet中间语言空间的映射表示[ 22]。2000年,Hasan等考虑到中文、日语都是象形文字,提出了面向汉字字符的中间语言模型,实现了中日双语表示[ 23]。2004年,Korn等利用一个单字词典和一个类似主题词表的词集,将德语和葡萄牙语的医学双语文档集合都映射到独立语种的概念层(符号语言),实现双语独立语种的表示[ 24]。2005年,Guyot等将查询和文档都映射到多语言本体空间中相应的概念,实现了基于多语言本体的多语言文本表示[ 25]。该方法实质是通过多语言本体中的概念中间语言(即概念标识符)进行跨语言匹配。
(2)映射到多语言空间
将文本都映射到多语言空间的方法是一种无需文本翻译的方法。该方法使用多语言资源构建一个多语言语义空间,在该语义空间中进行多语言文本的跨语言表示,从而无需通过翻译,实现多语言文本的统一表示。目前,该方法包括基于潜在语义分析的模型和基于显式语义分析的模型[ 13]等。
①基于潜在语义分析的方法
该方法是利用平行(或可比)语料,通过潜在语义分析或核典型相关分析(Kernel Canonical Correlation Analysis,KCCA)生成隐含语义空间,将多语言的文本都映射到该语义空间中,实现多语言文本的向量表示。
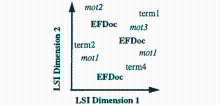
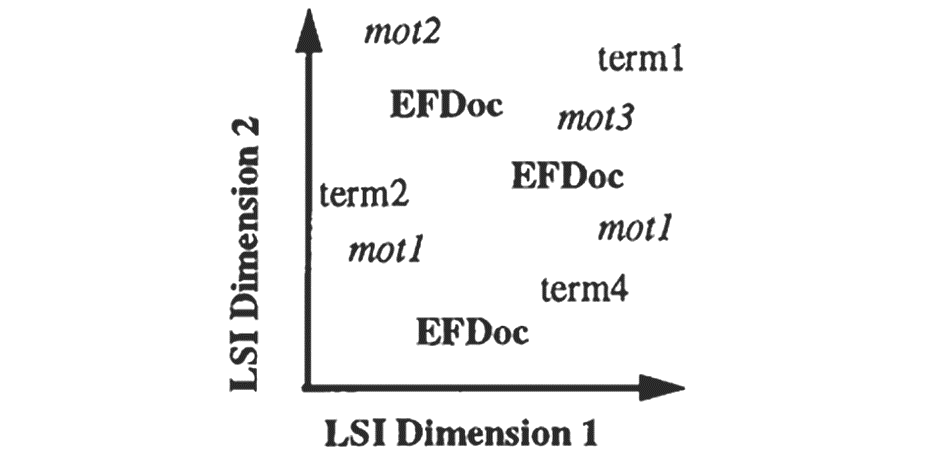
潜在语义分析或潜在语义标引(Latent Semantic Indexing,LSI),是利用统计方法提取潜在概念标引文本的一种方法[ 26]。1997年,Dumais等使用LSA进行英法双语表示并应用到信息检索中[ 27]。他们在实验中以英法平行语料作为训练集,利用LSA产生隐含的双语语义空间,如图10所示,其中EFDoc为训练文档,term1、term2、term3为英文特征项,mot1、mot2、mot3为法语特征项。该空间中具有相同意义的不同语言词对具有同一的表示,频繁关联的词具有相似的表示,双语文本特征并存,文档被表示为独立语种的向量。LSA方法无需翻译,但也存在许多缺陷,许多学者对其进行改进[ 28, 29]。有学者基于LSA进行多语言文本表示并应用到多语言文本聚类中[ 30, 31]。黄国斌等实现了基于LSA的中英双语文本表示[ 32]。
②基于核典型相关分析映射的方法
核典型相关分析是另一种通过训练语料学习推断文本潜在语义内容的方法。2002年,Vinokourov等使用KCCA实现了英法文本表示[ 33]。该方法基于双语语料,通过核函数将双语文本映射到同一语义空间;利用核典型相关分析学习空间中双语文本的语义关系;最终双语文本通过向量表示,查询则就它本身的语言投影到语义空间中。2006年,Li等利用KCCA从双语文档集合中推断出语义表示空间,实现日英双语表示并进行了跨语言信息检索实验[ 34],如图11所示:
③基于显式语义映射的方法
基于显式语义映射的方法与基于潜在语义映射的方法类似,不需要文本翻译,利用多语语料进行显式语义分析,将文本映射到多语言语义空间,实现多语言文本的跨语言表示。
2007年,显式语义分析由Gabrilovich等提出,是利用外部文档集合中预先声明的概念对文本进行标引的方法[ 35]。目前大多数基于ESA的方法所使用的外部文档集合为Wikipedia。2008年,Sorg 和 Cimiano以Wikipedia作为外部文档集合,使用ESA实现多语言文本表示[ 13]。在他们的方法中,利用机器学习构建语义解析器,将多语种文本都映射到多语言显式语义空间,再使用Wikipedia的跨语言链接,获取空间中不同语种文本的语义关系,最后利用该语义关系实现跨语言的文本向量表示。同年,Potthast等也使用Wikipedia作为外部文档集合,进行基于ESA的跨语言文本表示并应用到跨语言信息检索中[ 36]。2009年,Sorg 和Cimiano通过实验比较了ESA方法中不同参数选择对多语言文本表示应用效果的影响[ 37]。
映射到多语言空间的这些方法实质是利用训练语料,通过统计机器学习的方法构建多语言空间,实现多语言文本转换。其优点是无需事先构建或获取双语词典或语义资源,无需文本翻译;缺点是其效果受训练语料的规模和质量影响较大。
(1)基于LSA映射的方法和基于ESA映射的方法
基于潜在语义映射的方法和基于显式语义映射的方法的共同点是:无需进行文本翻译;通过语料学习生成语义空间;文本用独立语种的向量表示。两者的不同如表1所示:
| 表1 LSA方法和ESA方法差异比较 |
(2)基于LSA映射的方法和映射到中间语言方法
有研究者认为基于LSA的方法是一种映射到中间语言空间的方法[ 32, 38]。笔者认为基于LSA映射的方法是一种映射到多语言空间的方法,与映射到中间语言的方法有很多不同。
①映射到中间语言空间的方法需要通过文本翻译,将多语言文本都映射为中间语言(见图9,在跨语言匹配表示中双语文本都需转换为符号语言);而基于LSA映射的方法并不需要文本翻译,而是将文档都映射到多语言语义空间(见图10,LSA空间中双语特征并存)。
②映射到中间语言空间的方法实质是将多语言表示问题转化为单语言空间的文本表示;而基于LSA映射的方法是在语义空间中进行跨语言的文本表示。因此,基于LSA映射的方法是一种映射到多语言空间的方法,而不是一种映射到中间语言空间的方法。两者的共同点是文本映射结果都不是一种实际的语言,并且映射过程中融合了语义信息,如映射到中间语言空间的方法是将文本以概念层次映射到独立语种的符号语言,而基于LSA映射的方法是将文本都映射到语义空间。
(3)基于ESA映射的方法和基于机读词典方法
2006年,Chen使用词典知识库对文本进行翻译,实现了英汉双语表示[ 39]。该方法与基于WordNet对文本翻译的方法类似,是一种映射到单语言空间的多语言文本表示方法。与基于ESA方法的相同之处是:两者都使用含有语义信息的资源实现多语言文本映射。两者的不同主要体现在:ESA方法中无需文本翻译,在多语言空间进行跨语言的文本表示;而词典方法需要翻译文档,在单语言空间实现文本表示。同时,两者所使用的资源也存在很大差别,如表2所示:
| 表2 词典方法和ESA方法所用资源差异比较 |
(4)各种方法的综合比较
多语言文本表示中各种方法的特点、优缺点比较如表3所示:
| 表3 多语言文本表示方法比较 |
(1)依赖多语言资源。 当前的多语言文本表示的方法,需要借助如双语或多语词典、平行语料、多语言主题词表、多语言本体等资源获取翻译知识,跨越语言障碍,实现多语言文本的统一表示。因此多语言资源是进行多语言文本表示的基础。
(2)归为某种程度的一体化表示。 多语言文本的一体化表示可以归结为三类:统一转换为某一语种的语言表示;统一映射到中间语言空间进行表示;映射到同一语义空间表示。由此,多语言文本最终都转换为一定程度的一体化表示,这种一体化表示可以是同一语言的一致,或是同一语义空间的一致。
(3)从文本表面信息翻译深入到语义层次的表示。多语言文本表示的各种方法中,从词语直接翻译转换,到基于本体的翻译;从词语表面信息到利用词语之间潜在概念、人类预先定义的概念映射,融合语义信息的能力不断增强。
多语言文本表示经过多年的发展,技术和方法已相对成熟,但仍然存在不少问题。
(1)映射到单语言空间的方法
该方法实质是通过翻译实现多语言文本表示。其思想简单直观,实现相对容易,但在转换过程中,每进行一次语言转换就会造成一定的语义信息丢失;同时在翻译过程中,不可避免地会出现词汇歧义情况,进一步造成语义失真,最终会降低多语言文本表示的准确性和一致性,进而影响其在多语言信息处理中的应用效果。对于映射到中间空间的方法,则需要构建中间语言模型或独立语种的标识符,同时难以确保语言表示的一致性。
(2)映射到多语言空间的方法
该方法不通过文本翻译,最大限度地保留了文本的源信息,将语义损失的可能性尽可能降低,理论上其文本表示质量要优于映射到单一语言空间的方法,但也存在一些问题。基于LSA的方法,计算性能依赖于训练语料的规模和质量。如果训练语料规模太小,不足以进行正确有效的推理学习;若训练语料规模太大,计算复杂度会同时增加。另外,若训练语料具有较高代表性,则学习处理相对容易;否则,其性能会严重下降。 而基于ESA的方法,其资源是自由的自然语言文本,缺乏规范管理;概念由多人协作编制,易出现概念所指不一致的现象;此外用于获取多语言空间语义的跨语言链接,其规模有限。
多语言文本表示方法均需借助多语言资源,获取翻译知识,跨越语言障碍,因此其表示质量严重依赖多语言资源的质量。事实上,诸如双语词典、平行语料等资源属于稀缺资源,获取难度大,质量难以保证;即便是ESA方法所采用的Wikipedia多语言文档集合,同样存在规模受限、资源质量无法控制的问题。如何提高多语言资源质量或者减少对多语言资源的依赖,以降低多语言文本表示对多语言资源的依赖,提高文本表示质量值得深入探索。另外,对于多语言文本表示来说,由于至少涉及两种语言,即便是经过特征提取、特征降维,文本特征项的数量仍然是巨大的,对于这样大规模的高维数据,后续处理的计算开销是巨大的。如何将多语言文本特征的维度控制在一个可接受的范围内并且不降低文本表示的质量,也是一个亟待解决的问题。
多语言文本表示发展至今,其方法日渐成熟,但仍然存在一些问题。今后多语言文本表示的发展趋势主要体现在以下几个方面:
(1)自动或半自动构建高质量的可用多语言信息资源。可用多语言信息资源(如双语词典、平行语料、可比语料)是跨越语言障碍,实现多语言文本统一表示的基础。当前使用的多语言资源多需人工构建,耗力费时且质量低,因此自动或半自动构建高质量的可用多语言信息资源,仍是今后需要进一步解决的问题。WWW上的丰富资源为构建高质量的可用多语言信息资源提供了保障。
(2)多语言文本表示将更多地引入语义学知识。多语言文本表示从以表层的词法信息为主到逐渐引入到语义信息,绝非偶然,而是提高多语言文本表示质量的需要。未来多语言文本表示必然会将更深层的语义学知识融入其中,以提高文本表示质量。
(3)ESA方法的扩展应用。 ESA方法所利用的外部多语言集合,相对容易获取;且在信息指数增加的网络环境下,其文档集合所包含的语种比较丰富;同时,基于ESA的映射方法操作简单,可伸缩性强,结果易于解释,性能显著优于基于LSA及其他的一些方法[ 40]。在2009年CLEF的研讨会中,有两篇报告是有关ESA在跨语言信息处理中的应用[ 41, 42]。今后,基于ESA的方法将会得到更广泛的应用,以解决多语言信息处理的跨语言问题。
(4)寻找新的多语言文本表示方法。当前多语言文本表示方法都需要从平行语料或语义资源中获取翻译知识,进行空间映射,实现多语言文本关联,其性能受到语料、语义资源质量和规模的限制。以后的趋势是寻找一种不太依赖于平行语料或语义资源的方法,从根本上确保多语言文本表示的准确性和一致性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|