{kind=link}
模糊规则算法在教育信息分类中的应用*
引用本文
梁文超, 徐朝军, 沈书生. 模糊规则算法在教育信息分类中的应用* . 现代图书情报技术, 2011, 27(1): 94-98
Liang Wenchao, Xu Chaojun, Shen Shusheng. Application of the Fuzzy Rule Algorithm in the Classification of Educational Information. 现代图书情报技术, 2011, 27(1): 94-98
Permissions
Liang Wenchao, Xu Chaojun, Shen Shusheng. Application of the Fuzzy Rule Algorithm in the Classification of Educational Information. 现代图书情报技术, 2011, 27(1): 94-98
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
模糊规则算法在教育信息分类中的应用*
摘要
以中小学简介信息分类为例,在分析该类数据特征项少、权重不均等特点的基础上,采用去噪处理、基于模糊集的同义处理等策略构建类别特征库,并以特征库为依据,使用模糊规则构建分类模型,实现对短文本数据的分类。实验结果表明:对于类别特征项较少、权值分布不均的短文本分类,模糊规则分类优于VSM、Rocchio等分类算法。
关键词:
TF-IDF; 模糊规则; 分类
中图分类号:TP393
Application of the Fuzzy Rule Algorithm in the Classification of Educational Information
Abstract
Because of the fact that the introductions of primary and secondary schools have less feature items and unequal weights, the authors use the strategies of denoising, processing synonym features based on fuzzy set to build category vocabularies, and then classify short texts using the classification model which is based on category vocabularies and fuzzy rules. The results show that using fuzzy rules to classify the short texts which have less feature items and uneven distribution of weight is better than VSM, Rocchio and other classification algorithms.
Keyword:
TF-IDF; Fuzzy rules; Classification
1 引 言
互联网中存在大量教学基础设施配置、教育新闻以及学校的发展规模、招生情况、学校师资实力等各类学校简介信息,如果能对这些信息进行挖掘提取、分类处理并加以统计,可以从侧面反映一个学校、地区的教育发展状况,为教育研究、教育管理、建设投资等提供决策支持。
本研究的教育实践发展现状监测系统,需要对主题蜘蛛定点采集的网络教育信息资源进行分类处理,并将处理结果以规范化、结构化的形式提交给后续的信息抽取环节。与普通文本自动分类的需求有所不同,此处的分类不再以蜘蛛获取的整篇文档作为处理单元,而是具体化到文档局部(以段落为单位),判断局部具有的类别特征,即对于文档子类别的划分。
分类模型构建初期,分别采用基于VSM的分类算法和Rocchio分类算法进行实验对比,分类结果的最终统计数据如表1所示。
| 表1 基于VSM的分类算法和Rocchio分类算法封闭测试结果 |
两种算法的F1测试微平均值均小于80%,与预期目标差距较大,分析原因如下:
(1)各类别的特征项之间交叉现象严重,导致分类精确度下降。
(2)单个类别具有的特征项数量不足,难以构成分类器所需的有效向量空间模型[ 1]。
(3)另外,分类器要对每个处理单元遍历所有的特征类别,严重占用系统资源并导致系统整体时效性的降低。
考虑到分类需求的特殊性以及对分类算法特性的分析,笔者结合所做的工作提出了一种以模糊规则为核心的文本自动分类模型,用于教育信息数据的分类。以教育信息中的学校简介类文档为例,对应子类划分为学校概况、联系方式、学校荣誉、招生情况、师资力量、学校设施6个类别,分类的任务是判断该文档中的某段是否具有以上列举的某类或某几类特征。
2 模糊规则分类模型
基于模糊规则的特征分类模型如图1所示:
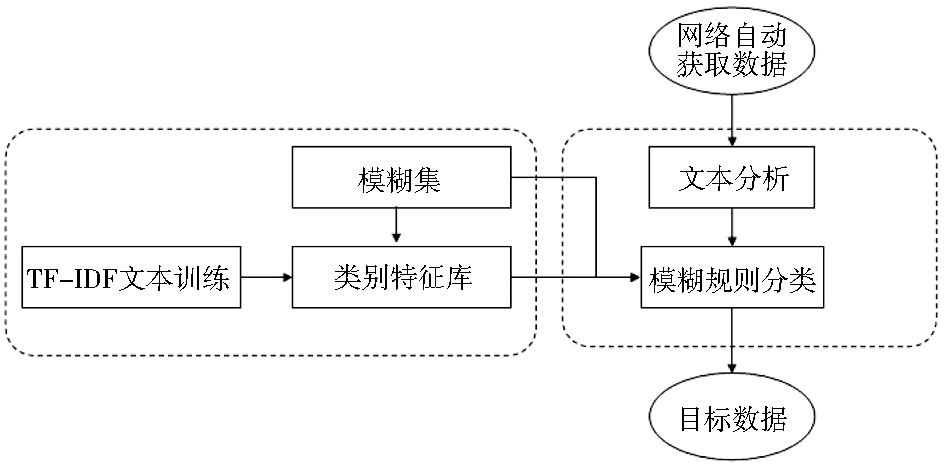 | 图1 基于模糊规则的特征分类模型 |
分类开始于对蜘蛛获取网页的文本分析,包括文档提取、分段处理与分词三个环节。文档提取使用正则表达式过滤HTML文件中的无效格式与信息,将原文档转化为格式规范、符合标准的文本文档。使用原文档约定的段落标识进行分段处理,提取出分类所需的处理单元;分词将篇章结构的文档转化为词的集合,便于文档的分析处理。考虑到分词效度与速度的均衡,以通用分词词典为基础并结合自定义词库,采用正向与逆向最大匹配技术进行分词,并根据具体需求过滤停用词与低频词。分词处理是较耗时的一项操作,原有的策略是先对文档分段再对段落分词,时间复杂度较高;采用改进策略,即对整篇文档进行分词处理,然后依据原文约定的段落标识对分词结果分段,实质是把对分词程序的多次调用合并为一次操作,实验数据表明处理文档的速度得以大幅提升。
文本分析环节抽取出以段为单位的处理单元,交付给模糊规则进行分类。模糊集(包括类别特征库中用到的同义词模糊集和分类中使用的量词模糊集)和类别特征库共同构成了模糊规则分类的前提,需要在分类模型之前先行创建,如图1左侧所示。模糊规则判定段落具有的类别信息,并将具有类别特征的段落及其类别项以规范的格式写入目标数据库。
3 系统关键技术
考虑到网络教育信息资源的分布状况及数据特点,采用模糊规则进行分类能够更好地处理该类数据集中大量存在的不精确的模糊信息以及多类别的交叉,尝试以人类的思维方式简化分类问题的复杂度,这也是笔者采用该分类算法的主要依据。模糊规则要以特征库提供的数据信息作为分类依据,因此特征库的建立构成系统的关键环节。
3.1 构建特征库
从各省市中小学网站及教育门户网站手工收集600篇学校简介类的文章作为训练文档,使用改进的TF-IDF算法进行迭代训练[ 2],取前200个标识度较高的特征词条建立特征库,表2为其中的前10条数据。
| 表2 学校简介类别特征库 |
为了确保较高的信度与效度,构建特征库时采用以下策略:
(1)噪音特征处理
学校简介在性质上隶属于教育信息类,如果直接采用TF-IDF算法进行学校简介类别特征训练,构成的特征库中将会存在大量教育领域常用基础词,比如“考生、学校、教育、考试”等,这些高频特征项平均分布于多个类别中,因而区分度较低,不具有任何特征识别性能,被称为噪音特征。因此,需要在构建类别特征库之前构建其所属的上位类别词库,即教育信息特征库,然后在构建所需类别特征库的过程中有选择地屏蔽上位库中的特征词,去除该类区分度较小的噪音特征,以提高分类的准确率。
(2)基于模糊集的同义词处理
同一语义的词有多种表述方式,比如建校时间的前缀可以采用“创建于”、“始创于”、“创办于”、“创始于……年”、“成立于”等词汇进行标识。为了提取出标识类别性能较高的特征词,采用基于模糊集的同义词处理方法,把一个同义词集合定义为一个模糊集S,选择一个主题词进行标识,然后使用主题词替换所有的同义词进行特征项权重值的计算,再采用训练文本计算每个词与其对应该概念的隶属度[ 3]。
模糊集:
S={(xr,SRD(xr,S))|xr∈X} (1)
隶属函数:
SRD(xir,Sr)=pir1m∑r=1mjpir×g(2)
其中,式(1)中xr表示同义词集X中第r个同义词或近义词,SRD(xr,S)表示xr对于S的隶属度;式(2)中Sr表示出现在某类文本集中的某个同义概念,xir表示Sr中的某个词,pir为词频,g表示用于控制SRD(xir,Sr)≤1的比例系数。
如将“更名为”、“改称”、“初名为”、“合并为”等表示学校名称变更的词定义为一个模糊集,然后计算各个词对该模糊集的隶属度。在文本分类阶段,利用词的隶属度与其对应主题词的权重值,重新计算词的类别贡献度用于分类,可以有效地解决特征项提取过程中出现的数据稀疏问题。
(3)子类别归一化处理
依据对该类数据分布特点的分析并充分考虑分类模型的综合性能,将TF-IDF训练得出的特征词划分到6个子类别中,便于教育信息的精确抽取和模型化处理。根据分类需求人工扩大部分特征项的权重值,然后针对每个类别所有特征词的权重值,即表2中的特征值1,进行归一化处理,处理后每个特征词的权重值,即表2中的特征值2,不仅保留了对于学校简介类文档的标识度,而且更精确地反映了其在所属子类别中具有的权重,这种分层次计算特征项权重值的方法能够有效地提升分类精确度。归一化的计算公式如下:
W′ik=Wiklog(Nnk+0.01)∑k=1n(Wiklog(Nnk+0.01))2(3)
其中,Wik为初始权重值,N为文档集中的总文档数,nk为出现特征项的文档数。
3.2 模糊规则分类
模糊规则分类是模糊逻辑推理的一个应用。基于规则的专家系统常应用于错误检测、生物、医学等领域的分类器构造。模糊逻辑通过提供对分类器结构和决策过程更为深入的认识,能够提高分类结果的可解释性,从而改进分类和决策系统[ 4]。
模糊规则采用“if…then…”形式的语句进行表示,多条模糊规则的集合构成模糊规则库作为分类的依据。具体描述为[ 5]:
Ri:if x1is Ak1,and xn is Akn,then y is Ck.(k=1,2,3…m) (4)
(1)数据表征方式
模糊规则分类算法中使用数据的表征方式如下:
P={A,C,D} (5)
其中,P表示以段落文本为单位的待处理单元,由三部分构成:A={ai|1≤i≤n},指的是文本中不重复的词的集合,并且所有的词映射为与之相对应的主题词;D表示该段落所属的文档;C={cj|1≤j≤n},表示该段落所属的类别集合。
F={N,W,C} (6)
其中,F表示的特征库是分类算法的依据,N、W、C分别对应特征库中的特征项、特征项权重值及所属类别。
(2)分类算法
对于以段落为单位的文本进行分类,模糊规则算法的核心是计算文本与各个类别的相关度。分类算法的伪代码如下:
foreach(Parap in P)
{ Feature f;
foreach(Term word in p.a) //计算段落具有某项类别的权重值
{ if(word∈F.N) //单词存在特征库中,将该单词的权重和类别信息写入p
{ type= word.featureType;
weight = word.featureWeigth;
f.c[type].weight += weight;
}
}
foreach(t in f.c)//临时变量f中某项特征权重值与特征库中该项特征权重值比较
{ if(t.weight >F[t].w * WMAX)// WMAX为上限比率阈值
p.addType(t);
else if(t.weight < F[t].w * WMIN)// WMIN为下限比率阈值
continue;
else
{
foreach(Term word in t.nearWords)//遍历t某特征项前后一定范围内的词
if(word∈S) p.addType(t); //S表示某特征词对应的量词模糊集
}
}
以构建的类别特征库为基础,统计文本所具有的各类别特征的权重值Wi(i=1,2,3…6,i指前文所述的6个类别),如果Wi
对处于可能域空间的类别,标记该类别并判断该类别包含特征项与对应量词模糊集的关系。假如学校概况类的相关度处于上下限阈值之间,并且文本中出现“教职工”一词,判断该词前后一定范围内是否出现其对应的量词“人”或者“名”。如果出现对应的量词,表明该文本内包含需要抽取的数据信息,信息形式为“…教职工XX人(名)”,或者“ …XX人(名)教职工”,可以据此直接判定该特征。采用这样一种推理判定方式基于两方面的考虑:首次的类别权值计算已经形成了对于文本性质的判定,确保该段文本处于某项特征的可能域空间;匹配量词是对可能域精确化的二元判断,即如果文本串包含确定抽取项,则赋予特征标识,这一逐步精确的过程同样也符合模糊逻辑推理的思想。
模糊规则分类中使用的上限(WMAX)与下限(WMIN)阈值的设定是关键点,它直接影响分类模型的整体性能。阈值采用了动态的比率阈值而非确定的数值型阈值,避免因不同类别特征项权重值的分布不均衡产生的分类偏差。比率阈值的设定一方面结合教育资源专家知识库,另一方面以多次测试数据结果为依据,不断修正调整比率,力求设定的阈值能够最大限度保证分类模型准确率与召回率之间的均衡[ 7]。
4 测试结果分析
本分类模型基于Windows XP/SQL Server 2005,开发语言为Java。分类模型的构建分为训练和测试两个阶段,然后开放应用于教育监测系统平台。
对于分类模型的训练仍然采用构建特征库时使用的600篇中小学校简介类文档,反复训练确保调整后的阈值能够使分类模型的准确率与召回率达到最佳平衡点,然后使用主题蜘蛛定点采集学校简介类文档300篇作为测试文档。为了验证模糊规则分类的性能,同时引入基于VSM的分类作为比较,两种分类方法分别处理测试文档后得出的统计数据如表3和表4所示:
| 表3 模糊规则的分类结果 |
| 表4 基于VSM的分类结果 |
表3和表4分别给出了两种分类算法针对6个类别的分类数量、召回率、准确率和F1测试值,其中模糊规则分类的F1测试微平均值达到0.91,大于基于VSM分类的F1微平均值0.81,表明前者的综合分类性能存在明显优势。
模糊规则分类的召回率较高,除学校概况类外均达到90%以上。召回率微平均值比基于VSM的分类高出13%;与之相比,准确率的微平均值增幅较低,只达到8%。表明模糊规则能够查找到属于某类别的绝大多数文档,而查到的文档中有相当一部分并不属于该类别。分析认为是阈值设定较低的原因,在保证召回率不受影响的前提下,对上下限阈值做适当调整后,分类准确率稍有提高。
与其他5个类别相比,学校概况类的特殊性体现在两种分类算法在处理该类别信息时表现上的相似性:分类数量差额为4,准确率与召回率差额均为5%左右。结合类别特征库分析,学校概况类别的特征项数量高于其他类别,而且权值分布较为均衡,能够形成有效的向量空间模型,因此基于VSM的分类对于该类别信息处理的性能高于其他类别。这也从一个侧面说明了模糊规则分类的特性及适用环境。
将最终调整的分类模型应用于教育监测系统平台,实现对蜘蛛获取网络资源的实时分类。系统共运行90小时11分15秒,处理数据1 000 000条,平均速率为3.08篇/每秒。随机抽样统计数据显示,模糊规则分类的召回率依然保持较高水平,精确率随测试文档的增多稍有下降。
5 结 论
模糊规则分类模型以模糊推理为依据,更好地适应了教育信息特征项不足且类别交叉严重、分布稀疏以及表述无规律的特性。根据对模糊规则的分析及其与VSM分类结果的比较,可以得出如下结论:
(1)模糊规则分类以专家知识库和类别特征库为基础,因此需要反复训练,采取多种策略,如摒弃上位的教育领域常用词、基于模糊集的同义处理等,构建信度较高的类别特征域,确保其最大限度地反映本主题域的特征构成状况。
(2)与其他分类算法相比,模糊规则构造方法简单,易于理解和调整;规模较小,运行时的空间复杂度与时间复杂度较低,因而具有较高的分类速率。
(3)模糊规则分类适合于文档子类别(局部类别)的分类。另外,对于篇幅较短、特征项权重值分布不均衡的文本处理(类别判定依赖于部分主要特征项),模糊规则在分类速度、分类精度等方面具备优于其他分类算法的性能。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|