
{kind=link}
{kind=link}
基于聚类算法的本体层次关系获取研究*
引用本文
谷俊, 朱紫阳. 基于聚类算法的本体层次关系获取研究* . 现代图书情报技术, 2011, 27(12): 46-51
Gu Jun, Zhu Ziyang. Study on Ontology Hierarchy Relation Induction on Clustering Algorithm. 现代图书情报技术, 2011, 27(12): 46-51
Permissions
Gu Jun, Zhu Ziyang. Study on Ontology Hierarchy Relation Induction on Clustering Algorithm. 现代图书情报技术, 2011, 27(12): 46-51
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于聚类算法的本体层次关系获取研究*
摘要
提出利用蚁群聚类方法进行初始聚类,通过K-means聚类算法对初始聚类的结果进一步分层聚类,并结合术语综合相似度计算的方式提取每个类的标签,从而完成术语层次关系的构建。最后抽取部分实验结果,由领域专家对其进行评价,并对结果进行分析。
关键词:
本体; 语义层次; 蚁群算法; 聚类
中图分类号:TP391
Study on Ontology Hierarchy Relation Induction on Clustering Algorithm
Abstract
This paper proposes a method,which clusters the initial terms collection by ant colony algorithm and clusters the results hierarchy by K-means algorithm, then gets the labels of classes using the comprehensive similarity calculation, finishes the term hierarchy relation’s structure at last. Parts of experimental results are appraised and analyzed by domain experts.
Keyword:
Ontology; Semantic hierarchy; Ant colony algorithm; Clustering
1 引 言
本体是一种有效的知识组织方式,被纳入语义网体系,因其具有明确性、形式性和共享性三大特征,可以在网络资源上融入计算机可以理解的信息,达到资源的语义理解,是语义层面上网络信息的交换与共享的基础[ 1]。它将Web资源通过语义的方式组织起来,使得互联网的资源获取更加便捷,是在互联网上提供高效服务的先决条件。目前,本体在人工智能、信息检索、知识工程、数据挖掘等学科领域中被广泛研究和应用[ 2]。
在本体构建过程中,术语间层次关系的建立,影响到本体的最终质量。本文尝试以聚类方法为基础,得到测试术语集的层次关系,并抽取每个类中的标签,最终完成本体层次关系的获取。
2 相关研究工作
目前,构建本体层次关系的方法常用的有基于词典的方法、基于词汇-句法模式的方法、基于Harris假设的方法、基于关联规则的方法和基于语言学的方法。聚类方法是基于Harris假设方法的一种,Harris假设又称为分布式假设,最早由Harris[ 3]提出,表述为如果两个词的上下文语境相似,那么这两个词也是相似的。基于Harris假设,衍生出基于层次聚类的方法[ 4, 5]和基于形式概念分析的方法[ 6]两种主要聚类方法,而国内外的学者也不断尝试利用上述方法对聚类算法进行调整和改进,以满足实际应用的需要。
马辉民等[ 7]讨论了文本表示方法中最常用到的向量空间模型,分析了其优势和不足,并基于一个文本处理实验,对VSM模型从可实现角度给出改进建议。乐兵等[ 8]提出了基于遗传算法的动态文本聚类方法,采用二进制编码方式对聚类中心进行编码,类内中的点与其类中心的欧氏距离作为适应度函数,通过遗传算子的操作对类中心进行逐步迭代,直至适应度函数收敛,得到使聚类划分效果最好的聚类中心。龚静等[ 9]提出了K-means聚类算法中选取初始聚类中心及处理孤立点的新方法,改进了K-means算法对初始聚类中心和孤立点文本很敏感的不足之处,并将改进后的算法应用于中文文本聚类中。 王刚等[ 10]针对文本聚类缺少涉及概念的内涵及概念间的联系,提出了一种基于本体相似度计算的文本聚类算法TCBO(Text Clustering Based on Ontology)。该算法把文档用本体来刻画,以便描述概念的内涵及概念间的联系。同时,他们还设计和改进了文本相似度计算算法,应用本体的语义相似度来度量文档间相近程度,设计了具体的根据相似度进行文本聚类的算法。温春等[ 11]通过分析已有的中文本体概念层次获取方法的特点和不足,提出了一种利用度属性获取概念层次的方法。季培培等[ 12]针对如何获取术语语义层次内部结构的关键问题,构建术语语义层次获取流程,采用多重聚类方法获取层次关系,结合综合相似度计算方法提取层次内部的聚类标签。余永红等[ 13]应用遗传算法进行全局和快速的文本特征项选择以实现降维处理,引入概率匿名思想,根据文本中不同特征项权重的组合,基于动态规划设计一个优化的多项式时间聚类算法。
在聚类方法中,K-means聚类算法较为成熟,运用也非常广泛,但是由于其初始类中心点是随机确定的,最终往往导致局部最优的聚类结果,而不是全局最优。因此本文尝试对K-means算法进行改进,利用蚁群算法对术语集合进行初步聚类,对每个划分出来的簇进行局部K-means聚类,并利用术语综合相似度计算的方法得到每个簇的标签,从而完成本体层次关系的构建。
3 方法描述
在先前的工作中[ 14],笔者对专利文献中的术语进行了抽取,方法为在ICTCLAS词典分词的基础上,利用串频最大匹配算法从中文专利文本中抽取候选概念,再利用TFIDF算法得到相关特征项的权重,经过筛选后得到最终概念术语。
针对上述术语,首先为术语建立向量空间模型,计算术语间的语义相似度,再利用蚁群算法,对术语集合进行第一次聚类计算,利用蚁群算法的强鲁棒性和优良的分布式计算能力获取若干个初始类,确定术语集合的聚类中心点,最后采用自上而下的多重K-means聚类算法得到术语层次关系。在获取聚类标签时,使用术语间综合语义相似度的方法进行类标签的标记,即综合相似度最大的术语被提取出来作为当前类的类标签,并将剩余的术语提取出来进行下一层聚类,直到满足聚类的层次要求时停止。获取流程如图1所示:
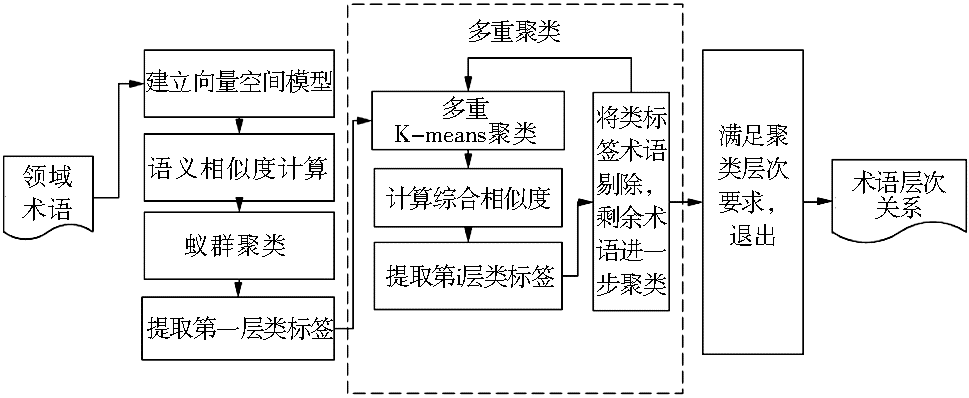 | 图1 本体术语层次关系获取流程 |
3.1 数据预处理
在进行聚类算法之前,需要对领域数据集合进行预处理,包括术语向量空间模型的建立和术语间语义相似度的计算,具体转换步骤如下:
(1)使用TFIDF方法为术语集合构建VSM模型。将文档集作为术语的向量空间,建立术语×文档的二维矩阵,矩阵中行表示文档,列表示术语,生成形如 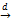
wij=tfij×log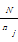 | (1) |
其中,tfij表示tj在文档Di中的频数,N表示总文档数,nj表示出现特征项tfj的文档数。
(2)得到术语集合的VSM模型后,利用余弦系数计算每个术语之间的语义相似度,公式如下[ 16]:
sim(ti,tj)=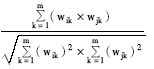 | (2) |
其中,wik为术语ti对应向量中第k维的值。
3.2 改进的蚁群聚类
蚁群算法(Ant Colony Algorithm,ACA)是一种通过模拟自然界蚂蚁搜索路径的行为而形成的新型模拟算法,最早由Dorigo等[ 17]提出。相对于传统的K-means聚类,蚁群聚类具有分布式和强鲁棒性等特点。蚁群算法在聚类开始时不必设置聚类的数量,可以自己完成聚类;具有群集算法的优势——并行性、健壮性,不会因为某些蚂蚁的停滞或者错误行为而影响整体聚类效果;可以把聚类过程投射到一个二维平面上进行,增加了聚类结果表示的可视性。蚁群算法主要通过平均相似性和概率转换函数来辅助实现。
(1)平均相似性[ 18]
蚂蚁在某个坐标中“拾起”、“移动”或者“放下”物体的概率是由该对象与周围对象的平均相似性决定的。术语ti平均相似性的定义如下[ 19]:
f(ti)=max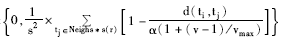 | (3) |
其中,α为相似性参数,决定了f(ti)的收敛速度和聚类数目,出于均衡考虑,本文设置α=0.5;v表示蚂蚁移动的速度,vmax为蚂蚁移动的最大速度,为了减小运算复杂程度,v设置为1,表示蚂蚁在平面中每次移动1格;Neighs*s(r)表示坐标r周围的以s为边长的正方形区域,s设定为3;d(ti,tj)表示术语ti和tj在空间中的距离,可由式(2)计算得到。
(2)概率转换函数
概率转换函数由平均相似性f(ti)得到,如果数据对象与周围对象的平均相似性较小,那么蚂蚁“拾起”的概率就越大;反之则“放下”的概率就越大。本文选择了Sigmoid函数作为概率转换函数,相对于其他函数,该函数具有更快的收敛性[ 20]。由此,得到无负载蚂蚁“拾起”对象的概率和有负载蚂蚁“放下”对象的概率分别如下[ 19, 20]:
Pp=1-Sigmoid(f(ti))(4)
Pd=Sigmoid(f(ti))(5)
其中:
Sigmoid(x)= | (6) |
(3)算法改进
在传统的蚁群聚类算法中:
①蚂蚁路径的选择是随机的,有可能出现同一只蚂蚁多次访问某个坐标的情况,导致程序运算时间延长;
②可能会出现某个坐标的术语与当前术语集中的其他任何术语都不相关或者与周围位置对象的平均相似性始终达不到指定阈值的情况,一旦蚂蚁“拾起”了此类术语,在迭代结束时都无法“放下”该术语,造成了蚂蚁资源的浪费。
为此,本文对算法进行了相应改进:
①增加蚂蚁记忆体存储蚂蚁已经爬行过的路径;
②设定负载蚂蚁的最大“放下”次数,如果超过指定次数的蚂蚁依然没有“放下”术语,则表示该术语为孤立的,标记为孤立点;
③记录所有蚂蚁的已爬行路线,蚂蚁在随机选择路线时绕过其他蚂蚁和自身已经爬行过的路线。
算法过程如下:
①将术语集对象投射到一个平面,给每个术语随机分配一个坐标值;
②将所有蚂蚁初始化为无负载,随机选择一个对象;
③定义最大迭代次数M,若i不大于M,转向步骤④,否则转向步骤⑨;
④定义蚂蚁数量ant_n,如果j不大于n,转向步骤⑤,否则转向步骤③;
⑤记录蚂蚁爬行的路线,如果当前蚂蚁或者其他蚂蚁已经爬行过该坐标,则转向步骤④,否则转向步骤⑥;
⑥根据式(3)计算蚂蚁所在坐标对象与邻近对象的平均相似性,如果蚂蚁无负载,依据式(4)计算蚂蚁的拾起概率Pp,若Pp大于某一随机概率P,则蚂蚁“拾起”该对象,同时将自己标记为“已负载”,随机移往别处;否则拒绝“拾起”该对象;
⑦如果蚂蚁无负载,则依据式(5)计算放下概率Pd,如果Pd大于某一随机概率,则蚂蚁“放下”该对象,并标记自己为“无负载”,随机移往别处;否则,转向步骤⑧;
⑧定义蚂蚁最大“放下”次数T,如果t不大于T,则转向步骤⑦,否则转向步骤④;
⑨若i不大于文档集合数量C,则转向步骤⑩,否则转向步骤⑫;
⑩在二维平面上随机分配一个点,取得该点的对象,如果对象不为空,则将该对象赋值给变量Tmp,再按照3*3的区域,递归取出该区域其他坐标的对象以及扩展区域的其他对象,直到坐标上对象值为空时停止;
⑪为Tmp分配一个聚类序号,转向步骤⑨;
⑫完成聚类。
表1显示了蚁群聚类的结果:
| 表1 蚁群算法聚类结果片段 |
以类簇1为例,“连续烧炖式”、“钢坯退火”、“退火温度”、“脱磷率”、“钢退火”等术语都属于钢板和线材轧制后的退火工艺范畴,而“分体式真空槽室”、“预热箱体”、“支撑对流板”、“线材连续退火机”等术语则为退火用设备,因此,基于蚁群算法的聚类效果总体较好。但也会存在一些错误,例如类簇3中的“平均值”,类簇4中的“伤”、“积”等词汇,这可能与术语抽取方法的准确率和测试数据的规模有关。
3.3 K-means多重聚类
在经过蚁群聚类后,原始术语集合被聚集为若干个大类,得益于蚁群聚类算法的特点,每个簇的术语分布较为平均,降低了局部最优情况的出现几率。但是蚁群算法需要满足一定的迭代次数才能完成最终聚类,往往比较费时,而K-means算法则具有简洁、快速的特点。因此,在已经完成初步聚类的情况下,对于每个大类中的术语集可以再利用K-means算法进行多重聚类,从而在不耗费太多时间的情况下,得到术语的层次关系。
此外,对于每次的聚类结果,本文采用了术语综合相似度[ 12]来获取当前类的标签。术语综合相似度是指聚类结果中每个术语与其他术语的相似度之和(见式(7)),若某个术语的综合相似度大于其他术语,则表示该术语在当前类中代表了最宽泛的语义内容,可以作为类标签使用。
su 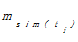

其中,m为当前聚类结果中术语的总数,sim(ti,tj)表示术语ti和术语tj之间的余弦相似度,可由式(2)计算得到。
由此,K-means多重聚类的过程可以描述为:利用术语综合相似度计算每个簇中术语的综合相似度,提取综合相似度最大的术语作为顶层类标签;再利用K-means算法对剩余的术语进行聚类;对于每次的聚类结果,分别利用术语综合相似度进行类标签的提取,并将剩下的术语放入下一层进行聚类,直到达到L层后停止。
具体算法步骤如下:
(1)定义蚁群聚类的类目数量M,若i不大于M,转向步骤(2),否则转向步骤(9);
(2)如果类目中的术语数量少于规定的T,使用式(7)得到综合相似度最大的术语,将其提取出来作为当前类的标签,并将剩余术语赋值给当前类,转向步骤(1),否则转向步骤(3);
(3)使用式(2)获得当前蚁堆的相似矩阵,用式(7)提取类标签,将作为类标签的术语剔除;
(4)对于已剔除类标签的类术语集合,设定子类的聚类数量为当前类术语总数的平方根[ 21],再利用K-means算法进行聚类,得到n个子类;
(5)若j不大于子类总数n,转向步骤(6),否则转向步骤(1);
(6)对于每个子类,利用式(7)计算术语综合相似度,并提取类标签;
(7)如果提取类标签后术语总数少于规定的T,将剩余的术语进行合并,赋值给当前类,并转向步骤(5),否则转向步骤(8);
(8)递归对子类进行下一层聚类,如果聚类层次达到给定的L,则转向步骤(5),否则转向步骤(6);
(9)对聚类结果进行整理,完成聚类。
4 实验结果及分析
本文的实验语料采用文献[14]的术语抽取结果,共计25 497个术语。这些术语主要从国际专利分类号为C21的中文专利名称和摘要中获取,因此笔者从国家知识产权局下载了截至2010年12月国际专利分类号(IPC)为C21(铁的冶金)的共计6 435条专利数据作为实验对象。
预先设定最大聚类层次为4层,每层可聚类术语总数不少于5个,经计算,共计得到237个一级类、786个二级类、1 196个三级类和1 088个四级类,结果如图2所示:
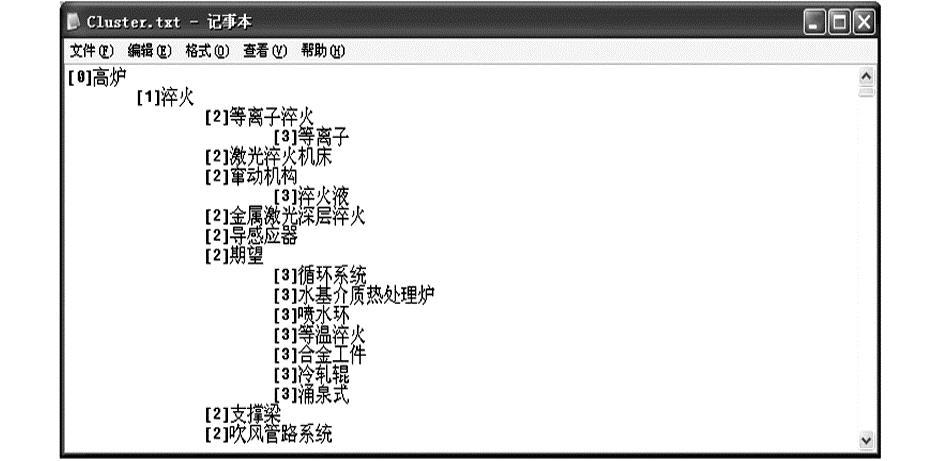 | 图2 本体层次关系获取结果片段 |
由于目前并没有统一的验证标准对聚类结果进行评价,因此只能通过由专家人工评价的方式对聚类结果进行评估。本文从聚类结果中随机抽取了10个一级类,由领域专家分别对其分层归类和类标签抽取的准确性进行评测,结果如表2所示:
| 表2 领域专家评价结果 |
表2从分层归类是否合理和类标签抽取是否准确两个角度对聚类结果进行了评价:
(1)归类是否合理。此次实验归类的准确率均值达到了80.47%,结合图3可以看出,对于二级类目“淬火”来说,“合金工件”、“冷轧辊”、“涌泉式”、“期望”等术语明显不属于该类,而将“等离子淬火”、“激光淬火机床”等术语归于该类较为合理。
(2)类标签抽取结果是否准确。从“淬火”的子类看,第二层将“淬火”设置为该类的标签比较合理,“等离子淬火”、“激光淬火机床”、“导感应器”等类标签的设置也比较符合要求。但是“期望”作为第三层的类标签则不可取。
总体看来,归类准确率和类标签抽取准确率分别达到80.47%和78.78%,层次关系和类标签抽取基本合理,但是并不完善,其原因主要有:
(1)用于测试的文档集数量较少。本文只选用了国际专利分类号为C21的发明专利作为测试文档集,该分类虽然标记为“铁的冶金”,但是并不能完全涵盖炼铁的所有领域。导致部分聚类结果的层次关系和归类准确性达不到领域专家认知的水平,需要扩大测试文档的规模,增加“C22”、“C23”、“B21”、“B22”等其他分类的内容,以提高聚类准确性。
(2)高频词的影响。在综合相似度计算过程中,高频词往往会因为其在文献中与其他术语同时存在的几率较大,从而在计算时可能得到较高的分值,容易被抽取出来作为类标签,而排名稍后的术语有可能代表了该类的主要含义,因排名靠后而被剔除。如果在实验中考虑了高频词的因素,通过合理的手段降低高频词的综合相似度权重,则可以有效提高类标签抽取的准确性。
(3)测试用的术语集合本身并不完备。本次测试使用了文献[14]的术语抽取结果,该结果随机样本的测试准确率达到了86.73%,并不是完全准确,从而导致在聚类过程中,一些没有意义的术语也参与了聚类计算,从而影响了整体的聚类效果。
5 结 语
术语层次关系的构建是本体学习中的重要步骤,影响整个本体的质量,文本聚类则是本体层次关系构建的基本方法。本文利用蚁群聚类算法进行初始聚类,再通过K-means聚类算法对初始聚类的结果进一步分层聚类,并结合术语综合相似度计算的方式提取每个类的标签,从而完成术语层次关系的构建。该方法在初始聚类时避免了K-means算法可能出现的局部最优解情况,再利用K-means进行聚类,以提高聚类速度。实验结果显示,该算法具有一定的合理性,但仍存在一些不足,需要进一步完善。
在未来的研究中,将通过扩充测试文档的规模,合理降低高频词的权重以提高聚类结果的准确性,同时还将改进术语抽取方法,尽量减小错误术语对于聚类结果的影响。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|