



{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于SUMO和WordNet本体集成的文本分类模型研究*
引用本文
胡泽文, 王效岳, 白如江. 基于SUMO和WordNet本体集成的文本分类模型研究* . 现代图书情报技术, 2011, 27(1): 31-38
Hu Zewen, Wang Xiaoyue, Bai Rujiang. Study on Text Classification Model Based on SUMO and WordNet Ontology Integration. 现代图书情报技术, 2011, 27(1): 31-38
Permissions
Hu Zewen, Wang Xiaoyue, Bai Rujiang. Study on Text Classification Model Based on SUMO and WordNet Ontology Integration. 现代图书情报技术, 2011, 27(1): 31-38
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于SUMO和WordNet本体集成的文本分类模型研究*
摘要
针对传统文本分类方法和目前语义分类方法中存在的问题,提出基于SUMO和WordNet本体集成的文本分类模型,该模型利用WordNet同义词集与SUMO本体概念之间的映射关系,将文档-词向量空间中的词条映射成本体中相应的概念,形成文档-概念向量空间进行文本自动分类。实验表明,该方法能够极大降低向量空间维度,提高文本分类性能。
关键词:
SUMO本体; WordNet; 本体集成; 文本分类模型; 词向量空间; 概念向量空间
中图分类号:G250 TP391
Study on Text Classification Model Based on SUMO and WordNet Ontology Integration
Abstract
Aiming at the existing problems in the traditional text classification methods and the current semantic classification methods, a new text classification model based on SUMO and WordNet Ontology integration is proposed. This model utilizes the mapping relations between WordNet synsets and SUMO Ontology concepts to map terms in document-words vector space into the corresponding concepts in Ontology, and forms document-concepts vector space to classify texts automatically. The experiment results show that the proposed method can greatly decrease the dimensionality of vector space and improve the text classification performance.
Keyword:
SUMO Ontology; WordNet; Ontology integration; Text classification model; Word vector space; Concept vector space
1 引 言
信息泛滥、无序、获取难度高是目前人们面临的难题。文本自动分类技术因其分类速度快、自动化程度高,能够很快有序化无序的海量信息,能够提供分类清晰的搜索界面和信息展示界面,提高信息的利用效率和水平,已成为国内外学者研究的热点。然而传统基于词向量空间(Word Vector Space,WVS)模型的文本分类技术因其没有考虑词间语义关系,如同义词、多义词、词间上下位关系等,造成向量空间维度高、分类性能低等问题[ 1],仍然无法解决信息之间缺乏语义关联,获取难度高的问题。为改变这种现状,国内外学者提出语义驱动的文本分类方法,如潜在语义索引法[ 2]、本体语义映射法[ 3]、概念格构建法[ 4]等。这些方法虽然能够有效地提高文本分类的性能、增强信息之间的语义关联,但实现过程复杂,计算复杂度高,基本上还停留在原理、模型框架、方法流程的研究阶段,目前还没有一个简单高效、可自动处理的映射技术与方法实现词向量空间向概念向量空间(Concept Vector Space,CVS)的转换。
为解决上述问题,本文面向文本分类领域,以SUMO[ 5]和WordNet[ 6]本体库为研究对象,提出一种基于SUMO和WordNet本体集成的文本分类模型。首先利用WordNet同义词集与SUMO本体概念之间的映射文件,编写正则表达式,对SUMO和WordNet本体库进行集成,形成涵盖WordNet同义词集与SUMO本体概念一一映射关系的集成本体库,然后基于集成本体库,将传统高维词向量空间转换成低维概念向量空间作为文本特征向量表示模型,大幅度降低向量空间维度,增强特征的通用性,改善特征词对文本的贡献程度,从而提高分类准确率。
2 研究背景
文档-词向量空间向文档-概念向量空间的转换是实现新一代基于概念向量空间或语义向量空间的文档语义分类技术的核心,也是国内外研究的热点与难点。目前国外有关词向量空间向概念向量空间转换的研究较少,其中比较深入的是Ginter等在2004年提出的基于本体的特征转换方法。该方法首先利用本体概念对文档进行标注,然后抽取标注的概念,利用本体概念及其相互之间的语义关系将抽取出的概念集组合成层次结构清晰的概念树,最后基于概念树,将词形不同而语义相同的概念转换成相同的概念、具体的概念转换成通用概念,从而形成低维的文档-概念向量空间[ 7]。该方法能够为词向量空间到概念向量空间的映射提供新的思路,但实现过程比较复杂且耗时耗力,并且分类性能的提高不明显。笔者认为,其原因是由于本体概念的抽象性,直接将文档特征映射到本体概念会出现很多文档特征映射不到本体概念的情况。国内有关该方面的研究更少,比较有代表性的是李文等在2010年提出一种基于本体的词语-概念映射方法。该方法首先利用概念-文档与词语-文档两重关系计算出词语与概念的相关度与置信度,再实现词语(集)到本体概念(集)的映射[ 8]。此方法主要应用于语义检索领域,由于需要对文档进行语义标注,考虑上下文信息等,计算过程复杂,并不适合文本分类领域中词向量空间到概念向量空间的转换。
笔者认为,目前实现文档-词向量空间向文档-概念向量空间转换的最便捷、计算复杂度最低的途径就是充分利用WordNet同义词典与SUMO本体概念之间的映射关系,直接将自然语言词汇映射到WordNet同义词集,进而映射成SUMO本体概念。然而目前国内外学者利用WordNet/SUMO映射去构建文档-概念向量空间,实现文档语义分类的研究较少,大部分集中在基于单本体的文档-概念向量空间的构建,如基于WordNet同义词典的概念向量空间的构建[ 9]或基于领域本体的文档-概念向量空间的构建[ 10]。从国外相关研究[ 11]可以看出,国外学者主要利用两者之间的映射关系去检验概念隐喻中的源域和目标域之间映射原则的有效性[ 12]。国内在基于WordNet/SUMO映射的应用研究方面基本上是空白。
3 基于SUMO和WordNet集成的文本分类模型
WordNet同义词集抽象层次低、贴近自然语言词汇[ 13],SUMO本体概念语义关系丰富、概念层次结构清晰[ 14],并且WordNet同义词集与SUMO本体概念之间存在映射的关系,即WordNet同义词集能够全部映射到SUMO本体中的相应概念[ 5]。借助两者之间的映射关系,能够很容易将传统缺乏语义关联的文档-词向量空间转换成低维的、语义丰富的文档-概念向量空间,实现文档的语义分类。
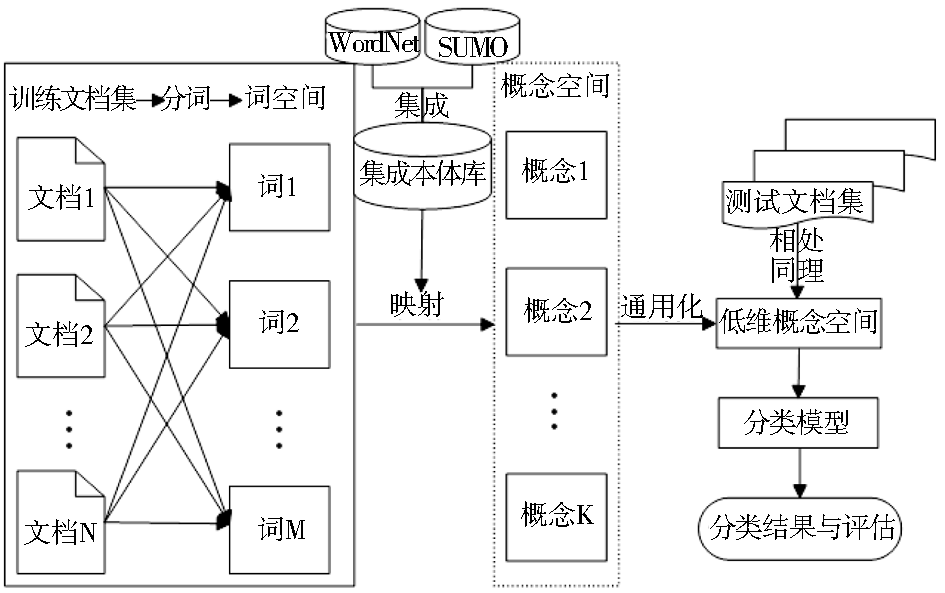
基于上述分析,笔者设计了一个集成WordNet和SUMO本体的文本分类模型,如图1所示:
 | 图1 基于SUMO和WordNet集成的文本分类模型 |
该模型共分为4个部分:
(1)集成本体库的构建;
(2)词向量空间到概念向量空间的映射;
(3)概念向量空间的通用化;
(4)分类模型的训练及实验。
其运作的基本流程为:首先基于SUMO本体概念与WordNet同义词之间的映射文件,编写正则表达式,抽取WordNet同义词集ID、同义词集及对应的SUMO本体概念,形成涵盖WordNet同义词集与SUMO本体概念一一映射关系的集成本体库,然后基于集成本体库,将传统词向量空间中相互独立的特征项映射成集成本体库中的同义词集字段,进而将同义词集映射成SUMO本体概念,基于SUMO本体概念语义图,将其中的具体概念映射成通用概念即SUMO本体上位概念,建立低维的概念向量空间,并进行文本分类模型的训练,最后对测试文档集进行相同处理,形成概念向量空间,实施分类实验及结果评估。
3.1 集成本体库的构建
目前,国内外学者在本体集成领域的研究主要集中在通用的本体集成模型、框架和方法的研究,集成的层次也主要集中在概念层次上的集成,这些集成方法主要应用于中小领域本体的集成[ 15]。对于大型本体库,由于其侧重点不同,如有些本体库侧重同义词集如WordNet同义词典,有些侧重概念及其语义关系如SUMO本体,有些侧重实例如DBPedia[ 16],有些侧重于推理和背景知识如OpenCyc[ 17],因此集成起来非常困难。笔者认为,如果在具体领域应用到这些本体库的不同部分,只需为这些本体库中的不同部分建立映射关系即可。比如本文提出的基于SUMO和WordNet本体集成的文本分类模型需要用到WordNet同义词集和SUMO本体概念,因此笔者基于两者之间的映射关系,设计了一个集成算法对WordNet同义词集及其对应的SUMO本体概念进行集成,形成涵盖WordNet同义词集与SUMO本体概念一一映射关系的集成本体库。集成算法的基本流程是:从网站 “http://sigmakee.cvs.sourceforge.net/sigmakee/KBs/WordNetMappings/WordNet”中获取WordNet同义词集与SUMO本体概念之间的映射文件;根据文件中同义词集与概念之间映射的特征编写正则表达式,从映射文件中抽取同义词集ID、同义词集及对应的SUMO本体概念,并分别作为synID、synset、concept三个字段存入建立的WSMap映射表中。集成算法的编程环境采用PHP+MySQL组合,该组合配置简单。
集成算法的核心代码如下:
输入数据:映射文件
输出数据:同义词集与概念存在一一映射关系的映射表WSMap
$strs1=file($filename); //将映射文件名赋予变量strs1
$con="/.+@/"; //抽取含有synID、synset数据段的正则表达式
$synID="/^[0-9]{8}/"; //抽取同义词集ID的正则表达式
$syset="/([a-z]{2,}_*[a-z]*)+/"; //抽取同义词集的正则表达式
$concep="/&%([a-zA-Z]{2,}_*[a-z]*)+/"; //抽取含有概念数据段的正则表达式
$concep1="/[a-zA-Z]{2,}/"; //抽取概念字段的正则表达式
for($i=0;$i {$line[$i]=trim($strs1[$i]); //各行去空格后存入 $line[$i]数组中 preg_match_all($con,$line[$i],$cons); //从$line[$i]各行中抽取$con表示的内容存入$cons数组中 preg_match_all($concep,$line[$i],$conce); //从$line[$i]各行抽取$concep表示的内容存入$conce数组中 $c=$cons[0][0];$d=$conce[0][0];//初始化$cons数组赋予$c变量和初始化$conce数组赋予$d变量 preg_match_all($synID,$c,$synid); //从变量$c匹配出$synID表示的内容赋予同义词集ID数组$synid preg_match_all($syset,$c,$synset); //从变量$c匹配出$syset表示的内容赋予同义词集数组$synset preg_match_all($concep1,$d,$concept); //从变量$d匹配出$concep1表示的内容赋予概念数组$concept $set=serialize($synset[0]); //序列化同义词数组$synset赋予变量$set $ids=$synid[0][0]; $cs=$concept[0][0]; //初始化数组$synid和$concept并赋予变量$ids和$cs $sql="INSERT INTO ′WS′.′ WSMap′ (′synID′,′synset′,′concept′)VALUES (′$ids′, ′$set′, ′$cs′) on duplicate key update synID=′$ids′"; //将变量$ids、$set和$cs的值分别插入到WSMap映射表中对应的三个字段 } 集成算法输出的映射表WSMap的部分结果如图2所示: 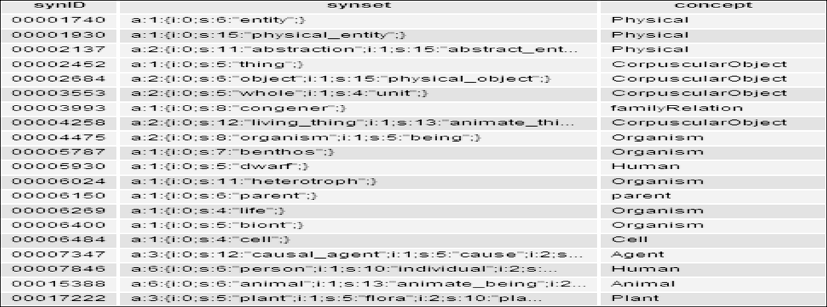
图2 映射表WSMap的部分结果
3.2 词向量空间到概念向量空间的映射
词向量空间到概念向量空间的映射是实现文档语义分类的基础和核心,也是国内外研究的热点与难点,目前还没有一个简单有效的映射方法,主要原因在于概念的抽象性。概念是从自然语言词汇中抽象出来的对人类世界的抽象性描述与概括,具有普遍性。如Computer、PC、Laptop、Notebook、Desktop、Dell、 Lenovo、HP等词汇可以直接用Computer这个概念来表示。自然语言词汇是本体概念的具体化表示,具有特殊性。如果人们只用Computer概念表示计算机,可能很多人会不理解PC、Laptop、Notebook、Desktop等词的意思。因此在人类世界里,需要有很多词汇去阐释一个概念。自然语言词汇与本体概念之间普遍性和特殊性的矛盾,使得二者之间无法进行有效沟通和互操作。因此在进行词向量空间到概念向量空间映射的过程,需要计算词汇与概念的相似度,确定两者之间的映射关系。显然,这种方法的计算复杂度很高,效果也不一定好,并且在文档词汇向本体概念映射的时候,由于词汇与概念之间存在一对多(如多义词)或多对一(如同义词)的关系,会出现很多词汇不能准确映射到相应本体概念的情形。而WordNet同义词典直接面向自然语言词汇,是对自然语言词汇的语义组织,涵盖的词汇量比较大,并且WordNet同义词集能够全部映射到SUMO本体概念。因此借助WordNet同义词集与SUMO本体概念之间的映射关系,可以简单有效地将文档词汇准确地映射到对应的本体概念,如同义词{Computer、PC、Laptop、Notebook、Desktop、Dell、 Lenovo、HP}可以映射到SUMO本体概念“Computer”,这只是笔者举例,目前WordNet同义词典还没有如此丰富的同义词集,这也是WordNet同义词典不能随网络新词汇的出现而动态更新的一个缺陷。根据上述思路,笔者借助WordNet同义词集与SUMO本体概念之间的映射关系,集成了一个涵盖WordNet同义词集与SUMO本体概念一一映射关系的映射表WSMap,基于WSMap,设计了一个映射算法先将文档-词向量空间中的词项映射到WSMap表中的同义词集字段,进而映射成对应的SUMO本体概念,并修改相应的权重,形成文档-概念向量空间。
映射算法的具体描述如下:
输入:映射表WSMap和文档-词向量空间di=(t1,wi1;t2,wi2;…;tj,wij),其中tj表示文档di的第j词项,wij表示第j个词项在第i个文档中的TF-IDF权重;
(1)循环遍历文档向量di中所有词项tj及其权重,判断tj在映射表WSMap中同义词集字段中是否出现:若tj是未登录词(即不在WSMap同义词集字段中出现),则将其及其TF-IDF权重从文档向量di中删除;若tj在WSMap同义词集字段中出现,则将tj替换为同义词集对应的SUMO本体概念,将tj的权重wij作为所替换概念的权重,直到所有词项tj替换成概念,循环结束,形成新的文档-概念向量空间:di=(C1,wi1;C2,wi2;…;Cn,win),其中Cn表示文档di的第n个概念,win表示第n个概念在第i个文档中的权重;
由于多义词、同义词的存在,词向量空间到概念向量空间的映射结果中,可能会出现一个词汇映射成多个概念或多个词汇映射成一个概念的情况,因此映射后的概念向量空间中会出现很多重复的概念。如何消除重复概念,使概念更精确地反映词汇在文档中的本义是要解决的问题。一般来说,概念的重复频率越高,说明文档中反映该概念语义的词汇越多,该概念越能反映文章或类主题,其权重也就应该越高。因此,下一步主要统计概念Cn重复的频次,对概念向量空间进行消重,重新调整概念Cn的权重。
(2)循环遍历文档-概念向量di中所有概念及其权重,将相同的概念合并为一个概念,赋予变量Ck,统计概念Ck出现的频次,赋予变量CFk,利用公式cwik=(∑n=1CFkwin+CFk)∑n=1CFkwin2+CFk2计算合并后概念Ck的权重,其中cwik表示概念Ck的权重,∑n=1CFkwin表示概念Ck及其相同概念的权重和(由于映射到概念的词汇不同,即使是相同的概念,其权重也不一样,因此在消重时,将相同的概念权重和作为合并后概念Ck的权重),CFk既指概念Ck的频次,也指相同概念的个数,分母为归一化因子;
输出: 消重调整权重后的概念向量:di=(C1,cwi1;C2,cwi2;…;Ck,cwik)。
3.3 概念的通用化
概念的通用化即下位概念通用化为上位概念,如下位概念“gold”、“silver”可以通用化成上位概念 “precious metal”。关于概念的通用化,国内研究较少,国外研究比较深入的是Ginter等提出基于本体构建概念树将词形不同而语义相同的概念转换成相同的概念,具体的概念转换成通用概念,并提出概念通用化深度的概念[ 7]。该方法需要利用本体从文档中抽取对应概念,形成概念集,然后利用概念语义关系,将概念集组织成概念树,实现过程较为复杂。针对此问题,本文设计了一个概念通用化的算法直接将SUMO本体可视化成本体概念语义图,基于此,进行概念的通用化操作。
算法的具体描述如下:
输入:消重调整权重后的概念向量:di=(C1,cwi1;C2,cwi2;…;Ck,cwik);
(1)调入SUMO.owl本体概念描述文件,并利用GraphViz.php文件中的Image_GraphViz.class[ 18]可视化类将其可视化为本体概念层次结构图,然后循环遍历文档概念向量di的所有概念Ck,判断Ck是否在本体概念层次结构图中存在:如果不存在,则保留原概念,对下一个概念进行判断;如果存在,则从SUMO本体概念层次结构图中获取概念Ck所在的层次,赋予变量L(Ck),判断Ck在层次结构图的第L(Ck)-r (r为层次调节参数,一般为整数,1≤r
(2)循环遍历di=(C1,cswi1;C2,cswi2;…;Cm,cswim)中所有概念及其权重,将相同的概念合并为一个概念,赋予变量Cl,统计概念Cl出现的频次,赋予变量CFl,利用公式ccswil=(∑m=1CFlcswim+CFl)∑m=1CFlcswim2+CFl2计算合并后概念Cl的权重,其中ccswil表示概念Cl的权重,∑m=1CFlcswim表示概念Cl及其相同概念的权重和,CFl既指概念Cl的频次,也指相同概念的个数,分母为归一化因子;输出:较低维度的文档-概念向量空间:di=(C1,cwi1;C2,cwi2;…;Cl,ccswil)。
3.4 分类模型训练与测试过程描述
本文主要利用RapidMiner4.6[ 19]作为文本分类实验平台。RapidMiner最初由德国多特蒙得大学人工智能实验室开发,目前已成为国际上主流的开源数据挖掘软件,为机器学习和数据挖掘提供一个优秀的实验平台。RapidMiner采用Jave语言编写,可以运行于任何平台。除了提供一个GUI的数据处理和分析环境外,还提供了Java API,以便将RapidMiner强大的数据处理与分析功能嵌入到其他应用程序中。
(1)分类模型训练过程描述
分类模型训练的基本过程如图3所示,包括词向量空间的构建、词向量空间到概念向量空间的映射、参数优化和模型的训练与输出。
 | 图3 分类模型训练的基本过程图 |
①词向量空间的构建。利用RapidMiner4.6的TextInput模块对输入的训练集进行分词、停用词过滤、词根还原、TF-IDF权重等预处理,形成文档的词向量空间。
② 概念向量空间的构建。利用映射算法将文档-词向量空间映射成文档-概念向量空间。
③ 参数优化。利用RapidMiner4.6的ParameterOptimization参数优化模块优化分类算法的参数,以提高文本分类模型的性能。
④ 分类模型的训练和输出。首先利用ExampleSource数据源加载模块输入概念向量空间,设置训练好的最优参数,然后利用FeatureSelection特征选择模块对输入的概念特征进行选择,获取最优概念特征集,最后利用XValidation交叉检验模块对分类算法的性能进行评估,并将性能优越的分类模型通过ModelWriter模块写出。
(2) 分类模型测试过程描述
对测试集进行语义处理,形成概念向量空间;进行特征选择,形成最优概念特征集;利用ModelApplier模块加载训练好的分类模型执行分类任务测试,并利用Classification Performance评估模块对分类模型的分类性能进行分析和评估。
4 实验及结果分析
4.1 实验设计
(1) 实验数据集
选择20 Newsgroups 作为实验数据集[ 20],该数据集是机器学习研究领域中一个非常流行的实验数据集。目前有三个版本:“20news-19997.tar.gz”、 “20news-bydate.tar.gz” 和 “20news-18828.tar.gz”。其中第二个版本消除了重复部分和一些消息头,并按日期排序,分为训练集(60%)和测试集(40%),避免了人工分类的随机性, 比较适合文本分类中的交叉检验。 该版本数据集共有18 846篇新闻文档, 其中训练集文档11 314篇, 测试集文档7 532篇, 按新闻主题分为20个类。 从中选择8个类作为本文分类实验的类别体系,类别体系的详细信息及对应的类别编号如表1所示。从N1-N8的每个类各取300篇文档,共2 400篇文档作为训练集。之后从每个类中再各取100篇,共800篇文档作为测试集。
| 表1 类别体系的详细信息及对应类别编号 |
(2) 实验方法
采用支持向量机(Support Vector Machine,SVM)分类算法对词向量空间和概念向量空间表示的文档集分别进行实验,并对两种向量空间的分类性能进行对比分析。
(3) 实验评估指标
采用目前文本分类领域最常用的评估指标:准确率(Accuracy)、精确度(Precision)、召回率(Recall)和 F1值。准确率(Accuracy):A=(正确分类的测试文档数)/(测试文档总数);精确度(Precision):P=(正确分为某类的测试文档数)/(测试集中分为该类文档总数);召回率(Recall):R=(正确分为某类的测试文档数)/(测试集中属于该类文档总数);F1测试值:F1=(精确度×召回率×2)/(精确度+召回率)。
(4) 实验环境
台式机的处理器为Intel Core i5 750 2.66GHz,内存为4GB。
4.2 实验结果分析
当训练文档集数量为960时,基于词向量空间WVS的SVM分类器和基于概念向量空间CVS的SVM分类器分别对各类测试文档进行分类测试的召回率、精确度、F1值及它们的平均值如表2所示:
| 表2 两种分类器在训练集规模为960时的分类性能比较 |
从表2可以看出,与基于WVS的SVM分类器相比,基于CVS的SVM分类器的平均分类性能较高,维度较低,其召回率、精确度和F1值的平均值分别从55.75%、56.03%、55.89%增加到82.61%、84.52% 和82.19%,分别增加了26.86%、28.49%、26.30%,向量空间维度也从原来的11 178维降低到3 360维。
选用不同数量训练文档时,两种向量空间模型分类器的分类测试结果,如图4所示。
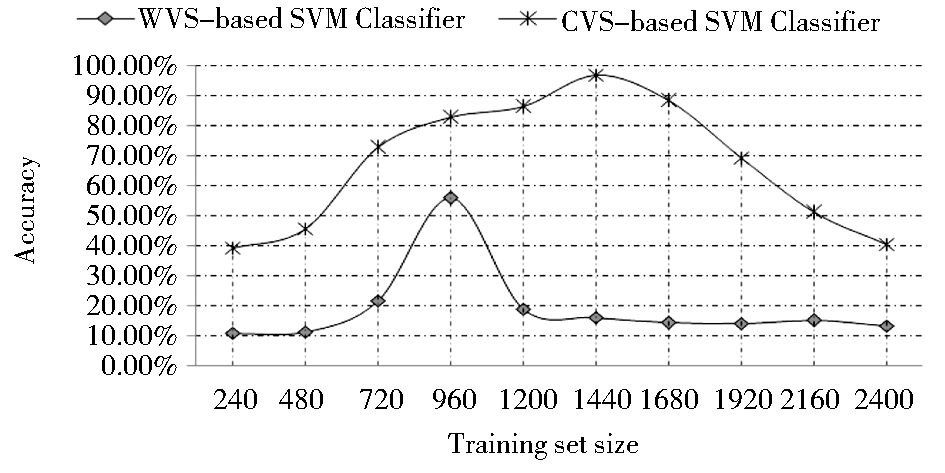 | 图4 不同数量训练文档时两种分类器的分类准确率比较 |
在训练集规模为240时,基于CVS的SVM分类器的分类准确率比基于WVS的高出28.50%。随着训练集规模的增加,两种分类器的分类准确率不断提高,当训练集规模达到960时,基于WVS的分类器分类准确率达到最高,为55.75%,此时两种分类器分类准确率之间的差距最小,为26.86%;当训练集规模达到1 440时,基于CVS的分类器分类准确率达到最高,为96.78%,此时两者之间的差距也达到最高,为80.78%。
5 结语
实验结果表明:传统基于词向量空间的文档表示模型,由于其没有考虑词间语义关系,不能解决同义词、多义词、词间上下位关系等问题,导致向量空间维度较高,分类性能较低。本文提出的基于WordNet和SUMO本体集成的概念向量空间模型,是通过词形映射到同义词集、进而映射到SUMO本体概念所构建的,能够有效克服因本体概念与自然语言词汇之间存在普遍性与特殊性的矛盾所导致的文档词汇无法直接映射到本体概念的问题,并且采用数目比词条少、语义表达更精确的概念表示文档集合,能够极大降低向量空间维度,提高分类器的性能。
笔者未来的研究工作是利用本文提出的算法所得到的概念向量进行文档的层次分类,并将其应用于语义检索中;同时考虑当训练文档集合特别大时,如何提高该算法的分类性能以及向量空间降维的效果。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|