{kind=link}
{kind=link}
{kind=link}
基于.NET的农产品市场行情信息采集——以重庆农产品市场行情查询网为例
[陈诗琴1  , 李文江
, 李文江2 ]
, 李文江|
|


针对农产品市场行情信息的精确采集,综合运用WebClient类和开源类库HtmlParser.NET,自动生成行情信息动态网页的分页下载链接,将每个分页下载转换为静态网页。建立基于HTML结构特征的网页数据精确提取通用方法,实现循环提取所有行情信息数据。
According to the information collection for market quotation of agricultural products, the paper comprehensively uses WebClient and HtmlParser.NET to automatically generate the downloading link of dynamic Web page of market quotation, and converts each page downloading to the static page.The common method which can extract Web data accurately is founded based on HTML structure, and all market quotation data is extracted cyclically.
农产品市场信息的发布方式很多,网络发布是其中重要的一种。全国各省(区、市)农业信息网,大多设有农产品市场行情信息栏目,该栏目动态发布全省农产品批发市场的各种农产品交易信息。为了精确采集农产品交易行情信息,本文设计了一种基于.NET 的WebClient类库下载网页、HtmlParser.NET[ 1, 2, 3]类库解析提取网页数据的通用采集方法,该方法简单实用,采集成功率较高。
相关研究者对信息采集已作了大量研究,提出了许多优秀的提取策略,主要可分为以下4类:
(1)基于自然语言理解方式。一定程度上借鉴了自然语言处理技术,利用子句结构、短语和子句间的关系建立基于语法和语义的抽取规则,实现信息抽取。
(2)基于Ontology方式。主要利用对数据本身的描述信息实现抽取,对网页结构的依赖较少[ 4]。
(3)基于网页结构特征方式。根据Web页面的结构来定位信息,在信息抽取之前通过解析器将Web文档解析成语法树,然后通过自动或半自动的方式产生抽取规则,最终转化为对语法树的操作来实现信息的抽取。该策略实现简单,抽取的准确性好[ 5]。
(4)基于统计学习的方式。根据统计学原理,构造一个模型以模拟信息抽取的过程,应用统计学方法从训练语料中得出模型的参数,然后用训练好的模型对待抽取语料进行信息抽取[ 6]。
以上这些提取策略大多基于Java框架进行,而采用.NET框架的相对较少。虽然有很多优秀的基于Java框架的开源爬虫可供使用,但实际应用时需设置众多爬行提取规则,这给不熟悉Java框架的.NET开发人员带来了不少困难。在这样的背景下,本文选择基于网页结构特征方式的提取策略,介绍一种基于.NET类库(WebClient类库、HtmlParser.NET)采集结构化农产品行情信息的方法,该方法使信息采集简单可行。
行情信息网页是典型的动态网页,从数据库读取行情信息数据,以HTML格式传送至浏览器分页显示。不同分页的页面结构相同,根据这个特点,可将动态网页的每个分页下载转换为包含行情信息数据的静态网页。然后建立一个基于HTML结构特征[ 5]网页数据的精确提取通用方法,循环提取所有转换生成的静态网页数据。
浏览分析全国各省(区、市)农业信息网(如:“重庆农产品市场行情查询”、“贵州农业信息网-市场价格”、“西藏农牧信息网-市场价格”等)的市场行情栏目,发现它们有很多相同的特点:
(1)以列表形式显示行情信息,包括:农产品名称、交易市场、交易价格、单价单位、交易时间等;
(2)在行情信息列表以外区域提供多种查询方式;
(3)提供分页浏览行情信息的功能。
分析这些网页源文件,发现行情信息列表主要以Table标签构成为主,而查询和分页的实现方式则多种多样。其中以“网页URL+查询参数+分页参数”[ 7]的方式为主, 如“重庆农产品市场行情查询网” (简称“重庆行情网”),如图1所示:
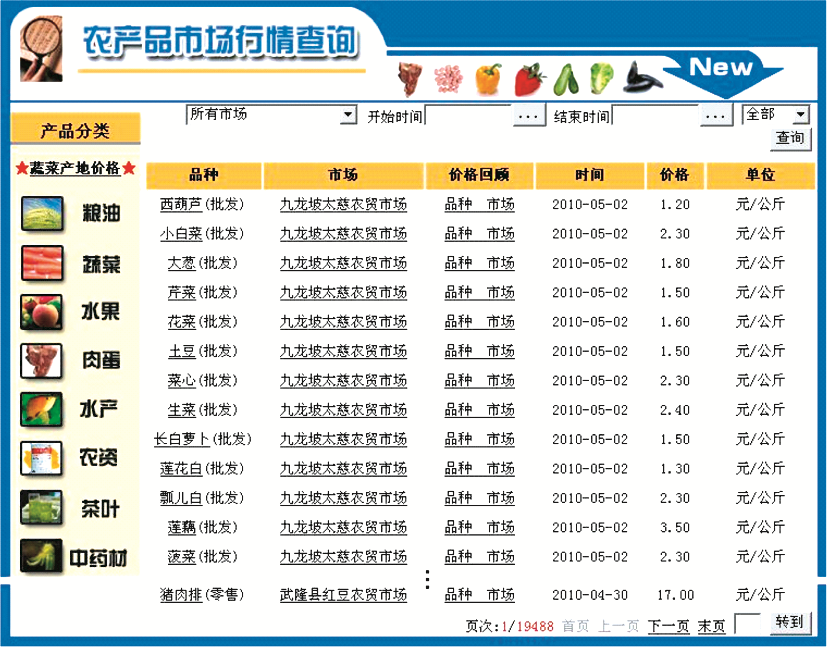 | 图1 重庆农产品市场行情查询网 |
农产品分类(如粮油、蔬菜和水果等)信息,在农产品市场行情数据分析时具有重要的作用。在“重庆行情网”中,行情信息列表并未包含农产品分类信息。为实现分类信息的采集,只有通过图1中的“产品分类”,逐类进行行情信息采集,然后添加分类信息。
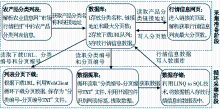
根据栏目特点和数据采集要求,采集过程分为两个阶段进行,如图2所示:
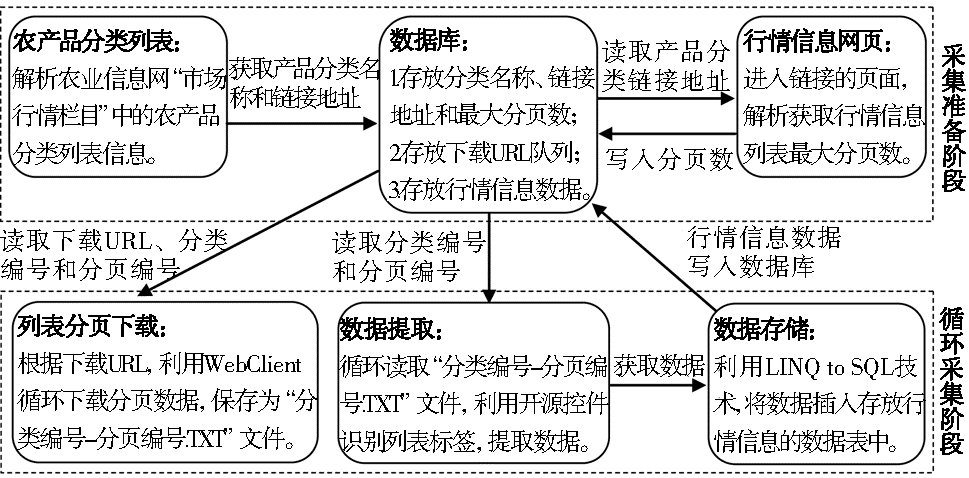 | 图2 按产品分类循环的采集过程 |
(1)采集准备阶段:从栏目中获取“产品分类”名称、链接地址,以及其对应行情信息列表的最大分页数,并存储到数据库中,同时生成分类编号。链接地址+分页参数就构成一个下载URL。分页参数取值范围为[1,最大分页数],根据参数范围,循环生成所有待下载的URL,存储在数据库中。
(2)循环采集阶段又分为两个过程。
①网页下载过程:从数据库中读取待下载URL、分类编号和分页编号,循环下载列表的所有分页数据,并按照“分类编号-分页编号.TXT”规则命名保存;
②数据提取过程:从数据库中读取分类编号和分页编号,循环读取“分类编号-分页编号.TXT”文件,然后识别文中的行情信息列表标签,提取行情信息数据,并将数据传递给数据储存过程,最后写入数据库。
本文以Microsoft Visual Studio 2008作为开发环境,在.NET 3.5框架下,采用VB.NET语言和SQL Server 2005数据库进行开发,并按照数据循环采集过程,实现模块化的设计。针对每个阶段的不同过程建立类[ 8],方便表现层对过程类的调用。
下载URL队列的生成需要获取分类信息和分页信息。
(1)分类信息采集:采用WebClient类的DownloadString方法,下载行情栏目首页,获取网页HTML字符。采用开源控件HtmlParser.NET解析HTML字符,利用Filter结点过滤模式[ 1, 2, 3],精确提取分类名称和链接地址。分类链接地址形如:http://www.cqagri.gov.cn/…/roster.asp? classID=1。
(2)分页信息采集:通过链接地址,进入行情信息列表页,使用分类信息采集的相同方法,提取“下一页”的链接地址和“页次”的最大值(即最大分页数)。“下一页”链接地址形如:http://www.cqagri.gov.cn/…/roster.asp? classID=1&Page=1。
根据带分页参数的链接地址形式和最大分页数,在1至最大分页数范围内,循环改变分页Page参数的值,自动生成不同分类待下载的URL地址。
以上所有过程封装在Creat_Uri_list类中。对应名称和作用描述如表1所示:
| 表1 Creat_Uri_list类 |
根据“重庆行情网”的时间区段查询方式,增加了StartTime和EndTime属性,分别对它们赋值,可实现按时间区段采集行情信息。增加这两个属性后,分类链接地址做了修正,即添加时间查询参数,形如:http://www.cqagri.gov.cn/…/roster.asp? classID=1& startTime=2010-03-08&endTime=2010-05-08。修正后的分类链接地址+查询结果分页参数,则构成按时间段下载的URL地址。
系统公共模块(BaseData)取出数据库中待下载的URL、产品分类编号和分页编号,传递给网页下载和数据提取过程使用。模块封装了三个属性和一个方法,其名称和作用描述如表2所示:
| 表2 BaseData公共模块 |
其中,Class_ID和Class_PageNum属性值主要提供给Save_File_Path方法使用。
Save_File_Path方法由“FileSystem.CurDir() + "\down_data\" + Class_ID + "-" + Class_PageNum + ".txt"”构成。在网页下载时,返回网页的保存路径;在数据提取时,返回读取文件的路径。
信息采集的成功与否主要取决于网页下载模块,该模块是整个信息采集过程中的关键环节。在设计网页下载过程中,选择WebClient类、WebRequest类和WebBrower类,分别采用同步、异步和多线程下载方式,针对“重庆行情网”行情信息100-1000个分页页面作下载对比实验。从下载100个分页开始,依次增加100个分页,共做了10次实验,得出以下结论:
(1)所有类库在异步和多线程下载时,速度比同步方式要快,但随着分页深度的增加,下载失败分页数不断增加,影响了下载成功率(成功下载分页数/总分页数);而同步下载方式虽然随着分页深度的增加,速度有所减慢,但出现下载失败分页数较少;
(2)所有类库都随着分页深度的增加,下载速度逐渐减慢。当深度超过500后,只有WebClient类采用同步方式还能继续下载。
究其原因,主要与被采集的网站有很大关系。行情信息数据根据时间降序排列。在查询时,分页深度随交易时间的久远而加深,查询响应时间也有所增加。同时,数据库对请求用户数量作了限制,控制并发操作等。
考虑WebClient类在实验时“下载失败分页数较少”的优点,结合实际采集情况,采用同步和异步两种下载方式,分别用于采集分页较深的历史行情信息和分页较浅的最新行情信息。将这两种下载方式封装在下载模块(HtmlDown_TxtFile)中。它们的实现过程基本相同:
(1)建立WebClient对象;
(2)设置WebClient.Encoding字符编码方式;
(3)获取待下载URL(公共模块Class_Down_Uri属性值)和文件保存路径(Save_File_Path返回的值);
(4)同步方式执行DownloadFile方法,异步方式执行DownloadFileAsync方法。
下载过程中遇到下载失败时,会重复执行失败的URL,当重复5次后仍无法下载则放弃,继续进行下一个URL下载。
数据提取的开源类库很多,但大多是基于Java框架的。本文采用基于.NET的HtmlParser.NET类库,利用Filter结点过滤模式[ 1, 2, 3],分析行情信息网页文件、精确提取行情信息列表Table标签的数据,并存储数据。
数据提取模块(TxtFile_Parser)封装了4个方法,其实现功能和方法描述如表3所示:
| 表3 TxtFile_Parser类的方法 |
其中,Filter方法是实现数据提取的核心。采集“重庆行情网”Filter方法的关键代码如下:
Public Sub Filter()
If File.Exists(Save_File_Path) = True Then
Dim str As String = Read_File_Str()
Dim Lexer As New Lexer(str)
Dim Parser As New Parser(Lexer)
Dim htmlNodes, tdNodes As NodeList
Dim Species, Market, Time, Price, Unit As String
htmlNodes = Parser.ExtractAllNodesThatMatch(New _ TagNameFilter("tr"))
'获取所有行节点
For i As Integer = 1 To htmlNodes.Count - 5 '行情信息起止行定位
tdNodes = htmlNodes.ElementAt(i).Children. _ExtractAllNodesThatMatch(New TagNameFilter("td")) '获取列节点
Species = tdNodes.ElementAt(0).ToPlainTextString '产品名称
Market = tdNodes.ElementAt(1).ToPlainTextString '市场
Time = tdNodes.ElementAt(3).ToPlainTextString '交易时间
Price = tdNodes.ElementAt(4).ToPlainTextString '价格
Unit = tdNodes.ElementAt(5).ToPlainTextString '单价单位
Insert_Data(Species, Market, Price, Unit, Time) '储存数据
Next
File_Del() '删除已提取的文件
End If
End Sub
采集“重庆行情网”2010年3月8日至2010年5月8日时间段内的行情信息作为实验数据。
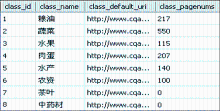
将行情信息栏目地址和时间赋值给Creat_Uri_list类,自动完成分类名称、链接地址和最大分页数的提取,结果如图3所示:
 | 图3 分类信息数据表 |
当上述过程完成时,程序自动生成待下载的URL地址,共计1 329个URL,保存在agr_down_uri表中。
调用Creat_Uri_list类的程序代码如下:
Dim Creat_URL As New Creat_Uri_list
Creat_URL.Defaul_Uri = "http://www.cqagri.gov.cn/marketSta/"
Creat_URL.StartTime = "2010-03-08"
Creat_URL.EndTime = "2010-05-08"
Creat_URL.Insert_Class_Info()
待下载URL以分页深度升序排列,实现行情信息按由浅到深的顺序下载。同时,对相同分页深度的不同分类行情信息按所属分类编号顺序下载。对已经下载的URL作标记,便于出现错误后继续下载。
调用网页下载HtmlDown_TxtFile类的程序代码如下:
Dim HtmlD As New HtmlDown_TxtFile '定义网页下载类
Dim w = From r In db.agr_down_uri Select r Where r.downed = 0 Order By r.page_num
For Each s In w
Dim uri_id As Integer = s.id
BaseData.Class_ID = s.class_id
BaseData.Class_PageNum = s.page_num
BaseData.Class_Down_Uri = s.url '获取下载URL
HtmlD.WebClient_Tb() '同步下载方式
Dim d = From r In db.agr_down_uri Select r Where r.id = uri_id '标记已下载过的URL
For Each com As agr_down_uri In d
com.downed = 1
db.SubmitChanges()
Next
Next
数据提取循环控制和网页下载控制过程一样,主要是采用循环控制TxtFile_Parser类的Filter方法实现数据提取。
整个实验结果如表4所示:
| 表4 实验结果 |
网页下载过程共用120分钟,成功下载了图3中6个分类的所有网页文件,共计1 329个,其中有部分文件重复了几次才下载成功,所以整体成功率为100%(网页下载与网络是否畅通和访问网站诸多因素有关,本次实验成功率100%并非指一次性成功下载率)。每个网页文件(除“末页”文件外)包含40条行情信息,6个分类的“末页”网页文件分别为:38、8、6、18、10和35条行情信息,所有网页文件共计53 035条行情信息。
数据提取过程用时44分钟,成功解析了1 329个网页文件,共提取53 035条行情信息数据,这与网页实际包含的行情信息数据条数一致,所以提取数据过程成功率为100%。
从基于.NET类库的“重庆行情网”网页信息采集实例中,可以发现信息采集的关键在于下载URL队列的生成和网页下载策略的选择。自动生成下载URL队列,避免了重复获取不同页面中“下一页”链接地址;运用WebClient同步和异步方式下载网页,两种方式有机结合、取长补短。另外,开源类库HtmlParser.NET的运用,使数据提取过程变得十分简单。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|