
{kind=link}
{kind=link}
{kind=link}
特征词抽取和相关性融合的伪相关反馈查询扩展*
引用本文
冯平, 黄名选. 特征词抽取和相关性融合的伪相关反馈查询扩展* . 现代图书情报技术, 2011, 27(1): 52-56
Feng Ping, Huang Mingxuan. Query Expansion of Pseudo Relevance Feedback Based on Feature Terms Extraction and Correlation Fusion. 现代图书情报技术, 2011, 27(1): 52-56
Permissions
Feng Ping, Huang Mingxuan. Query Expansion of Pseudo Relevance Feedback Based on Feature Terms Extraction and Correlation Fusion. 现代图书情报技术, 2011, 27(1): 52-56
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
特征词抽取和相关性融合的伪相关反馈查询扩展*
摘要
针对现有信息检索系统中存在的词不匹配问题,提出一种基于特征词抽取和相关性融合的伪相关反馈查询扩展算法以及新的扩展词权重计算方法。该算法从前列n篇初检局部文档中抽取与原查询相关的特征词,根据特征词在初检文档集中出现的频度以及与原查询的相关度,将特征词确定为最终的扩展词实现查询扩展。实验结果表明,该方法有效,并能提高和改善信息检索性能。
关键词:
相关性; 伪相关反馈; 查询扩展; 信息检索
中图分类号:TP391
Query Expansion of Pseudo Relevance Feedback Based on Feature Terms Extraction and Correlation Fusion
Abstract
Aiming at the term mismatch issues of existing information retrieval systems, a novel query expansion algorithm of pseudo relevance feedback is proposed based on feature terms extraction and correlation fusion. At the same time, a new computing method for weights of expansion terms is also given. The algorithm can extract feature terms related to original query from the n chapter top-ranked retrieved local documents, and then identify those feature terms as final expansion terms according to the frequency of each feature term appeared in the local documents and the correlation between each feature term and the entire original query for query expansion. The results of the experiment show that the method is effective,and it can enhance and improve the performance of information retrieval.
Keyword:
Correlation; Pseudo relevance feedback; Query expansion; Information retrieval
1 引 言
查询扩展 (Query Expansion,QE) 是采用计算机语言学、信息学等多种技术,将与原查询相关的词或者词组与原查询重新组合成新查询,以便更完整、更准确地描述原查询所隐含的语义或主题,帮助信息检索系统判断更多相关的文档,从而改善和提高信息检索系统的查询性能。它的核心问题是扩展词的来源及其权重的设置问题。
10多年来,查询扩展技术获得了成功,已成为解决长期困扰信息检索领域的词不匹配问题、改善和提高信息检索性能的关键技术之一,成为信息检索领域的研究热点,倍受学者的重视和关注。不同的学者从不同的领域提出各种查询扩展模型和算法,如:基于自然语言处理、基于数据挖掘技术、基于机器学习算法等,但是都没有最终解决查全率和查准率问题。本文在现有研究的基础上,提出一种基于特征词抽取和相关性融合的伪相关反馈查询扩展算法以及新的扩展词权重计算方法,试图解决现有信息检索系统中存在的词不匹配问题。该算法从前列n篇初检文档中抽取与原查询相关的特征词,根据特征词在初检文档集中出现的频度以及与原查询的相关度,将特征词确定为最终的扩展词实现查询扩展。实验结果表明,该方法能提高和改善信息检索性能,与传统的向量空间模型检索算法比较,该算法的检索性能MAP(Mean of Average Precision)平均提高了13.12%。
2 研究现状
传统的查询扩展方法[ 1]主要分为基于全局分析、基于局部分析、基于用户查询日志和基于关联规则挖掘等几大类。
(1)基于全局分析的查询扩展是对整个文献集的语词进行相关分析,得到每对语词的关联程度,选取与原查询关联程度较高的词作为扩展词进行查询扩展。
(2)基于局部分析的查询扩展首先利用传统的检索机制(如向量空间模型)对文档集检索,将初检出的与原查询最相关的前列n篇文档作为扩展词的来源,其主要技术有伪相关反馈(或称局部反馈)[ 2, 3, 4, 5]、用户相关反馈[ 6]和局部上下文分析[ 7]等。
(3)基于用户查询日志的查询扩展[ 8]充分利用用户的查询日志分析词间各种关联,自动选择与原查询高度相关的词或词组作为扩展词的来源。
(4)基于关联规则挖掘的查询扩展[ 3, 4, 9, 10]通过文本挖掘技术挖掘词间关联规则,将关联规则的后件或者前件作为扩展词的来源。
基于伪相关反馈的查询扩展是通过假定初检前列文档与原查询相关来模拟用户相关反馈的方法。其关键问题是对伪相关初检文档集如何处理,以致从中能得到与原查询相关的扩展词实现查询扩展。文献[2]-[5]从不同角度对伪相关反馈的查询扩展及其伪相关初检文档集进行了研究,取得了很大成果。文献[2]的主要思想是对初检的前列Web页面进行片段分割,从语义片段中提取与原查询相关的扩展词实现查询扩展,实验结果表明该方法能提高信息检索性能。文献[3]和[4]提出在伪相关反馈初检文档中进行数据挖掘,挖掘出与原查询相关的词作为扩展词实现查询扩展,其实验结果表明所提出的方法能提高查询性能。文献[5]则对伪相关反馈查询扩展的假设进行研究,提出利用语词共现技术在伪相关初检文档集中提取与原查询相关的词作为扩展词,实现查询扩展,其实验结果表明该方法有效,对信息检索性能的提高是有贡献的。
针对现有信息检索系统中存在的词不匹配问题,本文采用一种新颖的方法对伪相关初检文档集进行有效的处理,提出一种新的基于特征词抽取和相关性融合的伪相关反馈查询扩展算法。实验结果表明该方法能提高和改善信息检索性能。
3 特征词抽取和相关性融合的伪相关反馈查询扩展算法
3.1 算法基本思想
特征词抽取和相关性融合的伪相关反馈查询扩展算法基本思想是:用传统的向量空间模型检索算法对文档集进行初检,即计算原始查询q和文档集中每一篇文档dj的余弦值cos(q, dj),降序排列其余弦值,提取其前列n篇文档组成伪相关初检局部文档集D,对D进行分词、去停用词等预处理和特征词抽取,构建总的特征词库,统计每一个特征词在文档集D中的频度,根据其频度对特征词降序排列,提取前m个特征词作为候选扩展词,计算每一个候选扩展词与原查询的相关度,将相关度大于1的特征词项确定为最终的扩展词,实现查询扩展。
3.2 伪相关初检文档集D的确定
伪相关反馈查询扩展基于如下的假设:初检结果中排在最前列的n篇文档被自动认为与原查询相关。然而,文献[5]对该假设进行了专门的研究,结果表明这样的假设是很难保证的,初检结果中实际上会存在一些与原查询不相关的文档。一般来说,在基于向量空间模型检索中,查询和文档间的余弦值越大表明文档与原查询越相关。文献[11]的研究表明,在基于向量空间模型检索的返回结果中,查询和文档间的余弦相似值依据排序位置呈指数下降,而且排序靠前文献的余弦取值之间的差异比排在后面的文献之间的差异大。由此可见,在本文的查询扩展方法中,伪相关初检文档集D的确定非常关键,若D集合过小,初检文档太少,会遗漏一些相关的反馈信息;若D集合过大,即初检文档过多,不相关文档也多,由于噪音多而与原查询的相关性就下降,通过D获得的扩展词有可能是虚假的,与原查询不相关。为了探讨合适的初检文档集D,文献[4]做了一定研究,其实验结果表明,当查询与文档的余弦相似值规范化后,其值为0.2左右时,查全率和查准率之间达到最大的折中。因此,本文D的确定采用文献[4]的研究成果,即初检文档与查询的余弦相似值规范化后不小于0.2,此时获得的初检文档数量就构成伪相关初检文档集D。
3.3 相关性概述
相关性[ 12]表明特征词项集T1和T2之间可能存在某种关系,项集T1和T2的相关性(corrT1,T2)计算公式如下:
corrT1,T2=P(T1⋃T2)P(T1)P(T2)=TSupport(T1⋃T2)TSupport(T1)TSupport(T2) (1)
P(T1∪T2)、P(T1)和P(T2)分别表示特征词项集T1∪T2、T1和T2在文本数据库中发生的概率,TSupport(T1∪T2)、TSupport(T1)和TSupport(T2)分别表示特征词项集T1∪T2、T1和T2的支持度。当 corrT1,T2>1,表明项集T1和T2成正相关的关系,即一个项集的出现会增加另一个项集出现的可能性;当 corrT1,T2<1,则表明项集T1和T2是一种负相关,即一个项集的出现会降低另一个项集出现的可能性;当corrT1,T2=1,表示项集T1和T2没有任何关系,它们同时出现属于偶然的概率事件,没有特别的意义。
3.4 扩展词的确定及其权值的计算方法
(1)扩展词的确定方法
根据伪相关反馈查询扩展的假设,本文扩展词的确定基于如下假设:如果伪相关初检文档集D与原查询相关,那么D中的特征词项在D文档集中出现的总频度越高,该词项与原查询越相关。因此,当文档集D确定后,首先抽取D中所有特征词项,统计其在D中出现的总频度,降序排列频度,提取频度较高的前列k个特征词作为候选扩展词。然而,所得的候选扩展词是否都与原查询相关,这一点很难保证。为此,采用式(1)对每个候选扩展词分别计算其与所有原查询项的相关性corrtk,q,提取相关性大于1的候选扩展词作为最终的扩展词,并加入到原查询中,实现查询扩展。
(2) 扩展词权值计算方法
根据上述分析,将扩展词在D中出现的总频度作为其权重计算的依据,扩展词权重WEti的公式如下:
WEti=∑i=1ptfij (2)
其中,tfij为第i个特征词Eti在第j篇文档dj出现的频度,p为整个文档集D的文档总数。在查询扩展中,原查询项永远是最重要的,最能反映用户查询意图,故原查询词项权重可设为大于1的数,本文设为2。为了保证WEti值在[0,1]之间,通过式(2)计算得到的扩展词权值还要进行规范化处理。
3.5 查询扩展算法描述
采用N-S流程图描述基于特征词抽取和相关性融合的伪相关反馈查询扩展算法(Query Expansion of Pseudo Relevance Feedback Based on Feature Terms Extraction and Correlation Fusion,PRFQEofFTE&C),如图1所示。输入:原查询q,文档与查询的相似度阈值QDSim,前列特征词数量k。输出:查询扩展后的检索结果。
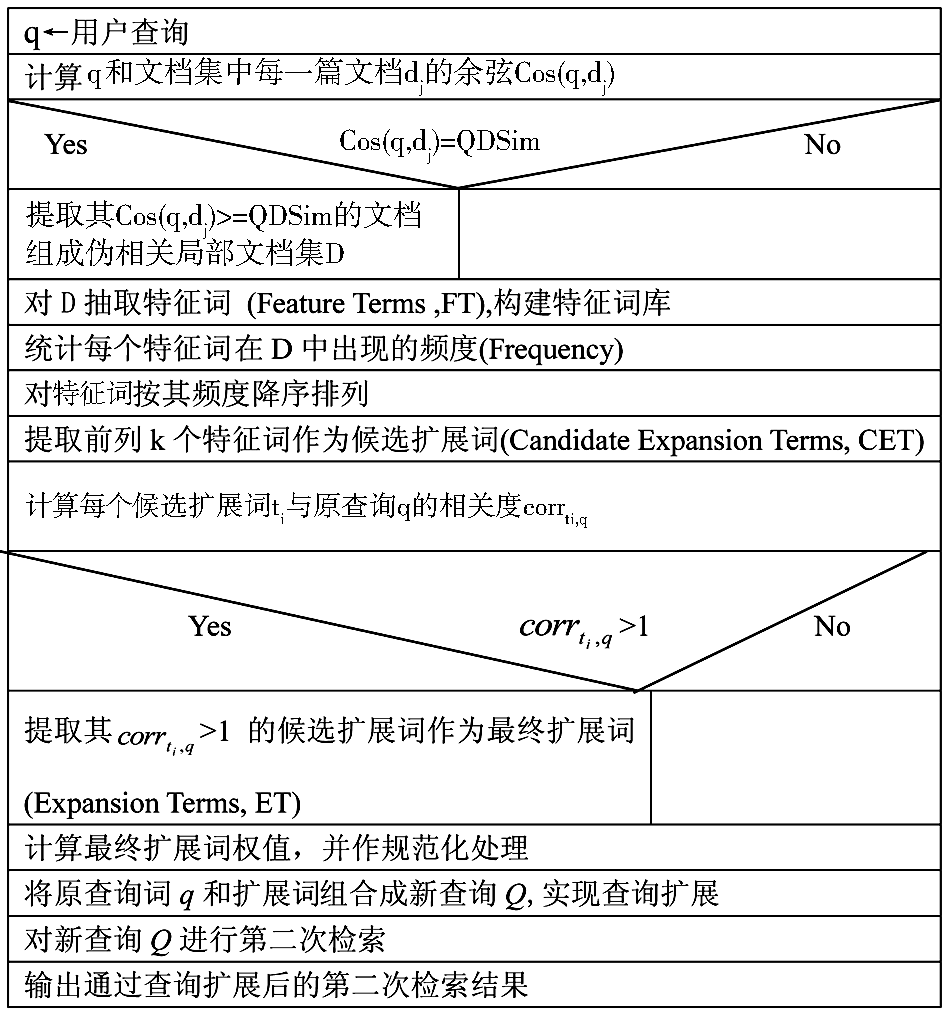 | 图1 PRFQEofFTE&C算法的N-S流程图 |
4 实验设计及其结果分析
4.1 数据集预处理及评测方法
从中国期刊网下载了720篇论文作为原始测试文档集,对本文提出的查询扩展算法(PRFQEofFTE&C算法)的查询性能进行测试,采用MAP作为主要评测指标。MAP表示查询集中每个查询q的平均准确率的算术平均值。
对原始测试文档集经过分词、去掉停用词等文档预处理,构建基于向量空间模型的文本数据库。设计了6个原始查询(q1,q2,…,q6)作为查询集,并人工检索获得原查询在原始测试文档集中的相关文档篇数。建立基于向量空间模型的伪相关局部文本数据库和总的特征词库。对原始查询也作类似的预处理,得到原查询向量形式。实验参数设置如下:QDSim=0.2,k=50。
4.2 实验结果及其分析
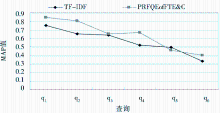
编写实验源程序,将PRFQEofFTE&C算法和传统向量空间模型算法(TF-IDF算法)进行查询性能比较,两种算法分别对所设计的6个查询在相同的测试文档集中进行检索,统计其MAP值,以及相应的各个查询所获得的扩展词数和伪相关初检文档集D,实验结果如表1和图2所示,原查询q1(数据挖掘)的实验界面如图3所示:
| 表1 查询性能比较 |
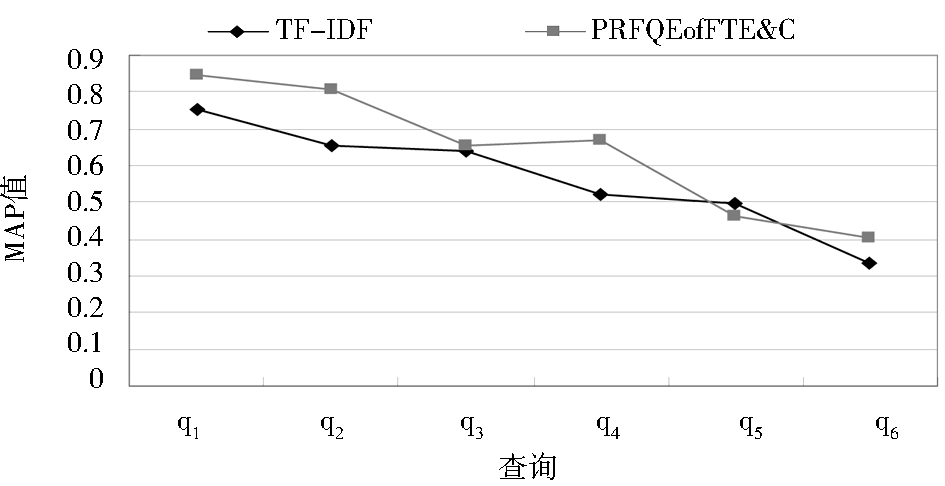 | 图2 检索性能比较图 |
 | 图3 原查询q1(数据挖掘)的实验界面 |
可以看出,在测试数据集上,与TF-IDF算法相比,PRFQEofFTE&C算法的MAP值平均提高了13.12%,而对于单个查询来说,提高的幅度最高可达28.17%(即q4),扩展词数在20至40个之间,平均为27个,伪相关初检文档集D在20至70篇之间,平均为43.7篇。实验结果表明,本文所提出的PRFQEofFTE&C算法是有效的,其检索性能(MAP)获得了明显的提高,其主要原因是采用了伪相关反馈查询扩展技术,将特征词抽取和相关性融合,获得与原查询相关的质量较高的扩展词,实现了查询扩展,信息检索性能得到了改善和提高。实验结果也表明PRFQEofFTE&C算法所基于的假设是正确的。
分析表1和图2还可以发现,对于每一个查询而言,PRFQEofFTE&C算法的检索性能(MAP)提高的幅度是不一样的,有的查询的扩展词并没有很好地改善和提高检索性能,或者提高幅度不大(如q3,仅提高2.12%),有的扩展词使查询主题产生漂移,降低了查询性能,例如q5的MAP没有得到提高,反而使检索性能降低。这就说明PRFQEofFTE&C算法还有一定的局限性,通过该算法还没有能够完全获取与原查询正相关的扩展词,在所获得的扩展词中还存在不利于提高检索性能的噪音,即与原查询成负相关的扩展词,这些问题有待于进一步研究和探讨。
5 结语
本文对伪相关初检文档集进行有效的处理,提出一种新的基于特征词抽取和相关性融合的伪相关反馈查询扩展算法。该算法首先提取伪相关局部文档集,抽取局部文档集的特征词,并统计其频度,根据其频度提取前m个特征词作为候选扩展词,计算其与原查询的相关性,根据相关性确定最终扩展词,实现查询扩展。实验结果表明,该方法有效,能提高和改善信息检索性能,这一研究成果对提高搜索引擎的检索性能具有很好的学术价值和广阔的应用前景。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|