{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
通过日志挖掘研究图书馆资源发现服务用户的搜索行为
引用本文
朱玲, 聂华. 通过日志挖掘研究图书馆资源发现服务用户的搜索行为. 现代图书情报技术, 2011, 27(12): 74-78
Zhu Ling, Nie Hua. Research of User’s Searching Behaviour of Library Resource Discovery Service by Log Mining. 现代图书情报技术, 2011, 27(12): 74-78
Permissions
Zhu Ling, Nie Hua. Research of User’s Searching Behaviour of Library Resource Discovery Service by Log Mining. 现代图书情报技术, 2011, 27(12): 74-78
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
通过日志挖掘研究图书馆资源发现服务用户的搜索行为
摘要
通过日志挖掘的方法对图书馆资源发现服务用户的搜索行为进行研究。搭建一个搜索日志中间平台,用于产生和记录相关日志信息;用Java编写日志处理程序,将日志信息存储于MySQL数据库中;基于日志结果,从检索方式、查询语言与查询长度、分面点击、查询词修改等方面对用户搜索行为进行分析,希望能对图书馆资源发现服务的部署、应用和优化提供参考。
关键词:
日志挖掘; 图书馆资源发现服务; 用户搜索行为
中图分类号:G250.76
Research of User’s Searching Behaviour of Library Resource Discovery Service by Log Mining
Abstract
This paper investigates user’s searching behaviour of library resource discovery service by log mining. First of all, an intermediate platform is built to generate and record user’s searching logs. Then the log information is identified, extracted and objectified by Java application, and the data is permanently stored in a MySQL Database for further statistics and analysis. The analysis includes searching language, searching length, the using frequency of advanced-search, facets, how users modify their search queries, etc, and the conclusions are helpful to the implementation, application and optimization of library resource discovery service.
Keyword:
Log mining; Library resource discovery service; User’s searching behaviour
1 引 言
(1)基于日志的互联网用户信息行为分析
用户信息行为分析和研究是互联网时代搜索引擎、电子商务网站和社交网站持续改进服务、吸引更多用户和增加已有用户忠实度的基础。用户搜索行为不仅与其学科背景、从事行业和个人习惯有关,还随着整个网络信息检索技术的发展而发生着潜移默化的整体性变迁,存在很大的复杂性、差异性和不确定性。如何对用户搜索行为进行更实时、有效、深入的追踪和分析,已经成为信息检索领域的一大课题,而日志挖掘则是目前获取和分析用户搜索习惯和行为分布特征最重要的方式之一。通过分析网络日志记录中的搜索词语言、搜索词长度、被点击记录在结果列表中的排名分布和结果页面跳转等,可以帮助信息资源提供者更好地从用户搜索历史记录中挖掘和理解用户行为,并且进一步理解驱动用户行为的搜索任务和意图,对于改进搜索引擎算法和搜索界面设计具有极其重要的意义。 Silverstein等[ 1]对大规模英文搜索日志进行了分析,得到了一些关于用户搜索行为的重要结论,对英文搜索引擎的算法改进和发展提供了指导意义。国内研究者对中文搜索引擎用户行为进行了一系列研究,包括查询语言、查询长度、页面点击深度等方面,对于中文搜索引擎的改进提供了有益参考[ 2, 3, 4]。
(2)图书馆资源发现服务
图书馆资源发现服务,是在Google、Wikipedia、Amazon等众多互联网资源服务兴起后,图书馆业界紧跟技术发展趋势而推出的一项基于海量元数据仓储和索引技术的突破性服务。它旨在通过类似Web搜索引擎(如Google)的简单界面和成熟框架为读者提供轻松发现和便捷获取图书馆全部资源(不论纸本/电子、文本/多媒体、本地/商业、书目级/文章级)的全新方式。图书馆资源发现服务一经推出即得到业界的强烈关注和响应,其用户数在短短两年内得到迅猛增长。据不完全统计,截至2011年6月,几大主流资源发现服务的用户数之和已超过500家统计结果由相关厂商提供,由于对产品的定义和统计方法不尽相同,该数据仅供参考。 。目前,已应用资源发现服务的图书馆用于征集和了解读者反馈的方式主要局限于问卷调查,受到问卷篇幅、题目复杂度和填写问卷的用户数量等因素限制,往往难于对用户的搜索行为特征和分布进行比较全面和深入的分析。
(3)资源发现服务用户搜索行为分析
将日志挖掘的方法应用于图书馆资源发现服务用户的搜索行为研究:利用Web反向代理服务器Squid[ 5]搭建一个搜索日志的中间平台,用于产生和记录北京大学图书馆资源发现服务Summon试用期间与用户搜索行为相关的日志信息,然后用Java编写日志处理程序,将日志信息存储于MySQL数据库中。基于日志挖掘结果,从检索方式、查询语言与查询长度、分面点击、查询词修改、排序切换和页面跳转等多个方面对用户搜索行为进行分析,希望能对图书馆资源发现服务的部署、应用和优化提供参考。
2 北京大学图书馆资源发现服务项目背景
北京大学图书馆自2010年春季学期开始,在相关厂家的大力支持和配合下,先后对三个目前在中国大陆市场上比较活跃的资源发现服务产品进行了全面深入的调研和试用[ 6, 7, 8]。2011年5月,为了更好地了解读者对图书馆重点调研和测试的两个资源发现服务(Summon、Primo)的使用反馈,本馆在搭建完成中间搜索日志分析平台的基础上,正式将资源发现服务开放给读者进行试用。本文的分析即基于该平台所产生和记录的日志,以Summon为例,共计获取近30 000行日志记录,其中与搜索相关的记录共计3 000余行。
3 中间日志平台及用户搜索行为模型
3.1 中间日志平台
基于日志分析的用户搜索行为研究面临的首要问题是如何获取和储存日志记录,在用户和资源发现服务Summon之间建立一个中间平台,用于产生和记录与用户搜索行为相关的日志信息。
利用代理服务器Squid作为资源发现服务的反向代理,由Squid转发用户与资源发现服务之间的所有请求和响应。通过在squid.conf文件中进行专门的配置,使其能够在访问日志中详细记录用户每次查询的时间、IP、请求内容等信息,对日志中查询请求基本结构的说明如表1所示:
| 表1 日志查询基本结构 |
3.2 用户搜索行为模型
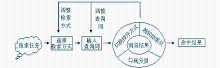
资源发现服务源起于对基于大规模元数据仓储和索引技术的搜索引擎的借鉴,目的在于让互联网时代的读者在搜索图书馆资源时拥有更便捷、更有效的发现与获取体验。资源发现服务的元数据一般要经过查重合并、规范化等一系列预处理,使其结构化更强,内容更丰富,质量更可靠。这种充分结构化的数据是资源发现服务能够拥有比搜索引擎更丰富的分面导航等功能的基础,也使得资源发现服务与Web搜索引擎在界面框架和用户搜索行为模型上存在一定的差异。本文针对资源发现服务Summon的用户搜索行为进行了建模,如图1所示。
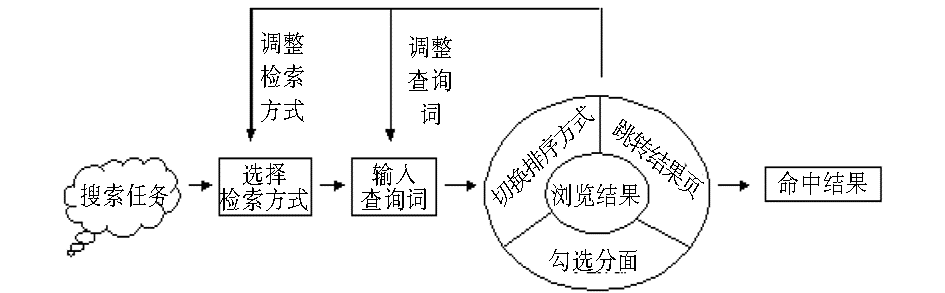 | 图1 资源发现服务Summon的用户搜索行为模型 |
分面类型主要包括:仅限全文资源、仅限学术性资源、不限于本馆馆藏、资源类型、主题、著者、时间、馆藏地、语言等。
4 基于日志挖掘的用户搜索行为分析
本文分析所用日志来源于利用Squid搭建的中间日志平台。2011年5月6日至6月12日,访问资源发现服务Summon的日志记录共计近30 000行,其中搜索相关记录3 064条,用户IP数588个。
4.1 检索方式的选择
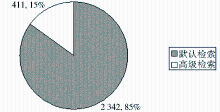
用户的有效查询共计2 753次。用户使用默认检索2 342次,占总检索次数的85%;使用高级检索411次,占总检索次数的15%,如图2所示:
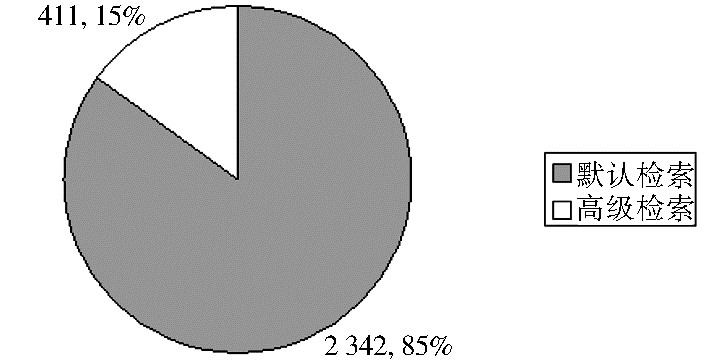 | 图2 两种检索方式的选择 |
用户对高级检索的使用率远低于默认检索。对使用高级检索的用户提交的请求序列进一步分析表明,高级检索的使用一般紧接发生于已进行默认检索之后。可以说,大多数情况下,高级检索是使用默认检索的结果不够满意时转而选择的后备方式。
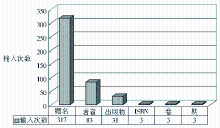
高级检索的字段之间也呈现出很大的差异性,各字段的使用情况比较如图3所示。
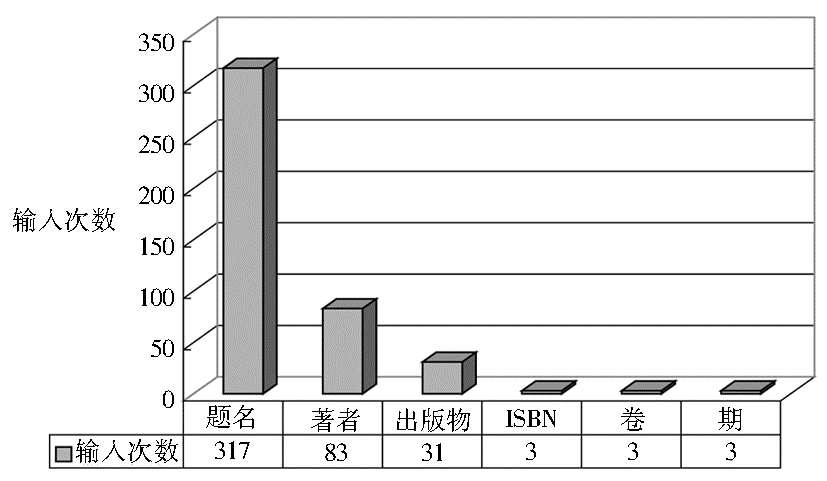 | 图3 高级检索中各字段的使用比较 |
可以看出:
(1)对题名字段的搜索次数最多,几乎77%的高级检索都会输入题名字段,这说明在题名命中关键词的记录对于用户的重要性远大于其他字段或全文。因此图书馆在考虑相关度排序各字段的加权时,应该着重强调题名字段的重要性,例如,给予题名字段大于其他字段的权重。
(2)用户对著者和出版物的搜索需求比较明显。由于著者和出版物往往在名称表达上存在多种格式及全缩写的差异,如果要更好地满足读者对于这两项精确检索的需求,就必须进一步加强在元数据中著者和出版物名称的规范化,在这方面,Google Scholar[ 9]提供了很好的借鉴和参考。
(3)对于ISBN、卷、期这三个字段的搜索次数低到几乎可以忽略,这说明用户的搜索任务以及相应在搜索字段上的表现主要是基于描述性的内容,那些标识编号性的、易理解性较差的字段重要性很低。这对设计高级检索界面给予了一定的启示,例如,可以着重突出重要字段,而将几乎不会被用到的字段以折叠或其他方式灵活隐藏,以便给用户呈现出更加清晰的界面,节省浏览、停留、选择的时间。
4.2 查询语言与查询长度
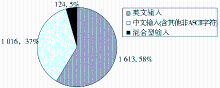
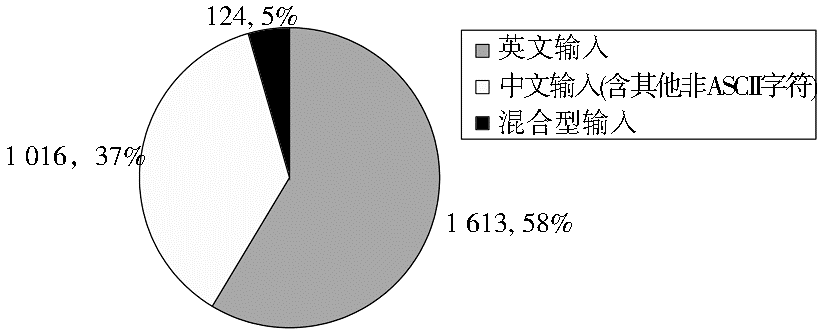
(1)用户的有效查询共计2 753次,其中英文输入1 613次,中文输入(含其他非ASCII 字符)1 016次,混合型输入124次,如图4所示:
 | 图4 各种查询语言类型所占比例 |
说明在高校用户群体中,查找学术资源时英文的使用比例很高。
(2)查询长度主要是指用户提交的查询词序列中包含几个词语(以空格隔开),统计结果为:
①英文输入的平均查询长度为2.81,这与Silverstein等[ 1]分析结果中的2.35比较吻合。
②中文输入的平均查询长度为1.04,这与国内其他研究者关于中文平均查询长度一般小于英文平均查询长度的结论基本一致[ 3]。
③混合型输入的平均查询长度为6.47。其原因可能是混合型输入一般是在用户的搜索任务难度较高(例如搜索任务难以用单语种清楚、唯一地表达)时采用,用户试图采用多重语言和更大的平均查询长度来提高结果的相关性。
中文输入平均查询长度非常小,进一步考察每个词中所含汉字的个数,得到平均每个词所含字数是4.66。这一方面说明中文检索与英文检索在查询词输入上存在明显的差异:中文输入的习惯是若干个关键词连排,并不以空格切分;另一方面也说明用户对资源发现服务理应具有的分词功能有着较高的期待或者默认。图书馆资源发现服务应该高度重视中文与英文之间的差异,加强中文化、本地化工作,对用户查询词以及中文资源的元数据索引内容都进行更加成熟的语义分析和处理,才能有效地提高中文资源搜索的准确性。
4.3 各种类型的分面点击
分面导航是资源发现服务的重要功能,目的在于使读者能够对检索结果按照各种范畴(例如资源类型、主题等)进行分组浏览,选中并精简到某一组结果集,由此逐层递进,最终能准确定位最相关的资源。从某种意义上说,以大规模的、高质量的元数据索引为基础,分面导航与简洁的单检索框界面相呼应,不仅将传统检索系统中读者进行高级检索的工作量一定程度上转而由系统后台代劳,而且为用户提供了更强的指引性,使得搜索任务成为一种边探索边发现的、更愉快的搜索体验。在Summon的界面体系中,分面类型主要包括:仅限全文资源、仅限学术性资源、不限于本馆馆藏、资源类型、主题、著者、时间、馆藏地、语言。
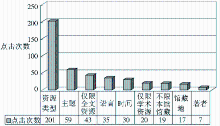
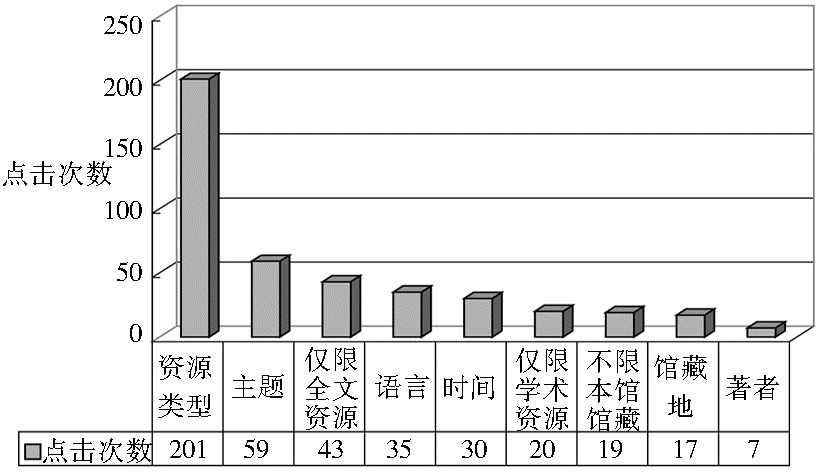
在本文的日志样本中,用户对分面的点击共计480次,不同分面类型的点击次数如图5所示:
 | 图5 各种分面类型点击排名 |
统计结果表明,用户对于各种类型的分面都存在着一定的需求,其中尤其以资源类型分面的需求最大。资源发现服务的分面导航功能依赖于高质量的、规范化的元数据。对于大规模的、整合自不同来源的数据,极易出现分面值重复(比如一个著者存在多种写法),或者具有二义性(比如北京大学讲座多媒体资源的资源类型可以归于特藏记录,亦可归于视频记录)等现象,给用户的理解和选择带来困惑和不便,在部署和应用时应该尤其重视,尽量避免由此带来的问题。
4.4 查询词修改
查询词是用户搜索任务的字面体现,当查询结果不够满意,或搜索目标领域还未穷尽,又或查询结果反过来启发和提示了用户更贴切的关键词时,用户都可能会对原有查询词进行修改,以便获取更相关的、更多的资源。
本文获取的日志记录中查询词有效输入共计2 753次,对来自同一IP的查询词修改模式进行了分析,归纳出用户修改查询词的几种主要模式如下:
(1)查询词增加/删除:主要原因是查询结果数过多/不足;
(2)查询词的不同表达/格式替换:例如通过尝试关键词的中英文表达,人名或机构名的正序/逆序、缩写/全称等,尽可能地减少目标资源的遗漏;
(3)近义词的交叉组合遍历:通过充分组合若干集合中的近义词,达到对某个研究范围的查询词覆盖,例如,有读者在搜索中将集合1({草原、草场})与集合2({管理、利用})中的近义词任意组合,或将集合3({西学东渐、洋务时期、晚清、清朝、鸦片战争以来})与集合4({传统高等教育、中国传统教育})中的近义词任意组合;
(4)查询词的相关联想:可从人物联想到人物(例如:刘士骥→康有为→严复→章士钊),也可从人物联想到其研究、思想、成果、参与活动与事件(例如:范祖辉→Astrophysical Journal→Dark Energy),或反之(古植物→全球变化→薛进庄→郝守刚)。此时用户很可能已不再局限于仅仅命中预想目标,而希望通过相关性联想进行更多的探索与发现。
用户查询词修改行为应促使资源发现服务在资源联想/推荐功能上进行更多、更深入的尝试,例如关键词联想树状图、标签云、相关数据库/文章推荐等,可以更好地帮助读者进行资源探索。
4.5 排序方式和结果页跳转
资源发现服务的默认排序方式为相关度排序,可选的其他排序方式主要包括时间正序、时间逆序等。本文的统计中,用户切换排序方式操作共计90次。可以看出,互联网时代用户对始于Web搜索引擎的相关度排序是比较认可和依赖的,选择从默认的相关度排序切换到时间排序方式的几率很低。
用户对结果页的跳转操作共计306次,也就是说,用户大概平均10次检索才会有一次选择翻页继续浏览。因此,图书馆资源发现服务应该着重改进和优化相关度排序,主动适应置身于海量信息源的读者的快节奏研究习惯,不再预期读者耐心浏览全部结果,而是尽可能地集中于第一页或前几页为读者呈现更相关、质量更高的结果。
5 结 语
用户行为分析是互联网时代资源搜索服务实现技术进步和服务提升的重要基础,本文将日志挖掘的方法应用于图书馆资源发现服务用户的搜索行为研究,从检索方式、查询语言与查询长度、分面点击、查询词修改、排序切换和页面跳转等多个方面对用户搜索行为进行了分析,结果表明图书馆资源发现服务用户的搜索行为具有以下特点:
(1)用户对高级检索的使用率远低于默认检索,而高级检索中以题目字段的使用比例最高。
(2)在高校用户群体中,查找学术资源时英文的使用比例很高。对于中文输入,查询长度较低,但每个查询词所含平均字数很高,说明中文分词处理对提高中文搜索准确性至关重要。
(3)用户对于各种类型的分面都存在一定的需求,其中尤其以资源类型分面的需求最大,需要着重梳理,尤其避免分面值重复或具有二义性。
(4)用户进行查询词修改的主要模式包括查询词增/删、表达/格式替换、近义词组合和相关联想等。资源发现服务应提供更多的资源联想/推荐功能。
(5)用户对始于Web搜索引擎的相关度排序比较认可,并且大多数情况下只浏览第一页结果,因此资源发现服务应该最大限度地优化相关度排序。
对图书馆资源发现服务用户搜索行为的日志分析表明:在资源发现服务的部署和应用中,图书馆应该致力于实现更简洁的界面和更成熟的检索框架、更规范的元数据、更优化的相关度排序、更成熟的中文切分和语义分析、更丰富的资源联想与推荐,才能真正为互联网时代的读者提供对图书馆资源更便捷、更有效的发现与获取途径。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|