
{kind=link}
{kind=link}
{kind=link}
应用改进的共词聚类法探索医学信息学热点主题演变
引用本文
杨颖, 崔雷. 应用改进的共词聚类法探索医学信息学热点主题演变. 现代图书情报技术, 2011, 27(1): 83-87
Yang Ying, Cui Lei. Evolution of Topics About Medical Informatics by Improved Co-word Cluster Analysis. 现代图书情报技术, 2011, 27(1): 83-87
Permissions
Yang Ying, Cui Lei. Evolution of Topics About Medical Informatics by Improved Co-word Cluster Analysis. 现代图书情报技术, 2011, 27(1): 83-87
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
应用改进的共词聚类法探索医学信息学热点主题演变
摘要
对传统的共词聚类方法进行完善:依据高频低频词界分公式选取高频词;计算粘合力确定每个类别的中心词;对比分析两个时间段,发现主题演变。以医学信息学为例,从PubMed数据库分别下载1999年-2003年和2004年-2008年该学科相关文献,提取主要主题词,进行共词聚类分析,探索医学信息学学科结构的演变过程。
关键词:
共词分析; 可视化; 聚类; 粘合力; 普夫定律
中图分类号:G35
Evolution of Topics About Medical Informatics by Improved Co-word Cluster Analysis
Abstract
Co-word cluster method is improved by following ways: high-frequency words are selected according to the formula derived from Zipf’s law; adhesive force is used to identify the core major MeSH words for tagging the content of each cluster; contrastive analysis of two periods helps to find the topics change. The bibliographic data of medical informatics are collected from PubMed in two periods (1999-2003 and 2004-2008). Major MeSH words from the articles are extracted separately to make co-word clusters as to explore the evolution of this subject structure based on comparison of two periods.
Keyword:
o-word analysis; Visualization; Cluster; Adhesive force; Zipf’s law
1 引 言
了解某学科主题领域的前沿及热点,除了采用专家调查法外,文献计量学的方法(包括引文分析和共词分析)也颇受关注。它对决策层规划学科布局,调整学科方向,促进学科发展具有重要的参考价值。其中,引文分析是对科学期刊、论文、著者等各种对象的引用与被引用现象进行分析,揭示科学知识的继承和利用。共词分析方法属于内容分析方法的一种,其原理是:当两个能够表达某一学科领域研究主题或研究方向的专业术语(一般为主题词或关键词)在同一篇文献中出现时,表明这两个词之间具有一定的内在关系,并且出现的次数越多,表明它们的距离越近、关系越密切。利用现代统计技术如因子分析、聚类分析和多维尺度分析等多元分析方法[ 1],可以进一步按这种“距离”将一个学科内的重要主题词或关键词加以分类,从而归纳出该学科的研究热点、结构与范式[ 2]。因共词分析方法灵活,结果直观,所寻找的是当前论文所集中关注的主题,能够反映研究前沿;并且对当前发表的文献直接统计,不需要庞大的引文索引作为基础,具有较好的时间效应。因此,本文运用共词分析方法,以医学信息学为对象,分两个时间段对该学科进行较深入的主题分析,从而考察其研究现状、热点和发展趋势。
2 研究背景及框架
共词分析法最早于20世纪70年代后期由法国文献计量学家提出,通常用聚类来表现所构建共词矩阵的内容,展现学科结构,经过几十年的发展,已经广泛应用于探索学科前沿主题[ 3, 4, 5]。共词聚类法利用高频词反映某学科或主题的研究热点,能定量反映出词与词之间的亲疏关系,进而反映这些词所代表的主题内容的结构。但同时也存在一定的局限性:
(1)高频词阈值的确定尚未达成统一。高频词代表了某研究领域的研究热点内容,如何确定高频词的阈值是关键的问题,因为低阈值不利于聚类,但有助于一些隐含主题或前瞻主题的外现,而高阈值则恰好相反。目前,国内外的研究对高频词的选取方法各异,大多数学者根据经验直接选取高频词[ 6],或根据关键词累积频次的变化曲线截取高频词[ 7, 8],或利用齐普夫定律确定高频词阈值。
(2)聚类过程中,由于词相互间的密切程度高而聚集成为一类,在聚集的过程中没有形成中心词,大部分聚类的研究都忽略了此问题。
(3)对一段时间内的某领域进行共词分析,只能得到本时间段的研究热点,但无法发现其热点主题的发展演变过程。
本文拟解决共词聚类存在的上述问题,将共词聚类方法作如下改进:
(1)依据Donohue提出的齐普夫定律推导出的高频低频词界分公式[ 9]确定阈值:T=(-1+1+8×I1)/2,I1是词频为1的词的个数,T为高频词中的最低频次值,即高频、低频词词频临界值。
(2)引入钟伟金提出的粘合力[ 10]来确定每个类别的中心词。粘合力是用来衡量类团内各主题词对聚类成团的贡献程度,表达每个主题在类团的聚集过程中所起作用的程度。某一词与类团内其他主题词在同篇文献分别共现频率的平均值即为该词的粘合力。平均值越大,该词在类团中的地位越突出。在类团中,粘合力最大的主题称为中心词。中心词在确定类团的名称与性质中起至关重要的作用。粘合力的计算方法为:在有N个主题的类团中,主题A与类团内其他主题组成词对,统计这些词对在同一篇文献同时出现的频率的总和C,那么成员主题A的粘合力N(A)表达式为N(A)=c/(n-1)。粘合力在类团发展变化中有着重要的作用。粘合力确定聚类中每个类别的中心主题词,使得聚类结果更加深入具体。
(3)分两个时间段进行共词分析,探索医学信息学的热点主题在两个时间段内的演变发展过程。
研究路线如图1所示:
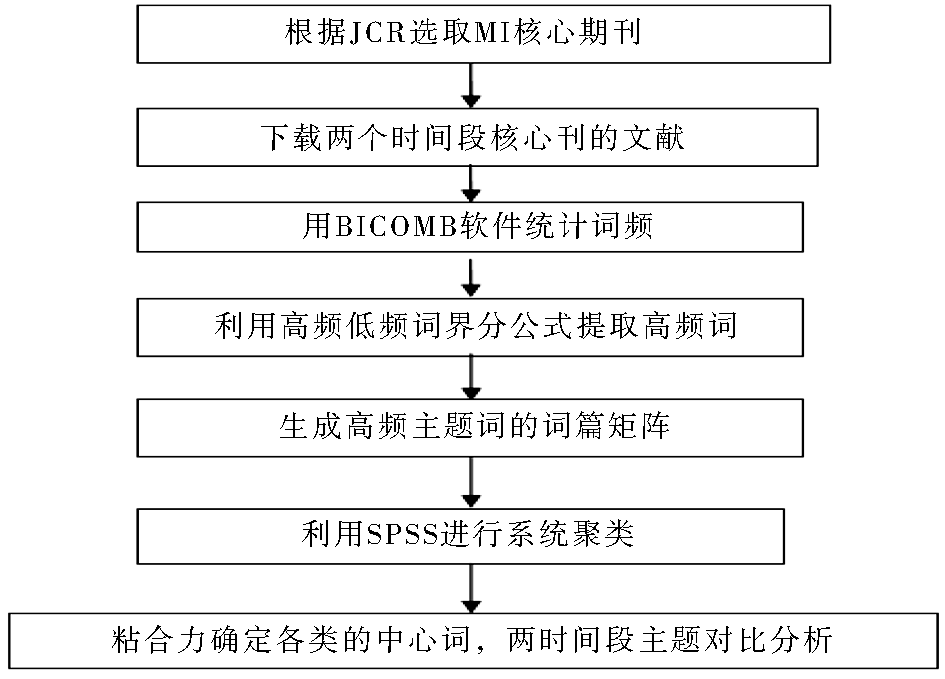 | 图1 研究路线图 |
3 研究方法
3.1 样本期刊选取及文献套录
通过调查美国科学情报研究所(ISI)《期刊引用报告》(Journal Citation Reports,JCR) 2008年数据,选取医学信息学(Medical Informatics,MI)的20种相关期刊,按影响因子(Impact Factor,IF)值排序。本文排除了计算机、统计学、生物医学方面的期刊,最终选取IF值大于1的5种医学信息学核心期刊作为最后的样本刊集,如表1所示。
| 表1 医学信息学核心期刊及其影响因子(2008) |
在PubMed数据库中检索,分别套录这5种期刊1999年-2003年、2004年-2008年期间发表的所有文章,保存以便统计分析。
3.2 选取高频词、生成共现矩阵
利用共词矩阵挖掘工具——书目共现分析系统[ 11](Bibliographic Item Co-Occurrence Matrix Builder,BICOMB)提取医学信息学相关文献的主要主题词 (简称主题词)字段,统计词频,根据高频低频词界分公式计算阈值,选取高频词,生成相应的词篇矩阵。
3.3 系统聚类分析
以统计软件SPSS15为统计工具,分别输入两个时间段高频词的词篇矩阵,对这些高频主题词进行系统聚类分析,得到树状结构图,并根据粘合力来确定每一个类别的中心主题词,分析主题词组合的语义关系,确定类别名称。
4 结果与讨论
最后得出两个时间段学科结构的差异,如表5所示:
两个时间段的高频低频词界分计算如表2所示:
| 表2 两时间段的高频低频词临界值的选取 |
计算得到的1999年-2003年主题词词频阈值为31,而实际词频没有31,因此确定阈值为最接近的33,提取高频主题词(累计百分比为41.0262%);2004年-2008年阈值为35,提取高频主题词(累计百分比为35.3791%)。同时得到两个时间段的高频主题词的词篇矩阵。
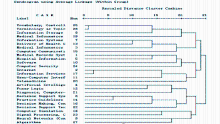
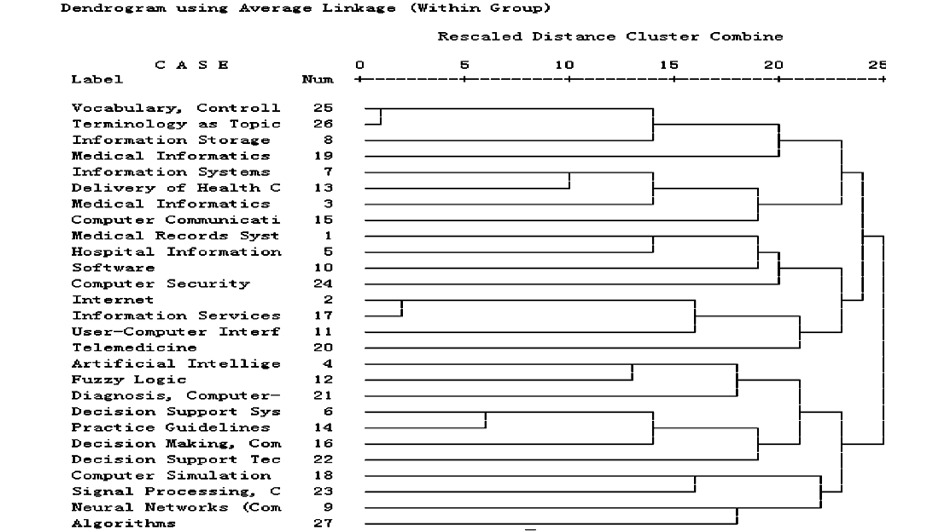 | 图2 1999年-2003年MI系统聚类树状图 |
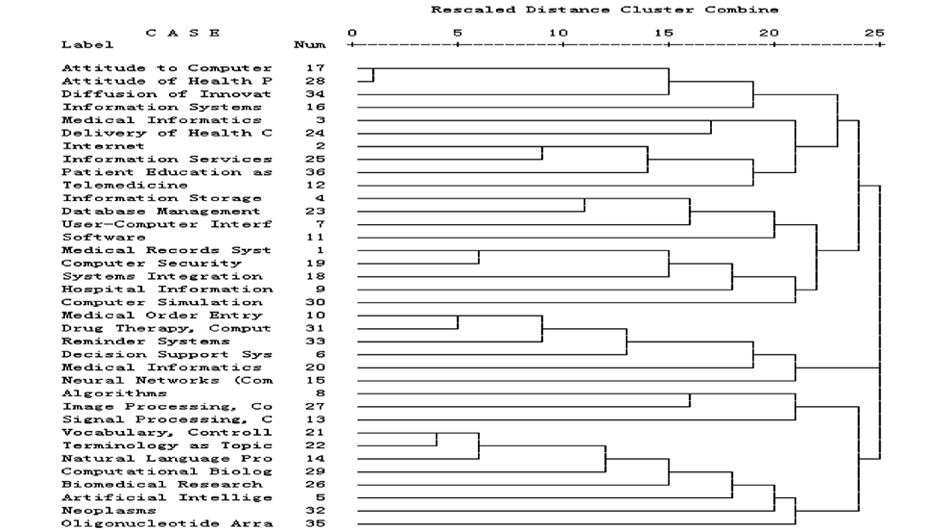 | 图3 2004年-2008年MI系统聚类树状图 |
对每个类别中的主题词的组合语义关系加以分析,根据粘合力来确定中心主题词并对每个类别命名,如表3和表4所示。
| 表3 1999年-2003年高频主题词及其粘合力 |
| 表4 2004年-2008年高频主题词及其粘合力 |
| 表5 两个时间段MI学科结构分类的对比 |
根据两个时间段的学科结构分类差异,进行两个时间段的结构分析: “医院信息系统中的电子病案系统安全性”、“计算机辅助信号处理算法”这两个热点的构成变化不大。其他热点的研究结构有所改变:
(1)后一阶段新增加热点“医务人员对计算机的态度”,不断追求创新并积极推广。
(2)表5中前一阶段(1999-2003)的第I类与后一阶段(2004-2008)第VII类对应,都是关于术语词表的研究,“术语”和“受控词表”都是类团的中心词,但其研究方向有所改变:前一阶段“信息检索与存储”的粘合力高,术语词表在信息存储与检索中的应用受到关注,而后一阶段的“自然语言处理”的粘合力高,自然语言处理与术语词表的关系密切,而且出现了生物医学研究、计算生物学、人工智能、肿瘤等热点,即“词表术语”、“自然语言处理”更多地与“生物医学研究”相关联,可见数据挖掘手段在生物医学领域应用广泛。随着数据库的开发与应用,后一阶段的“信息存储与检索”这个热点中融入“人机界面”和“数据库管理”,与“术语词表”分离,演变为独立的一类,即后一阶段中的第III类。
(3)后一阶段将前一阶段的“网络信息服务”与“医学信息学中的卫生保健系统”合并为一类“网络与医学信息学”,不仅囊括了远程医疗、卫生保健系统、信息服务,并添加了新的内容——“患者教育”。
(4)临床决策支持系统仍为两个时间段的热点,但前一阶段以人工智能为中心,研究模糊逻辑、医疗准则、计算机辅助决策和诊断的决策支持技术等;而后一阶段以计算机辅助药物治疗和遗嘱录入系统为中心,研究方向发生改变。
从对医学信息学领域的结构划分,可以清楚地得出:聚类树图利用高频词反映了医学信息学的研究热点,定量反映出词与词之间的亲疏关系,进而反映这些词所代表的主题内容的结构。但它在聚类的过程中将词间距离最短的主题词聚为一类,忽略了词与词之间的语义逻辑联系,因此也存在一定弊端:
(1)各个类别的组成是由主题词相互间的密切程度高而聚集起来,在聚集的过程中没有形成中心词,难以判别哪个主题词在聚类过程中起主要的作用。为了解决这一问题,本文引入评价主题词对类别贡献的指标——粘合力来确定各个类别的中心词。
(2)在聚类时,无法确定各个类别之间的关系,也无法辨明哪些是核心类别和成熟类别。可以采用其他方法,比如战略坐标或社会网络分析等方法从整体或个体的角度进行更深的剖析。
(3)划分类别的时候涉及到主观因素,不同的人对聚类结果的划分可能会有所不同,因此在分析前有必要对这一领域进行调研或向专家咨询。
(4)高频词阈值的确定直接关系到聚类的结果,以往的共词聚类方法是根据经验选取前几十到一百个左右的词作为研究对象,而本文依据齐普夫定律推导公式解决了高频词选取问题,使聚类结果更加可靠。
5 结语
以医学信息学学科为样本的共词聚类分析中,采用高频低频词界分公式确定高频词,因此,在对高频主题词的选取上有了可靠依据。此外,本文将粘合力的概念引入聚类分析,用其确定中心主题词并对每个类别命名,分类更加真实具体。将两个时间段的数据对比分析,对指导该学科专业人员了解学科前沿的演变趋势,集中有限力量在重点领域有所突破,促进学科发展具有重要意义。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|