
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向领域中文文本信息处理的术语语义层次获取研究
[季培培1, 2  , 鄢小燕
, 鄢小燕1 , 岑咏华3, 4 , 王凌燕1, 2 ]
, 鄢小燕|
|


研究国内外现有术语语义层次关联的主要方法,针对如何获取术语语义层次内部结构的关键问题,构建术语语义层次获取流程,采用多重聚类方法获取层次关系,结合综合相似度计算方法提取层次内部的聚类标签,并选取一定的语料进行实验,验证该流程的合理性。
Term semantic relationship is a key step of Chinese text information processing.Through researches on some existing methods at home and abroad,a process of term semantic hierarchy induction is proposed, which uses multiple clustering method to get the whole hierarchy,and combine with comprehensive similarity caculation to get the label of classes.Finally,some experiments are done to verify its rationality.
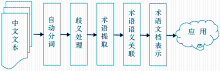
互联网上海量文本的出现,为语言处理提供了巨大需求,近年来中文文本信息处理是一个研究热点。对于汉语这种缺乏严格意义上的形态变化的语言来说,要让计算机自动理解并生成汉语,需要经过一系列的处理流程才能实现,如图1所示:
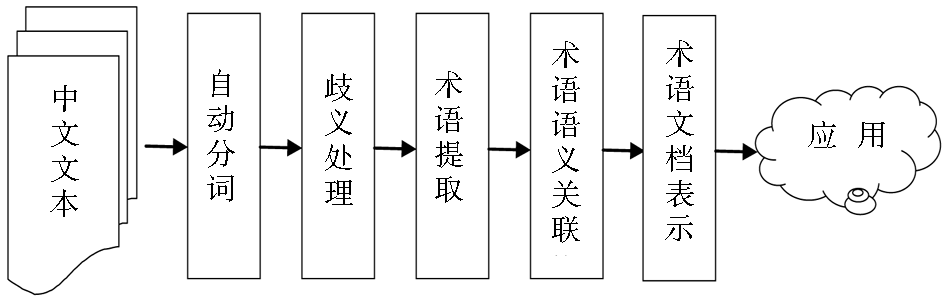 | 图1 中文文本信息处理模型 |
可以看出,术语语义关联(Term Semantic Correlations)的获取处于一个承上启下的位置,是中文文本信息处理中非常重要的一步。术语语义关联是对抽取出来的术语建立它们之间的语义关系。术语语义层次关联是指将大量的术语用层次化的方法组织起来,使得含有泛化语义的术语处于层次的上方,而含有具体化语义的术语处于层次的下方。本文围绕着如何建立一个完备的、描述准确的术语语义层次展开,在调研国内外相关研究工作的基础上,提出本文采用的方法流程,并通过实验进行结果分析。
目前,国际上对于术语层次关系的获取常用的方法有:
(1)基于语言学的方法
这类方法通过模式匹配原理,结合一些语言学知识或预定义的语义资源,得到术语形式上的内在关系。基于语言学的方法可分为两种:基于词典的方法和词汇-句法模式的方法。文献[1]和[2]通过挖掘词典中术语定义形式上的规律性来寻找给定术语的上位词;文献[3]利用词汇-句法模式从普通文档集中自动学习上下位关系。这类方法的缺点是往往忽略了大量新出现的术语之间的关系,因为预定义的语义资源是有限的,而且模板需要人工制定,模式的获取是否完备对于获取效果影响较大,领域扩展性也不好。
(2)基于关联规则的方法
基本思想是:如果两个术语经常出现在同一文档、段落或句子中,那么这两个术语之间必定存在关系[ 4, 5]。这类方法对判断术语之间是否存在关系效果很好,但对进一步的层次关系获取不是很理想,可以作为其他获取层次关系方法的基础方法,或者用于评价分析术语语义层次的实现效果。
(3)基于Harris假设的方法
Harris假设又称为分布假设,其内容是如果两个词的上下文语境相似,那么这两个词也是相似的。基于Harris假设有两种获取术语层次的方法:基于层次聚类的方法[ 6, 7]和基于形式概念分析(Formal Concept Analysis,FCA)的方法[ 8, 9]。层次聚类法很难获得聚类标签,FCA法很难处理术语过多的情况。
混合方法一般通过层次聚类或FCA法获取层次关系,再结合语言学方法,比如参照词典或者词汇-句法模板得到层次标签。
在国内,有关术语的研究不多,而对术语层次关系获取的研究就更少。目前可查到的有:
(1)裴炳镇等[ 12]对抽取出来的领域词汇建立分类语义森林,利用HowNet或其他MRDs整合,得到完整的分类关系。这种方法只能处理含有相同后缀的词以及在HowNet中出现的词,因此召回率比较低。
(2)何婷婷等[ 13]在获得领域术语的基础上,采用一种自顶向下的聚类方法来获得术语间的层级关系,通过统计类中出现频率最高的术语作为层次内部类的标记。这种标记方法显然是不全面的,而且聚类层数需要人工确定,无法自动得出完整的层次关系。
(3)温春等[ 14]通过两种方法来获取中文术语层次,实验对比发现层次聚类法效果最好,但仍需要基于HowNet来标记类;最近温春等[ 15]又提出了一种利用度属性获取术语层次的方法,主要以术语相似度为基础构建概念关系图,实验召回率仍然不是很高,问题在于如何准确地计算术语相似度。
无论是形式还是内涵上,中文与英文均存在很大的差异,因此国际上已有的方法用于处理中文时存在一些不足,而国内目前的方法以层次聚类法研究为主流,但是得不到完整的层次关系,分析其主要问题,在于难以对层次内部的聚类标签进行标记。本文提出一种基于综合相似度计算的层次聚类方法流程来解决这一问题。
目前,尚无通用标准的领域术语库,需要经过自动抽取才能准确获取相关领域术语,由于本文的研究内容是探讨如何建立术语之间的语义层次关系,因此实验背景是给定文档集中的领域术语,自动获取其层次关系。
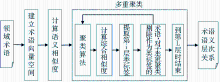
本文提出的术语语义层次获取流程如图2所示:
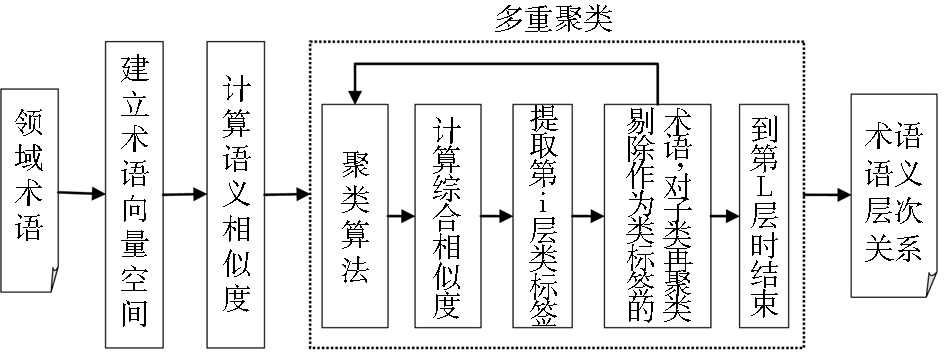 | 图2 术语语义层次获取流程 |
首先建立术语向量空间,计算术语语义相似度,采用自上而下的多重聚类算法来获取层次关系,在聚类过程中对层次内部的聚类标签进行标记(即术语层次内部上位术语与下位术语的标记)。在每一层聚类结束之后,对各类中所有的术语计算其综合相似度,该类中综合相似度最大的术语被提取出来标记该类,该类中剩下的术语进入下一层继续进行内部聚类,以此类推,得到术语语义层次关系。
文献[14]对比了基于窗口和向量空间模型(Vector Space Model,VSM)两种建立术语向量空间的方法,实验显示无论语料规模如何,基于VSM的方法都要优于基于窗口的方法,因此本文采用VSM的方法来建立术语向量空间。这个方法的主要原理是将文档集作为术语的向量空间,建立术语-文档矩阵,该矩阵的每一行代表一个术语向量。其中权值采用传统的术语权重计算方法,即:
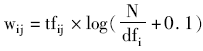
其中,wij表示术语ti在文档dj中的权重;tfij表示术语ti在文档dj中的出现频次(Term Frequency);N表示文档集合中的文档数量;dfi表示术语ti的文档频次(Document Frequency),即出现术语ti的文档数量。
相似度采用余弦系数计算,即:
cos(ti,tj)=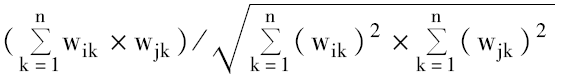
其中,wik为术语ti对应向量中第k维的值。
在聚类过程中,采用一种改进的K-means算法[ 13, 16]:在重新计算聚类中心时,不是简单地以距离每个类平均向量最近的术语作为类的新中心,而是根据类中元素的分布,决定该类中聚集度最大的p个术语,然后将距离这p个术语的平均向量最近的术语作为该类的新中心。这样可以使得聚类过程更快地收敛,聚类结果更接近术语的原始聚集分布状况。这个过程不断重复,直到准则函数收敛,常采用误差平方和准则函数作为聚类准则函数[ 17, 18],误差平方和准则函数的计算为:
Gc= 
其中,{Invalid MML}表示第i个类中的第k个术语,Ti表示类i中ni个术语的平均向量。
算法具体描述如下:
(1)选择m个术语作为初始聚类中心C1,C2,C3,…,Cm。
(2)对于每个术语tj,运用式(2)计算其与每个聚类中心的相似度,将该术语加入与其相似度最大的类中。
(3)按如下方法重新计算m个类的中心:
①计算类i中所有术语(i=1,2,…,m)的平均相似度:
avgsim[i]= 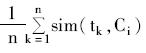
其中,n为类i中术语的个数。将m个平均相似度的最大值作为最大平均相似度max_avgsim。
②选出类i(i=1,2,…,m)中与类i中心相似度最大的p个术语,p由下式决定:

③计算p个术语的平均向量,将与其最近的术语作为类i的新中心。
(4)如果聚类中心未趋于稳定,即误差平方和准则函数式(3)没有收敛,则转到步骤(2)。
(5)得到m个类及其中心向量,算法结束。
结合聚类算法的结果,本文提出计算术语综合相似度的方法来构建术语语义层次。
对于聚类得到的每个类内部的术语,计算它们之间的综合相似度。综合相似度是指类中某个术语与类内其他任意一个术语的相似度之和。
假设类i中共有Ti个术语,那么类i中任意一个术语tk与该类中其他术语之间的综合相似度(co{Invalid MML})的计算公式为:

其中,cos(tk,tj)表示术语tk与tj之间的余弦相似度,计算公式见式(2)。
当一个术语与类中其他所有术语的综合相似度最大时,说明这个术语在这个类中的语义范围最宽,与其他任何一个术语都存在或多或少的关系,因此将其提取出来标记该聚类,置于该聚类所处层次的上方。
具体的算法流程如下:
(1)设顶层,第0层,为Top,指定术语语义的层次数为L。
(2)指定第一层中术语的数量为m,对术语集合进行基于改进的K-means算法聚类,得到m个类。
(3)用式(4)计算每个类中各个术语的综合相似度,将相似度最大的术语提取出来,置于该层,作为该类的标签。
(4)将提取出来的这个术语从原m类中剔除,对这m个类内部分别运用改进的K-means聚类算法,对子类聚类结果的处理重复步骤(3)。
(5)得到L层时,算法结束。
本文的实验语料采用Sougou文本分类语料库中健康领域的文档,该语料库来源于Sohu新闻网站保存的新闻语料。因为新闻语料具有用语规范、覆盖面广、语义清晰等特点,作为实验语料具有很强的代表性。从健康领域文档集中手动选取104个与健康相关的术语作为领域术语,并选取1 000篇文档进行统计。
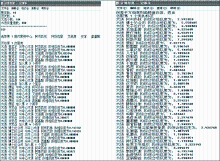
聚类过程中,设定聚类层数为4,初始聚类个数为10。计算过程如图3所示,左方为聚类时的部分计算过程,右方为综合相似度计算时的部分过程。
 | 图3 计算过程经过计算得到层次关系,结果如图4所示: |
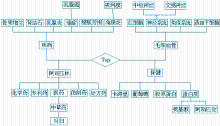
 | 图4 计算结果为了更好地查看所建立的术语层次关系效果,笔者节选部分术语,利用微软的Visio画图软件将其表示,如图5所示: |
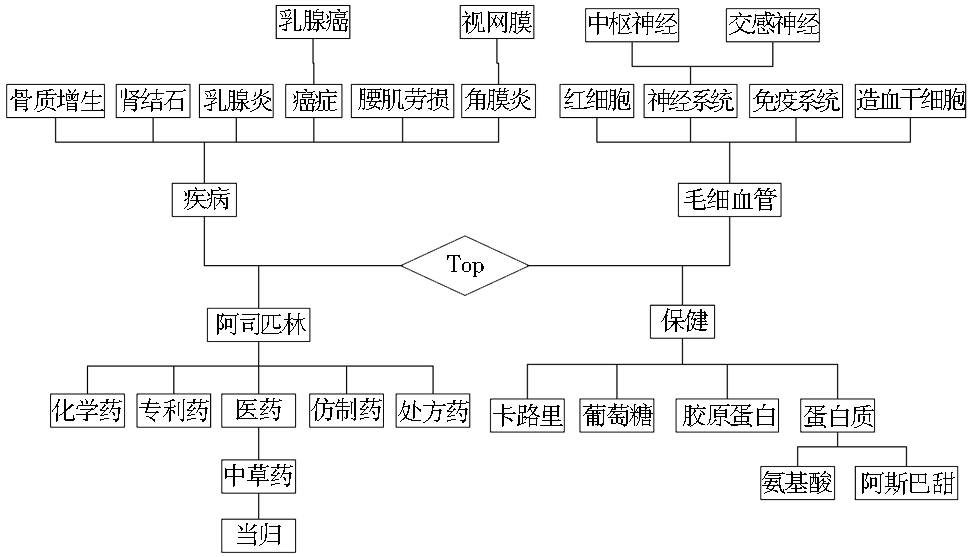 | 图5 术语语义层次关系图 |
由于目前尚无标准的术语语义层次关系评价标准,本文结合研究过程,提出从以下两个角度去衡量构建的层次关系效果:
(1)整体层次关系是否合理。因为实验语料选取的是有关健康领域日常生活的新闻文档,所选术语基本上是大家较为熟悉的,从而结合常识很容易地判断所生成的层次关系是否合理。从图5显示的4个子类可以看出,“疾病”和“保健”这两个层次比较合理。如“疾病”的第二层“骨质增生”、“乳腺炎”等是疾病的不同种类,第三层的“乳腺癌”是属于“癌症”的一种,基本上呈现出不同层次间的概念隶属关系。同时,同一层次的术语基本呈现出并列关系,如“保健”的第二层“葡萄糖”、“胶原蛋白”和“蛋白质”是糖类和蛋白质类的并列体现。
(2)每一层次的类标签提取是否合理。第一层的“阿司匹林”和“毛细血管”显然是不合理的,结合第二层的类目可以看出,这两个术语应该是各自第二层类目所表示的文档里都会高频出现的术语,从而它们的综合相似度计算结果会最大,所以出现了以个例统领全局的现象。撇开第一层看第二、三、四层,无论是层次关系,还是类标签,基本上都很合理。
图5显示的部分术语语义层次关系大体上是合理的,基本呈现出层次之间的隶属关系和层次内部的并列关系,类标签的选取还不是很完善,尤其是出现高频术语的情况下,容易发生个别术语代表全体的问题,因此在这方面还有待提高。
本文针对如何建立完备的术语语义层次关系提出了一种思路,其中主要运用多重聚类的思想来获取层次关系,并且提出了通过综合相似度计算来确定每一层次的类标签。相应的实验测试结果显示,这种方法具有一定的合理性,除了对高频术语还存在少许不足,总体上可以实现语义层次关系。
今后的工作将从以下两个方面进行改进:
(1)本文旨在测试提出的术语语义层次构建方法流程是否合理,因此在术语相似度计算和聚类这两个阶段,选取的都是经典的计算方法,实际上这些经典的方法存在很多缺陷与不足,比如改进的K-means聚类方法,初始聚类点的选取一直是一个难题,不同的初始点将会得到不同的聚类结果,因此这些都是后期提高层次关系效果所需考虑的因素。
(2)本文的综合相似度计算提取类标签的方法针对一般分布的术语建立层次关系效果较好,但对于高频术语存在缺陷,需要通过人工修正。因此,后期需要进一步改进该方法,可以考虑添加一些判断条件,将这些高频术语先甄别出来,或者引进其他方法的辅助。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|