

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
异构专利数据源集成方案设计与实现
[翟东升, 禾文汇 ]
]
]
|
|


针对目前用于专利分析的数据存在来源单一、预处理操作不够、可挖掘程度浅等问题,设计并实现异构专利数据源集成方案,即从七国两组织的专利数据库获取数据到本地专利数据库;以本地数据库为基础数据源,利用SSIS工具通过ETL(数据抽取-数据转换-数据装载)操作,生成规范的、集成的高质量数据;进而将其加载到事先围绕KPI(关键性能指标)分析构建好的专利数据仓库中,从而为专利多维分析以及数据挖掘提供有效的数据支持。
With consideration of the problems concerning the data of patent analysis, such as single data source, rough pretreatment, and low-level data mining, this paper designs and achieves the data integration over heterogeneous patent sources. Specifically, the local patent database where the data are acquired from heterogeneous sources including two organizations and seven countries is regarded as basic data source. After using the SSIS tool for data cleaning and data transformation, the data from local database are loaded into data warehouse that is built according to the key performance indicators, which provides data support for more advantaged analysis.
专利作为科技创新成果的重要表现形式和主要载体,蕴含着巨大的知识含量,具有启发性、可靠性、准确性等特点,因此专利信息已成为不可或缺的竞争情报信息源。目前不少国内外机构致力于专利信息分析研究,更多关注于如何从海量的专利数据中收集到及时、有效的专利信息,帮助企业了解技术状态、技术地位,识别新的技术领域、技术机会,进而做出有效决策。
专利分析研究已经取得了一定的成果,但仍存在许多不足。如在理论和方法方面,分析数据来源单一、分析前数据处理有待加强、聚类分析的深度和准确性有待完善、分析与分析指标的匹配度不高[ 1];在分析工具方面,存在多种数据源的融合度低、可扩展性差、知识挖掘程度浅等问题[ 2]。
如何将异构专利数据源进行集成、生成统一规范的数据、实现数据共享成为当前急需解决的问题。异构数据集成技术发展至今主要经历了三个阶段[ 3],即解决系统异构和结构异构,如联邦数据库、多数据库;对分布的异构数据源进行集成,如中间件技术;集成过程中致力于语义异构问题,如基于XML和基于本体的数据集成。总结各个发展阶段,比较典型的数据集成方案主要有以下三种类型[ 4]:联邦数据库、数据仓库和Mediator-Wrapper体系结构。联邦数据库将各个单元数据库系统按各自的模式进行集成,不需要生成全局共享模式,而是通过成员间的相互访问关系实现集成;数据仓库则将各个数据源数据按照一个集中、统一的视图要求,转换成符合数据仓库的模式存入其中;而目前国内外数据集成系统大多采用了Mediator-Wrapper体系结构,即中间件方法,通过中介模式将各数据源的数据模式转换为系统的公共数据模式集成起来,它不仅能集成结构化数据,还能集成半结构化和非结构化数据。针对半结构化和非结构化数据,集成难点主要集中在解决语法异构和语义异构上,XML作为数据交换的中间语言,通过对资源内容和结构信息的表示可以很好地解决语法异构问题;而本体则对各个概念和关系进行共享概念模型的明确的形式化规范说明,进而解决语义异构问题[ 5]。
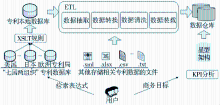
基于已有的集成技术和方法,本文在NetBeans IDE 6.1的集成开发环境下,通过Deep Web主题爬虫、XML技术以及XSLT规则[ 6]从各个异构专利数据库抽取所得的本地化数据为数据源,利用SQL Server Integration Services(SSIS)对异构数据进行清洗和转换,生成统一规范的数据,并利用数据仓库技术将其集成到数据仓库,从而实现异构专利数据源的集成,其框架如图1所示:
 | 图1 异构专利数据源集成框架 |
为保证专利分析数据的全面性,该方案以从“七国两组织”专利数据库中采集的数据为基础数据源,进行数据抽取;围绕KPI分析建立面向主题的数据仓库,通过填充维度表以及事实表,完成数据装载,为后期的多维分析、数据挖掘以及定性分析提供有效的集成数据;从抽取到装载过程中,由于多数据源的异构性,其融合度较差,所以在装载数据之前,需要对专利数据进行预处理,即针对数据流执行数据转换与数据清洗,保证数据的规范性、一致性以及完整性。
(1)依据商务目标,通过检索表达式分别从七国两组织(美国、英国、日本、法国、俄罗斯、德国、瑞士、世界知识产权组织、欧洲知识产权组织)的专利数据库中检索出能匹配业务需求的专利网页,基于检索所得的URL列表,利用XML技术抽取各网页信息到本地专利数据库。这时本地数据库的数据只是各个异构数据源在物理上的机械汇总,将为装载专利数据仓库提供基础数据源,但不能直接用于分析。
(2)构建数据仓库作为数据集成的目标,为多维分析、数据挖掘及定性分析提供直接数据支持。为了最大程度地满足业务主题,将从国家、企业、管理三个层面进行KPI分析即关键性能指标分析,进而生成星型架构。同时结合本地专利数据库特征,基于用户驱动和数据驱动相结合的理念完成专利数据仓库的搭建。
(3)从本地专利数据库装载数据到数据仓库的过程中,由于各国各组织的专利数据源存储格式存在差异[ 7],以及系统因素或人为因素也会导致“脏”数据的出现,为此需要根据每个数据源的数据结构和数据特征制定相应的ETL规则,对数据进行预处理,经转换和清洗后生成高质量的、纯净的、标准的专利数据,满足数据集成要求。
用于集成的专利数据主要通过检索表达式构造专利列表URL、获取七国两组织的相应的专利列表页面、并从中下载专利Web信息到本地专利数据库。
Web信息的获取是按照一定规则将网页中的半结构或非结构数据抽取成结构化数据[ 8]。而专利检索返回的网页一般以半结构化形式存在,所以网页专利信息抽取实际上是将半结构化内容转换为结构化形式的过程。
选择基于HTML结构方式的抽取方法[ 9],即清洗和净化页面,去除无用内容,修正错误标签,规范格式;根据专利DOM节点位置和关键字信息制定,将源树转换为结果树的XSLT规则;结合XSLT抽取规则,利用DOM解析器形成XML文档;抽取出节点文本信息,并通过递归算法映射到本地专利数据库中。以美国专利商标局(USPTO)为例,专利号、发明人、专利标题等基本信息的XSLT规则描述如下:
<xsl: template match="B[starts-with(normalize-space(.), "United States Patent")]">
<xsl: for-each select="ancestor::*[3]">
<PatentNo>
<xsl: value-of select="normalize-space(./TR[1]/TD[2]/B)"/>
</PatentNo>
<ChiefInventor>
<xsl: value-of select="normalize-space(./TR[2]/TD[1]/B)"/>
</ ChiefInventor >
<PatentTitle>
<xsl: for each select="following-sbling::FONT[1]">
<xsl: value-of select="normalize-space(.)"/>
</xsl: for-each>
</ PatentTitle >
……
</xsl: for-each>
</xsl: template>
由XSLT规则可知,基于网页节点信息所得的本地专利数据库数据有以下特点:
(1)不同国家或组织的数据结构及特征存在差异,如数据项定义不一致、部分无引文数据、更新频率不一、收录范围不同、可查获的最终结果不同、数据格式不一致等[ 7];
(2)由于人为或系统因素存在无用的、脏的数据,如大小写问题、意外的缩写语、拼写错误、字符合并、字符串截断、空值问题等。
通过异构数据源的分析,可以发现本地数据库的专利数据只是各异构数据源在物理地址上的简单汇总,是依赖于网页结构的节点信息的罗列,仍不能用于多维分析、数据挖掘以及定性分析。为此需要通过ETL即数据抽取、数据转换、数据装载操作生成专利数据仓库,完成真正意义上的数据集成。
源数据的抽取主要来自两个方面:本地专利数据库;以TXT、CSV、XLSX、XML等格式存储的其他专利数据文件,如专利所在国维的源数据来自存有国家编号、国家名称等信息的平面文件。
在数据抽取过程中,首先要明确抽取什么样的数据,源系统中的数据并不是都对数据仓库有用;其次要明确源系统到目标系统的映射规则,即访问源系统的哪些表和文件,经过怎样的格式转换进而提取到目标系统的哪些表的哪些字段中。
本文利用SSIS的连接管理器来建立源数据存储区和目标数据存储区的有效连接,如OLEDB连接管理器、平面文件管理器、文件管理器等,从而支持源数据的抽取。
作为集成数据的容器,将建立数据仓库,提供主题范围内的正确、完整、集成的数据,以便为后期的专利分析提供有潜在价值的知识。
专利数据仓库服务于决策层的企业管理者,设计数据仓库应当充分考虑到用户的分析需求,通过选定能说明业务主题的关键性能指标来指导逻辑建模。本文总结用户在国家、企业以及技术三个层面上的专利分析需求,并以满足这些分析需求为KPI选取原则,进行关键性能指标筛选,通过KPI计算公式或方法来确定所需的维度、维度层次以及度量值,完成数据仓库的构建。
(1)国家层
国家层的分析需求在于揭示各国的技术发展主要领域以及领域优势地位,明确国与国之间的相关性,通过技术领域的集聚程度以及专业化反映出该国的创新绩效和创新机会。因此,国家层的KPI分析包括:通过技术优势指数RTA衡量各国技术间的比较优势;通过快速增长领域指数FGSI判断快速进入某一技术领域的优势;通过CV指数标识某国技术的聚集程度;通过技术优势相关性判断是否存在明显的竞争关系;通过技术象限图判断国家在特定领域属于成熟型、夕阳型、落后型还是朝阳型[ 10]。
(2)企业层
企业层的KPI分析目标在于分析企业在技术领域的技术特征、竞争地位以及目标市场构成,以此评价自身的技术创新能力、发掘R&D重点、寻找商业机会等。因此,企业层筛选出的KPI有:专利质量,反映企业的技术竞争力;技术强度,反映企业在某技术领域的整体专利质量;技术份额,评估竞争对手之间的差距;三维评价结构,确定战略目标、研发目标、领域目标,并做出选择性投资;技术创新能力,以专利活动和专利质量为指标综合分析所得[ 11]。
(3)技术层
技术层的KPI分析过程为首先利用技术功效矩阵发现专利空白区、密集区、稀疏区。空白点将作为技术机会来辅助企业研发战略;而其他区的专利将进一步运用技术成熟度预测方法来辨别所处的生命周期的阶段以及生命特征;对成长期的专利用投资组合法和IPC分类分析法确定技术聚集领域,挖掘商业潜力;对成熟期的专利则利用曲线拟合和回归分析的方法预测其进入衰退期的时间以及当前更新换代的几率;对衰退期的专利将利用引文分析法把握技术脉络、发现新的技术机会。因此,技术层的KPI包括:技术功效矩阵、生命周期曲线、专利循环时间时序曲线、专利引用图等。
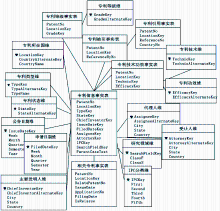
基于本地数据库结构以及KPI指标特点,以数据驱动和用户驱动相结合的理念构建面向国家、企业、技术三个主题的数据仓库。综合考虑数据装载、存储、查询和维护等各方面的性能,选取星型模式来组织多维数据,如图2所示:
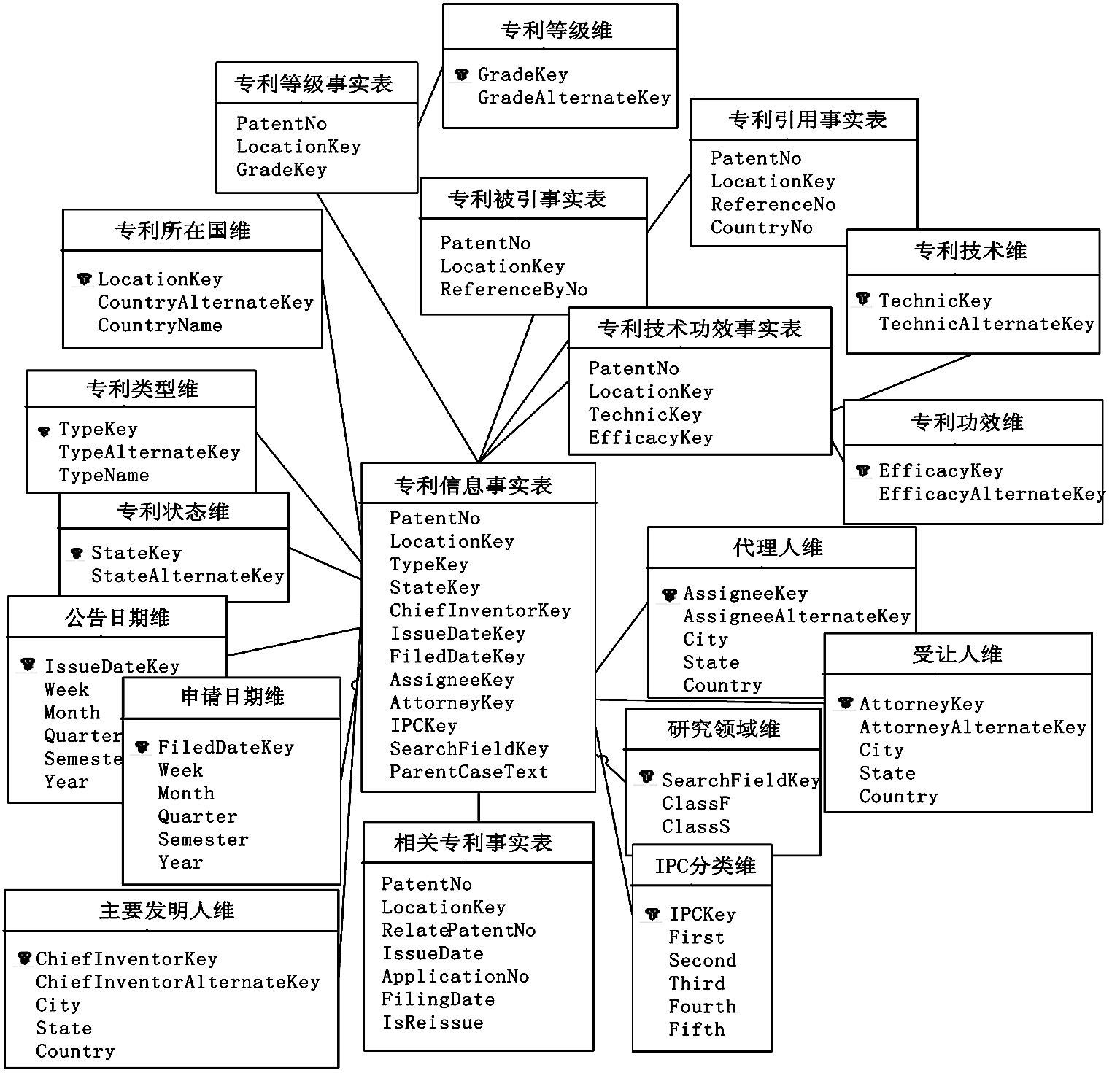 | 图2 专利数据仓库星型架构 |
该架构由6个事实表和13个维度表构成。其中事实表包括专利信息事实表、专利引用事实表、专利被引事实表、相关专利事实表、专利技术功效事实表、专利等级事实表。前4个表的度量值是本地专利数据库的数据通过无变化或标准计算、派生计算所得;而后两个表则是由文本挖掘、关键词匹配等智能计算所得。维度表包括专利所在国维、专利类型维、专利状态维、公告日期维、申请日期维、主要发明人维、受让人维、代理人维、IPC分类维、研究领域维、专利技术维、专利功效维以及专利等级维。其中日期维采用了年-半年-季-月-周的自然日历层次结构;主要发明人维、受让人维、代理人维以城市-州-国家为层次;IPC分类维以部-大类-小类-大组-小组为层次结构。
为确保维度表与事实表的关联程度,提高数据仓库的查询性能、索引性能等,将本地专利数据库数据装载到数据仓库时需要遵循以下规则:
(1)由于事实表中含Key的字段依赖相关维表的外键,根据关系规则,要先导入维度表,然后再导入事实表。
(2)每个维度都应包含一个代理键,作为主键与事实表外键字段相关,定义为[名称]Key,数据类型为数值型且自动递增。
(3)利用业务键在维度表中跟踪,只作为源表的主键值,确认与源表是数据关联性,并不用来标识维度表的唯一性,定义为[名称]AlternateKey。
(4)事实表引用维度表的代理键值时,先通过Lookup获取;对于获取失败的记录进一步采用Fuzzy Lookup方式,通过设置键值匹配度来引用维度表值;之后可能仍存在无法匹配维度值的记录,这时需要创建推断成员,即将至少有一个缺少维度成员的行加载到临时表,在事实表加载数据流后,插入推断成员到维度表中,然后通过Lookup重新处理临时表中的记录。
(5)事实表除包含与维度表的外键关系外,还应包含相关度量以及表中行的信息的元数据列,比如记录添加行的时间、数据来源等。
(6)在装载数据之前,为保证数据仓库中一致而且干净的数据,维度表和事实表的清洗与转换是不可缺少的。
由于系统因素、人为因素等,本地专利数据库并不能直接提供正确、一致、完整、可靠的数据给数据仓库,在数据装载之前需要进行ETL即数据抽取、转换、清洗、装载操作,而数据转换和清洗是关键的步骤之一,将直接影响数据质量,其主要进行数据类型转换、空值判断、字段运算、聚集运算、参照转换、拆分字段、合并字段、映射字段、去除重复记录、条件过滤等。本文以UPSTO专利数据为例,以SSIS为工具,对专利数据仓库的维度表以及事实表进行数据清洗与转换操作。
根据USPTO的专利数据特征,13个维度大致可分为5类:
(1)专利所在国维、专利类型维、授权状态维,其特点为长时间处于固定状态,例如专利所在国维的国家编号、国家名称以及数量长期不变。
(2)主要发明人维、授权人维、代理人维,其特点是部分字段有多个数据项,需要拆分字段,且不规则程度很高,如授权人维中存在空值、部分数据项有缩写、大小写问题、人为拼写错误,代理人的属性不一致,有的提供了州和国家属性,有的只有国家属性等。
(3)公告日维和申请日维,都属于日期维,因此涉及到标准日期格式的转换和构建层次结构。
(4)国际分类维和研究领域维,其特点是部分字段有多个数据项,但是相对第二类维度结构较为规则,如国际分类维大多以部、大类、小类、大组、小组的形式组合,不规则问题在于每个数据项后有版本说明、空值,以及部分数据项不以层次结构组合,而是用4位数表示。
(5)技术维、功效维以及等级维,其特点是业务键必须通过对源数据进行文本挖掘来获取。如功效维借助文本挖掘,从标题和摘要中提取关键词,计算出现的频率,结合专家知识最终筛选出词频高的关键词作为专利所要达到的功效种类,从而为技术功效矩阵分析在横轴上提供专利信息因素。
由于篇幅有限,以授权人维、公告日期维以及国际分类维为例进行维度的清洗与转换说明。
(1)授权人维
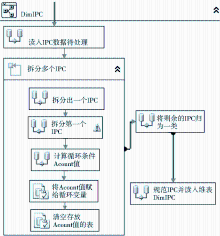
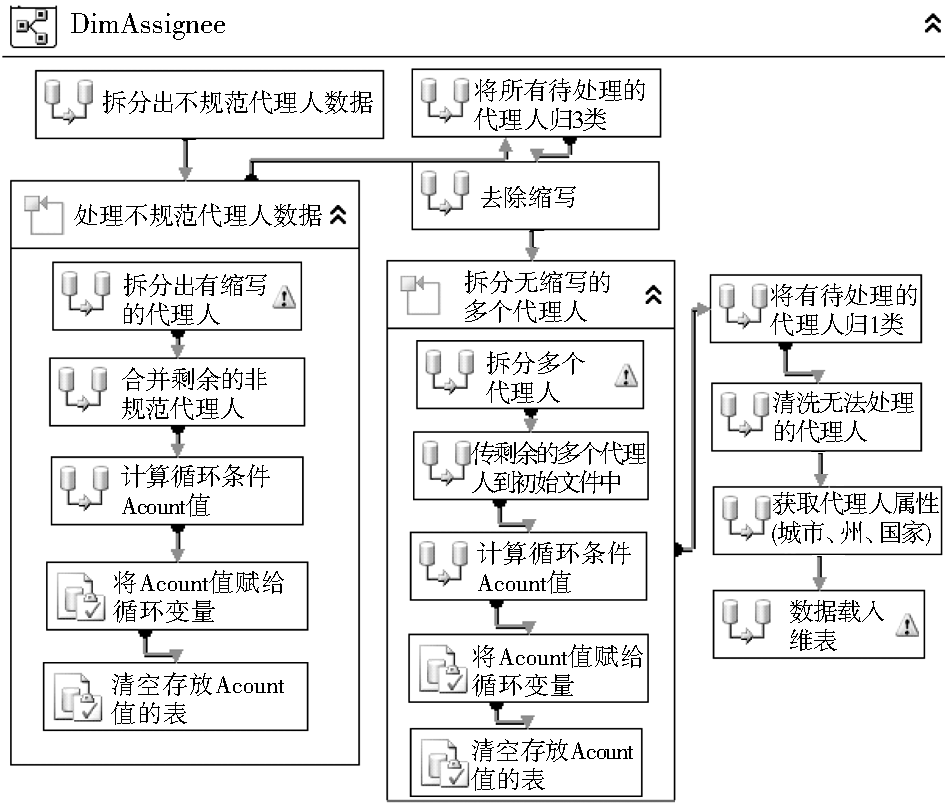 | 图3 基于SSIS的“授权人维”控制流 |
如图3所示,在数据清洗与转换过程中,数据项的拆分占主要部分。首先利用Conditional Split组件将初始数据条件拆分为没有缩写且只有一个代理人的记录集和不规范代理人记录集;针对不规范代理人利用For循环容器以及Derived Column和Conditional Split进行迭代处理,直到划分为没有缩写且只有一个代理人记录集、有缩写且只有一个代理人记录集、以及没有缩写且有多个代理人记录集等三种类型;对有缩写且只有一个代理人记录集,通过SSIS表达式中的Replace函数去除缩写;对没有缩写且有多个代理人记录集,利用For循环继续进行字段拆分的迭代处理,直到只有存在没有缩写且只有一个代理人记录集为止;合并所有的没有缩写且只有一个代理人记录集进行数据清洗处理,清洗工作如表1所示:
| 表1 “授权人维”数据清洗规则 |
(2)公告日期维
 | 图4 基于SSIS的“公告日维”控制流 |
如图4所示,首先利用Derived Column和Data Conversion组件规范日期格式,如将“December 18, 1974”转换为标准日期格式“1974-12-18”;利用Execute SQL Task组件从源数据中获取最大日期和最小日期,进而通过Script Component组件编写脚本代码,生成从最小日期到最大日期之间的记录集;通过Derived Column组件的日期函数DatePart (<日期部分>,<日期>)获取日期属性,其中日期部分用“wk”表示周、“mm”表示月、“qq”表示季、“yy”表示半年。
(3)国际分类维
 | 图5 基于SSIS的“国际分类维”控制流 |
如图5所示,前期操作和授权人维一样都是进行字段拆分,将其拆分为仅包含单一数据项的IPC记录集。后期的数据清洗主要有去除版本号、4位数IPC处理、去除重复值、获取IPC属性、数据转换等,具体操作如表2所示:
| 表2“国际分类维”数据清洗规则 |
对专利数据仓库中6个事实表的清洗与转换处理主要包括三个方面,即映射维度键、计算度量、管理事实表记录的变化。
(1)映射维度键。加载事实表时,需要通过连接维度业务键来引用维度代理键,从而建立与维度表的关联,获取维度属性。通过Merge Join转换组件,把源数据作为左输入、相应维度表作为右输入进行左外连接;条件拆分出匹配的记录和不匹配的记录;对于不匹配记录通过设置Fuzzy Lookup组件中的相似度进行模糊匹配,寻找合适的维度代理键。
(2)计算度量。计算度量涉及源数据的转换,转换类型主要包括源列无变化、列值标准计算、派生计算以及高级计算、文本挖掘等。对于本文的专利数据仓库,4个事实表的度量值为专利数量,属于源列无变化,直接从源数据中读取专利号即可;另外2个事实表即技术功效事实表和专利等级事实表则需要通过从源数据中提取关键词,通过关键词匹配来识别其度量值,所以度量转换类型属于文本挖掘。
(3)管理事实表记录的变化。源数据较之事实表中已存在的记录可能发生变化,所以需要在源与事实表之间做比较,并执行相应的插入、修改、删除操作。使用Merge Join组件的全连接方式进行处理:将来自源的数据流转换为和事实表一致的格式,并利用Merge Join组件与事实表记录进行全连接操作;进而通过Conditional Split拆分出4种记录集,即事实表中度量值为Null的记录为新记录、数据流中至少有一个代理键值为Null的记录为删除记录、至少有一个字段值前后不一致的为更新记录、完全匹配的则为无变化记录。对于前三种记录集将在装载数据时通过Execute SQL Task 执行相应的增、删、改操作。
本文以SSIS为工具,从“七国两组织”异构专利数据源获取数据到本地专利数据库,基于本地数据库进行数据抽取,通过数据清洗和数据转换生成高质量的数据,最终将数据装载到面向主题、高度集成的专利数据仓库中。在今后的研究工作中,将围绕专利数据仓库的集成数据,结合数据挖掘模型进行专利的多维分析,从而完成专利数据-专利信息-专利知识的转化过程。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|