


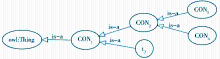



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于FCA和Folksonomy的本体构建方法
引用本文
张云中. 一种基于FCA和Folksonomy的本体构建方法. 现代图书情报技术, 2011, 27(12): 15-23
Zhang Yunzhong. A New Ontology Construction Method Based on FCA and Folksonomy. 现代图书情报技术, 2011, 27(12): 15-23
Permissions
Zhang Yunzhong. A New Ontology Construction Method Based on FCA and Folksonomy. 现代图书情报技术, 2011, 27(12): 15-23
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
一种基于FCA和Folksonomy的本体构建方法
摘要
针对当前使用Folksonomy进行本体构建的问题,归纳总结当前方法存在的局限性,指出FCA集数据分析与概念建模于一身的特性在解决这些局限性上的优势,通过构建基于FCA和Folksonomy的本体构建方法模型,最终得出一种基于FCA和Folksonomy的本体构建方法,为网络社区环境下通过Folksonomy实现低价、高效、及时、灵活和人本的本体构建过程提供新的思路。
关键词:
形式概念分析; 分众分类法; 本体构建方法
中图分类号:G203
A New Ontology Construction Method Based on FCA and Folksonomy
Abstract
Due to the current Ontology construction problems using Folksonomy, the limitations of the current approaches are summarized, and the advantages of FCA’s characteristics on solving these defects are pointed out,because it has the functions of data analysis and conceptual modeling rolled into one.By the way of building the Ontology construction model, a new Ontology construction modeling method based on FCA and Folksonomy is proposed, and it provides some new ideas and perspectives for achieving a low-cost, efficient, timely, flexible and people-oriented Ontology building process in Web community environment.
Keyword:
FCA; Folksonomy; Ontology construction method
1 引 言
当前,本体已发展成为知识管理和语义网的一种不可或缺的核心技术。与此同时,本体的构建方法也因本体应用范围的扩大和本体应用环境的日益复杂进行着相应的变革,尤其是Web2.0的不断发展和语义Web技术的不断成熟对本体开发提出了低价、高效、及时、灵活和人本等新的要求。事实上,诸如骨架法、评估法、SENSUS、七步法等本体论工程方法学中包括的传统的专业领域本体构建方法已不能满足上述要求,甚至存在弊端。
(1)本体构建应当是一个群体智慧相互协议决议的过程[ 1],但事实上大多数本体仅为个体或小群体的专家来设计,而作为本体使用者的用户却没有参与到开发过程中来[ 2],可以说,构建本体过程中用户参与过少是造成缺少令人满意的本体的重要原因之一[ 3]。
(2)传统本体构建采用集权式和形式化的途径,即通过专业人员和知识工程师来为用户构建并维护本体。这种集权式的途径导致了诸多问题:本体开发的高成本,难以对领域知识和用户需求做出与时俱进的变革,因缺少本体构建者和使用者间的交流而导致本体使用中的误解等[ 4]。
社会标签系统的协作环境可为高效的本体开发提供启示[ 5],Folksonomy的大众化、低成本、技术简易、时效性强、动态柔性等优势为本体构建带来了新的契机和希望,它对资源的组织有其自身不可替代的价值,更为知识工程师提供了一个新的角度理解本体, 特别是为本体构建提供了新的思路和途径。
FCA[ 6]是在给定数据集合基础上生成概念结构的一种数据分析方法,它强调用数学手段来表达、分析和构建客观知识,从大量数据中抽取和生成概念,构建概念层次化结构模型。文献[7]剖析了FCA与Folksonomy的关系并指出可利用FCA来协助进行Folksonomy中的相关数据和知识挖掘。
在上述背景下,本文研究的问题可界定为:利用FCA相关理论和技术,从网络社区社会化标注系统中的Folksonomy数据集抽取出适用于社区的本体。本文旨在提出一种基于FCA和Folksonomy的本体构建新方法,先设计该方法的理论模型,进而给出详细的研究过程,最终用研究结果来阐明该方法的科学性、易用性和优越性。
2 基于Folksonomy的Ontology构建研究现状
文献[3]提出了一种通过整合多种资源和技术的综合性方法来从Folksonomy中抽取出本体。该文认为应该整合的资源或技术包括:关于Folksonomy、相关使用数据及隐含的社会网络的统计分析;在线词汇资源,如词典、WordNet、Google 和Wikipedia;已有本体和语义网资源;本体映射和匹配方法;设计目的。尽管该文阐明了上述资源或技术在本体构建中的主要作用或贡献,但并没有明确提出一种规范化的具体方法。
文献[2]也延续了文献[3]的研究趋势,提出了一种基于Wiki 技术的协作式本体进化系统。
文献[8]通过两个案例研究来阐明Folksonomy中的本体浮现,提出Folksonomy中基于标签的共现的“概念-实例”网适合于进行概念挖掘,而基于兴趣标签共享的“用户-概念”适合于提取关系。
文献[9]将研究重心放到了从Folksonomy知识建构中抽取出结构化的信息(即本体)。
文献[10]认为可从Folksonomy中包含的社会网络关系来统计提取标签语义关系进而构造本体,并指出由Folksonomy构建本体的4个步骤:标签预处理;建立标签相互关系图;标签语义关系抽取; 社区成员参与生成本体。
文献[11]利用社会网络分析的理论和方法,采用“浮出语义”的思路, 分析基于Folksonomy的“标引者-标签概念-实例”三部图模型发掘概念间语义信息、建立本体的方法和过程模型。
文献[12]提出了一种基于FCA的Folksonomy语境构建方法,并根据语境从博客世界的标签中提取概念层次;文献[13]提出了一种基于FCA的Folksonomy数据挖掘方法来发现Folksonomy中的隐含知识,并给出了运用FCA对Folksonomy数据挖掘的一般步骤;与之类似的还有文献[7,14,15]。这些文献都提出了一种思路,即用FCA来对Folksonomy中的数据进行分析,依据形式背景和概念格这两种强有力的数据结构来为Folksonomy中的相关知识进行建模,这都为本文的研究提供了启发。
综上所述,国内外当前已形成了可使用Folksonomy进行本体构建的一致观点,但就如何进行构建的问题,国内外学者思路各异,存在很大分歧:部分学者强调从Folksonomy的标签集及隐含的社会网络中用统计方法获取标签层次关系作为构建本体的基础,如文献[2,3,10]等;还有部分学者强调基于Folksonomy本体构建必须以语境为基础,通过“标引者-标签概念-实例”的对应关系来发掘语义进而构建本体,如文献[11-15]等。本文偏向于后者,且认为当前基于Folksonomy构建本体的研究存在以下三方面的局限性:
(1)虽在宏观上形成了一般性的构建思路,但没有深入研究进而形成规范化的详细的方法模型和流程,可操作性差。
(2)获取标签间语义关系的途径多样,以统计方法为主,但统计分析通常以一定的假设为前提,且方法的选用直接影响着语义关系的质量,因而用统计方法抽取的语义关系具有局限性。也就是说,目前学界尚未形成一种简洁有效的标签语义关系获取方法。
(3)没有明晰标签-资源与本体之间的映射关系和转化规则来阐明Folksonomy如何映射和过渡为Ontology。
这三方面的局限性正是本文研究的逻辑起点,而FCA的集数据分析和建模于一体的独特优势和在Folksonomy中的运用的相关研究使其成为解决上述局限性的重要理论依据和具体方法。
3 基于FCA和Folksonomy的Ontology构建方法模型
本文要解决的核心问题可总结为:利用FCA相关理论和技术,在大量网络社区用户和少数知识工程师的协作下,经过一系列规范化的可操作流程,从网络社区社会化标注系统中的Folksonomy数据集抽取出适用于社区的本体,并将其运用到网络社区中进行修正完善。
为解决上述问题,本文提出一种新的基于Folksonomy的本体构建方法,具体模型如图1所示:
 | 图1 基于Folksonomy的Ontology构建方法模型 |
(1)并非所有Folksonomy都可用来构建本体,社会化标注系统形成后,必须经过一个语义浮出[ 16]的过程,逐渐获得一个统一的语义模型,从而使得社会化标注系统达到一种相对的稳定状态,并形成稳态Folksonomy概念模型,此时,Folksonomy才可用以构建本体。当然,针对社会化标注系统是否进入稳态的判断,要有一定的度量标准,Folksonomy中的标签符合长尾分布[ 17]和负幂分布规律[ 18]在某种程度上是社会化标注系统进入稳态的一种反映。
(2)通过标签清洗、标签合并等方式,得到Folksonomy原始数据集。标签清洗是将不规范的标签进行规范化的过程,标签合并是将拼写有误的标签合并为拼写正确的标签;将不同词性的标签抽取词干合并为一个标签;将标签相似度(标签相似度的计算可参考文献[19])超过一定阈值的标签定义为“相似词”并进行合并,最终得出Folksonomy原始数据集。
(3)由于本体是共享概念形式化的规范说明,因而要强调共享性,剔除Folksonomy中体现用户“自我性”的标签。这就需要在形成稳态Folksonomy概念模型后,结合长尾理论、负幂分布规律,通过设置合理的阈值,保留反映大众对于信息本质认知一致的标签,去除小众意见(即Minority Opinion),即过滤掉低频标签或单独出现的标签。另外,根据文献[20]提出的标签7类功用,剔除与本体构建相关性不高的诸如用以实现“自我参考”和“任务管理”等功能的标签,最终得出Folksonomy精炼数据集。
(4)运用FCA理论构建形式背景。即以二元表为数据结构,将Folksonomy精炼数据集中的T-R数据对填充到二元表中,得到Folksonomy的形式背景。进而使用造格算法或概念格构造工具,将上述形式背景转化成相应的概念格,由从事本体构建具体工作的知识工程师对Folksonomy概念格进行相应的分析。
(5)在概念格分析过程中,将标签或资源按照相应的规则映射对应到本体的类、属性和实例上,并对本体进行完善。具体的映射规则是:
①将概念格中的每个节点(空节点除外)映射为本体的一个概念(或称类),并为之命名。若节点内涵中存在能高度概括节点概念的标签名称,可将该标签从节点的属性中剥离出来,直接作为节点概念,若不存在这样的标签,可进行恰当的命名。
②将节点的内涵,即节点包含的所有标签(被用于节点概念命名的除外)映射为本体的概念属性。
③将节点的外延,即节点包含的所有资源映射为本体的实例。
④删减没有实际意义的空节点。
上述步骤之后,由知识工程师将结果上传到社区中,由社区成员对概念格向本体的映射过程做出投票表决,判定本体概念命名的恰当性和本体属性和实例的完备性,并对不完善的本体概念、属性和实例进行校正或补充,重复投票过程,直至半数通过为止。
(6)根据社区成员投票表决后的映射过程,得出相应的本体模型,之后选用合适的本体编辑工具(如Protégé等)和本体描述语言(如OWL语言)对本体模型进行形式化,最终得到一个形式化本体。
(7)将构建的本体运用到社区当中,由社区用户通过实践活动对所构建的本体进行评价,发现其中的不足,并及时反馈给知识工程师,在社区用户和知识工程师的协同下对社区本体进行修正和维护。
特别要强调的是,该方法并非是一种纯手工的方法,而是一种半自动的本体构建方法。在该方法中,形式背景的构建、形式背景向概念格的转化、本体模型的构建及其形式化等关键阶段,都是在相关软件的辅助下半自动化实现的,这大大提高了本体构建的效率,减少了本体构建过程中人为因素的影响。
4 基于FCA和Folksonomy的Ontology构建过程
4.1 准备阶段
准备阶段的主要任务是:
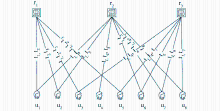
(1)选定需要构建本体的网络社区,并收集其社会化标注系统的数据。给出一个关于社区社会化标注系统的Folksonomy模型,如图2所示:
 | 图2 一个Folksonomy概念模型示例 |
该Folksonomy模型包括三个数据集,用户集U={u1,u2,u3,u4,u5,u6,u7,u8},标签集T={t1,t2,t3,t4,t5,t6,t7,t8},资源集R={r1,r2,r3}。
(2)判定稳态Folksonomy模型。对该数据集进行分析和判断,虽然用户集、标签集和资源集中的元素数量稍少,导致标签的长尾分布和负幂分布不是很凸显,但仍能观察得出,该模型基本满足稳态Folksonomy模型的要求。
(3)得出Folksonomy原始数据集。根据长尾分布,在描述资源r2的标签中,仅用户u8使用标签t8标注资源r2,该标签只是个别用户“自我性”的反映,并不能满足本体“共享概念”的要求,因此在构建本体时剔除该条标记行为,进行低频标签过滤。低频标签过滤的结果是Folksonomy原始数据集。
(4)标签清洗与标签合并。在描述资源r3的标签中,标签t7属拼写有误的标签,例如t6为student,t7为studant,应将t7修正为t6,并进行合并。标签清洗和合并后的结果是Folksonomy精炼数据集。
(5)由于用户集在后续构建本体的过程中作用不大,因此将Folksonomy精炼数据集中的用户集进行屏蔽,仅得出标签集T与资源集R之间的关系,如图3所示:
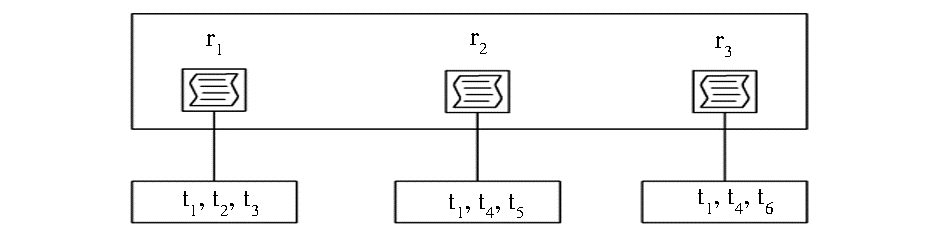 | 图3 Folksonomy中的标签集T与资源集R的关系 |
4.2 形式背景构建阶段
形式背景构建阶段的主要任务是以FCA理论的形式背景定义为依据,将经过准备阶段处理得出的Folksonomy精炼数据集
(1)以标签集T={t1,t2,t3,t4,t5,t6}为概念的属性集,并将各元素分置于二元表的横行上;
(2)以资源集R={r1,r2,r3}为概念的对象集,并将各元素分置于二元表的纵列上;
(3)若标签集元素ti与资源集元素 rj间存在关系y,则在二元表中两元素交汇处标记“×”,最终得出的结果如表1所示:
| 表1 Folksonomy形式背景表 |
4.3 概念格分析阶段
概念格分析阶段的主要任务是:
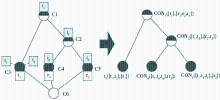
(1)选用造格算法或概念格构造工具(本文使用的概念格构造工具是Concept Expolore1.2),将上阶段得出的Folksonomy形式背景转化成相应的概念格,如图4所示。
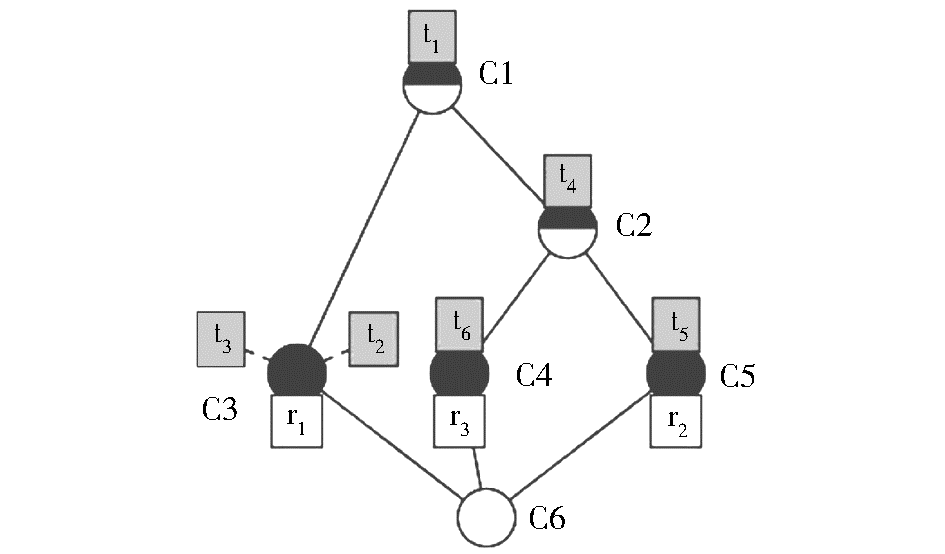 | 图4 由Folksonomy形式背景转化的概念格 |
(2)由知识工程师进行概念格分析。图4表示的概念格中,共形成4层6个节点,每一个节点代表了一个概念,节点的内涵集ti反映概念的属性,节点的外延集rj反映概念的对象。特别强调的是,节点的内涵具有继承其上层节点属性的特性,同时其外延具有涵盖其下层节点所有外延的特性。以节点C2为例,其属性集是T={t1,t4},其中t1继承于其上层节点C1;同时,其对象集为R={r2,r3},其中r2,r3都来自其涵盖的下层节点C4和C5。
(3)根据模型步骤(5)中提出的映射规则,将Folksonomy概念格向本体进行映射,如图5所示:
 | 图5 Folksonomy概念格向本体的映射示意图 |
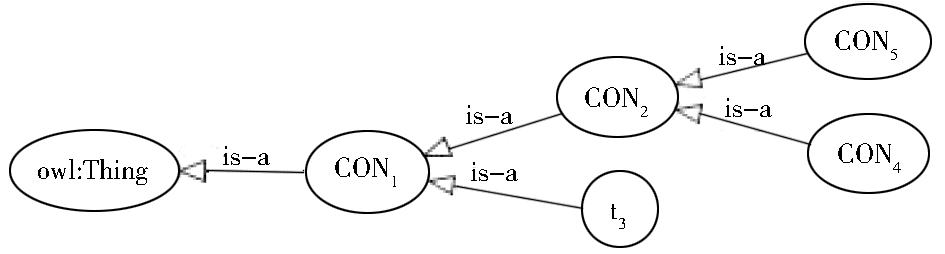
①将顶层节点C1映射为本体的顶层概念Concept-1,由于其内涵中不含能高度概括节点概念的标签名称,因此为其命名为CON1;将节点C1的内涵集T= {t1}映射为概念CON1的属性集;将节点C1的外延集R={r1, r2, r3}映射为概念CON1的实例集,将上述映射结果记为CON1({t1},{r1, r2, r3})。
②同理,使用映射规则,分别将节点C2、C4、C5映射为概念CON2({t1, t4},{r2,r3})、CON4({t1,t4,t6},{r3})和CON5({t1,t4,t5},{r2})。
③将节点C3映射为概念CON1的子概念Concept-3,假定其内涵中存在能高度概括节点概念的标签t3,可用t3来对Concept-3进行命名;将节点C3的内涵集T={t1, t2}映射为概念t3的属性集;将节点C3的外延集R={r1}映射为概念t3的实例集,将上述映射结果记为t3({t1,t2},{r1})。
④空节点C6不做映射。
⑤社区成员对该映射过程做出投票表决。
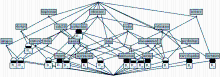
4.4 本体模型及其形式化阶段
根据概念格分析的结果,即可得出以分类结构为主体的本体模型,利用Protégé3.1本体构建辅助工具,构建出可视化的本体模型,如图6所示:
 | 图6 以分类结构为主体的本体模型 |
本体模型构造好之后,可根据不同的需求,选择合适的本体描述语言对本体模型进行形式化,本体描述语言包括RDF、XOL、OIL、DAMl、OWL等。一般地,可选由W3C推荐的OWL语言对本体进行形式化描述,其在万维网上发布和共享本体具有一定的优势。
4.5 本体评价和维护阶段
本体评价和维护是本体构建的最后阶段,也是时间周期最长的一个重要阶段。本体构建完成后,将其应用于网络社区中去解决诸如语义扩展、智能导航、知识检索等实际问题,才是本体构建的真正目的。本体构建的成功与否,必须在投入使用后,由用户,也就是社区成员来进行评价和反馈。社区本体维护的内容包括改正性维护、完善性维护、适应性维护和预防性维护等。知识工程师应充分考虑社区成员的评价结果,吸纳社区成员对本体修改的意见,对本体模型进行修正和完善,使得本体更具实用性。
5 实验结果及讨论
选取网站Delicious美味书签Delicious开源数据片段.[2011-11-29].http://www.delicious.com/.作为本方法实验的对象。
(1)“美味书签网”的知识组织模式分为两类:Recent Links和Featured Links,其中前者注重于即时性,反映的是最近几天的书签标记情况,后者则反映很长一段时间内用户使用标签标记资源的热点,相比之下,后者符合本方法“语义浮出”和“稳态Folksonomy”的要求,因而本文决定从Featured Links中截取出一段开源数据(前25条记录中的符合条件的16条记录,每条记录代表一个资源,见表2)作为本方法实验的样本,如图7所示:
 | 图7 Featured Links中的开源数据片段 |
| 表2 Featured Links开源数据16条记录名称表 |
(2)对上述16条记录分别进行标签合并、标签清洗以及低频标签过滤,得到相应的Folksonomy精炼数据集,以备构建形式背景。以记录1为例,图8为其Folksonomy初始数据集,其资源集为{Becoming Human http://www.becominghuman.org/},用户集为{yunzhong, julianadaluz, jamca, sforeror,koditschek, davidmpratt, awbruss, elpato, damsel, bacharelato2009, rsmitchell, yonita, emily107,……},标签集为{history, science, anthropology, anthro, antropoloxía, antropología, evolution,evo,evolución,evolução,biology,human,reference,documentary,video,education,life,tools,paleontoloxía,historia,vídeo,antropology,scienze,antropologia,interactive,bones,Africa,OutOfAfrica,soundbytes,Enciclopedias,prehistory,TIC,paleoantropologia,pré-história,archaeology,imported,earlyhumans,Greenfield-Web2,Civilizations,prehistoria}。
 | 图8 记录1的标记详情片段 |
合并(如anthropology, anthro, antropoloxía, antropología并为anthropology)、清洗(如evo规范为evolution)、去除低频(如TIC, Africa, bones等)后的标签集为{history, science, reference, documentary, video, education}。
(3)根据精炼数据集构建形式背景,如图9所示:
 | 图9 Delicious形式背景(部分) |
(4)根据形式背景映射出相应的概念格,结果如图10所示。
 | 图10 Delicious形式背景转化的概念格 |
(5)根据概念格分析的结果,结合Protégé本体构建工具,得出“美味书签”社区本体部分代码如下:
< ?xml version="1.0"? >
< rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:owl="http://www.w3.org/2002/07/owl#"
xmlns:xsd="http://www.w3.org/2001/XMLSchema#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns="http://www.owl-ontologies.com/unnamed.owl#"
xml:base="http://www.owl-ontologies.com/unnamed.owl" >
< owl:Ontology rdf:about=""/ >
< owl:Class rdf:ID="education-technology-innovation" >
< rdfs:subClassOf >
< owl:Class rdf:ID="education_technology"/ >
< /rdfs:subClassOf >
< /owl:Class >
< owl:Class rdf:ID="web2.0"/ >
< rdfs:subClassOf >
< owl:Class rdf:ID="inspiration"/ >
< /rdfs:subClassOf >
< /owl:Class >
< owl:Class rdf:ID="image"/ >
< owl:Class rdf:ID="science"/ >
< owl:Class rdf:ID="video" />
< owl:Class rdf:ID="reference"/ >
< owl:Class rdf:about="#education_technology" >
< rdfs:subClassOf rdf:resource="#education"/ >
< /owl:Class >
< owl:ObjectProperty rdf:ID="innovation" >
< rdfs:domain rdf:resource="#education-technology-innovation"/ >
< /owl:ObjectProperty >
< owl:ObjectProperty rdf:ID="technology" >
< rdfs:domain rdf:resource="#education_technology"/ >
< rdf:type rdf:resource="http://www.w3.org/2002/07/owl#TransitiveProperty"/ >
< /owl:ObjectProperty >
< inspiration rdf:ID="R18"/ >
< reference rdf:ID="R17" >
< rdf:type rdf:resource="#inspiration"/ >
< /reference >
< inspiration rdf:ID="R16"/ >
< reference rdf:ID="R11"/ >
< education_technology rdf:ID="R22"/ >
< reference rdf:ID="R24" >
< rdf:type rdf:resource="#inspiration"/ >
< /reference >
< science rdf:ID="R20" >
< rdf:type rdf:resource="#reference"/ >
< /science >
< reference rdf:ID="R6" >
< rdf:type rdf:resource="#science"/ >
< /reference >
< education-technology-innovation rdf:ID="R4"/ >
< reference rdf:ID="R5"/ >
< reference rdf:ID="R2"/ >
< science rdf:ID="R3"/ >
< reference rdf:ID="R1" >
< rdf:type rdf:resource="#science"/ >
< /reference >
< /rdf:RDF >
从整个测试过程可以看出,本文提出的方法步骤规范、流程详细、操作简易,所构建的社区本体反映和揭示了丰富的“概念-属性-实例”关系,满足本体“共享的概念模型的形式化的规范说明”的具体要求,充分反映了本体的“概念化”、“明确”、“形式化”和“共享”的4个典型特征,且具有如下优点:
(1)提出了基于FCA和Folksonomy的Ontology构建方法的模型,并给出了规范化和详尽的操作流程,将当前学界在该问题上仅形成的“一般性构建思路”深化和发展为一种具体的有较高的理论性和很强的操作性的方法。
(2)运用FCA,通过形式背景自动转化为概念格的过程,既实现了标签的聚类,又完成了标签语义关系获取的环节,较之用统计方法实现标签聚类和语义关系获取,既简洁又有效,既准确又自动,因而具有非常大的优越性。
(3)以概念格的可视化为前提,针对Folksonomy如何过渡为Ontology,提出了一套将Folksonomy的“标签-资源”映射为本体的“概念-属性-实例”的详细转化规则,并采用了网络社区成员投票机制来协助该过程的完成,集合了群体的智慧。这种转化规则的建立,重视从“概念-属性-实例”等本体元素去全面地揭示本体概念间关系、概念属性关系、概念实例关系和属性间关系等,改善了当前学界仅将标签转化为本体概念,不重视其余本体元素和本体语义关系的缺陷。
当然,本方法也存在一定的局限性,在处理将标签映射为本体的概念或属性时,没有建立一套自动化的判别机制来自动识别某个标签应该映射为概念或映射为概念的属性。本方法中这一过程需要由网络社区成员集体通过投票的方式判定,虽然集合了群体的智慧,但一定程度上削弱了本体构建过程的自动化程度,影响了本体构建的效率。
6 结 语
本文着眼于从网络社区中依据Folksonomy数据半自动地生成本体的问题,在总结这些问题的基础上,利用FCA集数据分析和数据建模为一体的功能,提出了一种基于FCA和Folksonomy的社区本体构建方法,在一定程度上解决了当前方法存在的局限性,具有创新性和启发性。该新方法从理论上丰富和完善了本体构建的方法体系,拓宽了网络社区本体构建的思路,形成了一种简洁、科学、易用的网络社区本体构建方法,具有重要的理论意义;从实践上指导了Web2.0下社会化标注系统(如博客世界、Delicious、Flickr)中的社区本体构建,有效地提高了Web2.0下网络社区的语义表达能力和知识管理水平,具有重要的实践价值。限于时间和精力,本文只研究了单个网络社区中基于FCA和Folksonomy的本体构建方法,而跨社区(特指相似社区)的基于FCA和Folksonomy的本体构建、本体映射、本体桥接和本体合并等方法是后续的研究方向。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|