


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于串频统计的汉语和孟加拉语专有名词识别*
引用本文
柯修, 王惠临, 于薇. 基于串频统计的汉语和孟加拉语专有名词识别* . 现代图书情报技术, 2011, 27(12): 31-38
Kishore Biswas, Wang Huilin, Yu Wei. Chinese and Bengali Proper Noun Recognition Based on String Frequency Statistics Model. 现代图书情报技术, 2011, 27(12): 31-38
Permissions
Kishore Biswas, Wang Huilin, Yu Wei. Chinese and Bengali Proper Noun Recognition Based on String Frequency Statistics Model. 现代图书情报技术, 2011, 27(12): 31-38
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于串频统计的汉语和孟加拉语专有名词识别*
摘要
基于Nagao串频统计算法实现汉语和孟加拉语专有名词的识别。提取未经过词性标注的中文和孟加拉语语料中的n元串,使用改进的SSR算法过滤多余子串,利用字串的相邻字信息计算所有n元串成为专有名词的概率,并据此筛选专有名词。最后,实现基于串频统计的跨语言专有名词识别系统。实验表明,系统能够从输入的生语料中有效地识别出人名、地名、团体机构名等。
关键词:
专有名词识别; 串频统计; Nagao算法; SSR 算法
中图分类号:TP391
Chinese and Bengali Proper Noun Recognition Based on String Frequency Statistics Model
Abstract
This paper implements String Frequency Statistics Algorithm proposed by Nagao to build Proper Noun Recognition (PNR) system for Chinese and Bengali languages. First, n-grams are extracted from untagged input corpus,then they are filtered to get rid of redundant sub-strings, using SSR algorithm. Finally, this multilingual PNR system assigns each n-gram a probability of being a proper noun based on the information of their neighboring words and outputs results according to their probability score. The test results show that this system can effectively recognize name of people, places, organizations or institutions from the input text.
Keyword:
Proper noun recognition; String statistics; Nagao algorithm; SSR algorithm
1 引 言
专有名词识别是自然语言处理领域的一个热门研究课题。互联网信息资源、报纸、杂志等文本中不断出现大量专有名词,它们都指向具体实体且包含比较精确的概念。这些专有名词中有很大部分是新词语,无法收集到一部有限的词典里。专有名词中很多是由现有的基本词语组成,所以对它们进行普通分词会引入不正确的分词结果。虽然大部分西方语言(包括南亚地区语类、孟加拉语)中不存在词的切分问题,但也同样需要识别多词组成的专有名词或短语。而且,很多专有名词是外来语的直接或间接翻译。这些都给专有名词的识别带来了一定的困难。 本文研究汉语和孟加拉语专有名词的识别。目前对汉语的专有名词识别的工作虽有很多[ 1, 2, 3, 4, 5, 6, 7, 8, 9],但是对南亚地区大语种孟加拉语还尚未涉及。因此,本文着眼于研究汉语和孟加拉语的专有名词识别,以Nagao串频统计算法为基础,提取n元串(n-gram),然后进行子串过滤并计算n元串成为专有名词的概率,最后筛选和识别专有名词。
2 国内外研究现状
目前对东方语言(如:汉语、日语、韩语),西方语言(如:西班牙语、英语等)专有名词识别有较多的研究工作[ 10, 11, 12]。但南亚地区的大语种(如:孟加拉语、印度语等)的专有名词自动识别方面的研究还没有。目前,专有名词识别方法可以分为三大类:基于规则[ 6, 7, 8, 9]、基于统计[ 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]和两种策略混合[ 25, 26]的方法。
(1) 基于规则的方法:首先需要人工发现文本中出现的专有名词的特征,然后根据这些特征制定在文本中查找专有名词的规则,并构建规则库,最后设计算法按这些规则从文本中寻找专有名词。如:基于转换的错误驱动的地名识别方法[ 9]。每种语言的内部结构不同,因此识别规则也不同。而且,除了已有的专有名词外,每天还会不断出现新的专有名词。因此,构建出一个能覆盖所有类别的专有名词的规则库是不现实的。基于规则的方法在小规模的语料中能够获得97%的高准确率[ 7]。
(2) 基于统计的方法:通过统计真实语料中重复出现频率高的字串来识别专有名词。因为专有名词的很大一部分是新词,识别专有名词时需要考虑一些新词的特征。现有新词识别特征中比较常用的有:成词率(In-word Probability)、构词模式(In-word Position)、词频 (Word Frequency)、互信息 (Mutual Information)等[ 21]。文献[13]使用基于角色标注的专有名词识别方法,识别过程中使用Viterbi算法对分词结果进行角色标注,然后进行模式最大匹配,从而实现中文人名识别。文献[16]使用基于决策树的方法识别专有名词,把专有名词识别问题看成一种分类问题,从语料库中统计出几类知识,把它们作为属性建立训练集,然后生成决策树。此外,基于隐马尔科夫模型 (Hidden Markov Models,HMM)[ 13, 14]、最大熵 (Maximum Entropy,ME)[ 15]、小句相似度计算[ 16]和支持向量机(Support Vector Machine, SVM)[ 17, 18]的专有名词识别、基于CRF模型的中文化学物质名称识别研究[ 19]也是基于统计的方法。
(3)以上两种策略混合的方法:目前常用的汉语专有名词识别系统采用的是基于统计和规则混合的方法。例如:孙茂松等[ 22]的中文姓名自动辨识系统、王振华等[ 23]的结合决策树方法的中文姓名识别、谭红叶等[ 24]的中国地名自动识别系统、张辉等[ 25]的中国组织机构名自动识别系统、郑家恒等[ 26]的基于HMM的中国组织机构名自动识别系统、胡乃全等[ 27]的混合的汉语基本名词短语识别方法。这类系统得到了比较满意的召回率和准确率。
孟加拉语方面,有基于HMM 的孟加拉语命名实体识别方面的研究[ 28, 29]。但是,对于孟加拉语专有名词识别的研究还没有。
由于不同语言内部规则不同,一种语言的专有名词识别系统不能有效地识别另一种语言的专有名词。但是,跨语种的专有名词识别方面,尚没有相关研究。
本文提出基于串频统计的跨语言专有名词识别系统。孟加拉语方面,尝试利用语料中词语的词频、搭配、前缀、后缀、前词、后词等特征识别人名、地名、团体机构名。汉语方面,已有的汉语专有名词识别系统中大多数只支持GB或BIG5编码的汉语语料,这样的设置导致对汉语文本中出现的其他语言的处理不太理想。因此,本文采用UTF-8编码,使系统可以有效地处理不同语言的文本。本文所识别的专有名词包括:人名、地名、团体机构名和其他类专有名词,分别用nr,ns,nt和nz表示。
3 汉语和孟加拉语专有名词的特征
东方语言(如:汉语、日语)中的分词问题对识别专有名词及其词性具有较大的挑战。识别语素变化大的语言(如:孟加拉语)中出现的专有名词也有一定的难度。
(1)无首字母大写的特征;
(2)词与词之间没有空格,无法直接切词;
(3)不规则的新名词;
(4)词的缩写形式多,如:北大表示北京大学;
(5)低频专有名词;
(6)前缀的不确定性,比如:在字串“在北京”和“在心理”中发现前缀“在”不能确定后字串为专有名词;
(7)无限长度的汉语地名:汉语地名长度没有一定的限制,一个长的地名可以包含另一个地名,比如: “北京市海淀区中关村南大街”中“北京”、“海淀区”、“海淀区南大街”都是一个独立的地名,确定整个“北京市海淀区中关村南大街”也是地名,因此需要采用不同策略。
孟加拉语专有名词识别的难点除了有以上第(2)和第(7)项提到的切分和无限长度的地名问题外,在识别孟加拉语专有名词中还存在其他的难点[ 28, 29]:
(1)孟加拉语专有名词的前缀以语素的形式和词语本身构成一个词,很难把它们分开。
(2)很多时候孟加拉语的专有名词不带特定后缀,使得识别该类词更加困难,比如:“达卡市” 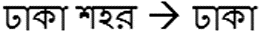
(3)在孟加拉语中外来语(如:来自英语)越来越多。因此人们在对话或书写中不对它们进行翻译而是直接用原本的英语单词或用孟加拉字母表达出来。因此,书写的外国人名是各种各样的,不能用孟加拉人所用的有限的姓名词来判断外国人名。
(4)孟加拉语的专有名词后缀和后词会因为句子中的时态、人称、名词数目等的变动而变化,这对保留后缀表带来一定的困难。
但是,专有名词的有些性质对识别工作还是有益的。本文将这些性质称为专有名词的特征。
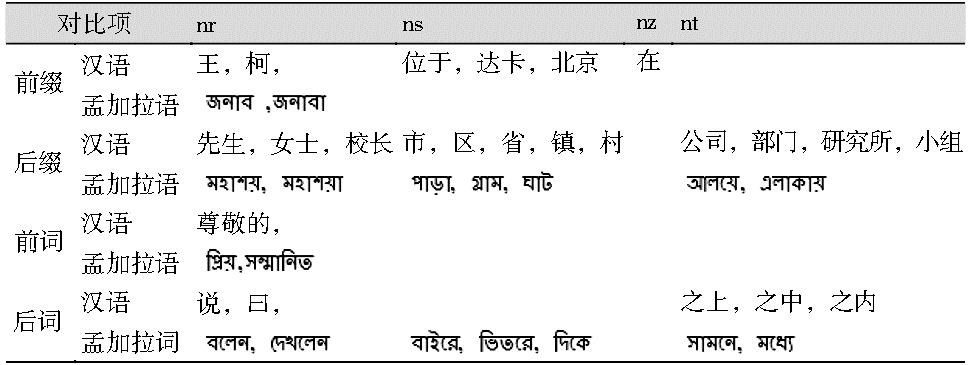
(1)语料中出现的大多数专有名词后面带有明显的后缀 (Suffix) 或后词 (After Word)。例如:安徽省、雷塔尼亚胡说,这里“省”是一个地方名的后缀,“说”作为人名的后词。
(2)汉语地名前很多时候存在前缀,如:位于南亚、在北京大学等。
(3)汉语语料中出现一个新的专有名词时,它的出现频率常常比较高。
(4)大部分的中国人名前带有中国人特定的姓氏。
(5)专有名词后面的后词一般也比较明显,只有少数几个停用词和动词,如:的、是、给、说、之间等。
(1)孟加拉语语料中出现的人名一般都带有比较明显的前缀。比如: 
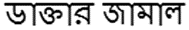

(2)有时候出现新的专有名词保持原语言(如英语)的形式。如: 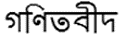
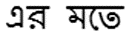
(3)孟加拉语专有名词后面的后词有 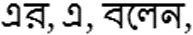
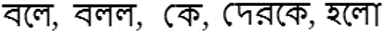
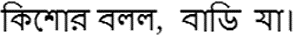
4 基于串频统计的专有名词识别方法
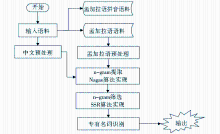
本文采用基于串频统计的方法,根据专有名词的两个特征:具有重复出现的规律和它们前后出现的特征词或子串(前缀、后缀、前词、后词)来识别专有名词,识别方法如图1所示:
 | 图1 基于串频统计的专有名词识别方法流程图 |
使用Nagao串频统计算法[ 30]提取n-元字串(主串),然后用改进的SSR算法(Statistical Substring Reduction)[ 31]过滤同频率多余的子串并筛选有意义的字串,以下称为“候选字串/候选词(Candidate String)”。发现候选字串相邻的特征词并按照这些信息赋给候选词一个能成为专有名词的概率值,最后按概率值排序候选词并输出。
4.1 用Nagao算法提取n元字串
识别专有名词的前提是从语料中提取所有可能的n元字串(n-gram)。为了识别所有可能的专有名词,本文从生语料中提取n为10的字串以保证能识别比较长的专有名词。如:“中国人民共和国,n=7”。 Nagao等提出的算法[ 30]能够在比较低的空间复杂度和O(nLogn)的时间复杂度下处理这些问题。因此,本文采用Nagao算法来提取n元字串。
4.2 用改进的SSR算法过滤多余子串
用Nagao算法提取得到的n-gram主串中会包含大量多余的子串,例如:“孟加拉人民共和国(主串)”,获得的子串中会有“孟加拉人民共和”和“拉人民共”这样无意义的子串。这些多余子串的过滤可以用Lv等[ 31]提出的改进的统计约减算法(Improved Statistical Substring Reduction Algorithm in Linier Time)来进行。
4.3 计算候选词成为专有名词的概率
假设在一篇文章中出现的任何一个n-gram能成为专有名词的概率P(Xz)是一个大于零的值。北京大学计算语言学研究所制定的106种汉语词语中专有名词只占4种(4/106=0.0377358)。因此假设汉语语料Ci中 
| 表1 特定词(前缀、后缀、前词、后词)表 |
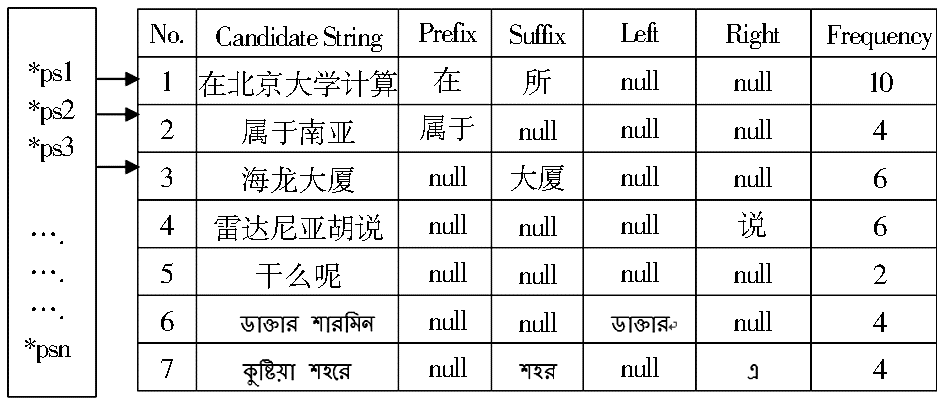
从一个候选词是否含有专有名词这个角度来考虑语料中每一个候选词,有以下4种状态:
(1)候选词前后分别带有特征词(特定前缀、后缀),如:在海淀图书城、位于南非地区。
(2)候选词后面只有特定后缀,如:雾灵山、新东方培训部。
(3)候选词前面只有特定前缀,如:住普瑞楼、属于肯德基。
(4)候选词前后无特定前缀和后缀,此类候选词最多,但通过判断它们的“前词”或“后词”也有可能识别专有名词。
候选词的这4种状态都有可能带“前词”或“后词”。比如:马德里说,在北京五环之内的房子很贵。这里面的“说”作为“在北京五环”的前词而“之内”作为后词。扫描候选词的相邻特征词算法如下:
输入: 经过SSR模块输出的候选词 (candidate strings P,length(P)>=2)
Sort candidate strings according to their last character/word. //候选词按最后一个字排序
while candidate strings P != NULL
Find predefined suffix in P[i] with highest priority of longest suffix //查找后缀
if suffix[i] != NULL
string_before_suffix = P[i] - suffix[i];
else sting_before_suffix[i] = P[i];
Sort candidate strings according to their first character/word //候选词按第一个字排序
while candidate strings P ! = NULL
Find predefined prefix in P[i] with highest priority of longest prefix //查找前缀
if prefix[i] != NULL
string_after_prefix[i] = P[i] - prefix[i]
else string_after_prefix[i] = P[i]
输出: final_candidate_strings = P[i]-suffix[i]-prefix[i], suffix[i], prefix[i]
该算法扫描候选词的环境并更新候选词的状态,如图2和图3所示:
 | 图2 扫描候选词的后缀 |
 | 图3 扫描候选词的前缀 |
经过算法1得到候选词相邻特征词的状态,如表2所示:
| 表2 候选词的状态表 |
对候选词的4种状态计算其作为专有名词概率的方法分别是:
(1)候选词带有特定前缀和特定后缀
如果候选词同时带有特定前缀和特定后缀而且它们是同类的,那么该类候选词成为专有名词的概率最大,如下所示:
P(Xz) = 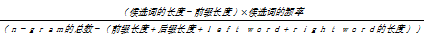
(1)
如果没有前词和后词,那么式(1)中left word 和right word的值为0。
(2)候选词只有特定后缀
只带特定后缀的候选词是语料中出现最多的一种专有名词,如下所示:
P (Xz) =
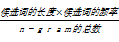 | (2) |
式(2)表示一个带有后缀的候选词的频率越高,它的成词概率越大。候选词长度越大,成词概率也越大。因此,一个字长度大的串出现很多次加上后面带有特定后缀,那么它很有可能是一个专有名词。
(3)候选词只有特定前缀
只有前缀信息不能完全确定一个n-gram是否为专有名词,其类型也无法确定。所以本文为此类候选词分配一个比前两种候选词小的概率值,如下所示:
P (Xz)= 
(3)
式(2)中的“0.0377”是用来平滑语料中出现带前缀的非专有名词和带前缀的专有名词的概率值。
(4)候选词没有特定前缀或者后缀
没有前缀和后缀的n-gram在语料中所占的比例最大,而且很难识别这类专有名词。本文利用这类候选词的前词和后词来判断它是否是专有名词,如下所示:
P (Xz)= 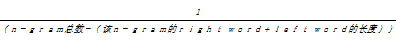
(4)
式(4)中的“0.0377”是用来平滑语料中出现带前缀的非专有名词和带前缀的专有名词的概率值。
识别孟加拉语的专有名词时候,需要用“词”单位代替汉语的“字”单位。
5 基于串频统计的跨语言专有名词识别系统构建
本文构建的系统由4个模块组成,分别是:语言的预处理(中文与孟加拉文分别处理)模块,Nagao算法提取n-gram模块,SSR算法实现n-gram 筛选、输出候选词模块和计算候选词的成名词概率并排序输出模块。系统结构如图4所示。
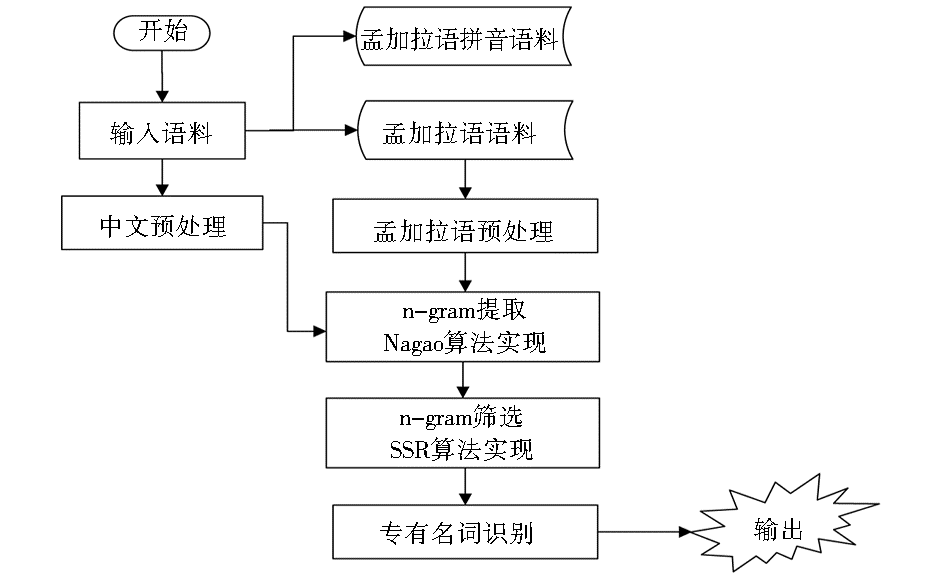 | 图4 系统结构图 |
5.1 语料的预处理
本系统采用线性数组来存储字串。同时对原文本进行预处理:
(1)记录文本大小、短文、句子、标点符号、单字/词和空格的数量,分别是:text_size, paragraph_number, sentence_number, char_number和punc_number。
(2)输入语料中的“”,‘’等符号之间除“_”,“-”以外不再包含其他标点符号的字符串视为一个独立的字串单位,不再把它分成子串。因为这样的字符串往往是特定指出的词语、短语或者句子。本文把“”,‘’,(),{},[]等符号中间的字符串叫作Quoted String。如:我们说的那个地方就叫做“小印度大街”。这些Quoted String不经过SSR算法过滤多余子串的步骤,直接进入概率大小计算的步骤。
(3)将所有保留词(Stop Word,如:的、们等)、日期、货币等符号开头的n-gram删除,这类的n-gram一般不是专有名词。
(4)一种语言L1的语料C1中单独出现另一种语言L2的字符X (L2),或者X (L1) 和X (L2) 混合出现时,本文不进行区分。比如:“去卡拉OK唱歌”,“我拿到MIT的Offer了”。由于本系统支持UTF-8编码,因此统一统计不同语言字串的频率。
(5)所有的非UTF-8编码的语料首先转换为UTF-8编码,然后再开始预处理。
(6)目前孟加拉语的标准语料还不够多。在Web上的孟加拉语文本的编码有很多种,而且这些文本中存在存储格式和字体的问题。孟加拉文的词和词之间用单个空格来区分,所以进行孟加拉语语料的预处理时以词为最小单位计算。
6 实验及结果分析
实验收集了不同来源、大小和不同领域的语料。汉语语料主要是2000年1月到10月的《人民日报》和抓取自百度新闻的Web新闻。孟加拉语语料主要来自孟加拉国著名的报纸“Ittefaq”和“Vorer kagoj”,以及抓取自Bangla News的Web新闻、孟加拉语论坛网页等内容。其中,单篇最大语料的大小为1 306kb,包含462 209个字,39 290个标点符号和31 576个n元串。实验比较5种不同领域(娱乐、体育、IT、国际、商务)中出现汉语和孟加拉语专有名词的情况。
(1)对汉语语料测试
①按不同大小的语料进行测试,比较汉语专有名词识别的召回率和准确率。本文分别用10kb、100kb、1Mb、10Mb、 100Mb和 1Gb的标准汉语语料(人民日报)进行测试。归纳语料大小对专有名词准确率的影响。
②按不同领域的语料进行测试,比较各个领域的语料中专有名词识别的召回率和准确率。这些语料的来源是大量Web新闻和该领域的网页内容。总结出专有名词使用较多的领域。
(2)对孟加拉语语料测试
①孟加拉语语料也按不同大小进行测试,比较孟加拉语专有名词识别的召回率和准确率。由于缺乏比较完整和标准的孟加拉语语料,无法采用大规模的语料,因此,分别用10kb、100kb、1Mb、10Mb的孟加拉语语料。该语料的来源是Web新闻和孟加拉文不同网页(如:Bangla News)的内容。
②对孟加拉语的不同领域的语料进行测试,比较各个领域的语料中专有名词识别的召回率和准确率。这些语料的来源也是大量Web新闻和该领域的网页内容。归纳专有名词出现相对较多的领域。
6.1 实验结果
本文的测评是人工先识别所有正确的专有名词,然后再计算召回率、准确率等值。实验结果如表3和表4所示:
| 表3 在不同大小的汉语语料中专有名词识别的召回率、准确率和F-值 |
| 表4 在不同大小的孟加拉语语料中专有名词识别的召回率、准确率和F-值 |
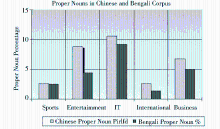
不同领域相关语料中专有名词的出现频率如图7所示。实验结果表明在娱乐和IT领域中出现的专有名词最多。
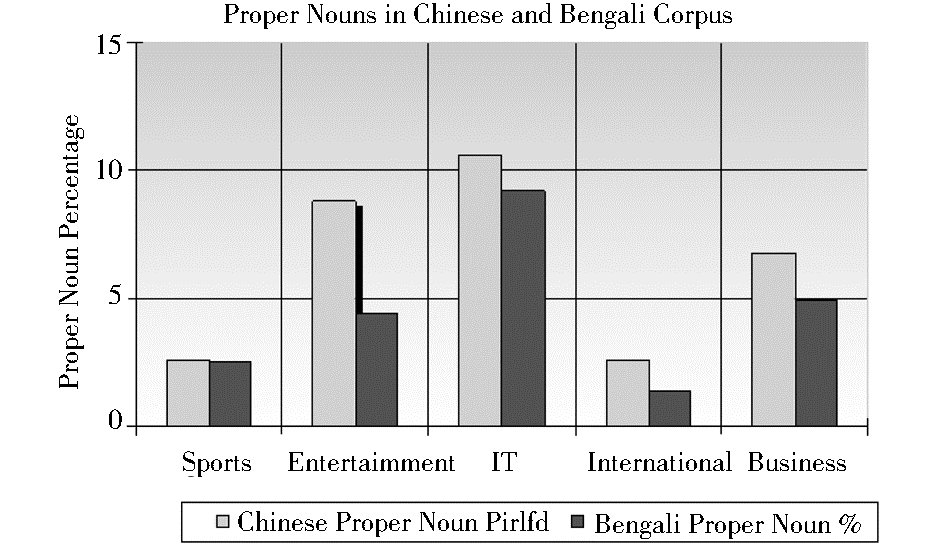 | 图7 不同领域的语料中出现孟加拉语和汉语专有名词的比例 |
实验过程中发现:
(1)利用一个候选词的前缀信息识别专有名词,准确率会降低,但召回率会提高。
(2)如果一个专有名词前面或中间带有特定后缀,那么识别该类专有名词会有误。比如:专有名词“红楼梦”因为有特定后缀“楼”,所以如果“红楼梦”左右没有其他的前缀或后缀,那么系统会把“红楼”识别为专有名词。
本系统还存在以下不足之处:
(1)没有用规则库;
(2)因为专有名词的相邻特定词也可以作为非专有名词的相邻词(如:在心里、在那里、小区等),语料大小上升时识别专有名词准确率会下降。
7 结 语
本文使用基于串频统计的方法对中文和孟加拉语的专有名词进行识别。笔者所做的工作对汉语和孟加拉语之间的机器翻译、信息检索及其他自然语言处理有一定的参考价值。另外,根据相应的语言修改候选字串相邻词的特征后,该系统可以对任何自然语言进行专有名词识别。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|