{kind=link}
{kind=link}
语义数据库Freebase研究
引用本文
李俊. 语义数据库Freebase研究. 现代图书情报技术, 2011, 27(10): 18-23
Li Jun. Research on Semantic Database Freebase. 现代图书情报技术, 2011, 27(10): 18-23
Permissions
Li Jun. Research on Semantic Database Freebase. 现代图书情报技术, 2011, 27(10): 18-23
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
语义数据库Freebase研究
摘要
采用文献研究与案例分析方法,对语义数据库Freebase进行研究。介绍Freebase与其他语义Web项目的区别及其数据来源,并分析其数据库架构的技术特性,对其在语义Web环境下知识表示和组织的理念与技术进行重点研究。同时对国外基于Freebase的应用进行探讨,为国内图书馆使用Freebase数据提供建议。
关键词:
Freebase; 语义Web; 关联数据
中图分类号:TP182
Research on Semantic Database Freebase
Abstract
Based on literature research and case studies, this paper makes an analysis on Freebase. It introduces the differences between Freebase and other semantic projects, studies the sources of Freebase, analyses its structure and features, and mainly focuses on the research of its knowledge representation and organization. This paper also explores the applications based on Freebase and the advices on how to use Freebase, which provides a thought to the research on advanced information technology as well.
Keyword:
Freebase; Semantic Web; Linked data
从文档网到数据网的过渡是当今Web技术重要发展趋势之一[ 1]。为Web赋予语义信息,让Web成为基于知识的资源共享平台是Web发展的必然趋势。在这种趋势下,许多新的理念、方法技术不断发展,关联数据(Linked Data)和语义Web(Semantic Web)成为数据网的主流方法与技术。语义数据库Freebase[ 2]集成关联数据和语义Web的理论与方法,为研究语义Web与关联数据技术和开发语义应用提供了优秀平台。本文主要研究Freebase在语义知识库建设方面的先进理念和技术,并探讨其对数据网建设的启示。
1 Freebase介绍
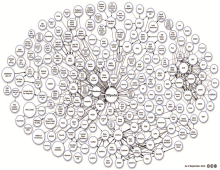
语义Web力图实现所有网络数据的无缝连接,并使数据能被计算机自动处理和理解,最终目标是使计算机能够在海量信息中找到真正满足需要的任何信息。语义Web技术能够在任何微小网络数据之间建立连接,同时能够帮助人们更精确地描述数据的含义[ 3]。关联数据技术是实现数据网络的最佳实践,通过在语义Web中使用URI和RDF发布、分享、连接各类数据、信息和知识,从而可以通过HTTP协议揭示并获取数据,同时强调数据的相互关联以及有益于人机理解的语境信息[ 4]。关联数据为实现语义Web奠定了坚实基础。Metaweb公司充分利用关联数据和语义Web的理论和方法,于2007年3月在线发布了语义数据库项目Freebase。2010年9月的LOD数据云图显示Freebase和DBpedia是整个LOD数据云图的数据中枢,如图1所示:
 | 图1 2010年9月的LOD数据云图[ 5] |
朝乐门等[ 6]介绍了DBpedia的6个特征,同时总结出DBpedia存在的一些问题,如数据结构化程度低、数据不一致以及数据质量低、数据权威性和规范性不高、对Wikipedia数据的更新存在滞后性等。Freebase与DBpedia是非常相似的项目[ 7],它们都从维基抽取结构化数据并发布成RDF。但Freebase是完全结构化的数据库,且数据来源不局限于维基,更导入了数量众多的专业数据集,并提供先进的数据查询和录入机制,相比DBpedia数据更全面,功能更为强大。Freebase与DBpedia的数据在2008年11月通过内置OWL属性owl:sameAs进行互联,使这两个数据集关联更密切。
2 Freebase数据来源
自底向上(Bottom-up)地建设语义Web,即从简单关联大量开放数据集开始,逐渐积累并丰富其语义,已经获得越来越多的共识。这种方式通过发布W3C支持的标准(如RDF,OWL)来定义资源和语义关联,技术有效且功能强大。缺点是对人类阅读和创立知识来说显得较为复杂和困难,且缺乏W3C支持的通用本体。目前许多社区和机构通过协作来构建大型语义知识库,数据由各领域专家手动贡献或由数据集建立者使用工具自动添加,再由程序或人工为数据进行语义分析。
Freebase从多个角度来集成数据:
(1)提供一个AJAX页面,用户可以通过编辑数据云中的单个节点添加或修改数据;
(2)提供开放的API工具MQL给专家级用户或数据集拥有者,方便他们把已存在的数据集集成到Freebase数据云中;
(3)通过数据萃取工具(如Yahoo Pipes, Dapper)对HTML页面进行数据萃取,通过MQL导入到数据云中;
(4)对数据进行建模操作的用户可以通过MQL直接将数据集成到数据云中。
MQL包含了对数据读写和查询等各方面的功能,通过MQL进入数据云中的数据已具备语义,用户可以使用RDF API对数据云中的数据进行读取并发布到页面中,应用程序开发者可以直接使用MQL对数据进行读取和使用。Freebase数据的导入和使用都需遵守Creative Commons Attribution License[ 8]。
相比DBpedia只从Wikipedia抽取数据,Freebase数据来自多种多样的数据集。一些数据由Freebase的Data Pipeline自动数据导入任务程序定时导入,如Wikipedia的数据每两周自动导入,Netflix的数据每一周执行自动导入。另一些由Freebase数据小组或社区成员使用MQL或其他数据导入工具批量导入,另外还有个人用户通过页面逐条手工编辑来增加数据。
Freebase的许可协议要求贡献者只能提供与Freebase许可条款兼容的数据,目前Freebase已经集成的一些知名数据源[ 9],如表1所示:
| 表1 Freebase已经集成的部分知名数据集 |
此外,还有很多如足球运动员数据库、地理名称信息系统、美国国家医疗数据库、美国教育统计信息等符合Freebase许可协议的数据在不断地被导入。随着人们对关联数据的研究越来越深入,更多的信息中心,包括政府、机构、各种组织开始使用语义Web技术和关联数据组织发布他们的信息和数据[ 10]。未来Freebase数据源将无限扩展,Freebase建立全球信息中心的理想将逐步变成现实。
3 Freebase数据库架构
Freebase后台数据库(Graphd)以节点和节点间关系的图状结构来组织数据,与传统关系数据库以表的方式组织数据完全不同[ 11]。Freebase服务器与Graphd紧密绑定,通过二进制数据存储块来储存图节点和节点关系,以哈希表的方式存储组织数据,在用户上传、下载数据时起到临时数据缓冲作用,在对数据进行检验处理后再保存到Graphd中[ 12]。Graphd的图结构由一系列节点和反映节点间关系的有向连线组成。图中每个节点记录与自身相关的信息,数据库中所有相关数据都以记录节点间关系的方式组织数据进行存储。Graphd以数组的方式对节点和其关系的元数据进行建模,以表格形式存储。表格中的每条数据对应一个节点关系数组,数组由源节点、属性、目标节点、源节点值组成。属性是节点间的关系,系统不以已存在的节点关系对新关系进行预定义。新属性表示一种新关系,可以在用户需要时被定义。在图中,属性也可以是节点,当属性为节点时,它将保存在数组表中的源节点列中,并与自身产生关系。Graphd中定义了一些必要属性作为架构中最基础的部分,如“/type/object/name”属性支持节点定义可读性较强的名称。基础属性为其他用户定义的属性规定了基本行为,数据库本身也依赖这些行为。
Graphd的图是有向图,节点关系的方向从源节点指向目标节点。虽然关系是有向的,但执行数据查询时,Graphd可以向前和向后遍历所有有向连线来获取查询结果。因为Graphd会按不同方向遍历连线,所以可以将节点间连线看作具有双向性。在属性定义时,可以将一个方向的属性定义为“主属性”,反向上定义为“逆属性”,这两个属性也称为“互惠属性”。在Graphd中,可以通过“/type/property/reverse_property”属性标注主属性和逆属性,从而实现关系的双向遍历。具体而言,当用户输入问题时,数据库引擎会分析用户输入的问题,得到问题的主体和可能所处的领域,在“源节点”列和主属性“属性”列中进行检索,然后将所有匹配的“目标节点”列中的值反馈给用户。也会反向在“目标节点”列和逆属性“属性”列中检索,也将所有相匹配的“源节点”列中的值反馈给用户,这样可以将所有用户想知道的信息呈现给用户。这种架构设计有效地保障了数据的查全率。
Freebase的图存储结构是一种可扩展元组存储,包含内置的查询规划和性能优化,允许快速和深入地构建数据,使查询能够被高效执行。这使得在数据查询方面没有特别技巧的用户借助Freebase数据也能构建高性能的系统和算法,为用户开发应用程序提供了性能保障。数据存储整合了反转机制(Revision),支持所有数据编辑的反转(Undo),因此允许大规模复杂操作回转到任何阶段。图存储支持所有数据属性的细粒操作,这些特性使得数据在面对恶意攻击时也能保证其安全性。
4 Freebase知识表示和组织机制
基于Freebase数据库架构的特点,可以把数据库想象成由一个个数据节点构成的庞大的数据云图。为了对如此多的数据进行表示和组织,Freebase使用了一个轻量级分类系统(Type System)。这套分类系统是一个结构化机制和约定的松散集,而不是本体和陈述固定的系统[ 13]。分类系统支持协作创建数据分类和属性,不会将世界上所有知识固定在条框之内。用户对同一知识不同的理解和观点可以通过为数据条目添加不同的分类和属性来表示。例如对Arnold Schwarzenegger,可以为其添加多个Type(如Person,Actor等)来表示他不同的身份[ 14]。不同分类的元数据定义了各自的属性(Property),通过众多属性值来全面揭示Arnold Schwarzenegger的信息。需要注意的是,Arnold Schwarzenegger作为一个数据条目(Topic)在Freebase系统里是唯一的,表示且仅表示现实世界中唯一的一个实体或概念,也就是说在Freebase数据云中,对应现实世界中Arnold Schwarzenegger这个人的只有唯一一个节点。
Freebase的分类系统包含很简洁的核心概念(Topic,Type,Property,Schema),如此设计是为了能够与其他系统的本体结构实现简单方便的映射。在Freebase中每条信息称为一个条目(Topic),一个条目是特定且具有明确意义的数据(如人物Arnold Schwarzenegger),也可以是一个抽象概念(如数学中的圆周率PI,基督教)。类型(Type)给条目分类,一个条目可以有多个类型,并且条目的类型可以随时添加或删除。与条目类似,一个类型仅表示唯一的一个意义,但Freebase允许为类型起别名,方便在不同的上下文语境中使用。类型不存在继承机制,而是通过在需要时创建来丰富。这是因为每一个类型元数据定义了不同的属性,例如类型“Film Actor”不会从“Person”继承,因为有些演员不一定是人(如动物),但两者可能会有相同的属性(如参演的电影Films)。通过为现实世界中实体定义类型并定义类型元数据,就能全面描述实体。属性(Property)是Freebase中最重要的概念,表示节点间关系。属性值可以是一个字面量,也可以是与其他条目之间的关系(如is a parent of)。每一个属性值会要求一个期望类型(Expected Type),意思是当填写一个属性值时需要填写的是一个类型还是一个条目或者是一个字面量等。当一个属性的期望类型是一个条目的时候,就会将两个条目连接起来,相当于把数据云中的两个节点连接起来,从而形成整个数据云。每一个类型是零个或多个属性集合,这被称为这个类型的模式(Schema),模式本质上是定义了一个类型的元数据,也可以理解为语义Web中的本体。
Freebase还设计了其他一些相关概念,如命名空间(Namespace)、域(Domain)、Key、ID等[ 15],这是为了帮助组织类型元数据,赋予条目可读性比较强的URI。通过一些很简洁的概念设计,Freebase很好地实现了知识表示和组织,不仅实现了语义Web和关联数据的技术要求,而且使数据的浏览和使用更为方便和简单。这种简单的体系设计使之与其他基于本体结构数据集的本体映射与数据融合较为容易。Freebase提供模式查看工具[ 16]来帮助用户了解知识组织的体系。图2显示了域Library的模式。
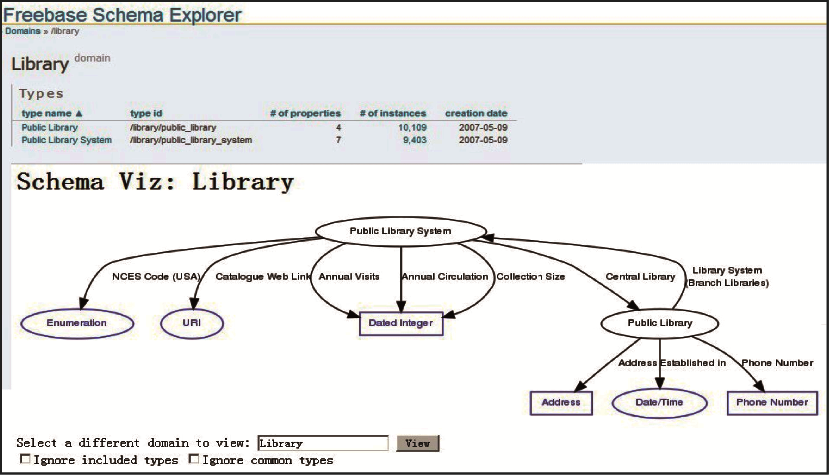 | 图2 域Library的模式可视化 |
5 Freebase其他特性
Freebase与一些语义Web项目和关联数据集相比,除了更为多样的数据源、高效的图结构数据库架构、简洁的知识表示和组织机制,还提供更优秀友好的数据协作建立和使用机制。Freebase的特性被设计成能够方便用户在组织、展示和整合大规模多样数据集时高度协作。Freebase为人设计了基于AJAX的客户端,为机器设计了基于JSON/HTTP的API MQL,使人和机器能够紧密合作来建立和编辑复杂且不断发展的结构化数据。Freebase提供的MQL相比Graph/RDF查询语言(如SPARQL,SERQL,RQL,MQL等)功能相同,但更简洁且更具表达性。
Freebase社区提供健全的PHP,Python,Perl,Ror,Java等主流工具库,帮助开发者使用Freebase数据。同时提供健全的查询和编辑手册,使应用程序开发有很好的基础。
Freebase作为一个发展了4年的项目,目前正在努力实现全球化信息中心的目标。但也面临着一些需要解决的问题,如Web页面和帮助文档的国际化,增强自然语言处理能力,垃圾数据和非法数据的处理等。Freebase通过邮件列表和社区讨论的方式探寻解决这些问题的方法。
6 使用Freebase数据构建应用
Freebase集成了语义Web与关联数据的先进理论和方法,在数据的使用方面提供了一套封装了语义Web技术的体系,方便用户创建和发布自身领域的相关数据,同时此技术体系也为使用Freebase丰富的数据提供了强大的工具与方法。用户可以从多个角度来使用Freebase数据,如用作参考或信息源,把Freebase数据嵌入自建的页面,利用API或Acre工具建立宿主程序,把Freebase所有的数据进行转储再利用,利用Freebase提供的RDF数据服务建立语义Web应用等。目前国外基于Freebase的典型应用有如下几个方面:
(1)UI应用。Freebase基于AJAX的页面类似于Wikipedia,用户可以通过浏览器查看、编辑相关数据。典型UI应用还包括Freebase Schema Explorer,该应用提供可视化界面来浏览Freebase中的类型元数据;Query Editor提供MQL查询可视化编辑器,帮助用户构建查询。
(2)数据挖掘应用。典型应用是自然语言搜索引擎Powerset,它致力于构建一个能进行Q&A的自然语言搜索系统,很多问题Powerset会从Freebase获取答案。目前Powerset已被微软收购,发展成微软必应搜索引擎[ 17]。Google收购Freebase后也利用Freebase海量数据来提高数据搜索质量。
(3)跨领域共享与服务。DBpedia作为关联数据中枢,扮演了不同数据集的纽带角色。但由于数据来源的局限性,其知识结构化程度和数据质量往往低于专家手工创建的知识库。Freebase集成数据的理念包含融合专业领域数据集。随着关联数据技术越来越广泛地被使用,专业数据集越来越丰富,Freebase有望成为互联网数据互联的中枢。当用户遵循Freebase许可条款发布数据时,数据就能通过Freebase融合到LOD中,Freebase就成为一个语义发布平台。
(4)利用Freebase数据构建专业数据集。此方面的应用在关联数据领域颇具特色。方法是抽取已有数据集中某一领域数据,集成为一个专业数据集。多伦多大学的一个项目小组构建了Linked Moive Data Base[ 18],从众多数据集中抽取电影相关的数据,进行融合处理,成为专业的电影知识库[ 19]。
(5)由Freebase驱动的Web应用。此方面应用是对Freebase数据进行直接消费,可以把数据应用到数据融合、语义标注、问答系统等各个场景。伦斯勒理工学院一个项目小组使用关联数据帮助研究美国最高法院的裁决[ 20],此项目基于美国最高法院数据库(SCDB)[ 21],并使用了DBpedia与Freebase中数据来增强SCDB原始数据。
国内研究语义Web和关联数据的学者和机构越来越多,但在应用实践方面成果还比较少。把理论和技术方法转化成能为用户服务的现实应用,需要图书情报界和其他相关学科学者共同努力。Freebase作为一个典型语义Web与关联数据项目,为图书馆提供了丰富数据和完整的技术体系来实现资源发现服务和图书馆语义应用系统的构建。高校图书馆可以利用Freebase数据创建信息服务系统,如利用Freebase中大量图书信息开发图书信息发现系统,利用教育相关信息开发留学信息系统,利用大量人物信息开发学科专家系统等。还可利用Freebase是关联数据中枢和可作为语义发布平台的特点,把图书馆的资源和外部世界连接起来,从而将数据融合到整个数据网中。
7 结 语
Freebase是一个可扩展、协作型、结构化的数据整合平台。它在语义数据库架构和知识组织方面的理念十分先进,对开展语义知识库与关联数据建设具有很强的借鉴价值,运用Freebase各领域数据进行各方面的应用开发也具有很强的实用价值。目前国内图书情报机构多数使用关系数据库存储数据,未来首先要解决这些数据的发布问题,在此基础上进行各组织间数据的集成和融合,实现不同类型的资源、信息和知识的共享。进一步开展基于关联数据的知识发现研究,从而为用户提供更有价值的信息服务。Freebase在这些方面的实践比较成功,对国内学者研究和实践具有很好的参考价值,值得继续探讨。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|