

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Single-Pass的网络话题在线聚类方法研究*
引用本文
朱恒民, 朱卫未. 基于Single-Pass的网络话题在线聚类方法研究* . 现代图书情报技术, 2011, 27(12): 52-57
Zhu Hengmin, Zhu Weiwei. Study on Web Topic Online Clustering Approach Based on Single-Pass Algorithm. 现代图书情报技术, 2011, 27(12): 52-57
Permissions
Zhu Hengmin, Zhu Weiwei. Study on Web Topic Online Clustering Approach Based on Single-Pass Algorithm. 现代图书情报技术, 2011, 27(12): 52-57
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于Single-Pass的网络话题在线聚类方法研究*
摘要
基于Single-Pass算法思想,研究网络话题的在线聚类方法,以期及时捕捉网络信息的动态变化。在分析该方法聚类流程的基础上,重点研究网络动态信息流的文本特征抽取和权重计算方法,以及话题类表示和更新等关键问题,设计实验对比分析不同的标题中特征加权系数、特征权重计算和标准化方法以及话题类向量维度对话题聚类质量和时间效率的影响。
关键词:
网络舆情; 话题挖掘; 在线聚类; Single-Pass
中图分类号:G353.1
Study on Web Topic Online Clustering Approach Based on Single-Pass Algorithm
Abstract
In order to get dynamics of Web information timely, an online Web topic clustering approach based on Single-Pass algorithm is researched. The clustering process of this approach is analyzed firstly,and the key problems including extracting and weight calculating of features as well as representation and modification of topic cluster are deliberated. Experiment is designed to compare the effects of different weight factor of features in title, weight calculating and normalizing methods of features and the vector dimension of topic cluster on cluster quality and time efficiency.
Keyword:
Internet public opinion; Topic mining; Online clustering; Single-Pass
1 引 言
网络是一个涉及面广、形式多样、更新快捷的动态信息流,网络话题一旦激起广大网民的关注和热烈讨论,短时间内将产生大量的网络相关报道。因此,迫切需要一种高效的、能够及时捕捉网络热点的话题聚类方法,这也是网络舆情监控和预警的一项重要内容。 已有工作采用基于密度的OPTICS算法[ 1]、层次聚类算法[ 2]和自组织映射网络(SOM)[ 3]等方法研究了话题的聚类,但这些方法均是批学习(Batch Learning)算法,即算法是在整个文档集合上进行聚类运算。由于网络报道是依时间顺序不断到达的动态信息流,批学习算法并不能及时地为逐个到来的网络报道进行话题聚类。针对网络报道这种流式数据,许多学者设计了各种各样的增量算法:Guha等[ 4]提出了一种局部聚类方法,它将数据流按时间顺序分成若干数据小块,对每一小块进行局部聚类;Gupta等[ 5]提出了一个基于Single-Pass的聚类算法GenIc,该算法同样是把数据流划分成不同的数据块,通过评价类中心的合适度来决定是保留或是删除该类中心;税仪冬等[ 6]指出基于Single-Pass的话题聚类方法具有明显的次序依赖缺点,提出了先聚类,再周期分类的话题聚类方法,以提高话题簇的识别精度;胡迁乔[ 7]基于Single-Pass思想设计了网络论坛热点话题的聚类算法,该算法需要先采集主帖,通过遍历统计出单词文档频率,然后基于Single-Pass思想进行话题聚类。综上可知,由于具有增量处理特性,基于Single-Pass思想的聚类方法被一些学者用于文本的增量聚类,但是在聚类过程中上述文献多是采用传统的文本处理方法,缺乏对传统方法适用于动态信息流的有效性进行讨论和实验分析。
在基于Single-Pass的网络话题在线聚类过程中,适合网络动态信息流的文档特征提取、特征项的权重计算,以及话题类的科学表示和动态调整,是该方法的关键环节。一些文本处理方法的选取和方法中系数的选择,以及对传统方法的改进直接影响了话题聚类质量和时间效率,本文结合理论分析和实验评价对此展开研究。
2 Single-Pass算法基本思想
Single-Pass算法又称单通道法或单遍法,是流式数据聚类的经典方法。对于依次到达的数据流,该方法按输入顺序每次处理一个数据,依据当前数据与已有类的匹配度大小,将该数据判为已有类或者创建一个新的数据类,实现流式数据的增量和动态聚类。
Single-Pass算法是一种增量算法,适合对流数据进行挖掘,而且算法的时间效率高;不足之处主要表现在该方法具有输入次序依赖特性,即对于同一聚类对象按不同的次序输入,会出现不同的聚类结果。
3 基于Single-Pass的网络话题在线聚类方法
基于Single-Pass的网络话题在线聚类方法的流程如图1所示:
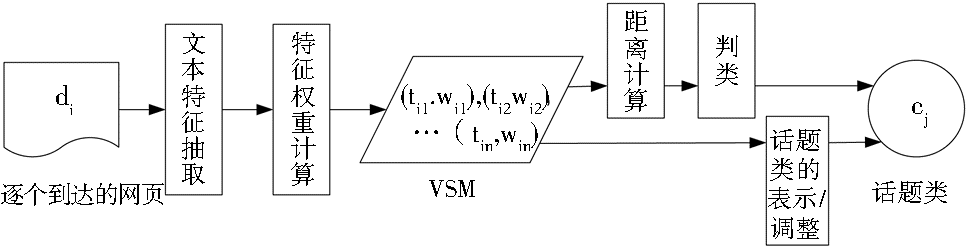 | 图1 基于Single-Pass的网络话题在线聚类方法的流程 |
对逐个到来的网页di进行文本特征抽取,并计算每个特征的权重,从而构建出文本di的向量空间模型(VSM);然后采用传统的夹角余弦公式计算di同已有话题类向量之间的距离,比对相似度阈值将其判为已有类或新创建的类cj;最后,基于di的特征向量更新话题类cj的表示向量。其中,动态文档的特征抽取、特征权重计算以及话题类的表示与调整是该方法的关键环节。
3.1 网络文本的向量空间模型
网络文本采用传统的向量空间模型来表示,即网络文本di可用形式化的方式来描述:di=((ti1,wi1), (ti2,wi2),…, (tin,win))。其中,tij代表文本内容的特征项,即文本中切分出的词;wij是特征项tij的权重。因此,针对网络动态信息流特点,研究文本特征项抽取及其权重计算是构建网络文本向量空间模型的关键步骤。
(1)网络文本的特征项抽取
由于汉语中词与词之间没有明显的分隔标记,一般采用分词技术来完成文本特征项的抽取。本文采用中国科学院计算技术研究所的汉语词法分析系统ICTCLAS2011对网络文本内容进行分词处理。ICTCLAS2011采用了层叠隐马尔可夫模型和PDAT大规模知识库管理技术,在分词高精度和高速度方面取得了较大突破。
网络文本经过ICTCLAS2011分词后的词向量空间维度很大,将会给后续处理带来较大的时间消耗;而且,切分出的特征词中包含了大量的虚词和无实际含义的词,它们对话题的描述与识别不起任何作用。因此,本文在分词过程中根据词性和词的长度过滤掉助词、介词、连词等虚词以及词长较短的无实际意义词。
网络文本一般包含标题和正文两部分内容,标题往往点出了报道的主题,是网络文本的核心。为了准确地描述出网络文本的特征,本文分别抽取出标题和正文中的特征词,在统计特征项词频时,对来自标题中的特征项词频乘上一个加权系数α(α≥1),即文本特征项ti的词频f(ti)=α×ft(ti)+ fc(ti),其中ft(ti)、fc(ti)分别为特征项ti在标题和正文中的词频。如果α取值过小将不足以突出标题中特征项的重要性;如果取值太大,将会抑制正文中绝大部分特征项对文本主题的描述能力。因此,α的取值直接关系到话题的聚类质量,实验将对其进行讨论。
(2)动态文本的特征权重计算
TF-IDF是计算文本特征权重的常见方法,其中TF为特征项在文档中出现的频率,IDF为特征项的反引文档频率,即在文档集中包含特征项的文档数目。TF越大,说明特征项在文档中越重要;IDF越大,即特征项在文集中的多篇文档中出现,这反映出该特征项并不是本文档的独有特征,在聚类过程中对类的划分所起的作用并不大。因此,TF-IDF方法中特征项的权重可描述为:
wi=fa(TFi)×fb(N/IDFi)(1)
其中,N为文集中的文档数目,fa和fb分别是关于TF和IDF的函数。
但是,网络信息流是依据时间顺序逐个到达的,计算信息流中某个文档di的特征项权重时,只能采用di及其之前到达的文档构成的文档集来计算特征项的IDF。这样每篇文档在计算特征项的IDF时所采用的文档集都不一样,影响了IDF计算的准确性,增大了聚类结果对网络文档输入顺序的敏感性,最终影响话题聚类的质量。因此,有必要对TF-IDF方法应用于网络信息流在线聚类的有效性进行评价。
网络文本的内容长短不一,内容较长的文档中特征项出现的词频往往较大,因此特征项的权重数值也较大。为了避免网络文本内容长短对话题聚类结果的影响,需要对特征项的权重数据进行标准化处理。常见的数据标准化方法有比例法和最小最大值法,假设网络文档di的特征权重向量为(wi1,wi2,…,win),则采用比例法和最小最大值法标准化处理特征权重的公式分别如下所示:
wij=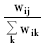 | (2) |
wij= | (3) |
式(2)和式(3)均是将每个权重分量标准化为[0,1]内,其中wmax和wmin分别为权重分量中的最大值和最小值。实验将讨论上述两种数据标准化方法对话题聚类质量的影响。
3.2 话题类的表示和动态调整
话题类的表示一般有质心向量和中心向量两种方法。中心向量法是指话题类由其中一个文档作为中心向量来表示,该方法需要大量时间搜索合适的中心向量,中心向量选择不准确将会导致所有后续增量聚类出错。质心向量法是采用类中所有文档向量的平均值来表示话题类,该方法对噪声和孤立点敏感,但不会存在一错皆错的问题。考虑到网络话题的在线聚类需要较高的时间效率,且质心向量可以被增量产生,本文采用质心向量法表示话题类,即话题类cj在tk时刻的质心向量c(cj,tk)可表达如下:
c(cj,tk)= 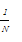
其中,N为该话题类的文档数。
由于话题类的质心向量是类中所有文档的特征向量叠加而成,因此向量维数非常高,增加了计算的复杂度。为了限制话题类向量的维数,本文对质心向量法进行了改进,取质心向量中权重较大的前Nd个特征项构成的向量来表示话题类。Nd的不同取值将会影响到话题聚类的质量和时间效率,实验将对Nd取值进行讨论。
在线聚类中话题类随着文档的添加而不断更新,因此话题类向量也要动态更新,本文依据式(4)推导出话题类向量的增量更新公式,如下所示:
c(cj,tk+1)= 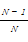

其中,N、dk+1分别为tk+1时刻话题类cj中的文档数量和此时刻到达的文档向量。
由于限制了话题类向量的维数,话题类表示向量只是其质心向量的一部分。同网络文本向量一样,话题类向量也需要数据标准化处理,以避免向量权重数值较大的话题类主导着聚类结果。
3.3 基于Single-Pass的网络话题在线聚类算法
基于Single-Pass的网络话题在线聚类的主要步骤如下:
算法1 ClusterBySingle-Pass( )
Input:网络动态信息流d1,d2,…,dn,内容相似度阈值Tc,以及话题类的向量维度Nd;
Output:话题类c1,c2,…,ck
①for 每个时刻ti到达的一篇网络报道di do{
② 通过特征抽取、特征权重计算、标准化处理构建出di的向量空间模型;
③ if 尚不存在话题类 then{
④ 创建新话题类c1,并将di∈c1;
⑤ c(c1,ti)= di中依据特征权重大小取其前Nd个分量,标准化处理;
⑥ } else{
⑦ for 已有的每个话题类cj do {
⑧ 计算di,cj的相似度sim(di,cj); }
⑨ 令maxS= 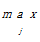
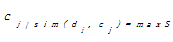
⑩ If maxS>=Tc then {
⑪ di∈maxC;
⑫ 依据式(5)调整c(maxC,ti),依据特征权重大小取其前Nd个分量,标准化处理;
⑬ }else{
⑭ 创建新话题类cnew,并将di∈cnew;
⑮ c(cnew,ti)= di中依据特征权重大小取其前Nd个分量,标准化处理;
⑯ }
⑰ } i++;
⑱ }return 所有的话题类c1,c2,…,ck.
算法1中,步骤①-⑰完成网络动态信息流中一篇文档di的处理和判类过程;其中步骤③-⑤完成信息流中第1篇文档的判类;步骤⑦-⑨识别出与di最相似的已有话题类;步骤⑩-⑫是当最大相似度大于或等于阈值时,将di判给已存在的类,并调整类表示向量;步骤⑬-⑯是当最大相似度小于阈值时,以di为成员创建一个新类。
令n为信息流中的文本数量,k为算法最终聚出话题类的数目,则算法1的计算复杂性是O(nk),其计算开销远低于其他聚类算法[ 1, 2, 3],因此基于Single-Pass的网络话题在线聚类方法具有较高的时间效率。
4 实验分析
实验文集选用2011年6月21日至7月4日期间网易新闻(http://news.163.com)中关于高速公路收费(话题1)、京沪高铁(话题2)、城市内涝(话题3)、郭美美事件(话题4)、高考招生(话题5)和庆祝建党90周年(话题6)6个热门话题的425个网页。实验文集的获取是先通过设置关键词、时间段和来源网站等检索条件,调用通用搜索引擎完成相关话题的检索,然后利用网络爬虫采集通用搜索引擎返回的检索结果;最后将采集下来的文集按网页创建时间的先后顺序进行排序,模拟出实验中的网络信息流。实验中网络爬虫和基于Single-Pass的网络话题在线聚类方法均在Visual C++ 6.0开发环境下实现。
实验采用准确率P、召回率R和综合指标F来评价方法的话题聚类质量,其中P=nc/na,R=nc/nt,na表示方法判断出与网络话题相关的文档数目,nc为na个文档中正确反映该话题的文档数目,nt表示由人工判断出实验文集中与该话题相关的所有文档数目;F=P×R×2/(P+R)。
实验分析了标题中特征加权系数、特征权重计算方法和标准化方法对话题聚类质量的影响,并比较了不同的话题类向量维度Nd对话题聚类质量和时间效率的影响。
4.1 标题中特征加权系数α对话题聚类质量的影响
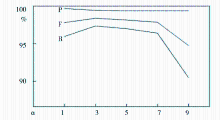
本实验比较了标题中特征加权系数α的不同取值对话题聚类质量的影响,实验结果如图2所示:
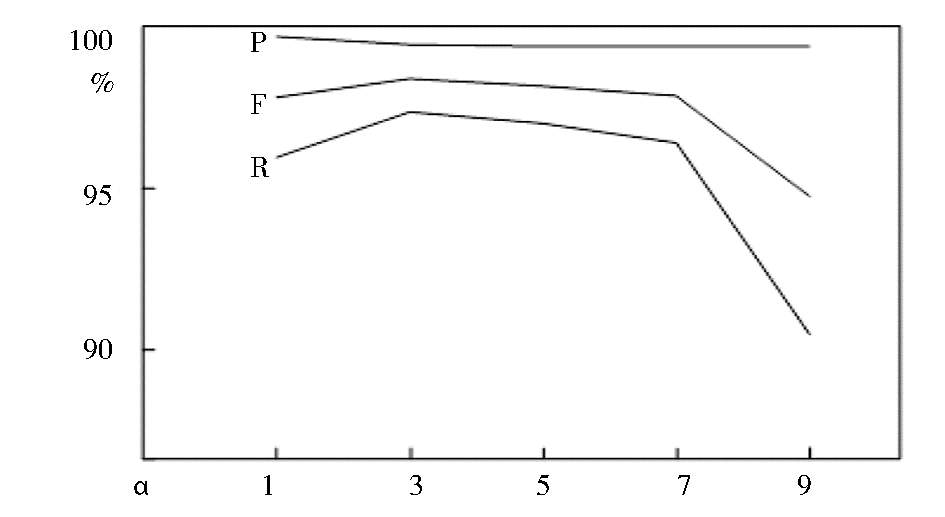 | 图2 α对话题聚类质量的影响分析 |
可以看出,α对话题聚类质量的影响主要体现在算法的召回率R上,当α=3时,聚类算法的R和F值最大,取值过小或者过大都使得算法召回率R下降,因此本实验中α取值为3。
4.2 特征权重计算方法对话题聚类质量的影响
面向网络动态信息流的话题在线聚类方法中,由于不能在一个统一的文集下计算反引文档频率,话题聚类质量将会受到影响,且对文档输入顺序的敏感性将会增强。考虑到在文本特征抽取时依据词性和词长过滤掉无意义的词,那么过滤后特征词的词频能够反映该特征词的重要程度,因此本实验将TF-IDF方法(特征权重计算方法见式(6)[ 6])同仅考虑词频的方法(记为TF,权重计算方法见式(7))进行了对比。
wi= TFi×ln(0.01+IDFi) (6)
wi=ln(1+TFi) (7)
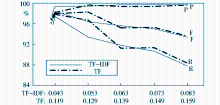
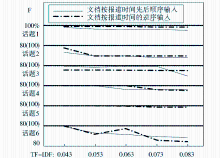
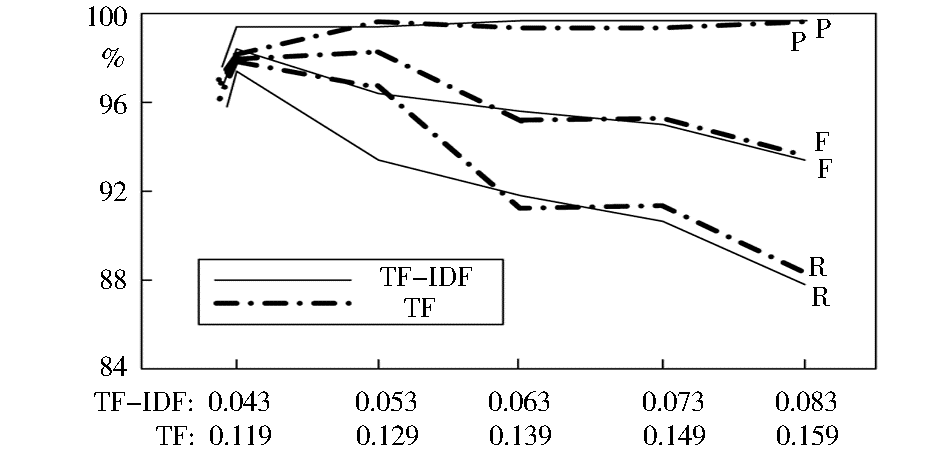
由于两种特征权重计算方法得出的文档与话题类的内容相似度对阈值的敏感程度不一样,采用式(6)和式(7)的实验只有在阈值分别达到0.043和0.119时,才能有效地区分各个话题类,因此实验分别以0.043和0.119为阈值起点、以0.01为步距,选择5个不同的阈值对话题聚类质量和文档顺序的敏感性进行了对比,实验结果如图3至图5所示:
 | 图3 两种特征权重计算方法对话题聚类质量的影响 |
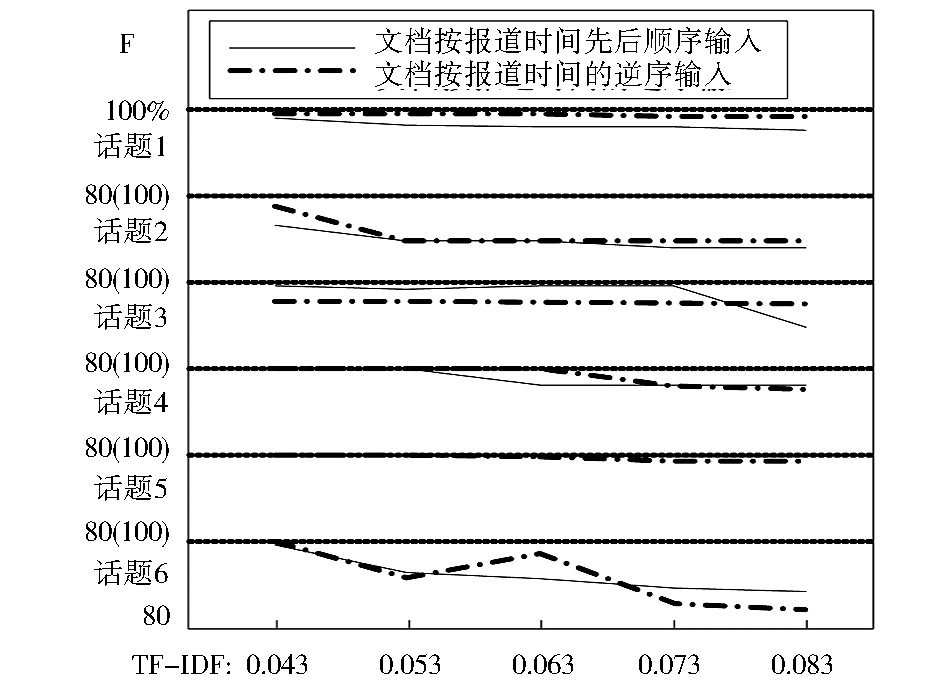 | 图4 TF-IDF方法在不同的文档输入顺序下的聚类质量 |
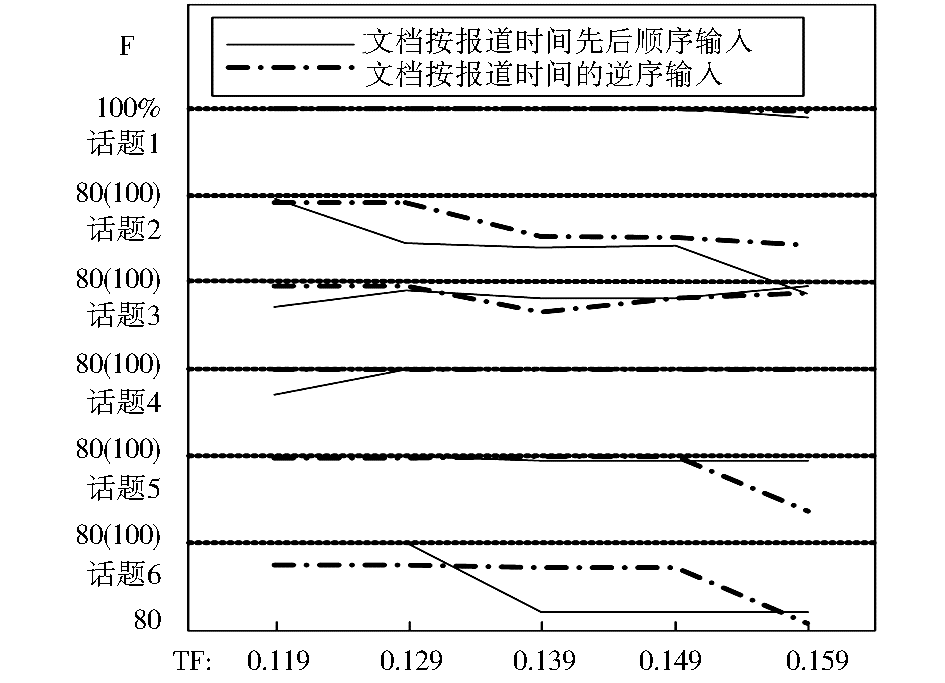 | 图5 TF方法在不同的文档输入顺序下的聚类质量 |
从图3可以看出,两种特征权重计算方法在各个阈值水平上都取得了较高的话题聚类准确率,相对来说,TF-IDF方法在准确率上略微占优,而仅仅考虑词频的方法在召回率上具有一定优势。从综合指标F来看,除第2个阈值水平外,两种方法的F值非常接近。对比图4和图5中两种方法在不同文档输入顺序下的话题聚类质量,TF-IDF方法对文档输入顺序的敏感性要小于仅仅考虑词频的方法,在话题2和话题6上表现尤为明显。综合实验结果,TF-IDF方法在面向网络动态信息流的话题在线聚类方法中具有良好表现。
4.3 特征权重标准化方法对话题聚类质量的影响
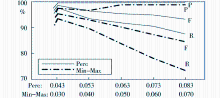
本实验比较了比例法(记为Perc)和最小最大值法(记为Min-Max)两种数据标准化方法对话题聚类质量的影响。由于采用两种方法计算出的文档与话题类的内容相似度对阈值敏感程度不一样,采用式(2)和式(3)的实验只有在阈值分别达到0.043和0.030时,才能有效地区分各个话题类。因此实验分别以0.043和0.030为阈值起点、以0.01为步距,选择5个不同的阈值对话题聚类质量进行对比,实验结果如图6所示:
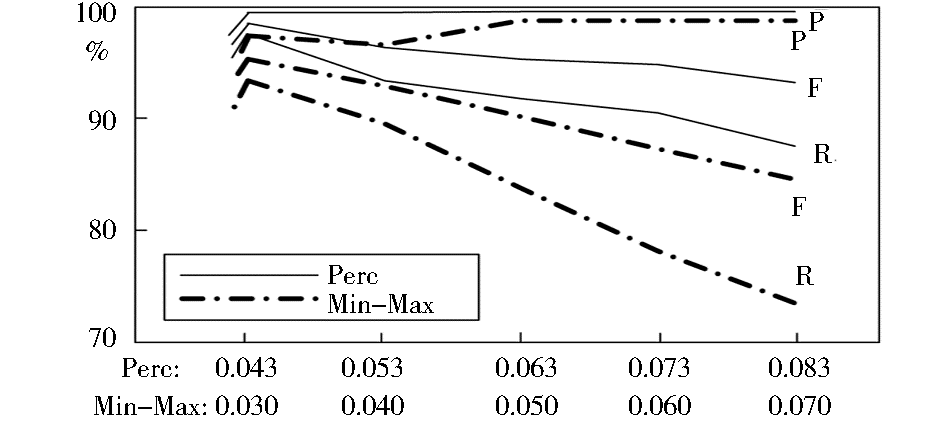 | 图6 两种特征权重标准化方法对话题聚类质量的影响 |
图6中反映出采用比例法的话题聚类算法在准确率P、召回率R和综合指标F上均高于最小最大值法。
4.4 话题类向量维度对话题聚类质量和时间效率的影响
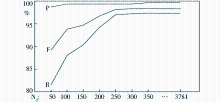
话题类向量维度Nd的选取将会影响到话题聚类的质量和时间效率。图7对比了Nd不同取值时的话题聚类质量,其中Nd=3 781是指实验中若不限制话题类向量维数时,所聚出话题类向量的最大维度。
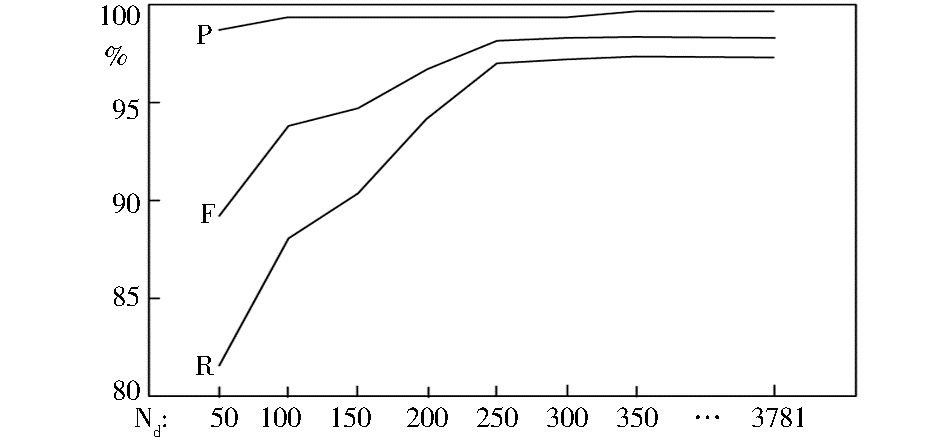 | 图7 Nd对话题聚类质量的影响分析 |
从图7中可看出,话题类向量维度Nd对算法召回率影响较大,随着Nd取值增大,算法召回率呈现先快速、后缓慢地上升。这是因为,话题类向量维度越大,包含的文本特征就越多,将有更多的文档因为具有与话题类向量相同的特征而被聚为一类。
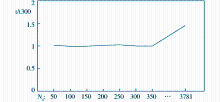
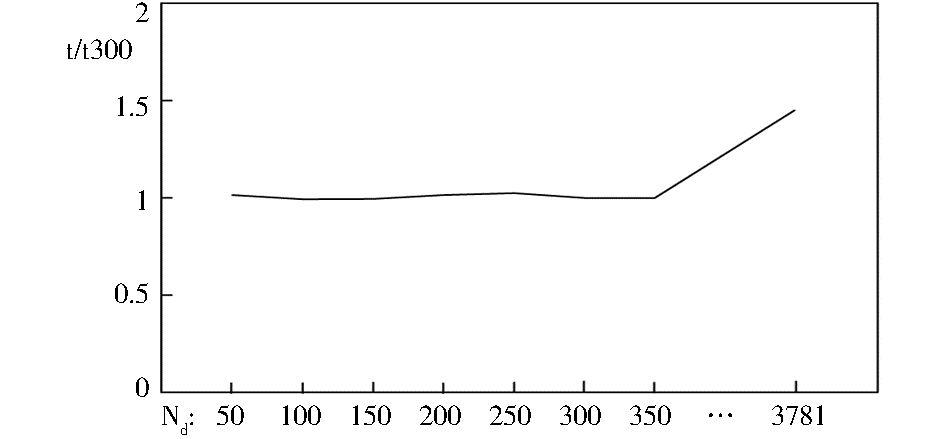 | 图8 Nd对话题聚类时间效率的影响分析 |
图8对比了Nd不同取值时话题聚类的时间效率。由于算法运行时间受到计算机硬件和软件资源的影响,纵坐标刻画的是算法运行时间与Nd=300时算法运行时间的比值。图7反映出当Nd≥250时,话题聚类质量增长得非常缓慢,但从图8中可看出,如果不对话题类向量维度加以限制,话题聚类所耗费的时间明显增加。因此,选择合适的Nd来限制话题类向量维度非常有必要,它可以在几乎不损失聚类质量的情况下显著提高算法的时间效率。
5 结 语
本文对基于Single-Pass的网络话题在线聚类方法关键问题展开了研究。针对网络文本具有标题和正文部分这一特点,通过为标题中特征项加权来抽取出准确的文本特征,并通过实验评价出合适的加权系数;讨论了动态信息流环境下常见文本特征权重计算方法存在的问题,结合实验对不同的特征权重计算和标准化方法进行评价;对话题类的质心向量表示法进行了改进,提出选取质心向量中权重较大的前Nd个特征项构成的向量来代表话题类,并通过实验验证了改进方法的有效性。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|