






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于本体和关联数据的书目组织语义化研究
[白海燕 , 乔晓东]
, 乔晓东]
, 乔晓东]
|
|


以书目对象基于形式形态多样性、生命周期变化性、复合对象复杂性的序化问题作为书目语义化组织的研究起点,提出并初步实践基于本体构建语义关联、通过关联数据的一致化语义描述方法(RDFS/OWL)和统一存取机制(SPARQL)进行语义化组织的方法。
The origin of this research is bibliography organization based on the multiplicity of information forms, variability in information lifecycle and complexity of hybrid object. The paper proposes and practises the basic idea of semantic organization of bibliography that build semantic linking based on Ontology, describes semantic information accordantly using RDFS/OWL and SPARQL.
语义网技术如本体、关联数据等在信息组织领域中的应用是近年来的研究热点。而书目数据是图书馆领域最具价值的信息资源之一,本文在分析现有书目组织方法的问题与局限的基础上,提出基于本体构建数据组织模型,通过关联数据的一致化语义描述方法(RDFS/OWL)和统一的存取机制(SPARQL)增强书目组织语义化的思路,并通过构建书目本体和应用开源软件,进行了初步的实现。
传统书目组织是基于MARC的一维、线性组织。MARC的优势在于结构化程度高,通过代码化的字段和子字段置标书目的内容特征和外在特征;缺点在于描述语言的通用性和语义性差,只有元数据描述,缺少从语义到语法结构到模型及著录规范和算法的完整体系;而一维和线性的组织方式,是以某一属性特征作为索引点和检索点,不区分信息对象的实体层次和相互的关联关系,在实际应用中,特别是数字环境下,存在很大的局限性,突出表现在缺少对于信息对象表现形式的多样性、生命周期的变化性、衍生性和复合对象的复杂性的关系描述和基于关系的序化,即语义化程度较低[ 1, 2]。
(1)信息对象多样性的检索案例分析
以《哈里波特与火焰杯》一书为例,同一信息对象具有多种形式和形态特征,包括不同的载体形式、版本形式(全本、缩略本等)、译本形式(原语种、翻译本)、装订形式(精装、简装)、信息形态(全集、单行本等)、体裁形式(小说、电影、有声读物等)等,有必要按一定的特征进行汇集和聚类,达到深度序化和有效组织的目的,以帮助用户提高查询、识别和获取的效率。
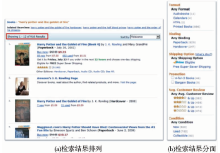
在Amazonhttp//:www.joyo.com的查询网站上,《哈里波特与火焰杯》一书的检索结果显示共命中916条记录,采取平铺的线性排列,对各种形态不加以区分,不能按某一特征进行汇集和聚类。例如用户要找到阿拉伯文的有声读物,只能逐条逐页进行查找,很难快速定位,如图1(a)所示:
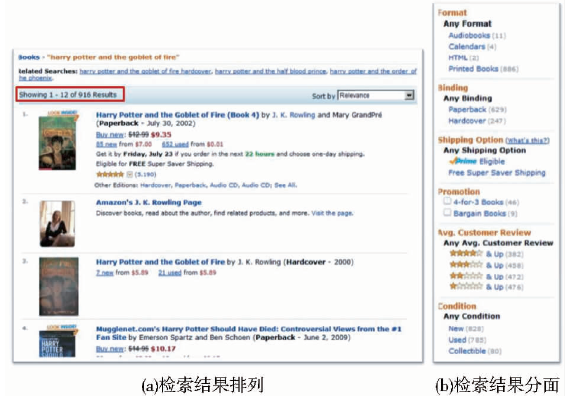 | 图1 《哈里波特与火焰杯》的检索结果 |
为了改进平铺排列的信息组织方式,Amazon和众多OPAC系统一样,采取了分面(Facet)检索和浏览的组织方式。分面是以一定的形式形态特征如载体、语种、出版地、年代、体裁、主题等为维度,将数量比较大的结果集划分为几大部分,每一维下按相同的特征进行集中或提供小范围内的二次检索。以《哈里波特与火焰杯》为例,查找阿拉伯文的有声读物,需要按“语种”和“载体”两种特征划分,而分面栏(见图1(b))中,只有“Format”的载体分面而没有“语种”特征的分面条件。可见分面组织仍面临一些问题:应该提供哪些属性特征作为分面的条件,如何组织和体现各个属性特征之间的相互关系,如何根据检索不同阶段的结果,动态地选择分面条件等,是分面组织需要解决的关键和难点。
(2) 信息对象变化性和动态性的检索案例分析
信息对象具有变化性和动态性。在数字环境下,信息对象的变化和衍生特点非常突出,对信息组织的适应性提出了更高的要求。以《Atlantic Monthly》一刊为例,自创刊以来,有5次刊名(Atlantic Monthly和Atlantic的交替变化)和多次ISSN的变化,同时有多次出版地、出版周期、载体形式的变化。
但在现有的书目检索系统中,对信息对象变化性和动态性的检索和揭示效果并不理想。以美国国会图书馆的OPAC查询http//:www.loc.gov为例,以题名Atlantic Monthly为检索条件,命中47条记录,但存在以下问题:
①出现漏检,如刊名为Atlantic的记录由于形式不匹配Atlantic Monthly而没有命中;
②书目之间的变化关系没有显性揭示,该刊的5次刊名和多次ISSN变化关系没有显示;
③信息对象的同一性没有揭示,即多条记录属于同一期刊品种无法体现。
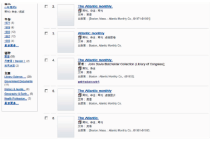
同样以题名Atlantic Monthly为检索条件,在OCLC的WorldCat的OPAChttp//:www.worldcat.org中检索,结果如图2所示。命中效果稍好于美国国会图书馆的结果,Atlantic Monthly、Atlantic两种刊名形式都有命中,检全率高于美国国会图书馆,但信息对象的同一性揭示问题仍然没有解决。
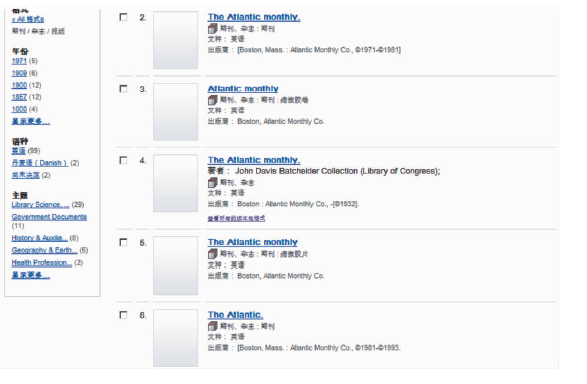 | 图2 OCLC的OPAC查询结果 |
综合以上案例分析,在信息对象的同一性没有显性揭示的情况下,很难清晰地揭示各种衍生和变化的书目关系;尽管书目著录比较详尽,但由于没有显示信息对象之间的关系,细节信息反而容易成为检索结果选择的干扰信息;而从检索结果的组织来看,没有依据信息对象的关系进行组织,是造成漏检或命中数据量过多的重要原因。
(3)复合信息对象的组织难度分析
复合信息对象的概念,来自于e-Science和科学出版领域,原指包括文本、图像、音频、视频等不同载体类型、不同内容类型(如文章、图书、数据集等)、媒体格式(如PDF、XML、MP3等)以及不同时间、空间版本和不同语义类型(比如线性关系、版本关系、引申关系、整部关系等)的信息单元,是多个信息单元按一定逻辑关系组合起来的整体集合。复合数字对象具有突出的多层性、可嵌套、可重组和多态性。因此,其信息描述、组织与检索需求日益受到重视[ 3, 4, 5]。
复合信息对象在传统文献中主要表现为多集、多册、多卷文献,文献与其单篇析出,大的会议集与所包括的若干小会议集等,而其描述与组织要求体现这种复合和等级关系,但实际系统中的表现并不好。在国家科技图书文献中心(NSTL)的查询系统中,《BBA》一刊包括9个子集,但无论是用总集名还是用各个分集名查询,都只有分散的个别揭示,而无法总览全貌。当复合对象具有多载体表现和生命周期变化时,管理的组织难度更大。主要表现在:
①以提供容纳和聚合多种媒体类型、内容类型、语义类型、不同版本类型的体系结构;
②检索结果没有语义关联,缺乏数据来源的背景信息,缺乏可选择性、交互性或者灵活性,没有针对信息对象不同粒度层次的访问分级,显示或者展现方式不够灵活[ 3, 5]。
(1)书目组织问题的普遍性
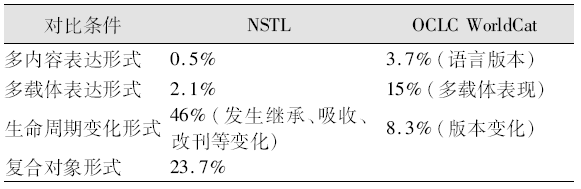
书目组织的问题具有普遍性。OCLC WorldCat的馆藏统计数据显示,全部馆藏中,有12%的资源品种具有2-5种表现形式,1%的资源品种具有超过5种以上的表现形式,只有一种表现形式的资源品种占87%。如果将这一统计扩大到所有成员的多家馆藏,则多表现形式的馆藏所占比例非常高:具有超过5种以上表现形式的资源所占比例由1%扩大到17%,而具有2-5种表现形式的资源所占比例由12%扩大到40%[ 6]。资源的多表现形式特性随着馆藏资源的增加和联合馆的增加而更加突出,对于资源的管理,包括馆藏统计、资源分析、管理决策等具有显著影响。
NSTL的联合目录系统由9家成员单位的书目资源组成,收藏以理、工、农、医的西文连续出版物、会议录等印本资源为主体,总计约20万条书目记录。NSTL资源的载体表达形式比较单一,出现多载体形式的资源仅占2.1%;多语种文献较少,多内容表达形式所占比例只占0.5%;而连续出版物具有出版的多变性和衍生性,因此,生命周期的变化形式,如期刊发生继承、吸收等改刊情况所占比例非常高。相比之下,OCLC由于收录全世界范围的文献,而OCLC的成员馆又多以图书为收藏主体,所以其多语言版本比例高于NSTL,而版本变化比例低于NSTL。NSTL与OCLC的馆藏多样性对比如表1所示:
| 表1 NSTL与OCLC的馆藏多样性对比 |
(2)书目组织语义化的必要性
进一步剖析目前信息组织方式的局限原因,主要在于资源描述语言、资源组织模型和资源组织机制的局限。而书目组织的语义化则是相对传统的书目描述、组织和检索方式,显性地、以机器可读的方式表达书目的属性特征和关联关系,基于规范的组织模型,对书目实体之间和属性之间的关系进行序化,并提供基于语义关系的、统一的存取方式。具体实现包括:
①划分书目实体层次,分离属性特征,提炼实体间、实体与属性间的关系,以获得实体和语义关系,并基于RDF的节点和边组成的有向图,显性地、以机器可读的形式描述和表达各种关系;
②基于本体构建资源组织模型,通过“概念语义”进行概念规范,对与书目组织领域相关的概念,如DC、FRBR、MARC、OAI-ORE等进行一致化理解,并采用普遍认可、相对固定的词汇集进行描述;通过“规则语义”进行关系约束和规则设定,固化基于网状关系的多维、立体的组织模式;
③建书目本体和实例数据在数据层的链接机制,构建具有结构化和富含语义的数据网络,通过统一的数据模型、一致的语义描述方法,提供统一的存取方式[ 2, 7, 8]。
书目本体是基于书目关系进行语义化组织和语义关联构建的数据模型。本文参考了相关书目本体如MarcOnt Ontolgy、Bibliographic Ontology Specification等,引用了通用词表,吸收了FRBR、OAI-ORE、DCMI等的概念模型和标准规范,并利用Protégé工具构建了以连续型出版物为主体的科技文献组织的书目本体。
(1) 相关书目本体
① MarcOnt Ontology
为了便于采用不同元数据方案描述书目信息的机构之间交换数据,欧盟DERI(Digital Enterprise Research Institute)的研究人员整合了MARC21、DC和BibTeX,构造了MarcOnt本体,试图提供一个统一的书目信息描述框架,以便通过格式转换、规则映射,解决不同元数据标准的整合和一致化。
图书馆用户可以分为三类,每一类用户都需要不同的描述格式:
1)图书馆员以及与图书馆有关的用户使用详细的描述格式MARC21;
2)研究人员以及与学术有关的用户使用引文关系描述格式BibTeX;
3)普通网络用户使用简单描述格式Dublin Core。
一般情况下,数字图书馆系统针对其目标用户仅支持一种描述格式。MarcOnt书目本体力图提供一个统一的书目描述格式,从现有的书目格式如BibTex、Dublin Core、MARC21中提取概念,定义了34个大类和43个属性。MarcOnt目前被用于Jerome数字图书馆http://jeromedl.org/ 〖ZW)〗提取资源的书目描述信息和不同格式之间的书目描述转换[ 9, 10, 11]。
② Bibliographic Ontology Specification
为了在语义网环境下管理参考文献和引文信息,D’Arcus、Giasson等开发了基于RDF的书目本体——Bibliographic Ontology Specificationhttp://bibotools.googlecode.com/svn/bibo-ontology/trunk/doc/index.html,提供描述引文和参考文献如图书、论文等的概念与属性描述,其中包括69个类、 52个对象属性、54个数据属性。
该本体基于许多现有的文档描述元数据格式构建,可以作为转换其他书目数据源的通用基础。该本体不是ISO或W3C意义上的本体,但却非常依赖于W3C的标准化成果,尤其是XML、XML命名空间、RDF以及OWL,所有的书目本体文档必须是格式良好的RDF或XML文档。因此,该书目本体具有强大的可扩展性,基于该本体的书目描述可以与其他RDF词汇描述的声明合并[ 11]。
(2) NSTL书目本体构建
本文参考了上述书目本体,并引用了以下词表:Dublin Core Element Sethttp://purl.org/dc/elements/1.1/、RDA Elements、 Metadata Management Associateshttp://RDVocab.info/Elements 、FRBR Entities、CDLR (Centre for Digital Library Research)http://metadataregistry.org/uri/schema/frbrentities,构建的书目本体包括18个类、31个对象属性、379个数据属性。
①书目本体的类
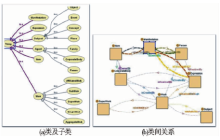
参照FRBR、OAI-ORE、DCMI等的概念模型和标准规范,确定了书目数据的实体区分和析出,主要包括作品及其子类、载体表现和内容表达。构建18个类,如表2所示:
| 表2 NSTL书目本体的类 |
类之间的等级关系图3(a)所示:
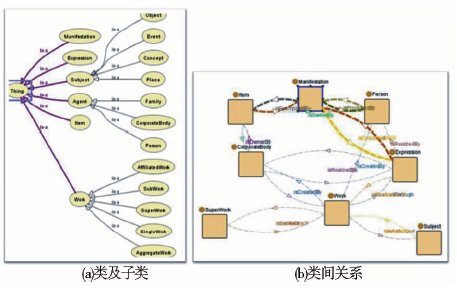 | 图3 书目本体的类 |
②书目本体的对象属性
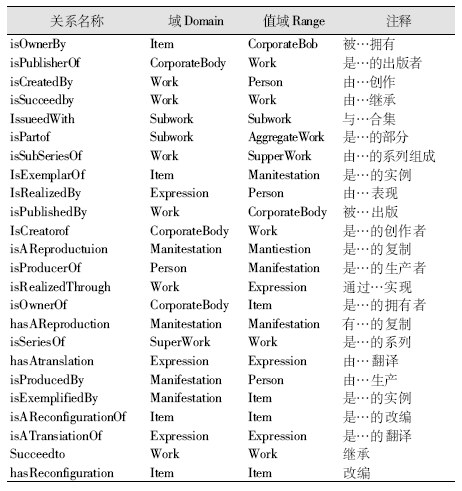
书目本体建立了类与类之间的关系(见图3(b)),也称为对象属性,具体描述如表3所示:
| 表3 书目本体的对象属性 |
③书目本体的数据属性
每一个实体都有自己的属性,如“作品”的属性,包括题名、形式、日期、其他类型特征、内涵等。本文基于RDA,确定了相应的每一实体的具体属性,及每个属性元素的类型、适用的域、替代值、字串值、语法编码体系、词汇编码体系等;为了兼容和支持现有资源描述体系ISBD和MARC标准,主要通过RDA的属性集与USMARC的映射和引用来实现。
利用Protégé的SPARQL查询工具及可视化工具,对NSTL的具体实例数据进行了重新组织,通过动态分面查询、语义关系查询和复杂查询的实现,一定程度上解决了信息组织的问题与局限,验证了本研究的有效性和可行性。
(1) 动态分面查询
分面查询是指以某一或某些属性特征作为信息分组依据。主要目的是在大数量检索结果的组织方面,通过属性或特征划分,将大数量检索结果分为较小的结果单元,以提高用户的信息吸收水平。通常使用的分面方法是静态分面,其特征如下:
①属性特征必须是预先确定的,并事先进行抽取和建立索引;
②不支持动态数据的特征提取和关系提取;
③不支持对特征本身的分层,原因是不支持对关系的描述和提取,包括对象属性和数据属性关系。
因此,对于大数量集和多属性集而言,静态分面的信息组织方式在划分数据集和分级方面,仍然存在很大局限。相比之下,动态分面的解决方式有一定的优势,具体表现在:
①属性或关系即分面的依据,在检索的任意阶段可以任意提取,实现动态分面;
②根据实体之间的关系以及属性之间的关系,指定特定类型、值域的属性或关系,可实现分层分面,即对属性关系进行组织后再用于大数集的划分。
采用本体组织的分层的书目体系,信息对象按类和类的属性进行划分,因此能够比较容易地提取出特定类的属性特征,通过类与类之间的关系,得到属性之间的关系。因此,可以在检索的任意阶段,提取属性特征,并根据实体之间的关系,对数据集进行划分和分组。
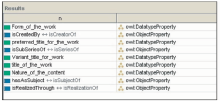
例如,通过SPARQL语句,能够非常容易地提取所有的对象属性和数据属性,代码如下所示:
prefix istic:
SELECT ? n
WHERE {?n rdf:type owl:ObjectProperty}
SELECT ? n
WHERE {?n rdf:type owl:DatatypeProperty}
得到的检索结果分别是所有的对象属性和数据属性,如图4所示:
通过增加一些限制条件,可以限定提取某一类型的对象或属性,例如提取“Work”类的所有属性,如图5所示:
 | 图5 查询结果-Work类的所有属性 |
(2) 语义关系查询
书目本体将信息对象之间的关系,以形式化的方式明确而规范地表达出来,因此,可以基于这种对象之间的关系进行检索查询和浏览展示。
例如实现基于特定关系的查询,通过SPARQL语句,以“具有分集”作为查询条件,查询所有聚合型作品及其所包括的子集。查询命令[ 12]如下所示:
prefix istic:
SELECT ? title ? sub_title
WHERE {?n:hasPart ? o.
? n:title_of_the_work ? title.
? o:preferred_title_for_the_work ? sub_title.}
检索得到BBA及其9个子集,结果如图6所示:
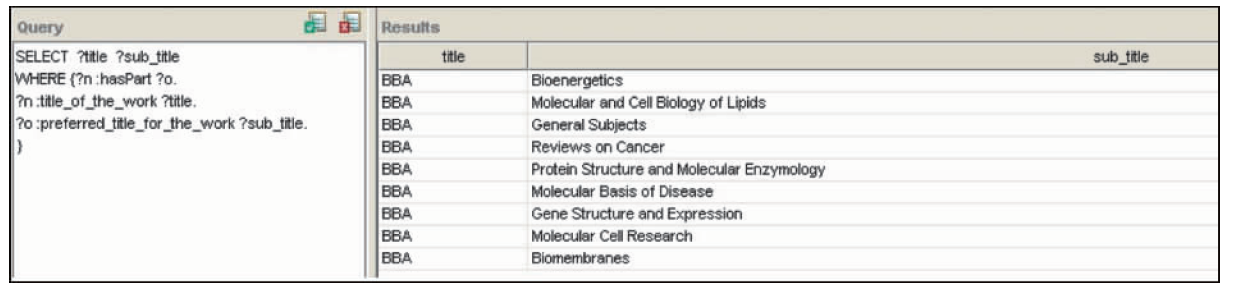 | 图6 查询结果-BBA及其子集 |
可以通过可视化工具,显性地展示总集及其分集之间的关系,如图7所示:
 | 图7 BBA及其子集的可视化查询结果 |
通过基于关系的查询,可以比较好地展现资源之间的结构关系和演变情况,例如,日文刊《解剖学杂志》创刊于1928年,2005年同时发行日文版和英文版两种版本,以下查询实现了基于资源结构关系和变化情况的检索。查询命令[12]如下所示:
SELECT ?title1 ?date1 ?Succeed_to ?title2 ?date2 ?isRealizedThrough ?othertitle ?language
WHERE {?n:Succeed_to ?o.
?n:title ?title1.
?o:title ?title2.
?n:data ?date1.
?o:data ?date2.
?o:isRealizedThrough ?other.
?other:title ?othertitle.
?other:Language_of_expression ?language}
通过可视化工具显性、直观地展示对象之间的关系,演变如图8所示:
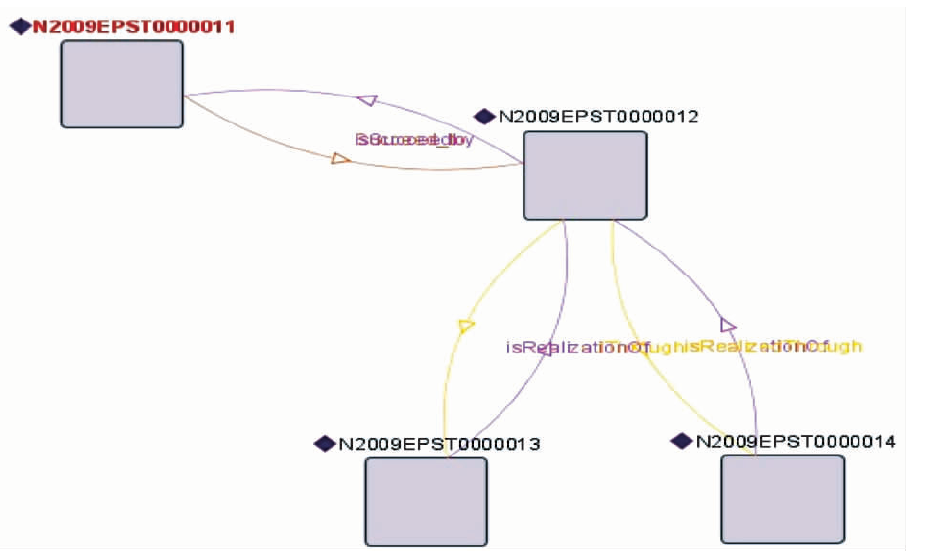 | 图8 《解剖学杂志》的可视化演变结构 |
(3) 复杂智能查询
利用对象之间的关系和属性之间的关系,以及利用SPARQL的查询特性,可以实现以往基于线性组织和关系数据库不可能实现的复杂智能查询。例如,查询由创建历史超过100年,出版过科学、技术、医学学科出版物的出版公司发行的,创刊时间超过50年,医学外科方面,同时具有电子版和印刷版的期刊。查询语句[12]如下:
SELECT ?s ?o ?p?d ?n ?x ?media
WHERE { ?s:isPublishedby ?o.
?s:pubdate ?y.
?s:hasAsSubject ?subject.
?subject:Term_for_the_concept ?n.
?o:Name_of_the_corporate_body ?p.
?o:Date_of_establishment ?d.
?s:isEmbodiedIn ?x.
?x:Media_type ?media.
filter (?d<=′1910’ && ?y <=′1960′ && ( regex(?n,"Science","i") || regex(?n,"Medical","i")||regex(?n,"Surgery","i")||regex(?n,"Agriculture","i"))&®ex(?media,"print","i") || regex(?media,"electronic","i") )}
查询结果如图9所示:
 | 图9 复杂查询结果 |
书目数据以MARC格式存储于关系型数据库中,一般通过相互关联的三张表实现存储与管理,即MARC数据表、简目表和索引表。如何将基于关系型数据库的二维表转换为RDF的三元组,以实现基于SPARQL的灵活查询,如何将一维、线性的语义模式转换为本体的语义模式,成为实现书目语义化组织的关键。本文利用开源软件D2Rhttp://www.w3.org/2001/sw/wiki/D2RServer的关联数据(Linked Data)构建机制,初步实践了通过映射实现关系型数据库向本体的语义模式转换,并提供基于RDF链接的富含语义的多种关联数据获取与访问方式[ 13]。
(1)D2R的结构与实现机制
①体系结构
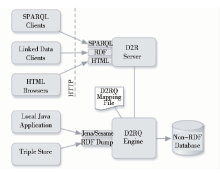
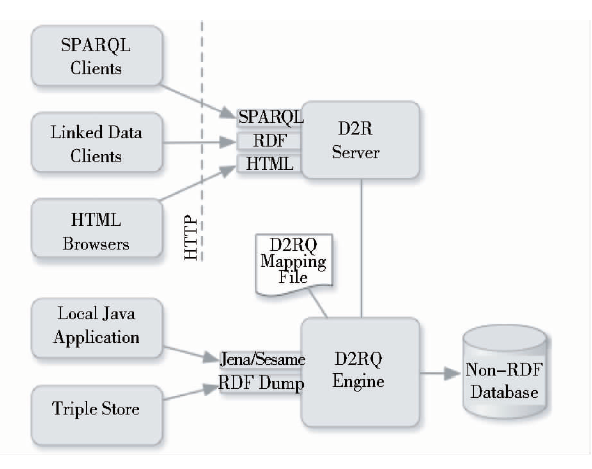
D2R是目前较为流行的关联数据开源软件。D2R Server的体系结构如图10所示:
主要包括以下三个部分:
1)D2R服务器(D2R Server),是一个HTTP Server,它的主要功能是提供查询RDF数据的访问接口,以供上层的RDF浏览器、SPARQL查询客户端以及传统的HTML浏览器调用;
2)D2RQ引擎(D2RQ Engine),主要功能是使用一个可定制的D2RQ Mapping文件将关系型数据库中的数据换成RDF格式;
3)D2RQ映射语言(D2RQ Mapping File),主要功能是定义将关系型数据转换成RDF格式的映射规则[ 14, 15]。
② D2R的运行机制
使用D2R可以对关系型数据库的数据进行两种方案的转化与访问:
1)将关系型数据库的数据转换为虚拟的RDF数据,通过 D2R Server访问关系型数据,或者通过Java Application,调用Jena/Sesame的API去访问数据;
2)直接将关系型数据库的数据包装成真实的RDF文件,以供一些可以访问RDF Store的接口访问。
一般来讲,数据库的数据规模都比较大,且内容经常发生变化,转换为虚拟的RDF数据空间复杂度会更低,更新内容更加容易。本文选用第一种方案,主要分为两大步骤实现:生成映射(Mapping)文件;使用映射文件对关系型数据进行转换与访问。该文件的作用是在访问关系型数据时将RDF数据的查询语言SPARQL转换为关系数据库数据查询的SQL语言,并将SQL查询结果转换为RDF三元组或者SPARQL查询结果。D2RQ能够提供对复杂关系结构的灵活映射,而不改变已经存在的数据模式。这种灵活性是通过在映射规则中直接使用SQL语句获得。
D2RQ引擎建立在Jena(Jena是一个创建Semantic Web应用的Java平台,提供了基于RDF、SPARQL等的编程环境)的接口之上,将Jena、 Sesame API、 Find和SPARQL查询重写为应用数据模式的特定SQL查询,SQL查询结果集转为RDF三元组或者是SPARQL的结果集,返回到更上一层的结构,关系型数据库中的数据输出为RDF、N3、N-Triples 或Jena Models[ 14, 15]。
本文选用支持Windows平台的D2R 7.0http://sourceforge.net/projects/d2rq-map/files/D2RServer/版本,数据库为SQL Server 2005,Java环境的版本为 JDK 1.6[ 14, 15]。
(2)基于D2R映射的语义模式转换
①数据组织模式的转换要求
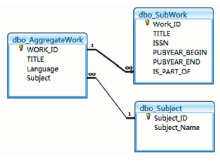
一维、线性的书目数据,需要依照本体的组织模式,进行相应的处理与转换,即参照书目本体的类和属性,抽取和分离出书目数据中相应的对象和关系。本文对NSTL关系数据库中的MARC数据,按照一定的处理规则和算法[ 16, 17, 18],分离和析出不同的实体,为每个实体建立一个表。例如AggregateWork、SubWork和Subject三个实体,其数据表及实体间关系体现了书目本体的语义模式,即聚合型作品是由分集作品组成的,聚合作品的主题表达来自于主题词表[ 19, 20, 21],这种语义模式通过二维表之间的主键和外键引用的隐性表达实现,如图11所示:
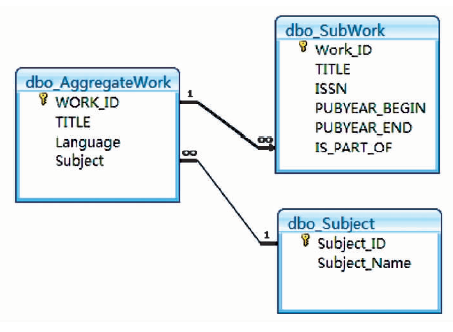 | 图11 关系型数据库的组织结构 |
对此三类表的关联数据转换和发布要求是:发布所有的表和字段;发布和展现表与字段的关系;发布和展现表之间关系。
②基于映射文件的Schema转换
将关系型数据库的二维组织模式转换为RDF的三元组表达,将数据结构、约束条件转换为本体的概念语义和规则语义,需要构建关系型数据库模式与RDF的Schema的映射,以完成模式的转换。D2R Server提供了基于映射文件,将数据库发布为RDF三元组的机制,具体是通过执行D2R生成映射文件的执行脚本——Generate Mapping来实现[ 14, 15]。
D2R映射语言中最重要的是两个概念是:d2rq:ClassMap和d2rq:PropertyBridge。d2rq:ClassMap代表OWL Ontology或者RDFS Schema 中的一个或一组相似的Class,它一般映射到关系数据库中的一个表。d2rq:PropertyBridge 代表OWL Ontology或者RDFS Schema中Class的属性,它一般映射到关系数据库中某个表的一列。ClassMap包括的属性有d2rq:Class、d2rq:UriPattern;PropertyBridge包括d2rq:belongsToClassMap、d2rq:property、d2rq:column、d2rq:refersToClassMap、 d2rq:join属性。本文的AggregateWork、SubWork、Subject通过ClassMap映射为一个类;而 ClassMap的PropertyBridges集,规定了一个创建实例的属性,由每个表的各个列映射而成,如图12所示:
 | 图12 实体与属性映射实例 |
NSTL书目数据库生成的映射文件如下:
#Table dbo.AggregateWork
d2rq:dataStorage map:database;
d2rq:uriPattern "dbo.AggregateWork/@@dbo.AggregateWork.WORK_ID@@";
d2rq:class
d2rq:classDefinitionLabel "dbo.AggregateWork";
d2rq:belongsToClassMap
d2rq:property rdfs:label;
d2rq:pattern "dbo.AggregateWork #@@dbo.AggregateWork.WORK_ID@@";
map:AggregateWork_WORK_ID a d2rq:PropertyBridge;
d2rq:belongsToClassMap
d2rq:property vocab:AggregateWork_WORK_ID;
d2rq:propertydefinitionLabel "AggregateWork WORK_ID";
d2rq:column "dbo.AggregateWork.WORK_ID";
d2rq:datatype xsd:int;
map:AggregateWork_TITLE a d2rq:PropertyBridge;
d2rq:belongsToClassMap
d2rq:property vocab:AggregateWork_TITLE;
d2rq:propertydefinitionLabel "AggregateWork TITLE";
d2rq:column "dbo.AggregateWork.TITLE";
map:AggregateWork_Language a d2rq:PropertyBridge;
d2rq:belongsToClassMap
d2rq:property vocab:AggregateWork_Language;
d2rq:propertydefinitionLabel "AggregateWork Language";
d2rq:column "dbo.AggregateWork.Language";
map:AggregateWork_Subject a d2rq:PropertyBridge;
d2rq:belongsToClassMap
d2rq:property vocab:AggregateWork_Subject;
d2rq:refersToClassMap
d2rq:join "dbo.AggregateWork.Subject => dbo.Subject.Subject_ID";
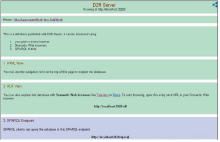
通过执行d2r-server.bat脚本,运行生成的映射文件,启动关联数据的Web发布服务D2R Server。D2R Server分别提供了HTML View、RDF View和SPARQL Endpoint三类服务入口。D2R Server的运行入口页面如图13所示:
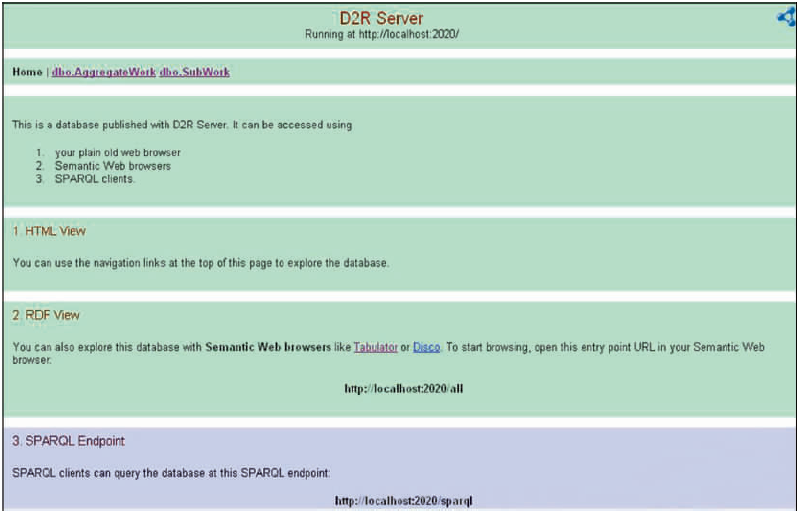 | 图13 D2R的服务首页 |
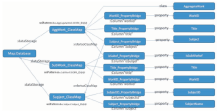
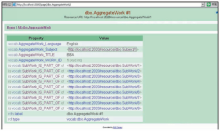
进入HTML View,可以看到三个数据表被映射为三种不同的实体类。在聚合型作品类AggregateWork中,可以看到一个具体资源作品《BBA》的各个属性特征,题名、语种等各个列被映射为资源的属性特征,通过“SubWork_IS_PART_OF”的反属性is vocab of关联到《BBA》的各个子集,进一步浏览可以看到各个子集及其属性特征;并可以通过与主题词的关联,得到相关同主题资源。关联数据最大的特点是资源和资源之间是互联的,从一个资源可跳转到其他许多资源[ 20, 21]。如图14所示,可以从类资源-聚合型作品,跳转到类资源-子作品,从聚合型作品跳转到类资源-主题词。可见,书目本体所规范的实体、实体属性和实体间的关系,在关联数据中发布为关联和链接,具体表现为映射文件中的属性映射d2rq:refersToClassMap。在实际应用中,数据之间会存在更为丰富的关系,而在其原始数据库中并没有全部表现为主键和外键引用,在这种情况下,要构建和发布这些关联,需要根据一定的领域组织需求,手动地修改映射文件,以展示资源之间更丰富的语义关系。
 | 图14 实体与属性的关联数据发布示例 |
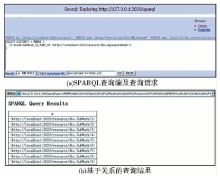
D2R还提供了SPARQL查询端,以支持基于SPARQL语言的关联数据查询,如图15(a)所示,可支持语义组织和语义查询原型。例如,以“具有分集”作为关系查询条件,查询聚合型作品-1的所有子集,以XML格式输出,共命中9条子集作品,如图15(b)所示,通过增加检索限制和输出条件,还可以得到更丰富的结果和链接。XML的结果形式也嵌入上层调用的各种应用中,也可以通过增加一些可视化工具,如开源软件Pubby等,增强直接浏览和查询的可视化效果。
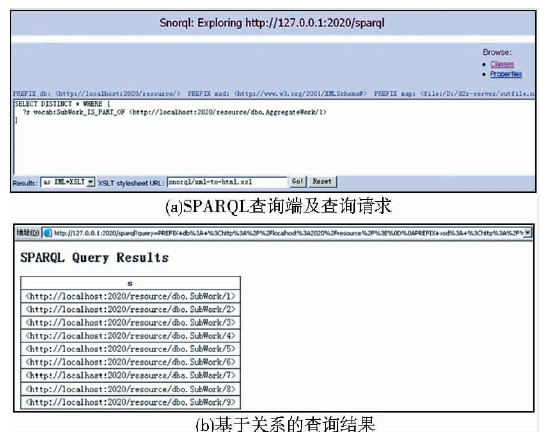 | 图15 D2R的SPARQL查询端和查询结果 |
本文尝试了将本体和关联数据应用于书目组织,以拓展有序化程度和语义化程度的思路与方法,目标在于解决传统书目组织在资源描述的语法规则、资源组织的数据模式和资源组织机制方面的根本性局限。研究成果可进一步尝试应用于更大范围、更多类型信息的科学数据组织,并通过多数据集关联的构建以及与知识组织系统的结合,尝试基于知识节点的多类型数据融合、知识整合服务等领域的应用。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|