

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于文本复杂网络的内容结构特征分析*
引用本文
刘红红, 安海忠, 高湘昀. 基于文本复杂网络的内容结构特征分析* . 现代图书情报技术, 2011, 27(1): 69-73
Liu Honghong, An Haizhong, Gao Xiangyun. Research on Content Characteristics About Complex Network of Text. 现代图书情报技术, 2011, 27(1): 69-73
Permissions
Liu Honghong, An Haizhong, Gao Xiangyun. Research on Content Characteristics About Complex Network of Text. 现代图书情报技术, 2011, 27(1): 69-73
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于文本复杂网络的内容结构特征分析*
摘要
针对文本信息内容结构参差不齐的问题,提出一种评价文本内容结构分析方法,该方法将文本中的句子作为节点,句子之间的共同名词作为边,构建文本复杂网络,并选取复杂网络的拓扑性质对文本结构特征进行分析。基于一个新闻文本案例构建复杂网络,并计算度、强度、最短路径、加权聚类系数等衡量指标,这些指标能很好地评价文本内容结构的好坏,也为理解和提取文本的中心思想、生成摘要、文本检索过滤提供重要参考依据。
关键词:
文本复杂网络; 内容结构; 最短路径; 聚类系数
中图分类号:G203
Research on Content Characteristics About Complex Network of Text
Abstract
To solve the problem of irregular structure of some texts, this paper presents a method based on the complex network theory to evaluate the text structure. This method uses a node to represent a sentence and an edge between two nodes to represent a common word of two sentences, which construct the complex network of a text. Then the authors analyze characters of text structure by topological characteristics of text complex network. By building a text complex network based on a selected article, the degree, the degree of intensity, the shortest paths and the weighting clustering coefficients of this selected article are calculated. The results show that the structure of the text content can be effectively evaluated by this proposed method. Moreover, the results also provide important references to understand main ideas, to generate summaries and to filter text retrieval of a given text.
Keyword:
Complex network of text; Content structure; Shortest path; Clustering coefficient
1 引 言
随着信息时代的发展,大量文本涌现出来,其中包括新闻信息、报告、论文以及散文小说等。大量信息的出现,给读者阅读和理解带来困难,这些文本信息的表述内容参差不齐,如何提取文本中心思想并评价文本内容紧凑和衔接程度的好坏,目前还主要依据专家的个人经验和主观评价,缺少量化的评价方法。
文本结构分析是文本处理领域中的重要内容,它可以有效地提高抽取文本摘要、文本检索以及文本过滤的精度。目前,国内在文本信息内容结构的研究主要集中在典型长篇小说的结构研究和论文文本内容结构的研究方面。王孟国通过“显”和“隐”的分析方法对长篇小说的文本结构问题进行系统研究[ 1]。何维等通过对文本信息之间相似度的计算建立句子的关系图,分析文本的主体句[ 2]。梁文婷等通过改进文本结构关系图对文本段与段之间的关系进行研究,完成文本结构的分析[ 3]。刘军万等基于潜在语义的分析技术,利用层次分析法研究文本结构[ 4]。
国外的研究除了包括前文国内的一些分析方法外,更重要的是随着复杂网络的兴起,尤其是1998年小世界和无标度性质在实际网络中的发现,推动了自然语言处理的研究[ 5],国外研究者利用复杂网络对文本信息进行分析的研究相对较多,网络节点(顶点)被用来代表词、句或段落,而网络边则根据一些任务依赖的标准来进行界定。将复杂网络与文本结合起来的研究,主要应用于作者评定和散文评价、摘要总结和翻译质量[ 6]的评估等方面。Antiqueira与Pardo等在这方面取得了突出的成果,分别通过构建文本复杂网络并研究其规律,能够了解作者写作特性,从而对作者和散文质量进行评定[ 7, 8]。Antiqueira等通过以句子为节点构建文本复杂网络,利用网络测量值自动获取文本摘要并对摘要质量进行评价[ 9, 10]。
国内对于文本信息内容结构的研究相对不足,仅停留在段与段之间的关系研究以及段与句之间层次分析方面,应用的方法则是潜在语义分析、相似度分析等,缺少创新性。而国外的研究,虽然引入新方法研究文本,但是对于文本结构特征分析方面的研究欠缺。本文通过对单个文本进行预处理,构建出文本复杂网络,并利用复杂网络的拓扑性质来分析文本内容结构的好坏,同时力图用复杂网络的各项拓扑指标来提取文中的中心思想,帮助读者理解文本信息。
2 文本复杂网络的构建与分析
2.1 文本预处理
文本预处理主要包括文本的噪声处理和自动分词两个过程。噪声处理过程主要是去除停用词和消除歧义,停用词包括助词、叹词、语气词、拟声词;歧义消除是指对文本中具有指代意义或者同一语义的词语进行统一,如文本中同时出现“中国人民大学”和“人大”,两者表示的意义完全相同,需要进行唯一化处理。
选用中国科学院计算技术研究所研制的汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)[ 11] 作为文本自动分词的工具,该系统不仅支持中文分词和词性标注,还具有关键词识别和支持用户自定义词典等功能。ICTCLAS3.0分词速度单机996KB/s,分词精度达到98.45%,可信度较高,是现有的比较好的汉语词法分析器。
2.2 文本网络的构建
复杂网络是由点和边构成的,文本中能够表示完整语义信息的最小单位是句子,因此本文中用节点表示句子,以句子为单位进行文本的结构特征分析具有可靠性。边的界定原则是如果两个句子间有一个共同的名词则产生一个边相联,否则不产生边。如果在网络中的两个句子存在边,即有一个公共名词,则可能阐述同一主题或者传达同一主题的补充资料,虽然两句话可能包含重复冗余的信息,但两个句子涉及的内容最为密切。通过两个句子之间共同名词的关系来构建复杂网络,最终得出文本复杂网络。
经过预处理后,将文本中各个句子产生的名词映射到网络中。根据邻接矩阵和N阶矩阵权重(N是节点或句子的数量)的概念,定义两个矩阵A和W,A矩阵表示句子间边的关系,W矩阵表示句子的权重。在A矩阵中,如果节点i和节点j之间有边的话,则aijaji等于1,其他情况都等于0。W矩阵中,边的权重wijwji是节点i和节点j中出现共同词的次数。
本文将句号作为界定句子的唯一标识,根据A矩阵和W矩阵的定义,应用计算机匹配算法,自动抽取句子关系构成矩阵A和W,将名词关系映射到矩阵中,最终借助社会网络分析软件UCINET,构建出文本的复杂网络[ 12]。
2.3 文本复杂网络的分析
目前,专家主要从连贯性和凝聚力、主题突出、段落分明三个方面评价文本信息内容结构。本文选取三个拓扑性质对生成的文本复杂网络进行分析,并通过计算这三类拓扑性质指标,分析文本信息的结构特征。
(1)度和强度
网络度(Complex Network Degree)和网络节点强度(Complex Network Strength)是描述网络中某一节点与其他节点连接程度的概念。文本复杂网络中的度是与某个节点有联系的节点总数,网络强度是与某个节点有联系的共同名词的数量(即是与某个节点有边联系的节点的边权重之和)。度和强度反映了某个句子与其邻接句子的紧密关系,能够反映文本的主题是否突出。
(2)最短路径
最短路径是测量网络结构中距离最常用的方法,路径是由从一个节点到另一个节点的不重复边构成,和网络度、网络节点强度不同的是,它不仅考虑了节点的近邻节点,还考虑了间接节点,节点之间最短路径大于1。无权网络和有权网络计算最短路径的方法有所不同,有权网络需要对权重进行转变后再进行计算。该拓扑指标衡量的是某个句子与其他句子的衔接性,是能够反映文本连贯性和凝聚力的结构特征。
(3)聚类系数
节点的聚类系数反映了该节点的近邻之间的集团性质,近邻之间关联越紧密,该节点的聚类系数就越高,即近邻句子之间的联系越紧密,所有节点的聚类系数的平均值便是整个网络的聚类系数。聚类系数是某个句子邻接节点之间的连接关系,能够反映文本的凝聚力和段落分明的结构特征。
3 案例分析
本文选用2010年9月10日人民日报的头版文章 “全面提高教书育人水平、推动教育事业科学发展”[ 13]为例构建文本复杂网络,文章分为14个段落,2 741字。经过分词处理,文本全文包含名词共计436个,其中不重复名词187个。
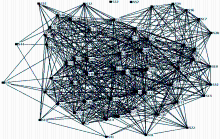
经过文本预处理和网络构建过程,构建出的文本复杂网络共有57个节点、671条边,节点分别为S1、S2、……、S57,结果如图1所示:
 | 图1 案例文本复杂网络 |
3.1 网络度和强度分析
网络度可以通过矩阵A计算,ki=∑j=1Naij,网络强度可以通过矩阵W计算,si=∑j=1Nwij[ 9]。度分布描述一个句子与其他句子是否存在联系,而强度分布更侧重描述一个句子与其他句子的联系强度。对于ki和si数值比较大的节点,可视为网络的枢纽。利用复杂网络来提取文章摘要,一般选择ki和si都比较大的节点来构成摘要。
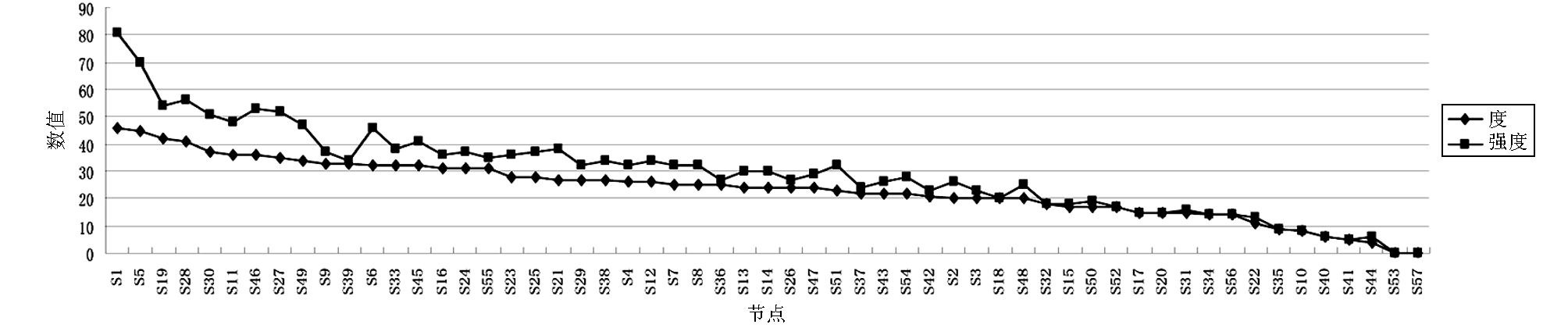 | 图2 文本复杂网络节点度与强度分布图 |
图2是句子节点度和节点强度的部分排名,前10个节点分别是S1、S5、S19、S28、S30、S11……,度值和强度值比较大,累积度分布达到60.2%,累计强度分布达到65.4%,单个节点度分布都在6%以上,说明这10个节点句子能够覆盖全文将近60%的信息量。通过与段落中句子的分布对比,这些节点度和强度排名靠前的句子,大多分布在段落的首句和末句,与实际的经验分析相符,可以根据排名提取文本的中心思想和自动摘要,同时从文本节点的度和强度的分布可知,各节点的大小虽然有差距,但是不明显,因此案例文本的主题较为突出,但还有待提高。
3.2 最短路径分析
最短路径是衡量连贯性和凝聚力的重要指标,两个句子节点距离越短,句子之间的联系越密切,文章连贯性和凝聚力也越强。连接节点i和j的最短路径长度dij可以通过矩阵A计算,最短路径长度是节点i到网络中的其他节点的路径的平均值,计算公式如下:
spi=1N-1∑i≠jdij (1)
如果节点i和j之间不存在路径,则dij=N,一对节点之间不存在路径,则说明网络是不连通的[ 8]。
对于文本复杂网络,边是有权重的,可以利用权重来计算最短路径。节点之间权重较大表示联系密切,这与最短路径的计算是相反的。所以在计算之前,先要把矩阵W中的边的权重进行改变,构造权重与原来权重成反比例的矩阵,下文介绍两种方法,首先定义两个矩阵Wwc和Wwl[ 10]。
(1)Wwc是把W经过以下变形得到的:
若wij=0则wijwc=0;
若wij>0则wijwc=wmax-wij+1 (wmax是矩阵W中的最大值)。
将公式(1)带入,计算Wwc的最短路径。如果节点i和j之间没有路径则dij=N,因为spi越小的节点与其他节点的联系越密切。
(2)Wwl是把W经过以下变形得到的:
若wij=0则wijwl=0;
若wij>0则wijwl=1/wij。
利用公式(1)进行计算即可,同理如果节点i和j之间没有路径则dij=N。
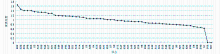
通过以上三种不同的方法,对本文案例的文本复杂网络进行计算,得出的结果基本一致。本文将通过无权重和有权重两种方法分别绘制W和Wwl的数据散点图,如图3所示:
 | 图3 文本复杂网络最短路径分布图 |
此文本复杂网络是非连通图,得出的最短路径数值较大,可以看出,不管是有权重还是无权重,基本路径基本满足线性关系,但是最短路径的变化不明显。无权重网络的平均最短路径为50.4,数值比较大,因此文章的连贯性和凝聚力较差。
3.3 加权聚类系数分析
本文的聚类系数则反映文章内容的紧密程度。在考虑文本复杂网络权重的情况下,对于网络中某一节点的聚类系数可以定义如下[ 14]:
Ciw=1siw(ki-1)∑j,kwij+wik2aijajkaik (2)
由前文的网络度和强度的计算可知,ki为节点i的度,si=∑j=1Nwij为节点强度,表示节点i与近邻节点的权重之和,∑k>iaijajkaik表示网络中包含节点i的三角形的总数,当C=0时所有的节点均为孤立节点,没有任何连接边。根据公式计算得出各节点的聚类系数,如图4所示。
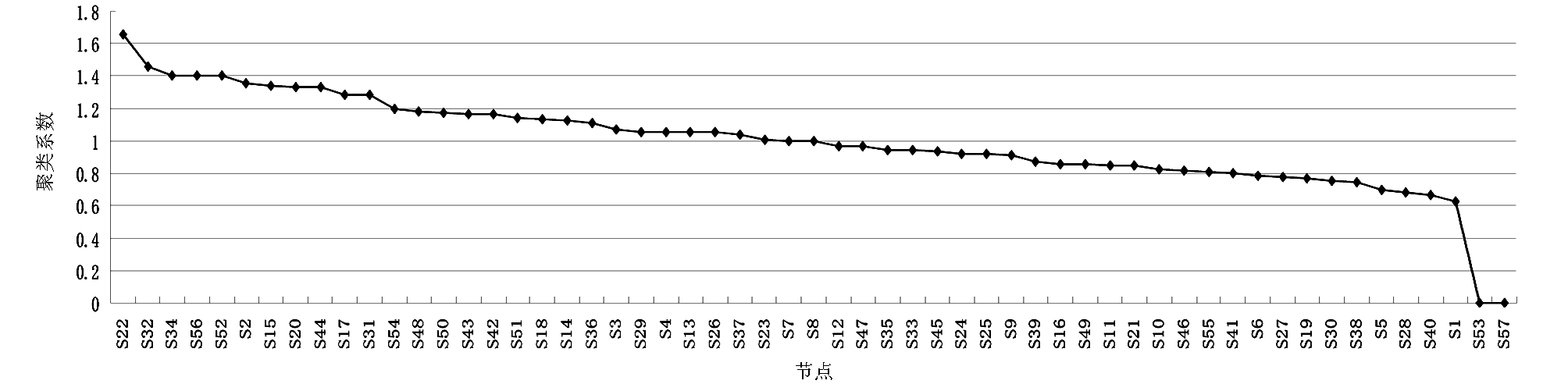 | 图4 文本复杂网络节点聚类系数分布图 |
节点聚类系数的分布区间是0-1.65,文章中存在两个孤立点,整体聚类系数波动程度不大,句子的聚类系数成线性排列。
整个网络的聚类系数C越大,则文本的凝聚性较好,文本表达较好,内容衔接较好,相反,则文本内容孤立,不利于文本内容的表达,本文得出的聚类系数为0.941,文章的整体凝聚性较差。但是通过对节点聚类系数进行分析可知,排名靠前的节点,如S1、S5、S19等大多分布在文中的不同段落,这表明文章的段落较分明,每段围绕聚类系数大的节点句子展开。
3.4 结果与讨论
通过节点度和强度的分析可知,节点度和强度大的,所占据的文本的信息量较大,在文章中占有重要地位,是文章的中心句,这些句子大多分布在段落的首句和末句,与实际的经验分析相符,同时可以根据排名提取文本的中心思想和自动摘要。从文本节点的度和强度的分布可知,各节点的大小虽然有差距,但是不明显,因此案例文本的主题较为突出,但还有待提高。
通过文本复杂网络最短路径的分析可知,无论用哪种方法计算最短路径,得出的节点序列基本相同。最短路径越短则句子与其他句子的连通性越好,是全文的中心句,对理解文章的中心思想和自动文本摘要起重要作用。此文本无权重网络的平均最短路径为50.4,数值比较大,因此文章的连贯性和凝聚力较差。
聚类系数反映文章内容的凝聚力,体现文章的整体状况,聚类系数越大,证明文章的凝聚力越好,而对节点聚类系数进行分析可知,排名靠前的节点,如S1、S5、S19等大多分布在文中的不同段落中,这表明文章的段落较分明,每段围绕聚类系数大的节点句子展开,文章在文本段落结构方面比较好。
通过对文本复杂网络的拓扑性质度、强度、最短路径、节点聚类系数的分析, 能够很好地分析文本的连贯性和凝聚力、主题突出、段落分明等方面的结构特征,从而对文本结构进行评价。
4 结 语
本文通过对文本复杂网络拓扑性质的研究,提出一种新的量化方法,对文本的内容结构进行评价,同时通过计算网络度、强度、最短路径、聚类系数的数值,可以依据不同指标数值的大小把句子节点排序,为提取中心思想、挖掘文章摘要、理解文章的内容提供参考。
下一步研究将通过对大量文本进行实验,通过现有系统构建复杂网络,并对文本的各项拓扑性质进行深入分析,研究其分布规律与结构特性,并与现有文本结构的评价方法进行对比性分析,最终依据实验数据制定特定的标准,分析文本结构特征与拓扑性质分布规律之间的关系,从而对文本进行评价,并验证文本的中心思想、摘要提取的准确性。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|